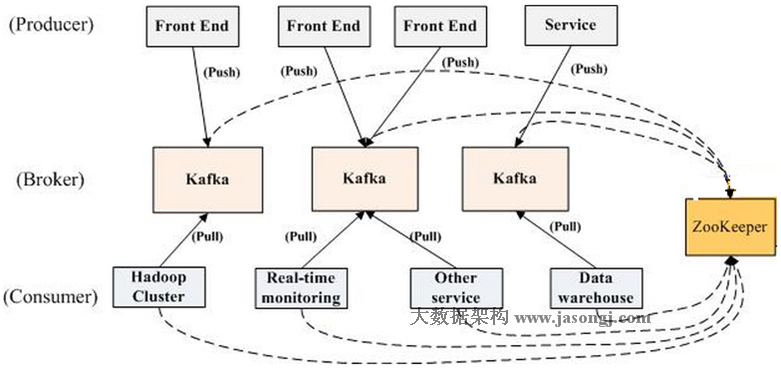
kafka术语
kafka 架构Terminology(术语)
- broker(代理)
- Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic
- 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic(可以理解为队列queue或者目录)。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处。
- Partition
- Parition是物理上的概念(可以理解为文件夹),每个Topic包含一个或多个Partition。
- Producer
- 生产者,负责发布消息到Kafka broker。
- Consumer
- 消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group
- 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Kafka拓扑结构
Topic & Partition
topic可以看成不同消息的类别或者信息流,不同的消息根据就是通过不同的topic进行分类或者汇总,然后producer将不同分类的消息发往不同的topic。对于每一个topic,kafka集群维护一个分区的日志:如图所示:
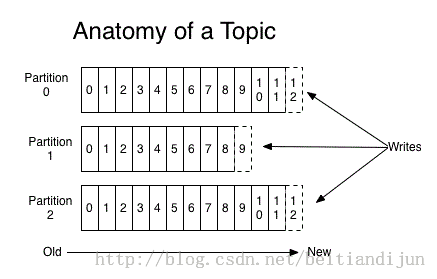
上图中可以看出,每个partition中的消息序列都是有序的,并且不可更改,这些分区可以在尾部不停的追加消息。同一分区中的不同消息都会分配一个唯一的数字进行标识,这个数字被称为offset,用来进行消息的区分,每一条消息都是由若干个字节构成。
kafka集群可以保存所有发布的消息---无论消息是否consumed,保存时间是可配置的。例如,如果日志保存时间设置为两天,则从日志保存之时开始,两天之内都是可供消费的,然而两天之后消息会被抛弃以释放空间。因此,Kafka可以高效持久的保存大量的数据。
事实上,每个消费者所需要保存的元数据只有一个,即”offset“,即主要用来记录日志中当前consume的位置。offset是由consumer所控制的: 通常情况下,offset会随着consumer阅读消息而线性的递增,好似offset只能被动跟随consumer阅读变化,但实际上,offset完全是由consumer控制的,consumer可以从任何它喜欢的位置consum消息。例如,consumer可以将offset重新设置为先前的值并重新consum数据。
这些特征共同说明: Kafka consumer可以很廉价的进行操作----在不必影响集群和其他consumers的情况下,consumers可以很自由的来去。例如,你可以使用kafka提供的命令行工具,去追踪任何topic的内容,而不必改变当前consumers 所consum的topic内容。
日志服务器中存在partitions有以下若干目的:
- 多个分区的共存可以使日志规模超过单个server的尺寸;需要注意的是,每一个单独的分区必须符合所在servers的尺寸,即同一个topic的同一个partition的数据只能在同一台server上存储,也就是说同一个topic下的同一个partition的数据不能同时存放于两台server上,但是同一个topic可以包含很多partitions,这样就使同一个topic可以包含任意数量的数据,理论上你可以通过增加server的数目来增加partitions的数目。
- 多个partitions的存在,可以作为数据并行处理的单位,而不是以bit为单位(既可以有多个consumers对不同的partition进行consume,也可以有不同的consumers对同一个partition进行consume,因为offset是由consumer控制的)。
参考:
http://www.aboutyun.com/thread-18894-1-1.html
http://www.aboutyun.com/thread-14732-1-1.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号