Elasticsearch入门与优化
一、Elasticsearch概述
https://blog.csdn.net/qq_41262248/article/category/7467390
一)基本概念
1、接近实时(NRT)
Elasticsearch 是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个很小的延迟(通常是 1 秒)。
2、集群(cluster)
代表一个集群,集群中有多个节点(node),其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
3、索引(index)
ElasticSearch将它的数据存储在一个或多个索引(index)中。用SQL领域的术语来类比,索引就像数据库,可以向索引写入文档或者从索引中读取文档,并通过ElasticSearch内部使用Lucene将数据写入索引或从索引中检索数据。
4、文档(document)
文档(document)是ElasticSearch中的主要实体。对所有使用ElasticSearch的案例来说,他们最终都可以归结为对文档的搜索。文档由字段构成。
5、映射(mapping)
所有文档写进索引之前都会先进行分析,如何将输入的文本分割为词条、哪些词条又会被过滤,这种行为叫做映射(mapping)。一般由用户自己定义规则。
6、类型(type)
每个文档都有与之对应的类型(type)定义。这允许用户在一个索引中存储多种文档类型,并为不同文档提供类型提供不同的映射。
7、分片(shards)
代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
8、副本(replicas)
代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当个某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
9、数据恢复(recovery)
代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
10、数据源(River)
代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的,river这个功能将会在后面的文件中重点说到。
11、网关(gateway)
代表es索引的持久化存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到硬盘。当这个es集群关闭再重新启动时就会从gateway中读取索引数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
12、自动发现(discovery.zen)
代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
13、通信(Transport)
代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。
14、分片和复制(shards and replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点可能没有这样大的磁盘空间来存储或者单个节点处理搜索请求,响应会太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多片的能力,这些片叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引” 可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量
- 允许你在分片(位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生。在某个分片/节点因为某些原因处于离线状态或者消失的情况下,故障转移机制是非常有用且强烈推荐的。为此, Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,复制提供了高可用性。复制分片不与原/主要分片置于同一节点上是非常重要的。因为搜索可以在所有的复制上并行运行,复制可以扩展你的搜索量/吞吐量
- 每个索引可以被分成多个分片。一个索引也可以被复制0次(即没有复制) 或多次。一旦复制了,每个索引就有了主分片(作为复制源的分片)和复制分片(主分片的拷贝)。
- 分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你不能再改变分片的数量。
二)elasticsearch集群角色
https://www.cnblogs.com/sunfie/p/9598464.html
在生产环境下,elasticsearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题。
集群默认是拥有所有角色,每个节点都有称为主节点的资格。
详情见官网:https://www.elastic.co/guide/en/elasticsearch/reference/6.4/modules-node.html
不同角色对服务器配置的要求
- master节点:普通服务器即可(CPU、内存消耗一般)
- data节点:主要消耗磁盘和内存
- client节点:普通服务器(内存多点)
ES2.x及之前与ES5.x之后的差异:详见 https://blog.csdn.net/laoyang360/article/details/78290484
5.x之后添加了ingest角色
1、master节点
让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调器
master负责结果聚合等工作,压力较大 所以不建议节点同时为master和data
主要负责集群中索引的创建、删除以及数据的Rebalance等操作。Master不负责数据的索引和检索,所以负载较轻。当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。为了防止脑裂,常常设置参数为discovery.zen.minimum_master_nodes=N/2+1,其中N为集群中Master节点的个数。建议集群中Master节点的个数为奇数个,如3个或者5个
node.master: true node.data: false node.ingest: false search.remote.connect: false
- The node.master role is enabled by default.
- Disable the node.data role (enabled by default).
- Disable the node.ingest role (enabled by default).
- Disable cross-cluster search (enabled by default).
