
如何在Windows本地运行一个大语言模型
ChatGLM3 是智谱AI和清华大学 KEG 实验室联合发布的新一代对话预训练模型,可以在消费级显卡上轻松运行一个离线的对话机器人。
它功能强大,配置过程简单,对初学者比较友好。
本文记录了ChatGLM3的环境配置过程,希望能对跟我一样的新手朋友起到帮助。
准备工作:
以上步骤比较简单,而且你的电脑上可能已经具备,就不作介绍了。
接下来介绍以下步骤:
- 安装CUDA
- 安装CUDNN
- 安装Pytorch
- 下载并运行ChatGLM3
一、安装CUDA
CUDA(Compute Unified Device Architecture)是由NVIDIA推出的并行计算平台和编程模型,用于利用GPU进行通用目的的并行计算。
它允许开发人员使用C/C++、Fortran、Python等编程语言在NVIDIA GPU上编写并行程序,加速计算任务。
它是我们调用GPU能力的基础。
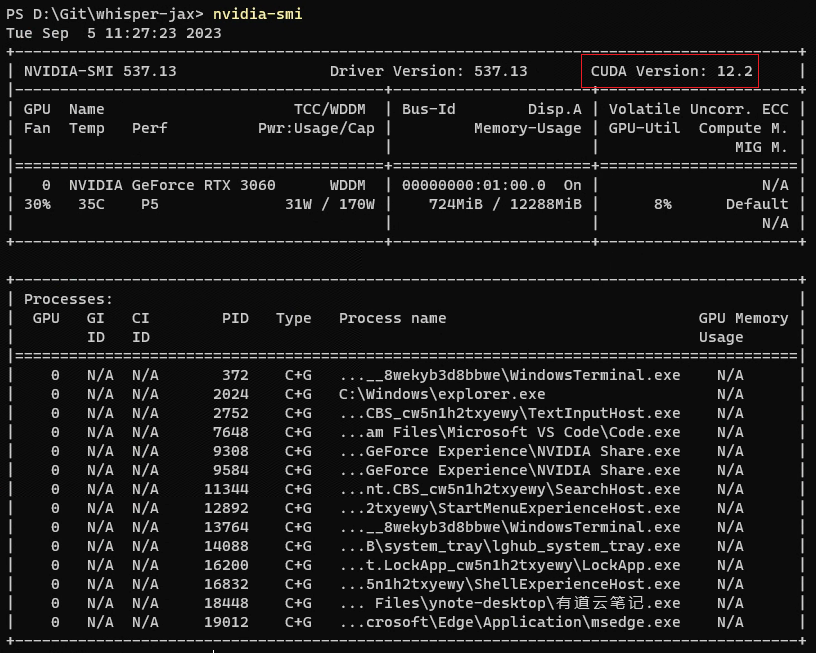
先查看显卡支持的最高CUDA版本
命令行输入 nvidia-smi ,确认显卡最高支持的版本,例如 cuda 12.x
CUDA安装
这里建议安装11.8
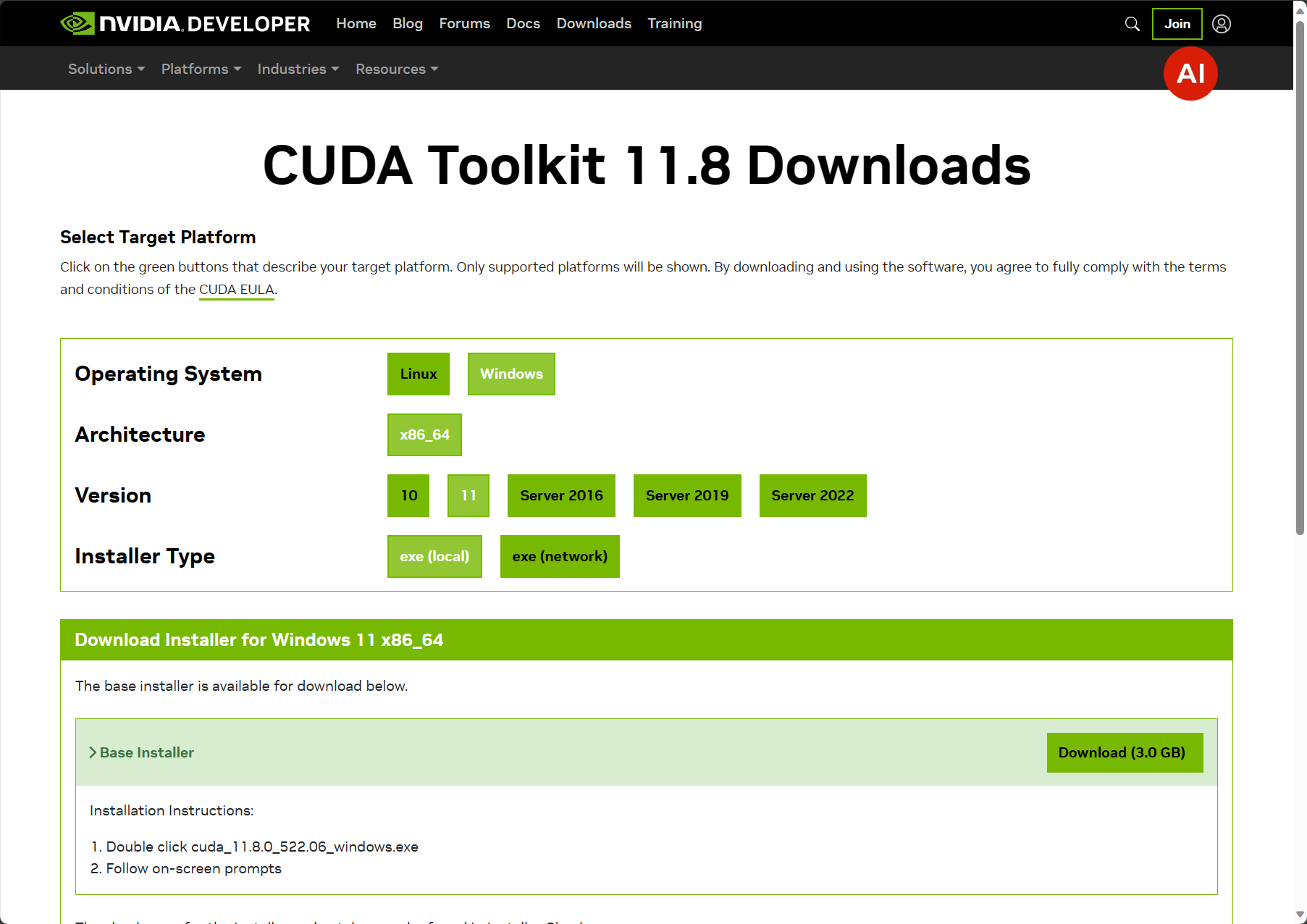
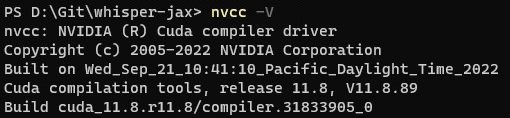
下载安装包,安装完毕后用 nvcc-V 查看CUDA版本,能显示版本号说明安装成功。
二、安装CUDNN
CuDNN(CUDA Deep Neural Network library)是NVIDIA针对深度神经网络(DNN)开发的加速库。
它提供了针对深度学习任务的高度优化的GPU加速计算操作,包括卷积神经网络(CNN)和循环神经网络(RNN)等。
