ElasticSearch query_string vs multi_match cross_fields query
ElasticSearch query_string vs multi_match cross_fields query
本文记录以字段为中心的查询和以词为中心的查询这两种查询方式的区别以及在ElasticSearch中的实现接口,然后以ElasticSearch官方文档为参数资料,比较 query_string dismax 查询 和 multi_match cross_fields查询异同点。
以字段为中心 vs 以词为中心
当Client发起查询请求时,ES会计算查询字符串与文档之间的相关性,即计算一个得分,得分越高的文档与查询字符串越相关。单字段搜索这里不讨论,因为只有一个字段,针对这个字段计算出来的得分就是整个文档的得分。
而对于多字段搜索,因为有查询字符串,也有待查询的多个字段,此时得分有两种计算方案:
-
以字段为中心
基于ES的索引字段计算,比如索引中有2个字段:title、overview
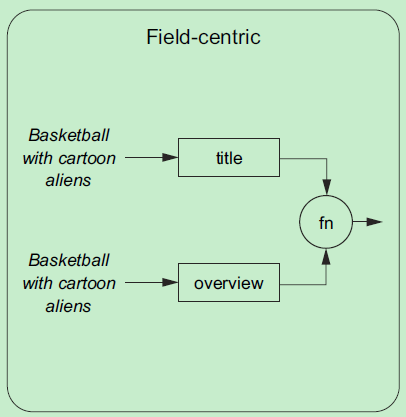
查询字符串"Basketball with cartoon aliens",Analyzer成一个个的term,"输入"到 title 字段,计算出一个得分\(S_{title}\),类似于,针对 overview 字段计算出一个得分\(S_{overview}\),将 \(S_{title}\)和\(S_{overview}\)按某种方式再组合成一个最终的得分\(S_{doc1}\),\(S_{doc1}\)就是文档doc1 关于 查询字符串"Basketball with cartoon aliens"的最终得分。ES索引中的每篇文档都按这种方式计算出得分:\(S_{doc2}\)、\(S_{doc3}\)……,对这些得分排序,返回TOP-N 文档。
这里的某种方式,可理解成Search Type,有三种:best_fields、most_fields、cross_fields
- best_fields

best_fields取 \(S_{title}\) 和 \(S_{overview}\)中的最大值,作为文档的最终得分\(S_{doc1}\)。
- most_fields
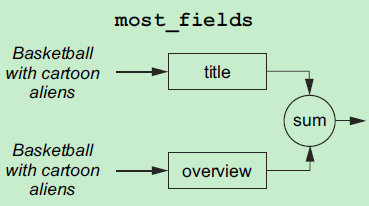
most_fields 将 \(S_{title}\)和\(S_{overview}\)二者的得分求和,作为文档的最终得分\(S_{doc1}\)。
到这里,还有一种情况:认为 title字段比overview字段重要,这既不符合best_fields那样由完全由\(S_{title}\)说了算(假设\(S_{title} > S_{overview}\))也不满足most_fields对 titile字段和overview字段完全平等对待的思路。于是,就引入了 tie_breaker 参数。
于是,文档得分就变成了如下计算公式:(假设还有额外两个字段:cast.name和directors.name)