2、data节点
如果你想让节点从不选举为主节点,只用来存储数据,可作为负载器
主要负责集群中数据的索引和检索,一般压力比较大。建议和Master节点分开,避免因为Data Node节点出问题影响到Master节点。
node.master: false node.data: true node.ingest: false search.remote.connect: false
- Disable the node.master role (enabled by default).
- The node.data role is enabled by default.
- Disable the node.ingest role (enabled by default).
- Disable cross-cluster search (enabled by default).
3、ingest 节点:搜索器
如果想让节点既不称为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等
Ingest node专门对索引的文档做预处理,实际中不常用,除非文档在索引之前有大量的预处理工作需要做。
node.master: false node.data: false node.ingest: true search.remote.connect: false
- Disable the node.master role (enabled by default).
- Disable the node.data role (enabled by default).
- The node.ingest role is enabled by default.
- Disable cross-cluster search (enabled by default).
ingest的用途:
- ingest节点和集群中的其他节点一样,但是他能够创建多个处理管道,用以修改传入文档。类似logstash过滤器已被实现为处理器
- ingest节点 可用于执行常见的数据转换和丰富。处理器配置为形成管道。在写入时,ingest node有20个内置处理器,grok,data,gsub,小写/大写,删除和重命名。
- 在批量请求或索引操作之前,ingest节点拦截请求,并对文档进行处理。
ingest官网文档:https://www.elastic.co/guide/en/beats/filebeat/current/configuring-ingest-node.html
4、Coordinating only 节点:协调器
client的node.master和node.data都是false,作用类似于Nginx的请求转发
作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
node.master: false node.data: false node.ingest: false search.remote.connect: false
- Disable the node.master role (enabled by default).
- Disable the node.data role (enabled by default).
- Disable the node.ingest role (enabled by default).
- Disable cross-cluster search (enabled by default).
二、Elasticsearch集群部署
1、elasticsearch6与7的区别
https://www.jianshu.com/p/385ec5d35358?hmsr=toutiao.io&utm_medium=toutiao.io&utm_source=toutiao.io
2、elasticsearch集群管理:
https://www.cnblogs.com/leeSmall/p/9220535.html
三、elasticsearch性能优化
一)elasticsearch查询慢排查思路和优化
https://cloud.tencent.com/developer/article/1357698
二)影响elasticsearch性能
软硬件选型:https://blog.csdn.net/thomas0yang/article/details/55518105
https://www.cnblogs.com/cutd/p/5800795.html
- 软件层
- 索引
- 分词器
- segment数量
- 分片数量
- 索引
一个分片的底层即为一个Lucene索引,会消耗一定文件句柄、内存、以及CPU运转;
