
Java SE(四)IO流
File类
概述
File类介绍:来自于java.io包
1.它是文件和目录路径名的抽象表示。
2.文件和目录是可以通过File封装成对象的。
3.对于File而言,其封装的并不是一个真正存在的文件,仅仅是一个路径名而已。这个路径名它可以是存在的,也可以是不存在的.将来是可以通过具体的操作把这个路径的内容转换为具体存在的。
路径:用于描述文件或者文件夹的所在位置的字符串。举例 : D:\0308系统班\day18\笔记
路径分类:
绝对路径:是一个完整的路径,从盘符开始。举例 : D:\0308系统班\Idea资料
相对路径:是一个简化的路径,相对当前项目下的路径。举例: a\b\ok.txt
idea中, 默认的路径: 当前项目工程根目录
File类型的构造方法
1、File(String path)://把字符串的路径,封装成一个File对象
2、File(String parent, String child)://将父级路径和子级路径封装成一个File对象,其实描述的是父级路径和子级路径拼接后的路径
3、File(File parent, String child)://将父级File对象路径和字节路径封装成一个File对象,其实描述的也是父级路径和子级路径拼接后的路径
import java.io.File;
public class Demo01_FileConstructor {
public static void main(String[] args) {
// 1. 创建出一个File类型对象 : 就表示一个文件或者一个文件夹
// 1) File(String path)
File f = new File("D:\\0308系统班");
System.out.println(f);// D:\0308系统班
// 2) File(String fu,String zi) : 将fu+zi拼接成一个完整的路径
File f1 = new File("D:\\0308系统班","day02");// D:\0308系统班\day02
System.out.println(f1);
// 3) File(File fu,String zi) : 将fu+zi拼接成一个完整的路径
File f2 = new File(f1,"笔记\\JAVASE_day02.docx");
System.out.println(f2);// D:\0308系统班\day02\笔记\JAVASE_day02.docx
}
}
File类型的创建方法
1、boolean createNewFile()://创建当前File对象所描述的路径的文件
2、boolean mkdir()://创建当前File对象所描述的路径的文件夹(如果父级路径不存在,那么不会自动创建父级路径)
3、boolean mkdirs()://创建当前File对象所描述的路径的文件夹(如果父级路径不存在,那么自动创建父级路径)
import java.io.File;
import java.io.IOException;
public class Demo02_FileCreate {
public static void main(String[] args) throws IOException {
// 1. 创建出一个File类型对象,表示文件
File f = new File("D:\\abc.txt");
// 2. 调用createNewFile() : 创建当前File对象所描述的路径的文件
// 注意 : 文件所在文件夹路径需要存在; 文件不存在
boolean boo = f.createNewFile();
System.out.println(boo);
// 3. 创建出一个File类对象, 表示一个文件夹
File f2 = new File("D:\\myDirectory");
// 4. mkdir() :创建当前File对象所描述的路径的文件夹
// (如果父级路径不存在,那么不会自动创建父级路径)
boolean boo1 = f2.mkdir();
System.out.println(boo1);
// 5. 一次性需要创建出多级文件夹
// mkdirs() : 创建当前File对象所描述的路径的文件夹
// (如果父级路径不存在,那么自动创建父级路径)
File f3 = new File("D:\\a\\b\\h\\myDirectory2");
boolean boo2 = f3.mkdirs();
System.out.println(boo2);
}
}
File类型的删除方法
1、
delete()://删除调用者描述的文件或者文件夹, 文件存在或者文件夹为空才能删除成功
2、注意事项:
-
delete在删除文件夹的时候,只能删除空文件夹, 是为了尽量保证安全性
-
delete方法不走回收站
import java.io.File;
public class Demo03_FileDelete {
public static void main(String[] args) {
// 1. 创建出一个存在的文件, 删除, 成功
File f = new File("D:\\abc.txt");
boolean boo = f.delete();
System.out.println(boo);
// 2. 创建出一个存在的,空的文件夹,删除, 成功
File f1 = new File("D:\\myDirectory");
System.out.println(f1.delete());
// 3. 创建出一个存在的, 非空文件夹, 删除, 失败
File f2 = new File("D:\\a");
System.out.println(f2.delete());
}
}
File类型常用的判断功能
1、exists()://判断当前调用者File对象所表示文件或者文件夹,是否真实存在, 存在返回true,不存在返回false
2、isFile()://判断当前调用者File对象,是否是文件
3、isDirectory()://判断当前调用者File对象,是否是文件夹
import java.io.File;
public class Demo04_FileCheck {
public static void main(String[] args) {
// idea中给出相对路径: 不带有盘符的路径
// 默认给提供的路径添加一个项目工程根目录作为完整路径
File f = new File("myFirstFile.txt");
System.out.println(f.exists());// true
System.out.println(f.isFile());// true
System.out.println(f.isDirectory());// fasle
System.out.println("-----------------");
File f1 = new File("D:\\a");
System.out.println(f1.exists());// true
System.out.println(f1.isFile());// false
System.out.println(f1.isDirectory());// true
File f2 = new File("Q:\\a");
System.out.println(f2.exists());// false
}
}
File类型的获取功能
1、String getAbsolutePath()://获取当前File对象的绝对路径
2、String getPath()://获取的就是在构造方法中封装的路径
3、String getName()://获取最底层的简单的文件或者文件夹名称(不包含所造目录的路径)
4、String[] list()://获取当前文件夹下的所有文件和文件夹的名称,到一个字符串数组中
5、File[] listFiles()://获取当前文件夹下的所有文件和文件夹的File对象,到一个File对象数组中
import java.io.File;
import java.util.Arrays;
public class Demo05_FileGet {
public static void main(String[] args) {
File f = new File("D:\\a");
