索引构建
背景
面向C端用户的在线核心搜索系统底层采用ES作为核心“存储/检索”引擎,搜索作为用户购买决策的核心链路的一部分,对系统的可靠性要求tp9999,对查询性能要求极高(召回+排序 300ms以内)。如何搭建一套这样系统稳定、性能可靠的搜索系统呢?
索引构建
索引构建流程图如下:

- 各类业务数据存储在自己的 MySQL 表,业务表会同步到 Hive 数仓(Hive数据仓库分层),可经过一些清洗处理,生成业务数据 Hive 底表
- 每类业务数据有自己的 Hive 底表,通过 Hive join 各类业务表中需要支持检索的字段,生成ES的Hive数据底表
- Hive底表同步到 HBase 中,采用的是 HBase 的 bulkload 功能,直接生成 HFile 文件,写入时不会经过 memory table。此外,由于 HBase是列式数据库,因此能够非常方便地解决:新增字段需要支持检索的问题。
- Spark读取 HBase 中的数据,构建ES索引文件(lucene索引文件)。在开始构建索引时,记录索引构建时间点。在spark节点服务上,创建一个ES服务,执行索引构建逻辑,创建2个索引,一个是离线索引、一个增量索引。离线索引是 T+1 的离线全量数据,增量索引则是:在索引构建开始时,到索引构建完成这段时间内的增量数据。索引构建完成后,变更的数据也会更新到增量索引中。
- 将生成的索引文件压缩上传到S3对象存储
- 索引加载服务从S3上下载索引文件,并基于自定义的ES插件,读取索引文件,加载到ES集群
- 做一些段合并、预热等操作preload-data-to-file-system-cache,完成索引的加载,并进行副本分配。当本集群的ES节点的分片全部就绪后,为当前集群开流量,并摘除另一个"对等"备份集群的流量,开始构建另一个集群的索引
一些索引字段:
商品的spu名称、商品spu_id---商品团队的商品表
商家店铺名称、商家id---商家团队的商家表
商品spu的库存、近30天的销量---交易团队的销售表
商品spu_id的商家录入类目(一、二、三、四级类目)以及算法预测类目---算法团队产出的表
商品spu的活动标签、券标签等各种营销活动标签---营销团队的业务表
商品spu可配送区域id---基础信息表
好处:
- 新增的字段接入搜索非常方便
- 基于spark分布式计算来构建索引,可以构建很大量级的索引。在底层spark节点上启动一个ES进程(ES安装包已经部署到节点上),然后通过ES进程来构建分片。
- 采用离线索引+增量索引,可缓解更新索引doc对查询性能的影响。如果ES集群中只有一个索引,索引中各个字段的数据频繁更新势必影响查询性能,频繁更新带来的段文件数量不可控,会导致不可避免的查询抖动,详见ES 查询集群的稳定性优化。此外,索引中会有很多字段,有些更新频繁、有些更新不频繁,有些字段的数据重要、有些字段的不重要。只有一个索引很难满足所有的这些场景。比如:“近30天销量”是一天计算并更新一次、“商品spu可配送区域id”需要实时知道、“活动标签/券标签”可一天全量更新一次当前参与活动的spu_id,也需要接入实时的活动信息。因此,采用离线索引+增量实时索引方式能较好地兼顾各种需求下的字段变化。
- 相比于全部业务数据都放到一个索引的设计方式, 此方式也有更好地利用ES的page cache缓存
- 基于 spark 任务读取 HBase 中的全量数据构建索引,生成 lucene 索引文件这种索引生成方式,相比于:线上直接通过 restful api index document 减少了大量的网络开销和IO开销(写数据过程中还有写translog开销+merge开销)
- 在读取 HBase 数据生成索引分片时,能够使用更灵活的文档路由策略 ShardingStrategy,ES 默认的按 doc_id 哈希可能导致分片不均匀,可以根据全量数据(可以提前知道一些特征)自定义路由策略,从而确保分片“绝对”均匀
需要注意的地方:
ES查询非常依赖操作系统的缓存,ES节点每天都会加载一份最新的索引数据(每天构建一遍离线索引+增量索引,这些索引都可能被装载到内存中),ES节点通过定时任务每天更新索引时,可清除以前的缓存,避免生成的当天的索引在查询时没有足够的page cache而导致过多的内存换入、换出。比如构建20220104的索引时,01、02、03的索引已经过时,但有可能在内存中,而所有的查询只会查04的数据。
goods_index_20220101
goods_index_20220101_realtime
goods_index_20220102
goods_index_20220102_realtime
goods_index_20220103