每一个搜索请求都需要索引中的每一个分片,若每一个分片都处于不同的节点还好,但若多个分片都需要在同一节点上竞争相同的资源就糟糕了;
用于计算相关度的词项统计信息都是基于分片的。若有许多分片,每一个都只有很少的数据会导致很低的相关度
-
-
- 多:打开过多的文件,会导致交互多(一般都设置分片数量不超过节点数的3倍)
- 少:会导致单个分片过大(单个分片不超过32G,就会有性能下降的现象;30-50G影响较大)
- 节点数≤主分片数*(副本数+1)
- 副本数量:副本太多,性能会下降
- 选择Linux操作系统(系统做出相应的优化:尤其是文件描述符)
-
- 硬件
- 内存:单实例32G
- 硬盘:尽量大,RAID10、SSD(IO)
- 使用SSD作为存储设备
- 使用本地存储,避免使用NFS或者SMB
- 注意使用虚拟存储,比如亚马逊的EBS
- CPU:配置尽量高(对es影响比较大的)
- 网络:千兆,最好是万兆
1、索引方面
max_num_segments:段数优化,可设置值最小为1,这个值越小,查询速度越快(通常设置为1)
only_expunge_deletes:该优化操作是否可清空打有删除标签的索引记录(通常设置为false)
flush:在执行完操作之后,再执行刷线操作。默认值为true
wait_for_merge:当该参数设置为true时,表示其他请求操作要等到合并sgement操作结束之后,再进行响应。(通常设置为false)
2、分片数量
官网:https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
1)分片数量的设定
- Elasticsearch究竟要设置多少分片数:https://mp.weixin.qq.com/s/mKL2PJuNUJTl71Axv4-Rcw
- 设置标准:尽量设置多个分片,若节点数有限可以做数据的冷热分离
- 热数据存在elasticsearch中,冷数据存储在hdfs中
2)推迟分片分配
对于节点瞬时终端的问题,默认情况,集群会等待一分钟查看节点是否会重新加入,若这个节点此期间重新加入,重新加入的节点会保持其现有的分片数据,不会触发新的分片分配。这样就减少ES再自动分片时所带来的极大开销。
通过修改参数delayed_timeout,可以延长再均衡的实践,可以全局设置也可以在索引级别进行修改
PUT /_all/_settings { "settings": { "index,unassigned.node_left.delayed_timeout": "5m" } }
3、路由选择
当我们查询文档时,Elasticsearch如何知道一个文档应该存放到哪个分片中呢?他其实通过下面公式计算出来
shard = hash(routing) % number_of_primary_shards
routing默认值是文档的id,也可以采用自定义值,比如用户id
1)不带routing查询
在查询时,因为不知道要查询的数据具体在哪个分片上,所以整个过程分为2个步骤
- 分片:请求到达协调节点后,协调节点将查询请求分发到每个分片上
- 聚合:协调节点搜集到每个分片上查询结果,在查询结果进行排序,之后给用户返回结果
2)带routing查询
查询时,可以直接根据routing信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序
像上面自定义的用户查询,若routing设置userid的话,就可以直接查询出数据来,效率提升很多
4、写入速度优化
ES的默认配置,是综合了数据可靠性、写入速度、搜索实时性等因素。实际使用时,我们需要根据公司要求,进行偏向性优化。
针对搜索性要求不高,但是写入要求较高的场景,需要尽可能的选择其恰当写优化策略。可以考虑一下几个方面提升写索引的性能
- 加大Translog Flush,目的降低IOPS,writeblock
如果没有用 fsync 把数据从文件系统缓存刷(flush)到硬盘,我们不能保证数据在断电甚至是程序正常退出之后依然存在。为了保证 Elasticsearch 的可靠性,需要确保数据变化被持久化到磁盘。
在动态更新索引,我们说一次完整的提交会将段刷到磁盘,并写入一个包含所有段列表的提交点。Elasticsearch 在启动或重新打开一个索引的过程中使用这个提交点来判断哪些段隶属于当前分片。
即使通过每秒刷新(refresh)实现了近实时搜索,我们仍然需要经常进行完整提交来确保能从失败中恢复。但在两次提交之间发生变化的文档怎么办?我们也不希望丢失掉这些数据。
Elasticsearch 增加了一个 translog ,或者叫事务日志,在每一次对 Elasticsearch 进行操作时均进行了日志记录。