// 1) String getAbsolutePath():获取当前File对象的绝对路径
String s = f.getAbsolutePath();
System.out.println(s);// D:\a
// D:\IdeaProjects\project\myFirstFile.txt
File f1 = new File("myFirstFile.txt");
System.out.println(f1.getAbsolutePath());
// 2) String getPath():获取的就是在构造方法中封装的路径
System.out.println(f.getPath());// D:\a
System.out.println(f1.getPath());// myFirstFile.txt
// 3) String getName():获取最底层的简单的文件或者文件夹名称(不包含所造目录的路径)
System.out.println(f.getName());// a
System.out.println(f1.getName());// myFirstFile.txt
// 4) String[] list():获取当前文件夹下的所有文件和文件夹的名称,到一个字符串数组中
File f2 = new File("D:\\0308系统班\\day01");
String[] sArr = f2.list();
System.out.println(Arrays.toString(sArr));
// 5) File[] listFiles():获取当前文件夹下的所有文件和文件夹的File对象,到一个File对象数
File[] fileArr = f2.listFiles();
System.out.println(Arrays.toString(fileArr));
}
}
IO流
1.IO流介绍:
I和O,分别是Input和Output两个单词的缩写,Input是输入,Output是输出。
流:是一种抽象概念,是对数据传输的总称.也就是说数据在设备间的传输称为流,流的本质是数据传输。
IO流就是用来处理设备间数据传输问题的。常见的应用: 文件复制、文件上传、 文件下载等。
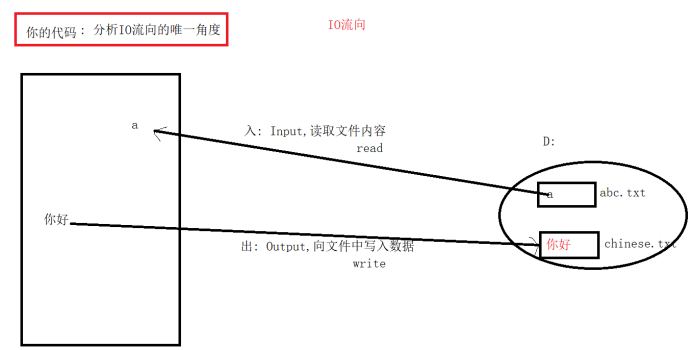
2.IO流分类:
按照数据的流向:
输入流:读数据
输出流:写数据
按照数据类型:
字节流:
字节输入流和字节输出流
字符流:
字符输入流和字符输出流
字节流和字符流的使用场景:
如果操作的是纯文本文件,优先使用字符流
如果操作的是图片、视频、音频等二进制文件,优先使用字节流
如果不确定文件类型,优先使用字节流.字节流是万能的流
3.IO流程序书写流程:
1、在操作之前,要导包,java.io包
2、在操作流对象的时候,要处理解决异常(IOException)
3、在操作完流对象之后,必须关闭资源, 所有流资源的关闭 close();
字节流
字节流抽象基类: 以字节读写文件
InputStream://这个抽象类是表示字节输入流的所有类的超类
OutputStream://这个抽象类是表示字节输出流的所有类的超类
根据交互设备的不同,有不同的具体子类
字节输入流FileInputStream
1、FileInputStream是InputStream一个具体子类,用于和磁盘上的文件进行交互
2、FileInputStream不仅可以一次读取一个字节,也可以一次读取很多个字节;不仅可以读取纯文本文件,也可以读取图片、视频、音频等非纯文本文件。一切数据在计算机中都是以字节的形式在存储和计算
3、构造方法:
FileInputStream(File f)://将一个File对象所表示的文件路径封装在一个字节输入流中,未来从文件中以字节方式读取文件内容
FileInputStream(String path)://将一个字符串所表示的文件路径封装在一个字节输入流中,未来从文件中以字节方式读取文件内容
注意事项:无论是哪个构造方法,都只能封装文件的路径,封装文件夹的路径没有任何意义,因为文件夹本身没有任何数据,所以也不能使用流对象读取数据
- 读取文件的方法:
int read()://从当前的字节输入流中,读取并返回一个字节,返回值结果int类型, 表示读取到的字节对应的整数结果, 如果返回-1表示证明文件读取完毕
int read(byte[] arr)://将最多arr.length个字节,读取到的字节放置到arr中,返回值结果int类型, 表示本次读取到的字节的个数, 如果读到-1,证明文件读取完毕
注意 : 数组读取效率远远优于单个字节读取效能
void close():关闭该流对象
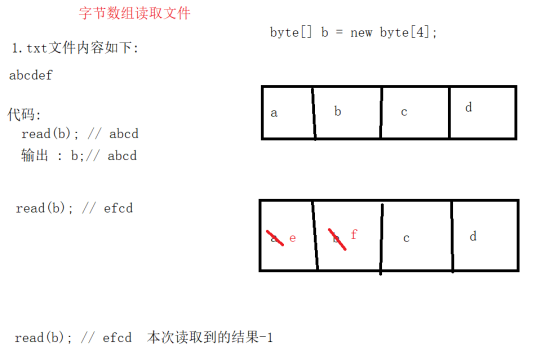
单个字节读取代码
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class Demo01_FileInputStream {
public static void main(String[] args) throws IOException {
// 1. 创建出一个字节输入流,绑定数据源
FileInputStream fis = new FileInputStream("D:\\a\\1.txt");
// FileInputStream fis2 = new FileInputStream(new File("D:\\a\\1.txt"));
//2. 读取文件:
/*int first = fis.read();
System.out.println(first + "--" + (char)first);// a
int second = fis.read();
System.out.println(second + "--" + (char)second);// b
int third = fis.read();
System.out.println(third + "--" + (char)third);// c
int four = fis.read();
System.out.println(four + "--" + (char)four);// d
int five = fis.read();
System.out.println(five + "--" + (char)five);// e
int six = fis.read();
System.out.println(six + "--" + (char)six);// f
int end = fis.read();
System.out.println(end + "--" + (char)end);// -1*/
// len表示每次读取到的字节的整数结果
int len;
while((len = fis.read()) != -1){
System.out.print((char)len);
}
// 使用完毕流资源资源关闭
fis.close();
}
}
字节数组读取文件
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Arrays;
public class Demo02_FileInputStreamReadArr {
public static void main(String[] args) throws IOException {
// 1. 创建出一个字节输入流, 绑定数据源
FileInputStream fis = new FileInputStream("D:\\a\\1.txt");
// 2. 定义出一个字节数组, 用于存储从文件中读取出的字节数据
// 注意 : 实际开发中, 通常数组大小设计成1024的倍数
// 1024 1024 * 4 1024 * 8
byte[] b = new byte[4];
// 3. 2)int read(byte[] arr):将最多arr.length个字节,
// 读取到的字节放置到arr中,返回值结果int类型,
// 表示本次读取到的字节的个数, 如果读到-1,证明文件读取完毕
//注意 : 数组读取效率远远优于单个字节读取效能
/*int i = fis.read(b);
System.out.println("读取到了"+i + "个字节");
System.out.println(new String(b));// abcd
int j = fis.read(b);