goods_index_20220103_realtime
使用 HBase 做底层存储的问题
-
HBase 存储容量适合大规模的索引构建,这里也是基于 Spark 任务全量读取 HBase 上的索引数据构建索引。如果使用单机JVM进程构建全量索引,极有可能频繁 full gc
-
HBase 的列式数据库特性能够很好地支持动态添加字段的需求
-
基于搜索的其他业务需求可能需要扫描全量的ES索引中的数据,如果直接遍历ES,肯定会对线上搜索服务性能造成影响,为了避免直接遍历ES索引数据,因此需要:一张“基础索引表”。而从上面的索引构建的架构来看,HBase 中的数据与ES索引中的数据是实时同步的,因此可以作为索引基础表来使用。但是,由于 HBase 只能基于主键 row_key 进行查询,而在索引构建时,有时甚至对主键进行了“加盐”,只支持主键的“点查”,对大部分场景下的查询非常不友好。
比如根据行政区id过滤所有的不可配送的商品,对线上搜索流程而言,只能通过一个个的 query 请求召回商品,再走不可配送过滤逻辑。这相当于是从 query 角度获取“满足某些条件”的商品。这里的 query 角度是指:通过 query 来获取商品,而“条件”是指:商品在当前行政区下可配送。而实际上很多搜索需求,并不是从 query 角度获取商品的,比如 query 推荐中计算某一类商品的“候选推荐词”,如果“候选推荐词”召回的商品都是不可配送的,需要将此候选推荐词过滤掉,也需要用到“不可配送”逻辑的过滤。而这个过滤,如果通过走线上搜索流程过滤,就会影响用户的搜索主流程。一种比较好的方案是查询“基础索引表”,但是正如索引构建架构所示:这里的基础索引表是 HBase ,而 HBase 不支持二级索引,只支持基于 row_key 的点查,无法满足此要求。 -
使用 tidb 替代 HBase 存储全量索引数据。首先解决了 HBase 只支持 row_key 点查的问题,能够针对各类过滤条件进行查询(tidb 能够很好地支持二级索引),从而更灵活方便地支撑业务需求。比如:搜索过滤出某些活动标签、过滤不可配送的商品……能够基于商品的标签进行过滤了(不用查询ES,从而不影响线上搜索主流程)。此外,tidb 也是分布式存储系统,能够支撑大规模索引存储。最后,tidb 支持 online DDL 在线改表增加字段,不会导致大规模锁表,也能方便地在字段上添加二级索引。
-
对于离线索引的构建,需要读取全量的 tidb 数据,可借助 tispark 实现。借助于 tispark 以及 tidb,能够实现 T+0 数据查询,而且相比于 HBase,能够支持二级索引等各种条件的过滤,对业务开发非常友好。
增量索引构建
ES集群部署方式
- 单集群跨机房部署
只有一个ES集群,集群下不同ES节点部署在不同的机房,这样能做到跨机房容灾。但是对于线上要求较高的系统,机房之间的网络抖动很可能导致ES节点的不稳定,比如出现频繁选主,或者因心跳检测超时,master将某台data节点摘除而出现数据恢复,这对线上核心系统来说是不可接受的。 - 集群同机房部署,部署多集群
一个ES集群下的所有节点部署在同一个机房下,但是为了跨机房容灾,需要在同地域下的另一个机房再部署一个同样的ES集群。这样两个集群互为备份,从而做到跨机房容灾。部署2个ES集群,需要解决这2个集群中的数据是完全相同的,这样才能在一个机房的ES集群出现故障后,可切换到另一个机房的集群上。
集群内的节点都部署在同一个机房,机房内的网络比较稳定,这样能够保证ES节点非常稳定,避免网络抖动造成的集群不稳定。(线上核心服务一般都是同机房部署)
双集群部署也有利于日常的索引更新,即做到离线索引每天更新一次,增量索引可做到秒级内实时更新。相比于单集群,可以不停服务迁索引。当有 doc 更新时,从离线索引里面删除doc,并往增量索引里面插入新doc。当有新 doc 时,只会写增量索引。查询时,同时向离线索引和增量索引发起查询。 - 集群同机房部署,跨地域部署多集群
这种方式与第2种方式相同,只是在不同的城市/地域部署ES集群,一是跨地域容灾,另一个则是降低跨地域调用导致的网络延时(电商搜索)。
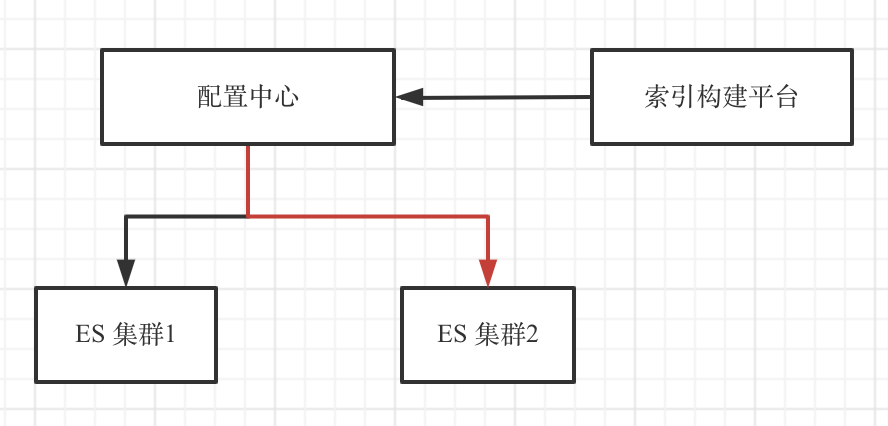
双集群部署,索引上线切流量示例图:
- 索引构建平台准备构建ES集群1的索引,将ES集群1的流量摘除。此时,线上只有ES集群2
- ES集群1的索引构建完毕,恢复集群1的流量
- 摘除ES集群2的流量,开始集群2的索引构建
- 集群2索引构建完毕,恢复流量,此时线上双集群同时在线
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号