CuDNN为深度学习框架提供了基础性的加速支持。
它是依赖于CUDA的,所以我们在安装CUDA之后再才安装它。
选择与CUDA相匹配的版本下载,CUDA 11.8 对应 CuDNN 8.6
解压后把lib、bin、include等3个目录拷贝到CUDA的安装目录下,并把这3个目录和添加到环境变量中
三、安装PyTorch
PyTorch是一个开源的机器学习框架,由Facebook开发并维护。
它基于Python,提供了丰富的工具和库,用于构建和训练机器学习模型,尤其擅长处理深度神经网络。
PyTorch提供了易于使用的张量计算和自动微分功能,使得构建和训练神经网络变得更加灵活和高效。
它依赖CUDA和CuDNN,所以放在第三步安装。
访问该地址以生成安装命令:https://pytorch.org/get-started/locally/

在该页面选择适合自己的配置会自动生成相应的安装命令,以下是适合我电脑的命令:
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
验证安装成功的办法是进入python环境,import torch看是否报错,如果不报错且 torch.cuda.is_available() 结果为 True 则表示GPU可以在python中使用了。

四、下载并运行ChatGLM3
# 下载项目代码 git clone https://github.com/THUDM/ChatGLM3 # 切到demo目录 cd ChatGLM3/composite_demo # 创建conda环境 conda create -n glm3 python=3.10 # 切到conda环境 conda activate glm3 # 安装依赖 