System.out.println("读取到了"+j + "个字节");
System.out.println(new String(b));// efcd
int z = fis.read(b);
System.out.println("读取到了"+z + "个字节");
System.out.println(new String(b));*/
// len表示每次读取到的字节的个数
int len;
while((len = fis.read(b)) != -1){
// 查看数组中内容,将字节数组转换成字符串
// 查看b数组中的内容,从0索引开始,查看len个字节
System.out.print(new String(b,0,len));
}
// 关闭资源
fis.close();
}
}
字节输出流FileOutputStream
-
说明:可以将字节数据写出到指定的文件中
-
构造方法:
FileOutputStream(File f)://将f描述的路径文件封装成字节输出流对象
FileOutputStream(String path)://将path描述的文件路径封装成字节输出流对象
FileOutputStream(String path,boolean append)://如果第二个参数为true,则字节将写入文件的末尾而不是开头
FileOutputStream(File path,boolean append)://如果第二个参数为true,则字节将写入文件的末尾而不是开头
- 字节流写数据的方式:
void write(int b): 将指定的字节写入此文件输出流一次写一个字节数据
void write(byte[] b): 将b.length字节从指定的字节数组写入此文件输出流
void write(byte[] b, int off, int len): 将len字节从指定的字节数组开始,从偏移量off开始写入此文件输出流
- 字节流写数据实现换行
windows:\r\n
linux:\n
mac:\r
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo03_FileOutputStream {
public static void main(String[] args) throws IOException {
// 1. 创建出一个字节的输出流, 绑定一个数据目的
FileOutputStream fos = new FileOutputStream("myFirstFile.txt");
// 2) write(int b): 将指定的字节写入此文件输出流一次写一个字节数据
fos.write(97);// a
// 3)write(byte[] b): 将b.length字节从指定的字节数组写入此文件输出流
byte[] b = {65,66,67,68};
fos.write(b);// ABCD
// 4) void write(byte[] b, int off, int len):
// // 将len个字节从指定的字节数组开始,从索引off开始写入此文件输出流
// 将b数组中从1索引位置开始, 写2个字节到文件中
fos.write(b,1,2);
// 5) 向文件中写入字符串
fos.write("今天天气阴,明天要下雨".getBytes());
// 关闭输出流资源 : 资源关闭之后, 不能使用
fos.close();
}
}
追加写入和加入回车换行代码
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo04_FileOutputStream2 {
public static void main(String[] args) throws IOException {
// 向文件中追加写入数据(从源文件末尾继续写)
FileOutputStream fos = new FileOutputStream("myFirstFile.txt",true);
// 向文件中接入一个回车换行
fos.write("\r\n".getBytes());
fos.write("我是后追加内容".getBytes());
fos.close();
}
}
文件复制
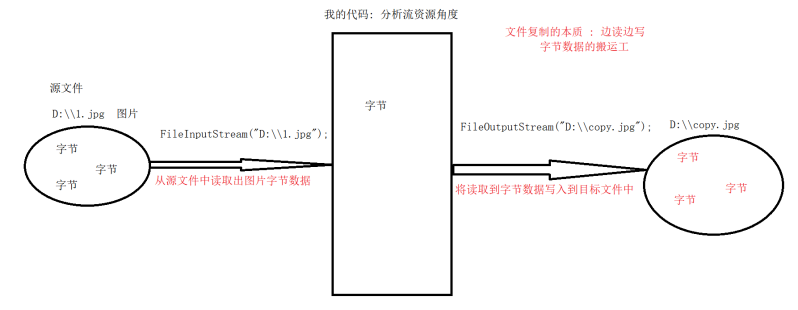
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo05_CopyPicture {
public static void main(String[] args) throws IOException {
// 1. 创建出一个字节输入流, 绑定一个数据源
FileInputStream fis = new FileInputStream("D:\\a\\图片1.png");
// 2. 创建出一个字节输出流, 绑定一个数据目的
FileOutputStream fos = new FileOutputStream("D:\\copy1.png");
// 3. 边读边写
// len表示每次读取到的字节对应的整数结果
long begin = System.currentTimeMillis();
int len;
while((len = fis.read()) != -1){
// 向目标文件中写入数据
fos.write(len);
}
long end = System.currentTimeMillis();
System.out.println(end - begin);// 453
// 4. 使用字节数组进行图片的复制,目的就是为了加快复制的效率
/* byte[] b = new byte[1024 * 4];
// len表示每次读取到的字节的个数
long begin = System.currentTimeMillis();
int len;
while((len = fis.read(b)) != -1){
// 特别在文件复制, 使用数组, 记得, 读到什么就写入什么
// 读到几个字节, 就写入几个字节
fos.write(b,0,len);
}
long end = System.currentTimeMillis();
System.out.println(end - begin);// 1*/
fos.close();
fis.close();
}
}
缓冲(高效)字节流
- 字节缓冲流介绍:
BufferedOutputStream://是OutputStream的子类, 表示高效字节输出流。流资源在创建对象时, 会在代码底层默认创建出一个大小为8192(1024 * 8)的字节数组, 提供数组缓冲区, 如何按照字节数组进行文件写, 那么效率高
BufferedInputStream://是InputStream的子类, 表示高效字节输入流。流资源创建对象时, 会带代码底层默认创建出一个大小为8192(1024 * 8)的字节数组, 接下来通过字节数组进行文件内容的读, 如此提高效率
注意:这两个流是包装类型:本身不具备读写的功能,只是在某个具体的流对象的基础上,对其进行加强,例如FileInputStream和FileOutputStream,原本效率较低,加强之后,就效率较高。
- 构造方法
BufferedOutputStream(OutputStream out): //创建字节缓冲输出流对象
BufferedInputStream(InputStream in): //创建字节缓冲输入流对象
缓冲字节流实现原理
- FileOutputStream和BufferedOutputStream原理分析:
BufferedOutputStream高效的原理:在该类型中准备了一个数组,存储字节信息,当外界调用write方法想写出一个字节的时候,该对象直接将这个字节存储到了自己的数组中,而不刷新到文件中。一直到该数组所有8192个位置全都占满,该对象才把这个数组中的所有数据一次性写出到目标文件中。如果最后一次循环过程中,没有将数组写满,最终在关闭流对象的时候,也会将该数组中的数据刷新到文件中。
- FileInputStream和BufferedInputStream原理分析:
BufferedInputStream高效的原理:在该类型中准备了一个数组,存储字节信息,当外界调用read()方法想获取一个字节的时候,该对象从文件中一次性读取了8192个字节到数组中,只返回了第一个字节给调用者。将来调用者再次调用read方法时,当前对象就不需要再次访问磁盘,只需要从数组中取出一个字节返回给调用者即可,由于读取的是数组,所以速度非常快。当8192个字节全都读取完成之后,再需要读取一个字节,就得让该对象到文件中读取下一个8192个字节了。
import java.io.IOException;
public class Demo01_BufferedStream {
public static void main(String[] args) throws IOException{
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("D:\\0308系统班\\day19\\视频\\01.昨日内容回顾.mp4"));
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("D:\\copy.mp4"));
long begin = System.currentTimeMillis();
int len;
while((len = bis.read()) != -1){
bos.write(len);
}
long end = System.currentTimeMillis();
System.out.println(end - begin);
bis.close();
bos.close();
}
}
flush()方法和close()方法区别
-
close方法会先调用flush方法
-
close方法用于流对象的关闭,一旦调用了close方法,那么这个流对象就不能继续使用了
-
flush只是将缓冲区中的数据,刷新到相应文件中,而不会将流对象关闭,可以继续使用这个流对象。但是如果flush方法使用过于频繁,那么丧失了缓冲区的作用。
import java.io.*;
public class Demo02_BufferedStreamCopyTxt {
public static void main(String[] args) throws IOException {
// 1. 创建出一个高效字节输入流
BufferedInputStream bis = new BufferedInputStream(
new FileInputStream("Info.txt")
);
// 2. 创建出一个高效字节输出流
BufferedOutputStream bos = new BufferedOutputStream(
new FileOutputStream("InfoCopy.txt")
);
// 3. 边读边写
int len;
while((len = bis.read()) != -1){
bos.write(len);
}
/*
问题:
使用带有底层数组缓冲的流资源时, 如果没有刷新过资源, 也没有关闭资源, 那么流资源目标结果可能有问题, 例如 : 数据没有同步到文件中
问题发生原因:
BufferedOutputStream,将数据写入到底层的8192的字节数组中, 写入的数据因为不够8192,因此没有自动将数据同步到文件中,仍然还是存储在底层的数组中
解决问题的办法
1) flush() : 表示刷新流资源, 将当前流资源底层数组缓冲中的所有数据同步到文件中
2) close() : 因为每次流资源关闭之前, 默认先调用一次flush方法功能,将所有存在于底层数组缓冲中的数据先同步到文件中, 然后再关闭流资源的使用权利
flush和close方法的不同:
flush刷新资源之后, 流还能使用
close关闭资源之后, 流不能使用
*/
// 5. 刷新流资源
// bos.flush();
// 4. 关闭资源,必须要做,在流资源使用结束之后
bis.close();
bos.close();
bos.write("你好".getBytes());
bos.flush();
}
}
IO中保证流对象关闭的标准格式
-
捕获异常和声明异常的原则
- 如果知道如何处理异常,那么就使用try...catch来进行处理;如果不知道如何处理异常,那么就使用throws来对异常进行声明,或者将当前的异常包装成其他的异常类型,进行声明,因为越到代码的高层,拥有更多的资源、更高的位置和权力,知道如何处理,底层被调用的方法,虽然是出现异常的位置,但是并不知道如何处理。
- 如果你希望程序出现异常之后,继续运行下去,那么就使用try...catch;如果出现异常之后,希望当前方法的代码停止运行,那么就使用throws
-
IO中保证流对象关闭的格式(jdk1.7之前)
try{
流对象的使用;
}catch(异常类名 变量名){
异常的处理代码;
}finally{
关闭流资源;
}
- IO中保证流对象关闭的格式(jdk1.7之后)
try (
流对象的创建;
) {
流对象的使用;
}catch(IOException e){
异常处理方式;
}
特点:
流对象使用之后,不需要手动关闭,因为这个格式中的小括号会在流资源使用完毕后,自动关闭了流对象.
JDK1.7之前标准异常处理方式
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo03_StreamExceptionDeal {
public static void main(String[] args) {
// 案例 : 普通字节输入输出流进行文件的复制案例
FileInputStream fis = null;
FileOutputStream fos = null;
try{
fis = new FileInputStream("myFirstFile.txt");
fos = new FileOutputStream("myCopy.txt");
int len;
while((len = fis.read()) != -1){
fos.write(len);
}
}catch(IOException e){// 利用多态捕获一个父类的异常即可
e.printStackTrace();
}finally{
try {
if(fis != null){
fis.close();
}
} catch (IOException e) {
e.printStackTrace();
}finally{
try {
if(fos != null){
fos.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
JDK1.7之后优化的IO流资源异常处理代码
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo04_StreamException2 {
public static void main(String[] args) {
/*
新的IO流资源的异常处理语法结构 : 需要在JDK1.7版本以及以后才能使用
try(
需要使用流资源的对象创建;// 小括号作用: 当流资源使用完毕,自动关闭流资源
){
对于流资源的使用过程;
}catch(异常类型 e){
异常处理方式;
}
*/
try(
FileInputStream fis = new FileInputStream("myFirstFil.txt");
FileOutputStream fos = new FileOutputStream("myCopy.txt");
){
int len;
while((len = fis.read()) != -1){
fos.write(len);
}
}catch(IOException e){
// e.printStackTrace();
System.out.println("我已经将异常抓住");
}
System.out.println("end code");
}
}
字符流
使用字节流处理字符的问题
- 使用字节流写字符
可以使用,但是需要先把字符串转成字节数组,再存储到文件中,比较麻烦
- 使用字节流读取字符
如果是纯英文,可以一次读取一个字节
如果是纯中文,可以一次读取两个字节(GBK)
如果是中英文混杂,每次不知道读取多少个字节,因此无论字节数组准备多大,都会出现乱码
-
解决方案:
- 由于字节流操作中文不是特别的方便,所以Java就提供字符流。
- 字符流 = 字节流 + 编码表
- 中文的字节存储方式:
用字节流复制文本文件时,文本文件也会有中文,但是没有问题,原因是最终底层操作会自动进行字节拼接成中文,如何识别是中文的呢?