ElasticSearch中mulit_match查询,默认采用best_fields方式计算得分。当 best_fields 满足不了要求时,可采用tie_break 进行一些微调。
-
cross_fields
multi_match 采用 cross_fields方式查询时,就是以词为中心的得分计算方式。
/** * Uses a blended DocumentFrequency to dynamically combine the queried * fields into a single field given the configured analysis is identical. * This type uses a tie-breaker to adjust the score based on remaining * matches per analyzed terms */ CROSS_FIELDS(MatchQuery.Type.BOOLEAN, 0.0f, new ParseField("cross_fields")),它也有一个tie_breaker参数来实现得分的”平衡“调节,从上面注释看:uses a tie-breaker to adjust the score based on remaining matches per analyzed terms。这里,不太明白cross_fields查询时,tie_breaker如何对各个 term 进行调节的(我的理解是,在使用multi_match cross fields 查询时,既然是以词为中心,当查询字符串analyze 成 一个个的term时,其中,肯定有一些term命中了mutli_match指定的所有字段,也有一些term只命中了部分字段,那么给term的打分就会不一样,而 tie_breaker 参数就是用来调节各个term得分权重的)。
-
以词为中心
对查询字符串Analyzer,分解成一个个的Term,基于Term计算得分。
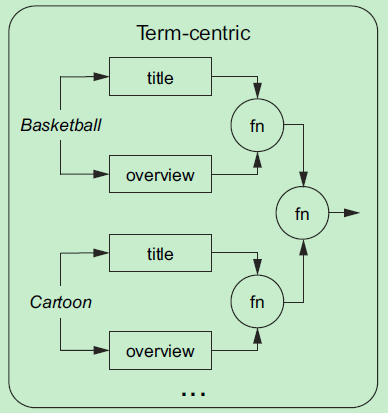
针对Term:Basketball,”输入“到各个字段中,计算出一个得分:\(S_{Basketball}\)、针对Term Cartoon,输入到各个字段中,计算出一个得分\(S_{Cartoon}\),然后再按某种方式组合成一个最终的得分\(S_{doc1}\)。
白象化问题
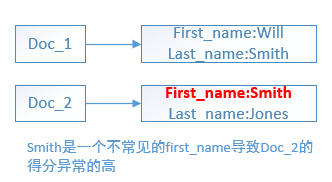
以TF-IDF计算term权重为例,有两个索引字段: first_name字段、last_name字段。当查询“Will Smith”时,由于 词 Will 是一个很常见的first_name,因此Will在first_name字段的得分会很低。同理,词Smith是一个很常见的last_name,因此Smith在last_name字段的得分也会很低。
假设有一篇文档的内容是:“Smith Jones”,其中Smith 在索引的first_name字段,Jones在索引的last_name字段。而根据人类起名字的习惯,很少有人把 词 Smith 作为first_name,而TF-IDF衡量词的权重时,倾向于给不常见的词赋予高权重,当词 Smith 出现在 first_name字段时,相应的文档得分就会异常的高。而现在刚好有个“奇葩”名字 "Smith Jones",Smith是first_name,因此,用户查询的是:“Will Smith”,但是返回的最佳匹配文档是:“Smith Jones”,没有匹配到 "Will" 这个词---这种针对多字段搜索的方式未完全匹配中用户的查询字符串。而这就是白象化问题。
query_string vs multi_match cross_fields 查询
这两种查询都是以词为中心的查询。
-
query_string
在查询字符串中可以指定 Operator(比如 OR 、AND)。因此这是一种更接近Lucene原生查询语法的查询。它查询时指定的操作符,因此不像 mulit_match cross_fields查询那样会为文档计算得分。
比如官网上给的示例:
GET /_search { "query": { "query_string" : { "default_field" : "content", "query" : "(new york city) OR (big apple)" } } }- 采用了 OR 运行符
- "new york city" 和 "big apple" 在进行query_string查询前先Analyze,至于采用何种Analyzer要视 content 字段的类型而定。如果content 字段的类型是 keyword 类型,那么"new york city" 会被Analyze成一个term:"new york city" 。如果content 字段的类型是 text 类型,那么默认采用Standard Analyzer,"new york city" 会被Analyze成三个term:"new "、"york "、"city"。
query_string 中的多字段查询:
基于dis_max查询实现,可采用tie_break 放大term 在某个字段中的影响。而dis_max查询其实是一种组合查询。见compound search
-
multi_match with cross_fields type
The
cross_fieldstype is particularly useful with structured documents where multiple fields **should **matchstructured Document:索引的文档有明确的字段定义,比如user profile 有昵称、签名 这样的字段。
如果用户的查询意图并不是针对某个具体的字段查询,用户不关注搜索内容出现在哪个字段,其查询意图倾向于对整篇文档的查询,cross_fields就比较合适。由于TF-IDF评分模型倾向于给词频较低的词高得分,cross_fields查询能缓解“白象化”问题。值得注意的是,multi_match with cross_fields 也有一个tie_breaker 参数微调评分。
ElasticSearch Multi_match 查询 JAVA API
基于ElasticSearch6.3.2 Rest High Level API。由于JAVA API变化很快,一般是基于下面四步:(模板方法模式)
- 构造QueryBuilder,比如MatchQueryBuilder、BoolQueryBuilder……
- 构造SearchSourceBuilder,指定分页参数
- 构造SearchRequest,指定索引名称、索引类型名称等参数
- 执行Search请求。
org.elasticsearch.client.RestHighLevelClient#search
在构造QueryBuilder的时候,对查询进行微调:
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keyword, fields);
//采用 MOST_FIELDS 方式查询
multiMatchQueryBuilder.type(MultiMatchQueryBuilder.Type.MOST_FIELDS);
若不确定QueryBuilder的写法,其实可以在debug的时候,查看QueryBuilder:
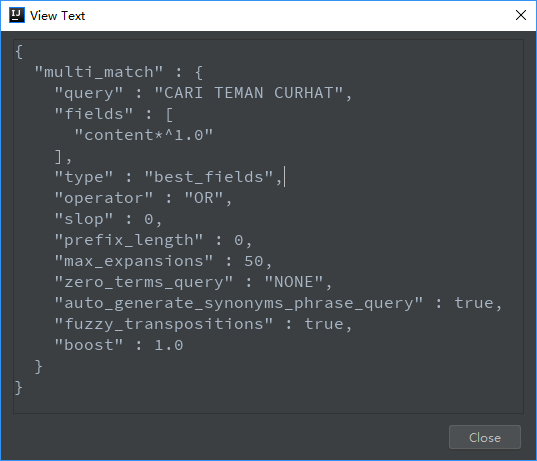
参考资料
- 《相关性搜索 利用solr与elasticsearch创建智能应用》
- multi-match-query
- query-string-query
- copy-to
- dis-max-query

 浙公网安备 33010602011771号
浙公网安备 33010602011771号