一个文档被索引之后,就会被添加到内存缓冲区,并且追加到了 translog ,正如 Figure 21, “新的文档被添加到内存缓冲区并且被追加到了事务日志” 描述的一样。
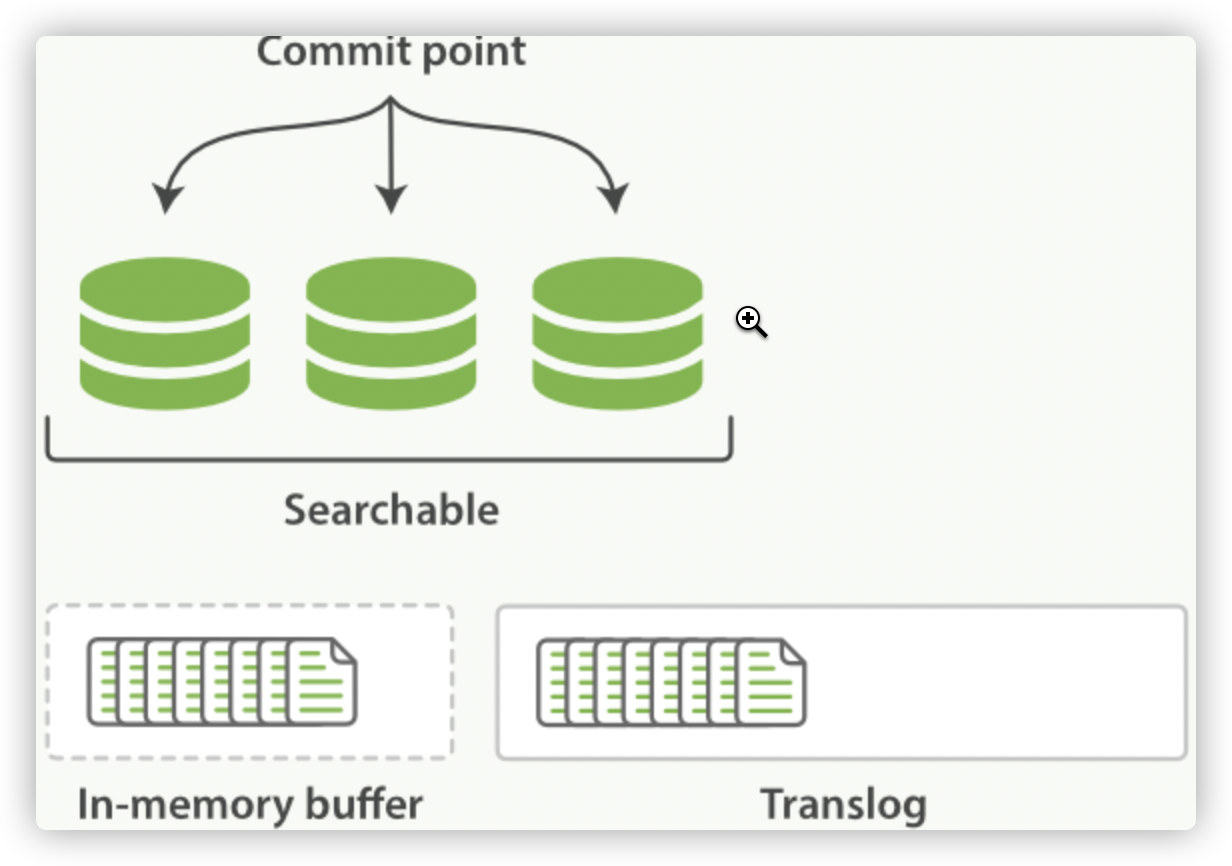
Figure 21. 新的文档被添加到内存缓冲区并且被追加到了事务日志
- 增加Index Fefresh间隔,目的是减少Segment Merge的次数
- 调整Bulk线程池和队列
- 优化节点间的任务分布
- 优化Luence层的索引建立,目的是降低CPU及IO :http://blog.sciencenet.cn/blog-3134052-1074737.html
1)批量数据提交
ES提供了Bulk API支持批量操作,当我们有大量的写任务时,可以使用Bulk来进行批量写入。
每个Elasticsearch节点内部都维护着多个线程池,如index、search、get、bulk等,用户可以修改线程池的类型和大小,线程池默认大小跟CPU逻辑一致
ES 提供了 Bulk API 支持批量操作,当我们有大量的写任务时,可以使用 Bulk 来进行批量写入。
通用的策略如下:Bulk 默认设置批量提交的数据量不能超过 100M。数据条数一般是根据文档的大小和服务器性能而定的,但是单次批处理的数据大小应从 5MB~15MB 逐渐增加,当性能没有提升时,把这个数据量作为最大值。
核心线程池
index:此线程池用于索引和删除操作。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为300。
search:此线程池用于搜索和计数请求。它的类型默认为fixed,size默认为可用处理器的数量乘以3,队列的size默认为1000。
suggest:此线程池用于建议器请求。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为1000。
get:此线程池用于实时的GET请求。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为1000。
bulk:此线程池用于批量操作。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为50。
percolate:此线程池用于预匹配器操作。它的类型默认为fixed,size默认为可用处理器的数量,队列的size默认为1000
修改线程池配置
1、elasticsearch.yml
threadpool.index.type: fixed
threadpool.index.size: 100
threadpool.index.queue_size: 500
2、Rest API
curl -XPUT 'localhost:9200/_cluster/settings' -d '{
"transient": {
"threadpool.index.type": "fixed",
"threadpool.index.size": 100,
"threadpool.index.queue_size": 500
}
}'
这个错误明显是默认大小为50的队列(queue)处理不过来了,解决方法是增大bulk队列的长度
threadpool.bulk.queue_size: 1000
2)优化存储设备
ES是一种密集使用磁盘的使用,在段合并时会频繁操作磁盘,所以对磁盘要求较高,当磁盘速度提升之后,集群的整体性能会大幅度提高。
3)合理使用合并
Luence以段的形式存储数据。当有新的数据写入索引时,Luence就会自动创建一个新的段。
随着数据量的变化,段的数量会越来越多,消耗的多文件句柄数及CPU就越多,查询效果就会下降。
由于Luence段合并的计算量庞大,会消耗大量的I/O,所以ES默认采用较保守的策略,让后台定期进行段合并。
http://blog.sciencenet.cn/blog-3134052-1074737.html
4)减少Refresh的次数
Luence在新增数据时,采用了延迟写入的策略,默认情况下索引的refresh_interval为1秒。
Luence将待写入的数据先写入到内存中,超过1秒(默认)时就会触发一次Refresh,然后Refresh会把内存中的数据刷新到操作系统文件缓存系统中。
若我们对搜索的实效性要求不高,可以将Refresh周期延长。这样还可以有效地减少段刷新此商户,但这同时意味着需要消耗更多的Heap内存。
5)加大Flush设置
Flush的主要目的是把文件缓存系统中的段持久化到硬盘,当Translog的数据量达到512MB或30分钟时,会触发一次Flush。
