
区别:
1、Dictionary支持泛型,Hashtable不支持泛型,Hashtable的key和value都是object。
Dictionary 不需要进行类型转换,Hashtable在存储或检索值类型时通常会发生装箱和拆箱的操作,非常耗时。
2、Dictionary非线程安全,多线程必须人为使用 lock 语句进行保护。
多线程程序中推荐使用 Hashtable, 默认的 Hashtable 允许单线程写入,多线程读取。
对 Hashtable 进一步调用 Synchronized() 方法可以获得完全线程安全的类型。
3、Dictionary<K,V>在使用中是顺序存储的,而Hashtable由于使用的是哈希算法进行数据存储,是无序的。
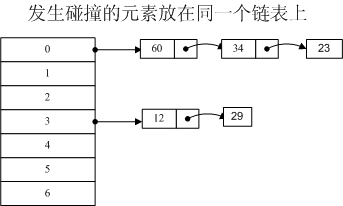
![]()
采用链表法的是Dic 采用开放寻址法(open addressing)-中 双重散列的方法的是 HashTable
引用自博客:https://www.cnblogs.com/jilodream/p/4219840.html
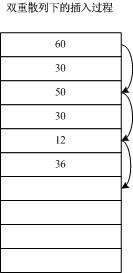
不建议使用
Hashtable类进行新的开发。 相反,我们建议使用泛型 Dictionary<TKey,TValue> 类。 有关详细信息,请参阅 GitHub 上 不应使用非泛型集合 。https://docs.microsoft.com/zh-cn/dotnet/api/system.collections.hashtable?view=net-5.0
常见数据结构
内存上连续存储,节约空间,可以索引访问,读取快,增删慢
Array:在内存上连续分配的,而且元素类型是一样的,可以坐标访问;读取快--增删慢,长度不变。
创建一个新的数组时将在 CLR 托管堆中分配一块连续的内存空间,来盛放数量为size,类型为所声明类型的数组元素。
如果类型为值类型,则将会有size个未装箱的该类型的值被创建。如果类型为引用类型,则将会有size个相应类型的引用被创建。
- ArrayList: 不定长的,连续分配的;元素没有类型限制,任何元素都是当成object处理,如果是值类型,会有装箱操作;读取快--增删慢。
ArrayList是System.Collections命名空间下的一部分,所以若要使用则必须引入System.Collections。
------------------------------------------------------------------------------- 关于扩容 -----------------------------------------------------------------------------
构造ArrayList的时候,默认初始化容量为10(这好像是java的初始化长度,c#好像是4,有时间跑个程序验证下,原理类似),当add第11个元素时,add方法中先调用ensureCapacity方法对原数组长度进行扩充,
扩充方式为,通过Arrays类的copyOf方法对原数组进行拷贝,长度为原数组的1.5倍+1。
然后把扩容后的新数组实例对象地址赋值给elementData引用类型变量。扩容完毕。
每一次的扩容代表着创建新数组对象,复制原有数据。
如果数据很大,那么有必要为集合初始化一个默认大小,防止多次扩容,但如果数据增长很慢,那么就会浪费内存,看实际应用场景。
文章详情:https://blog.csdn.net/javaoverflow/article/details/8952421?spm=1001.2014.3001.5501
转载出处:http://blog.csdn.net/thinking_in_android
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
- List: 也是Array,内存上都是连续摆放;不定长;泛型,保证类型安全,避免装箱拆箱;读取快--增删慢
和Array、ArrayList差异点:(1) 即确保了类型安全; (2) 也取消了装箱和拆箱的操作; (3) 它融合了Array可以快速访问的优点以及ArrayList长度可以灵活变化的优点。
list.Capacity 获取list分配的长度,list.Count 获取list的有效长度
list在新建表之后的初始长度为0,添加第一个元素之后会生成一个长度为4的表,也就是初始长度
每此添加数据的时候会判断是否超出表长,如果超出表长那么就新建一个list表(这个表的长度是原来表的二倍),
然后list表会把之前的表数据复制到新表中,指针指向了新的表,当前的表会变成内存垃圾等着cg回收
通过自定义表的长度,优化list来提高效率
文章详情:https://blog.csdn.net/main_hello/article/details/110954255
非连续摆放,存储数据+地址,找数据的话就只能顺序查找,读取慢;增删快
- 链表LinkedList:泛型;链表,元素不连续分配,每个元素都有记录前后节点;节点值可以重复;不能下标访问,找元素就只能遍历,查找慢;增删快
- 队列Queue:就是链表,先进先出;
- 栈Stack:就是链表 先进后出 解析表达式目录树的时候,先产生的数据后使用;操作记录为命令,撤销的时候是倒序的
Set 纯粹的集合,容器,唯一性
- HashSet:hash分布,元素间没关系,动态增加容量;去重。使用场景:统计用户IP--IP投票;交叉并补--二次好友/间接关注/粉丝合集
- SortedSet:排序的集合:去重 而且排序。使用场景:统计排名--每统计一个就丢进去集合
读取&增删都快? 有 hash散列 字典
- Hashtable key-value:体积可以动态增加 拿着key计算一个地址,然后放入key - value;object-装箱拆箱 ;浪费了空间,Hashtable是基于数组实现;查找个数据 一次定位; 增删 一次定位; 增删查改 都很快
- Dictionary字典:泛型;key - value,增删查改 都很快;有序的
- SortedDictionary 排序字典
- SortedList 排序集合
线程安全的几种数据结构
- ConcurrentQueue 线程安全版本的Queue
- ConcurrentStack线程安全版本的Stack
- ConcurrentBag线程安全的对象集合
- ConcurrentDictionary线程安全的Dictionary
- BlockingCollection

 浙公网安备 33010602011771号
浙公网安备 33010602011771号