人类的所有语言文字,都可以分为一个一个的字符存在, 每一个国家对于这些字符的使用,都会有对应的编码表
所有编码表,底层都兼容ASCII编码表(美国标准信息交换码表,包含: 0-127个字节,每一个字节对应的符号, 数字, 大写字母, 小写字母); 在此基础上,还会将自己国家语言文字对应成数字的形式,为了让计算机识别人类语言
中国也有自己编码表:
GBK(中国标准信息表换码表) : 一个中文在内存中占有2个字节
UFT-8 (万国码表,包含了所有国家的语言文字字符组成): 一个中文在内存中占有3个字节
不论哪种编码表, 中文文字, 第一个字节都是负数, 字符流在进行文件读取时, 先从文件中读取出一个字节, 判断, 这个字节是否为正数, 认为来自于ASCII, 直接通过编码表,将读取到的字节数据,转换成字符; 如果读取到的第一个字节为负数, 那么继续向下读取, 根据编码表的不同, 决定接下来, 是读取出2或者3个字节, 将这些字节的对应的数据结果参考编码表转换成对应的语言文字(字符)
字符流的使用
字符流写数据方式
- 字符流输出流介绍:
Writer: //用于写入字符流的抽象父类
FileWriter: //用于写入字符流的常用子类
- FileWriter构造方法
FileWriter(File file): //根据给定的 File 对象构造一个 FileWriter 对象
FileWriter(File file, boolean append): //根据给定的 File 对象构造一个 FileWriter 对象
FileWriter(String fileName): //根据给定的文件名构造一个 FileWriter 对象
FileWriter(String fileName, boolean append)//根据给定的文件名以及指示是否附加写入数据的 boolean 值来构造 FileWriter 对象
- 写的方法:
void write(int c): //写一个字符
void write(char[] cbuf): //写入一个字符数组
void write(char[] cbuf, int off, int len): //写入字符数组的一部分
void write(String str): //写一个字符串
void write(String str, int off, int len)//写一个字符串的一部分
import java.io.FileWriter;
import java.io.IOException;
public class Demo03_FileWriter {
public static void main(String[] args) throws IOException {
// 1. 创建出一个字符输出流,绑定一个数据目的
FileWriter fw = new FileWriter("chinese.txt",true);
fw.write("\r\n");
// 1) 每次写入一个字符 write(int i)
fw.write('A');
fw.write(97);
// 2) 向文件中写入字符数组
char[] ch = {'1','?','y','国'};
fw.write(ch);
// 3) 向文件中写入字符数组的一部分
fw.write(ch,0,2);// 1?
// 4) 向文件中写入字符串
String s = "今天下雨了";
fw.write(s);
// 5) 向文件中写入字符串的一部分
fw.write(s,2,2);// 下雨
// 必须关闭资源
fw.close();
}
}
字符流读数据方式
- 字符流输入流介绍:
Reader: //用于读取字符流的抽象父类
FileReader: //用于读取字符流的常用子类
-
FileReader构造方法
FileReader(File file): 在给定从中读取数据的 File 的情况下创建一个新 FileReader FileReader(String fileName): 在给定从中读取数据的文件名的情况下创建一个新 FileReader -
读的方法:
- int read(): 一次读一个字符数据,返回值结果是int类型, 返回的就是这个字符在编码表中对应的整数结果,如果读到-1,证明文件读取完毕
- int read(char[] ch): 一次最多读一个字符数组数据, 将从文件中读取出的字符放置在参数ch数组中, 返回值结果int类型, 表示每次从文件中读取到的字符的个数, 如果读取到-1,证明文件读取完毕
import java.io.FileReader;
import java.io.IOException;
public class Demo02_FileReader {
public static void main(String[] args) throws IOException {
// 1. 创建出一个字符输入流, 绑定一个数据源
FileReader fr = new FileReader("chinese.txt");
int len;
while((len = fr.read()) != -1){
System.out.print((char)len);
}
fr.close();
}
}
字符流的拷贝
-
纯文本文件概念 : 可以使用txt记事本方式打开的,并且可以读懂的文件
-
字符流复制结论:
- 字符流,可以复制纯文本文件, 但是效率不高, 因此对于文件的复制,通常采用字节流
- 字符流,不能复制非纯文本文件
- 实际开发中, 带有中文的文件, 类型一般都是记事本
举例 : 实际开发中有产品文件, 可以将多个产品信息写在一个文件中, 代码可以进行批量的产品信息新增, 要求客户将产品信息写在文件中, 代码读取文件, 解析文件, 将每一个产品信息获取到, 同步到数据库中
产品编号 产品名称 产品单价 产品数量 产品成分 产品所属公司
100001||小金猴||3999||2||AU999||李老师黄金行
100002||纪念章||899.99|| 5|| AU999||深圳黄金
- 字符流复制纯文本效率低原理:

4.字符流不能复制非纯文本文件原理:
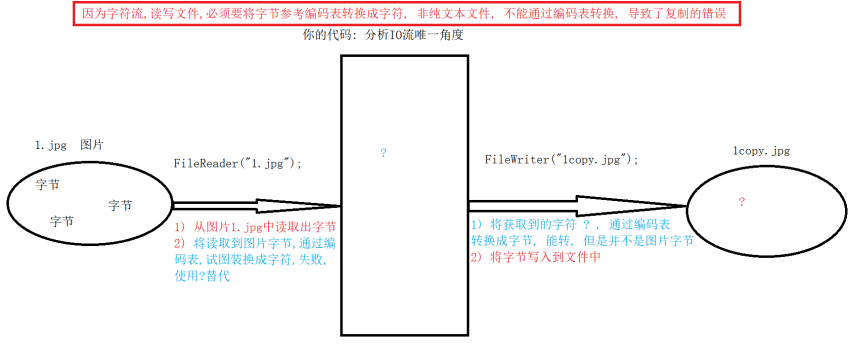
复制纯文本代码
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Demo05_字符流复制文本文件 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("nameAndPass.txt");
FileWriter fw = new FileWriter("nameAndPassCopy.txt");
int len;
while((len = fr.read()) != -1){
fw.write(len);
}
fr.close();
fw.close();
}
}
字符流复制非纯文本失败
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class Demo06_字符流复制图片失败 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("D:\\a\\stream.png");
FileWriter fw = new FileWriter("D:\\copyFail.png");
int len;
while((len = fr.read()) != -1){
fw.write(len);
}
fr.close();
fw.close();
}
}
字符(高效)缓冲流
1、
BufferedReader和BufferedWriter
2、使用:
创建了高效缓冲流对象之后,使用和加强之前一样的方式,BufferedWriter是Writer的子类,BufferedReader是Reader的子类,所以可以继续使用在抽象类中定义的各种方法。
3、高效的原因:
BufferedReader:每次调用read方法,只有第一次从磁盘中读取了8192个字符,存储到该类型对象的缓冲区数组中,将其中一个返回给调用者,再次调用read方法时,就不需要再访问磁盘,直接从缓冲区中拿一个出来即可,效率提升了很多。
BufferedWriter:每次调用write方法,不会直接将字符刷新到文件中,而是存储到字符数组中,等字符数组写满了,才一次性刷新到文件中,减少了和磁盘交互的次数,提升了效率
import java.io.*;
public class Demo07_字符高效缓冲流 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(
new FileReader("Info.txt")
);
BufferedWriter bw = new BufferedWriter(