index.translog.flush_threshold_size 参数的默认值是512MB,,我们进行修改。增加参数意味着文件缓存系统中可能需要存储更多的数据,所以需要为操作系统的文件缓存系统留下足够的空间。
6)减少副本的数量
ES为了保证集群的可用性,提供了Replicas(副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以Replicas的数量会严重影响写索引的效率。
当写索引时,需要吧写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢。
若我们需要大批量进行写入操作,可以先禁止Relica复制,设置index.number_of_replicas: 0关闭副本。再写入完成后,Replicas修改回正常的状态。
5、内存的设置
ES堆内存的分配需要满足一下两个原则
- 不要超过物理内存的50%:Luence的设计目的是把底层OS里的数据缓存到内存中。
Luence的段分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。
若我们设置的堆内幕才能过大,Luence可用的内存将会减少,就会严重影响Luence的全文本查询性能。
- 堆内存的大小最好不要超过32GB:在Java中,所有对象都分配在堆中,然后有一个Klass Pointer指针指向它的类元数据。
64位操作系统,64位的指针意味着更大的消耗,因为你的指针本身大了。浪费内存不算,更糟糕的是,更大的指针在准内存和缓存器(LLC和L1等)之间移动数据的数据时,会占用更多的带宽。
最终都会采用最多设置31GB
-Xms 31g
-Xmx 31g
三)指定多个路径
1、 配置
官网:https://www.elastic.co/guide/en/elasticsearch/reference/6.3/path-settings.html
配置方式一:
path.data: /mnt/first,/mnt/second
配置方式二:
path:
data:
- /mnt/elasticsearch_1
- /mnt/elasticsearch_2
- /mnt/elasticsearch_3
2、数据如何存储
官网包括源码:https://elasticsearch.cn/question/753
ES多盘shard分配原理
假设现在单机环境中有两块磁盘,es的配置文件elasticsearch.yml中的path.data:/index/data,/data2/index/data
配置了两块盘,对应了两个路径。那么我现在要创建hrecord1索引的2个主shard分配原理如下:
首先会创建shard1(我估计ES会优先创建shard编号大的shard,但是影响不大),创建shard1的时候会找出两个路径对应的磁盘空间大的那个盘,然后将shard1放到那个路径下。
创建shard0的时候,会将/index和/data2磁盘的剩余可用空间相加,然后将这个总和乘以百分之五
将前面创建shard1的磁盘空间减去这个百分之五的值,然后再将这个差值与/data2磁盘剩余空间进行比较,找出磁盘空间大的,然后把shard0放到那个大的磁盘空间上。
四)output中elasticsearch输出的hosts写master节点还是data节点
output { elasticsearch { hosts => ["xxxx"] ---填写master节点还是data节点,有何影响
看规模情况,小集群无所谓了,大点的,尽量不要直接指向 master,尽量用 client node。(data node)
五)elasticsearch索引存储类型
基于文件系统的存储是默认索引存储方式。有不同的实现或存储类型。最好的一个操作系统的自动选择是:mmapfs使用在Windows的64bit系统上,simplefs使用在windows的32bit系统上,除此之外默认是用(hybrid niofs 和 mmapfs
http://www.openskill.cn/article/116
四、Elasticsearch的配置文件详解
默认情况下,Elasticsearch中的每个索引分配5个主分片和1个复制。
集群设置注意事项
https://blog.csdn.net/qq_36666651/article/details/81704717
配置文件主要有下面三个
1 elasticsearch/elasticsearch.yml 主配置文件 2 elasticsearch/jvm.options jvm参数配置文件 3 elasticsearch/log4j2.properties 日志配置文件
一)elasticsearch.yml配置
1、配置详解