pip install -r requirements.txt # 安装Jupyter内核 ipython kernel install --name glm3 --user # 安装pytorch ## 如果没有Nvidia显卡,用下面这行命令,它会利用cpu来代替gpu工作,但性能低且巨吃内存 pip install torch torchvision torchaudio ## 如果有Nvidia显卡,用下面这行命令 ## 在前面的第三步,我们已经安装过pytorch,但那是安装在全局环境,这里安装在conda中我们新建的glm3环境中 pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118 # 启动dmeo(第一次启动会自动下载模型,耗时较长) streamlit run main.py # 一般来说,下载模型会失败,需要给命令行设置科学代理 # 如果你已经在本机启动了科学代理,把1087换成你的科学代理的端口号然后执行以下命令 set http_proxy=http://localhost:1087 set https_proxy=http://localhost:1087 # 然后再尝试执行上面的启动demo命令,直到启动成功为止
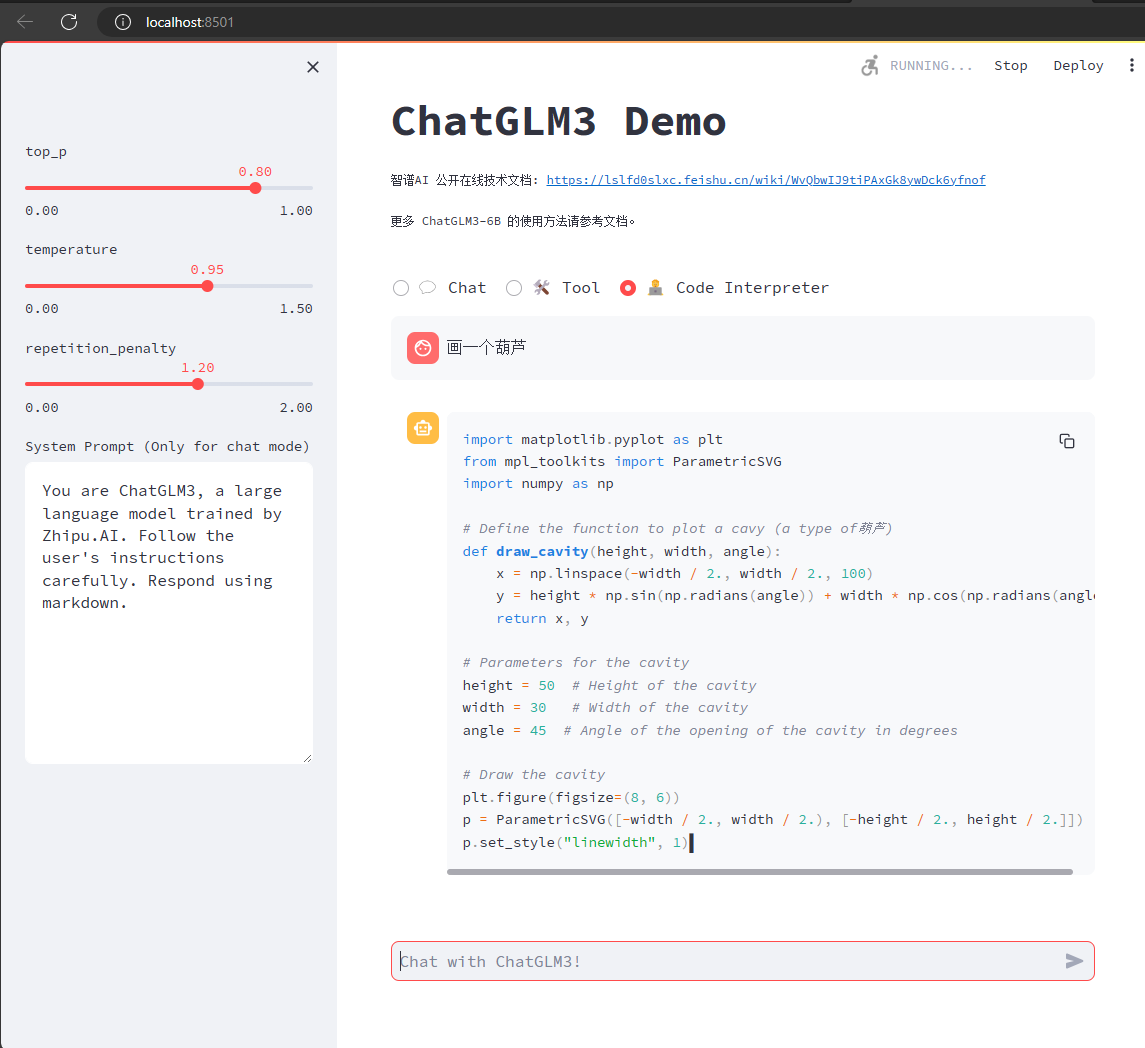
启动demo成功后的运行效果如下:
可以看到,模型跑起来之后,CPU、GPU和内存的占用并不高,但是12G显存一直是占满状态。

关于ChatGLM3的更多文档,可以参考项目首页 https://github.com/THUDM/ChatGLM3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号