new FileWriter("InfoCopy.txt")
);
int len;
while((len = br.read()) != -1){
bw.write(len);
}
br.close();
bw.close();
}
}
高效缓冲字符流的特有方法
1、BufferedReader:
readLine()://可以从输入流中,一次读取一行数据,返回一个字符串,如果到达文件末尾,则返回null
2、BufferedWriter:
newLine()://换行。在不同的操作系统中,换行符各不相同,newLine方法就是可以给我们根据操作系统的不同,提供不同的换行符
import java.io.*;
public class Demo08_字符高效流特有方法 {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(
new FileReader("code.txt")
);
BufferedWriter bw = new BufferedWriter(
new FileWriter("codeCopy.txt")
);
String s;
while((s = br.readLine()) != null){
bw.write(s);
bw.newLine();
}
br.close();
bw.close();
}
}
转换流
编码表
1、GBK:国标码,定义的是英文字符和中文字符。在GBK编码表中,英文字符占一个字节,中文字符占两个字节。
2、UTF-8:万国码,定义了全球所有语言的所有符号,定义了这些符号和数字的对应关系,英文字符使用一个字节进行存储,中文字符使用三个字节进行存储
总结 : 转换流的主要作用就是针对于不同编码集的文件,有正确的读写过程
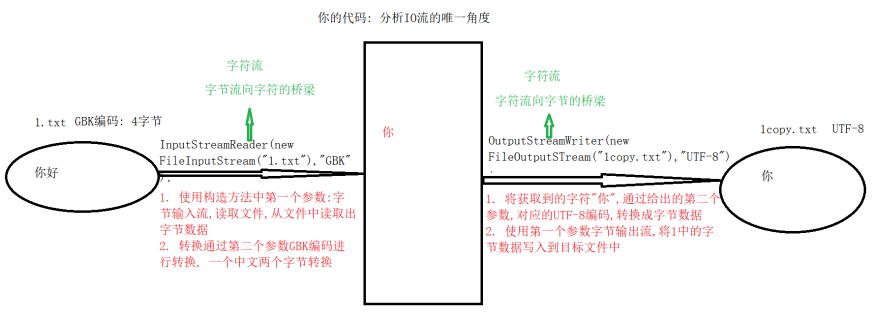
1、OutputStreamWriter:字符流到字节流的桥梁,可以指定编码形式
构造方法:OutputStreamWriter(OutputStream os, String charSetName)
创建一个转换流对象,可以把将来方法中接收到的字符,通过指定的编码表charSetName,编码成字节信息,再通过指定的字节流os,将字节信息写出
使用:直接使用Writer中的方法即可(该类是Writer的子类)
2、InputStreamReader:字节流到字符流的桥梁,可以指定编码形式
构造方法:InputStreamReader(InputStream is, String charSetName)
创建一个转换流对象,可以使用is这个指定的字节流,从磁盘中读取字节信息,通过指定的编码表charSetName,将字节信息解码成字符信息,返回给调用者
使用:直接使用Reader类中的方法即可(该类是Reader的子类)
3、说明:
无论是读取的时候,还是写出的时候,都需要参考读取文件和目标文件的编码形式
读取源文件时,解码的形式必须和源文件的编码形式一致
写出到目标文件时,编码形式必须和目标文件的编码形式一致
转换流的实现原理如下图:
import java.io.*;
public class Demo01_转换流 {
public static void main(String[] args) throws IOException {
// 1. 创建出一个转换输入流, 绑定一个源文件
InputStreamReader isr = new InputStreamReader(
new FileInputStream("D:\\0308系统班\\chinese.txt"),"GBK"
);
// 2. 创建出一个转换输出流, 绑定一个数据目的
OutputStreamWriter osw = new OutputStreamWriter(
new FileOutputStream("chineseCopy.txt"),"UTF-8"
);
int len;
while((len = isr.read()) != -1){
osw.write(len);
}
osw.close();
isr.close();
}
}
标准输入输出流
- System.in : 标准输入流,返回值类型是InputStream (字节流)
分类:字节输入流
设备:默认关联键盘
对标准输入流关联的路径进行修改:setIn(InputStream is), 来自于System类中, 可以改变标准输入流的数据来源
该流对象不需要关闭
- System.out : 标准输出流,返回值类型PrintStream (打印流)
分类:打印字节流
设备:默认关联到控制台
对标准输出流关联的路径进行修改:setOut(PrintStream ps)
注意 : System.in主要使用的默认的键盘录入场景上, 例如: Scanner键盘默认录入数据System.out: 默认在控制台进行数据的输出, 主要关注的就是PrintStream中的print和println系列方法功能, 将任意的数据类型转换成字符串进行输出, 默认在控制台, 实际开发中, 通过System.out可以查看代码的运行结果, 自我测试最主要的使用场景
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.io.PrintStream;
import java.util.Scanner;
public class Demo02_标准输入流 {
public static void main(String[] args) throws FileNotFoundException {
InputStream is = System.in;
// 1. 修改流资源的数据来源
// is.setIn();
// 将标准的输入流数据来源从默认的键盘录入改成了student.txt来源
System.setIn(new FileInputStream("student.txt"));
Scanner sc = new Scanner(System.in);
// int number = sc.nextInt();
String s = sc.next();
System.out.println(s);
System.out.println(sc.next());
// 2. System.out: 默认通过控制台进行输出
PrintStream ps = System.out;
ps.print('A');
ps.println(12);
// 将标准的输出流输出目的有默认的控制台改成chineseCopy.txt文件
PrintStream ps1 = new PrintStream("chineseCopy.txt");
System.setOut(ps1);
ps1.println("我在家");
}
}
打印流
PrintStream打印字节流,PrintWriter打印字符流,这两个流都属于输出流。
这两个流中,除了继承各自父类中的write()方法外,还提供了很多重载形式的print()和println()方法,可以很方便的将各种数据类型以字符串的形式进行输出(会将所有数据类型,先转成字符串,然后进行输出),这两个方法也是打印流特有的方法,对于在使用这两个方法的方式上,这两个流没有区别,print()写出的数据末尾没有行终止符,println()写出的数据末尾有行终止符。
对象序列化
对象流: 将一个对象写入到文件中(序列化),或者将文件中的对象获取到(反序列化)的过程
序列化: 就是指将对象写入到文件中的过程
反序列化: 将对象和对象中的数据从文件中获取到
对象: 表示任意对象,Object的子类,都可以写
作用: 例如: 实际开发场景中,Person类,创建出(new)很多的个对象,正常对象的信息需要保存到数据库中,但是,也可以保存在文件中,节省数据库的空间
举例: 玩游戏,英雄联盟,角色(对象),角色有功能,技能,皮肤, 角色升级,第一次玩结束,于是角色需要被保存下来(序列化); 下次再玩,读档,角色还能重新使用,数据不变(反序列化)
对象输出流的介绍
ObjectOutputStream : //对象的输出流,是OutputStream的子类
功能: 将对象写入到文件中
构造方法:
ObjectOutputStream (OutputStream o): //需要绑定一个数据源,向文件中写入对象
常用方法:
writeObject(Object obj): //向文件中写入obj对象
注意事项:
-
写入文件的对象,必须要实现Serializable序列化接口,如果没有实现接口,会报错
java.io.NotSerializableException
注意: 需要被序列化和反序列化的对象,必须要实现Serializable接口, 否则不能序列化和反序列化.Serializable接口是一个标志性的接口,里面没有任何方法