整理部分来自:https://www.cnblogs.com/sunxucool/p/3799190.html
集群节点数较多时,可以根据需求设置角色
# 允许一个节点是否可以成为一个master节点,es是默认集群中的第一台机器为master,如果这台机器停止就会重新选举master. # node.master: true # 允许该节点存储数据(默认开启) # node.data: true # 配置文件中给出了三种配置高性能集群拓扑结构的模式,如下: # 1. 如果你想让节点从不选举为主节点,只用来存储数据,可作为负载器 # node.master: false # node.data: true # node.ingest: false # 2. 如果想让节点成为主节点,且不存储任何数据,并保有空闲资源,可作为协调器 # node.master: true # node.data: false # node.ingest: false # 3. 如果想让节点既不称为主节点,又不成为数据节点,那么可将他作为搜索器,从节点中获取数据,生成搜索结果等 # node.master: false # node.data: false # node.ingest: true (可不指定默认开启) # 4. 仅作为协调器 # node.master: false # node.data: false # node.ingest: false
常规配置
cluster.name: elasticsearch 配置es的集群名称,默认是elasticsearch,es会自动发现在同一网段下的es,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。 node.name: "Franz Kafka" 节点名,默认随机指定一个name列表中名字,该列表在es的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字。 node.master: true 指定该节点是否有资格被选举成为node,默认是true,es是默认集群中的第一台机器为master,如果这台机挂了就会重新选举master。 node.data: true 指定该节点是否存储索引数据,默认为true。 index.number_of_shards: 5 设置默认索引分片个数,默认为5片。 index.number_of_replicas: 1 设置默认索引副本个数,默认为1个副本。 path.conf: /path/to/conf 设置配置文件的存储路径,默认是es根目录下的config文件夹。 path.data: /path/to/data 设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开,例: path.data: /path/to/data1,/path/to/data2 path.work: /path/to/work 设置临时文件的存储路径,默认是es根目录下的work文件夹。 path.logs: /path/to/logs 设置日志文件的存储路径,默认是es根目录下的logs文件夹 path.plugins: /path/to/plugins 设置插件的存放路径,默认是es根目录下的plugins文件夹 bootstrap.mlockall: true 设置为true来锁住内存。因为当jvm开始swapping时es的效率 会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。 同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过`ulimit -l unlimited`命令。 network.bind_host: 192.168.0.1 设置绑定的ip地址,可以是ipv4或ipv6的,默认为0.0.0.0。 network.publish_host: 192.168.0.1 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址。 network.host: 192.168.0.1 这个参数是用来同时设置bind_host和publish_host上面两个参数。 transport.tcp.port: 9300 设置节点间交互的tcp端口,默认是9300。 transport.tcp.compress: true 设置是否压缩tcp传输时的数据,默认为false,不压缩。 http.port: 9200 设置对外服务的http端口,默认为9200。 http.max_content_length: 100mb 设置内容的最大容量,默认100mb http.enabled: false 是否使用http协议对外提供服务,默认为true,开启。 