Spark Java API 计算 Levenshtein 距离
Spark Java API 计算 Levenshtein 距离
在上一篇文章中,完成了Spark开发环境的搭建,最终的目标是对用户昵称信息做聚类分析,找出违规的昵称。聚类分析需要一个距离,用来衡量两个昵称之间的相似度。这里采用levenshtein距离。现在就来开始第一个小目标,用Spark JAVA API 计算字符串之间的Levenshtein距离。
1. 数据准备
样本数据如下:
{"name":"Michael", "nick":"Mich","age":50}
把数据保存成文件并上传到hdfs上:./bin/hdfs dfs -put levestein.json /user/panda
2. 代码实现
定义一个类表示样本数据:
public static class User{
private String name;
private String nick;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getNick() {
return nick;
}
public void setNick(String nick) {
this.nick = nick;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
创建SparkSession
SparkSession sparkSession = SparkSession.builder()
.appName("levenshtein example")
.master("spark://172.25.129.170:7077")
.config("spark.some.config.option", "some-value")
.getOrCreate();
在Spark命令行./bin/pyspark 启动Spark时,会默认创建一个名称为 spark 的SparkSession。而这里是写代码,也需要创建SparkSession对象。
The SparkSession instance is the way Spark executes user-defined
manipulations across the cluster. There is a one-to-one correspondence between a SparkSession and
a Spark Application.
定义数据类型
Encoder<User> userEncoder = Encoders.bean(User.class);
JAVA里面定义了一套数据类型,比如java.util.String是字符串类型;类似地,Spark也有自己的数据类型,因此Encoder就定义了如何将Java对象映射成Spark里面的对象。
Used to convert a JVM object of type
Tto and from the internal Spark SQL representation.To efficiently support domain-specific objects, an
Encoderis required. The encoder maps the domain specific typeTto Spark's internal type system. For example, given a classPersonwith two fields,name(string) andage(int), an encoder is used to tell Spark to generate code at runtime to serialize thePersonobject into a binary structure. This binary structure often has much lower memory footprint as well as are optimized for efficiency in data processing (e.g. in a columnar format). To understand the internal binary representation for data, use theschemafunction.
构建Dataset:
Dataset<User> userDataset = sparkSession.read().json(path).as(userEncoder);
说明一下Dataset与DataFrame区别,Dataset是针对Scala和JAVA特有的。Dataset是有类型的,Dataset的每一行是某种类型的数据,比如上面的User类型。
A Dataset is a strongly typed collection of domain-specific objects that can be transformed in parallel using functional or relational operations. Each Dataset also has an untyped view called a
DataFrame, which is a Dataset ofRow.
而DataFrame的每一行的类型是Row(看官方文档,我就这样理解了,哈哈。。)
DataFrame is represented by a Dataset of
Row。While, in Java API, users need to useDataset<Row>to represent aDataFrame.
这个图就很好地解释了DataFrame和Dataset的区别。
计算levenshtein距离,将之 transform 成一个新DataFrame中:
Column lev_res = functions.levenshtein(userDataset.col("name"), userDataset.col("nick"));
Dataset<Row> leveDataFrame = userDataset.withColumn("distance", lev_res);
完整代码
import org.apache.spark.sql.*;
public class LevenstenDistance {
public static class User{
private String name;
private String nick;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getNick() {
return nick;
}
public void setNick(String nick) {
this.nick = nick;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder()
.appName("levenshtein example")
.master("spark://172.25.129.170:7077")
.config("spark.some.config.option", "some-value")
.getOrCreate();
String path = "hdfs://172.25.129.170:9000/user/panda/levestein.json";
Encoder<User> userEncoder = Encoders.bean(User.class);
Dataset<User> userDataset = sparkSession.read().json(path).as(userEncoder);
userDataset.show();
Column lev_res = functions.levenshtein(userDataset.col("name"), userDataset.col("nick"));
Dataset<Row> leveDataFrame = userDataset.withColumn("distance", lev_res);
// userDataset.show();
leveDataFrame.show();
System.out.println(lev_res.toString());
}
}
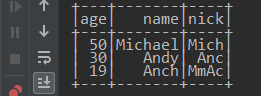
原来的Dataset:
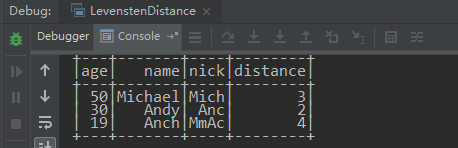
计算Levenshtein距离后的得到的DataFrame:
根据上面的示例,下面来演示一下一个更实际点的例子:计算昵称和签名之间的levenshtein距离,若levenshtein距离相同,就代表该用户的 昵称 和 签名 是相同的:
数据格式如下:
{"nick":"赖求","uid":123456}
-
加载数据
Dataset<Row> dataset = spark.read().format("json") .option("header", "false") .load("hdfs://172.25.129.170:9000/user/panda/profile_noempty.json");
-
取出昵称和签名
//空字符串 与 null 是不同的 Dataset<Row> nickSign = dataset.filter(col("nick").isNotNull()) .filter(col("signature").isNotNull()) .select(col("nick"), col("signature"), col("uid"));
-
计算昵称和签名的Levenshtein距离
Column lev_distance = functions.levenshtein(nickSign.col("nick"), nickSign.col("signature")); Dataset<Row> nickSignDistance = nickSign.withColumn("distance", lev_distance);
-
按距离进行过滤
Dataset<Row> sameNickSign = nickSignDistance.filter("distance = 0");
这样就能找出昵称和签名完全一样的用户了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号