类比记忆: 比如买猪肉,猪肉上面的戳,就表示肉是经过检测,安全的,可以吃的,那这个戳,就相当于实现了Serializable接口,没有实质的用途,却可以表示该猪肉的安全特质
- 对象写到文件中,内容是无法读懂的,因为将对象转换成字节存储,因此无法识别,只要在进行反序列化的时候,能够将对象成功获取到即可.
import java.io.Serializable;
// 注意 : 实现类Serializable序列化接口的类型才能进行序列化和反序列化操作
public class Person implements Serializable {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
import java.io.*;
public class Demo03_对象序列化 {
public static void main(String[] args) throws IOException {
writePerson();
}
// 1. 定义出功能 : 将对象写入到文件中(序列化过程)
public static void writePerson() throws IOException {
// 1) 创建出一个对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.txt"));
// 2) 创建出一个Person类型对象
Person p = new Person("张三",20);
Person p1 = new Person("李四",18);
// 3) 需要将对象p写入到指定的文件中
oos.writeObject(p);
oos.writeObject(p1);
oos.close();
}
}
对象输入流的介绍
ObjectInputStream : //对象的输入流,是InputStream的子类
功能: 能将对象从文件中读取到
构造方法:
ObjectInputStream(InputStream in): //从某个指定的文件(序列化对象的文件)中读取到对象
常用方法:
readObject(): //将对象从文件中读取出来,每次读取出一个对象,返回值类型是Object
//如果文件中没有对象,还要继续进行对象读取,会抛出
EOFException : End Of File Excepttion //文件到达结束位置,不能再进行对象的获取了
import java.io.*;
public class Demo03_对象序列化 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// writePerson();
readPerson();
}
// 1. 定义出功能 : 将对象写入到文件中(序列化过程)
public static void writePerson() throws IOException {
// 1) 创建出一个对象输出流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("person.txt"));
// 2) 创建出一个Person类型对象
Person p = new Person("张三",20);
Person p1 = new Person("李四",18);
// 3) 需要将对象p写入到指定的文件中
oos.writeObject(p);
oos.writeObject(p1);
oos.close();
}
// 2. 定义出功能: 将对象从文件中读取出来(反序列化过程)
public static void readPerson() throws IOException, ClassNotFoundException {
// 1) 创建出一个对象输入流
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("person.txt")
);
// 2. 使用readObject()方法, 每次从文件中读取出一个对象
Person p = (Person)ois.readObject();
Person p1 = (Person)ois.readObject();
// EOFException: End Of File Exception
// 当文件中已经没有序列化对象之后,仍然使用readObject()继续获取对象
// 那么报出: 文件到达结束异常
Person p2 = (Person)ois.readObject();
System.out.println(p.getName() + "---" + p.getAge());
System.out.println(p1.getName() + "---" + p1.getAge());
System.out.println(p2.getName() + "---" + p2.getAge());
/*Object obj;
while((obj = ois.readObject()) != null){
Person p = (Person)obj;
System.out.println(p.getName() + "---" + p.getAge());
}*/
ois.close();
}
}
将对象存储在集合中进行序列化和反序列化
反序列时 : 将对象从文件中读取,不知道文件中有几个对象, 于是获取对象次数多了, 报出EOFException, 文件到达末尾异常
可以出一个优化方案: 将多个对象放置到一个集合中, 将这个集合对象写入到文件中,实现序列化过程; 读取文件的时候,就读一次, 将集合对象获取出来, 遍历集合相当于将集合中所有对象都获取到. 如此可以避免掉,不知道文件中有多少对象从而报出的异常问题
package com.ujiuye.stream;
import java.io.*;
import java.util.ArrayList;
public class Demo04_序列化优化 {
public static void main(String[] args) throws IOException, ClassNotFoundException {
// writePersonList();
readPersonList();
}
// 1. 定义出方法: 进行多个对象放置在集合中的序列化过程
public static void writePersonList() throws IOException {
ArrayList<Person> list = new ArrayList<>();
list.add(new Person("张三丰",21));
list.add(new Person("李二狗",17));
list.add(new Person("娃哈哈",15));
list.add(new Person("大户好",19));
// 1. 创建出一个对象输出流, 将集合list进行序列化
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("personList.txt")
);
// 2. 序列化集合
oos.writeObject(list);
oos.close();
}
// 2. 定义出方法 : 反序列化list集合, 获取到集合中的所有对象
public static void readPersonList() throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("personList.txt")
);
ArrayList<Person> list = (ArrayList<Person>)ois.readObject();
for(Person per : list){
System.out.println(per.getName() + "---" + per.getAge());
}
ois.close();
}
}
序列号serialVersionUID和transient关键字
类每次被编译成.class文件的时候,都有一个版本号 long数字
类有改动,重新编译成.class,生成了一个新的版本号 long 数字
两次数字不相等
进行对象的序列化,记录class文件的版本号 long数字
反序列化的时候,检测Person.class的版本号与序列化时的版本是否一致,如果不一致,报错. 无效的类异常
解决方案:
Person类中,添加一个成员,是序列号(版本号), 序列号是一个固定的值,不管该不该代码,序列号都是一样的
private static final long serialVersionUID = 1L;
transient:
如果一个对象中的某个成员变量的值不想被序列化,又该如何实现呢?