gateway.type: local gateway的类型,默认为local即为本地文件系统,可以设置为本地文件系统,分布式文件系统,hadoop的HDFS,和amazon的s3服务器,其它文件系统的设置方法下次再详细说。 gateway.recover_after_nodes: 1 设置集群中N个节点启动时进行数据恢复,默认为1。 gateway.recover_after_time: 5m 设置初始化数据恢复进程的超时时间,默认是5分钟。 gateway.expected_nodes: 2 设置这个集群中节点的数量,默认为2,一旦这N个节点启动,就会立即进行数据恢复。 cluster.routing.allocation.node_initial_primaries_recoveries: 4 初始化数据恢复时,并发恢复线程的个数,默认为4。 cluster.routing.allocation.node_concurrent_recoveries: 2 添加删除节点或负载均衡时并发恢复线程的个数,默认为4。 indices.recovery.max_size_per_sec: 0 设置数据恢复时限制的带宽,如入100mb,默认为0,即无限制。 indices.recovery.concurrent_streams: 5 设置这个参数来限制从其它分片恢复数据时最大同时打开并发流的个数,默认为5。 discovery.zen.minimum_master_nodes: 1 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4) discovery.zen.ping.timeout: 3s 设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。 discovery.zen.ping.multicast.enabled: false 设置是否打开多播发现节点,默认是true。 discovery.zen.ping.unicast.hosts: ["host1", "host2:port", "host3[portX-portY]"] 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
2、elasticsearch的配置文件范例:elasticsearch.yml
cluster.name: escluster #集群的名称,同一个集群该值必须设置成相同的 node.name: "es01" #该节点的名字 node.master: true #该节点有机会成为master节点 node.data: true #该节点可以存储数据 network.bind_host: 0.0.0.0 #设置绑定的IP地址,可以是IPV4或者IPV6 network.publish_host: 10.0.0.10 #设置其他节点与该节点交互的IP地址 network.host: 10.0.0.10 #该参数用于同时设置bind_host和publish_host transport.tcp.port: 9300 #设置节点之间交互的端口号 transport.tcp.compress: true #设置是否压缩tcp上交互传输的数据 http.port: 9200 #设置对外服务的http 端口号 http.max_content_length: 100mb #设置http内容的最大大小 http.enabled: true #是否开启http服务对外提供服务 path.data: /opt/data/es,/opt/nas/storage/es path.logs: /opt/logs/es discovery.zen.ping.unicast.hosts: ["10.0.0.10:9300","10.0.0.11:9300", "10.0.0.12:9300"] #设置集群中的Master
慢查询设置
index.search.slowlog.level: TRACE index.search.slowlog.threshold.query.warn: 10s index.search.slowlog.threshold.query.info: 5s index.search.slowlog.threshold.query.debug: 2s index.search.slowlog.threshold.query.trace: 500ms index.search.slowlog.threshold.fetch.warn: 1s index.search.slowlog.threshold.fetch.info: 800ms index.search.slowlog.threshold.fetch.debug:500ms index.search.slowlog.threshold.fetch.trace: 200ms
二)elasticsearch中设置JVM堆的大小
官网链接:https://www.elastic.co/guide/en/elasticsearch/reference/current/heap-size.html
默认情况下,Elasticsearch会告诉JVM使用的堆大小为2GB。当迁移产品,要确保为Elasticsearch配置的堆有足够的空间。
1、Elasticsearch 在jvm.options中指定了Xms(最小)和Xmx(最大)的堆的设置。所设置的值取决于你的服务器的可用内存大小。好的规则应满足:
- 最小堆的大小和最大堆的大小应该相等。
- Elasticsearch可获得越多的堆,并且内存也可以使用更多的缓存。但是需要注意,分配了太多的堆给你的项目,将会导致有长时间的垃圾搜集停留。
- 设置最大堆的值不能超过你物理内存的50%,要确保有足够多的物理内存来保证内核文件缓存。
- 不要将最大堆设置高于JVM用于压缩对象指针的截止值。确切的截止值是有变化,但接近32gb。您可以通过在日志中查找以下内容来验证您是否处于限制以下:
heap size [1.9gb], compressed ordinary object pointers [true]
- 最好尝试保持在基于零压缩oops的阈值以下;当确切的截止值在大多数时候处于26GB是安全的。但是在大多数系统中也可以等于30GB。在启动Elasticsearch之后,你也可以在JVM参数中验证这个限制-XX:+UnlockDiagnosticVMOptions -XX:+PrintCompressedOopsMode和查询类似于下面这一行:
heap address: 0x000000011be00000, size: 27648 MB, zero based Compressed Oops
显示基于零压缩oops有被下面的所代替:
heap address: 0x0000000118400000, size: 28672 MB, Compressed Oops with base: 0x00000001183ff000
2、这里的例子告诉我们如何在jvm.options文件中设置堆值:
-Xms2g #设置最小堆的值为2g
-Xmx2g #设置组大堆的值为2g
也可以通过环境变量来设置堆的值。这可以通过注释掉jvm.options文件中的xms和xmx设置来完成,并通过ES_JAVA_OPTS选择设置这些值:
ES_JAVA_OPTS="-Xms2g -Xmx2g" ./bin/elasticsearch #设置最小和最大堆的值为2g ES_JAVA_OPTS="-Xms4000m -Xmx4000m" ./bin/elasticsearch #设置最小和最大堆的值为 4000M
三)elasticsearch如何合理分配索引分片个数和副本的个数
分片数量设定:
- 预估索引的大小,最好30G一个分片;
- 分片数量是节点数量的1.5到3倍
https://blog.csdn.net/alan_liuyue/article/details/79585345
五、开启用户认证
es开启用户认证:https://www.jianshu.com/p/f53da7e6469c
elkstack开启用户认证:https://www.cnblogs.com/cjsblog/p/9501858.html
六、保留指定时间的索引
https://blog.csdn.net/qq_34896760/article/details/80425332
七、elasticsearch安装 IK Analyzer插件
https://blog.csdn.net/u011499747/article/details/78917718
https://www.cnblogs.com/ytkah/p/9908071.html
找到版本对应的插件进行安装即可
/usr/share/elasticsearch/bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v6.5.4/elasticsearch-analysis-pinyin-6.5.4.zip
安装完,重启服务。 (5.x版本需要修改配置文件)
八、Restful API
https://zhaoyanblog.com/archives/732.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号