给该成员变量加transient关键字修饰,该关键字标记的成员变量不参与序列化过程
import java.io.Serializable;
// 注意 : 实现类Serializable序列化接口的类型才能进行序列化和反序列化操作
public class Person implements Serializable {
// 为每一个序列化的类添加一个不可改变的(固定的)serialVersionUID
// 为了防止修改类的时候, 不能反序列化问题
private static final long serialVersionUID = 42L;
private String name;
// 如果类型中有哪些成员变量不想要序列化,那么可以使用transient关键字进行成员变量的修饰
private transient int age;
// String sex;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
Properties
- Properties介绍:
表示一个持久的属性集
属性集:属性名称和属性值的对应关系,其实还是一个双列集合
持久的:可以保存到流中,也可以从流中读取。可以很方便和文件进行交互
是一个Map体系的集合类,是Hashtable的子类,所以可以当做普通的Map来使用
属性列表中的每个键及其对应的值都是一个字符串,因此不需要写泛型
- 主要作用: 一般是用于进行配置文件的读写,能将配置文件中的数据,读取到集合中
配置文件中,一般都是键值对的关系(都是String类型)进行存储, 因此Properties中默认存储的键值对类型也是<String,String>
- 配置文件中的注释, 使用#表示
#userName 表示用户姓名
userName = mysql
password = 88888
- 构造方法: 直接使用空参数的构造即可
Properties集合中的常用方法
put(key k,Value v): //将参数中的键值对存储在Properties集合中,继承自父接口中的方法
setProperty(String key, String value) : //将键值对映射关系添加到集合中,键和值都是String类型,key值不重复,如果重复,后面的value值替掉前面key对象的value值
getProperty(String key): //就是通过制定的key值获取到value值
stringPropertyNames() : //方法是将Properties集合中所有的key值获取到,放置到Set<String>集合中
import java.util.Properties;
import java.util.Set;
public class Demo01_PropertiesMethod {
public static void main(String[] args) {
// 1. 创建Properties键值对映射关系对象
Properties p = new Properties();
// 1) setProperty(String key,String value):将键值对映射关系添加到集合中,
// 键和值都是String类型,key值不重复,如果重复,后面的value值替掉前面key对象的value值
p.setProperty("张三","北京");
p.setProperty("李四","新加坡");
p.setProperty("张三","台湾");
// 2) stringPropertyNames(): 获取到Properties中所有的String类型的key值
Set<String> set = p.stringPropertyNames();
for(String key : set){
// 3) getProperty(String key): 就是通过制定的key值获取到value值
String value = p.getProperty(key);
System.out.println(key + "--" + value);
}
}
}
Properties和IO流相结合的方法
1.load(InputStream inStream) : //通过load方法,将InputStream 字节流读取到的配置文件信息,放置到properties的键值对集合(String,String)中
2.load(Reader read): //通过load方法,将Reader 字符流读取到的配置文件信息,放置到properties的键值对集合(String,String)中
3.store(OutputStream out, String comments) : //使用字节的输入流,修改配置文件中的内容,comments 就是针对于本次修改的描述
4.store(Writer out, String comments) : //使用字符的输入流,修改配置文件中的内容,comments 就是针对于本次修改的描述
读取配置文件数据并且修改配置文件内容过程
-
先创建一个配置文件, config.properties
1)配置文件的书写格式(正常的配置文件中,数据都是英文的)userName=zhangsan
age=25
2)通过load方法,读取配置文件中的内容到集合中
3)修改配置文件的内容
setProperty(String key, String value) : //只是修改了集合中的变量,并没有修改文件内容
store(输出流,”修改原因”) : //将修改同步到配置文件中
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Properties;
import java.util.Set;
public class Demo02_PropertiesReadFile {
public static void main(String[] args) throws IOException {
// 1. 创建Properties键值对映射关系对象
Properties p = new Properties();
// 2. load方法功能,使用指定流资源.将配置文件中的字符串键值对,直接
// 存储在Properties集合中
p.load(new FileReader("config.properties"));
// 3. 遍历Properties集合,查看读取到的文件内容
Set<String> setKey = p.stringPropertyNames();
for(String key : setKey){
String value = p.getProperty(key);
System.out.println(key + "--" + value);
}
// 4. 通过Properties集合,修改配置文件的内容
// 1) 先将需要修改的值,设置在Properties键值对中
p.setProperty("username","hello");
// 2) store(writer,"修改的原因") : 将集合p中的键值对,同步到文件中
p.store(new FileWriter("config.properties"),"change name");
}
}
