
Java SE (三)异常 集合
异常
- 异常概述: 在java程序运行过程中,出现的不正常情况,出现的错误,称为异常最终会导致程序非正常停止。
需要注意:语法错误不算在异常体系中。
-
Java中的每一种异常都封装成一个类, 当异常发生时创建出异常对象,对象中包含了异常情况的原因、类型、描述以及位置。
-
异常也是一种处理异常情况的机制,可以进行跳转、捕获以及结束程序
异常的体系
1、Throwable:可抛出的,是异常体系的顶层父类,其他的异常或者错误都是Throwable的子类类型,只有Throwable的体系类型,才可以使用异常的处理机制
2、Error:错误,是Throwable的子类,用于描述那些无法捕获和处理的错误情况,属于非常严重的错误,StackOverflowError
3、Exception:异常,是Throwable的子类,用于描述那些可以捕获和处理的例外情况,属于不太严重的错误,ArrayIndexOutOfBoundsException
4、RuntimeException:运行时异常,是Exception的特殊的子类,在编译阶段不做检查的一个异常
5、异常体系结构:
Throwable
Error
Exception
RuntimeException : 运行时异常
除RuntimeException 之外: 编译时期异常
- 运行时异常和编译时期异常的区别
编译时期异常:
a: Exception类和Exception除了RuntimeException以外的其他子类
b: 出现就必须显示的处理,否则程序无法编译通过,程序也就无法运行; 当代码中发生编译时期异常, 提示自动进行处理
运行时异常:
a: RuntimeException类和RuntimeException的子类
b: 出现无需显示处理,也可以像编译时一样显示的处理,无论是否处理程序都可以编译通过。
在jvm中默认处理异常的机制
1、在代码的某个位置,出现了和正常情况不同的情况,就将异常情况封装到一个异常对象中。
2、将异常对象抛给调用该方法的方法
3、某个方法接收到底层方法抛上来的异常,也没有办法自己处理,继续向上抛出,最终抛给主方法,主方法也没有办法处理,抛给调用自己的jvm虚拟机
4、Jvm虚拟机是我们手动调用的,只能将异常对象的所有信息,通过错误流打印出来,结束jvm虚拟机
5、总结,jvm默认处理的方式:【一层一层向上抛,jvm接收到之后结束自己】

手动处理异常的方式
1、有两大类处理异常的方式:
异常的声明:某个方法有编译时异常,编译就会无法通过,需要在异常所在的方法声明上,声明该方法可能出现的编译时异常
异常的处理:出现异常之后,可以通过某些格式来捕获和处理异常,可以让程序在出现异常之后,继续运行。可以定义自己处理异常的逻辑。
2、捕获处理异常的代码格式:
try...catch
try...catch...finally
try...finally(无法捕获处理异常)
throw关键字
1、throw:抛出,用于抛出一个异常对象
2、throw关键字的使用场景 : 异常是一个对象,当程序运行到某种情况时,程序员认为这种情况和现实生活不符合,就把当前的对于情况的描述,封装到一个异常对象中,通过throw关键字将异常对象进行抛出。将异常抛给方法的调用者
3、throw关键字的语法结构:
throw new Exception或者Exception任意一个子类对象(“将异常发生详细信息描述清楚”);
4、作用:
创建一个异常对象,使用throw关键字抛出,实现了程序的结束或者跳转
5、说明:
如果抛出的是编译时异常,那么这个异常必须使用异常处理的方式处理,才能编译成功
如果抛出的是运行时异常,在编译阶段就相当于没有异常,可以不处理这个异常
6、throw关键字使用注意事项:
throw关键字使用在方法中
throw每一次只能抛出一个异常
public class ThrowDemo {
public static void main(String[] args) {
int[] arr = {12};
getArrayEle(arr,7);
}
// 获取到数组中的某一个索引元素值
public static int getArrayEle(int[] arr, int index){
if(arr == null){
throw new NullPointerException("数组不能为null") ;
}
if(arr.length == 0){
throw new ArrayIndexOutOfBoundsException("数组中没有元素,无法进行数据获取");
}
if(index < 0 || index > arr.length-1){
throw new ArrayIndexOutOfBoundsException(index + "索引在arr数组中不存在, 无法操作");
}
return arr[index];
}
}
throws关键字
异常的手动处理方式之一 : 声明异常, throws关键字
1、throws:抛出,用于声明异常类型
2、在某个方法中,有一些编译时异常,没有给出处理的方案,没有捕获这个异常,没有处理这个异常,就说明这个方法是一个有问题的方法。为了让调用者在调用时,可以考虑到处理这个异常,所必须在当前方法的声明上,声明这个异常。
3、声明格式:
修饰符 返回值类型 方法名称(参数列表) throws 异常类型1, 异常类型2,... {
可能出现异常的代码;
}
4、注意事项:
1、如果抛出的是一个运行时异常,那么就相当于没有抛出异常,这种异常也不需要在方法上声明;声明了一个运行时异常,也相当于没有做任何声明
2、如果抛出的是一个编译时异常,那么就必须进行声明或者捕获;如果声明了一个编译时异常,将来调用这个方法时,也相当于有一个声明的异常
import java.io.FileNotFoundException;
public class ThrowsDemo {
public static void main(String[] args) throws Exception,FileNotFoundException {
checkFile("123.txt");
}
// 验证目标文件abc.txt是否存在
public static void checkFile(String str) throws Exception, FileNotFoundException{
if(str == null){
// NullPointerException 运行时异常, 不需要进行处理, 代码也不会提示处理
throw new Exception("提供字符串文件不能为null");
}
if(!"abc.txt".equals(str)){
// FileNotFoundException 编译时期异常, 一旦出现, 必须要进行异常处理
// 代码也提示要处理
throw new FileNotFoundException("提供的文件不是abc.txt");
}else{
System.out.println("文件找到了");
}
}
}
throw和throws的比较
1、throw是对异常对象的抛出,throws是对异常类型的声明
2、throw是对异常对象实实在在的抛出,一旦使用了throw关键字,就一定有一个异常对象出现;throws是对可能出现的异常类型的声明,即使声明了一些异常类型,在这个方法中,也可以不出现任何异常。
3、throw后面只能跟一个异常对象;throws可以跟很多个异常类型
try...catch语句
异常手动处理方式第二种 : 异常捕获处理, try...catch系列语句
try {
可能发生异常的代码
} catch(可能出现异常的类型 标识符) {
这种异常出现之后的处理方式
}
public class TryCatchDemo {
public static void main(String[] args) {
int i;
try{
i = 10 / 1; // 1. try代码块中第5行检测出异常 new ArithmeticException("/ by zero");
// 从try代码块发生异常的行数开始, 直接将异常抛给catch, 代码跳转到catch结构运行
// 因此try代码块中, 从第5行之后的代码, 不再运行
System.out.println("try end");
}catch(ArithmeticException e){
System.out.println("捕获到了数学运算异常");
i = 0;
}
System.out.println("program end "+i);
/*try{
i = 10 / 0;
}catch(NullPointerException e){
System.out.println("捕获到了数学运算异常");
i = 0;
}*/
}
}
try...catch...catch...语句
1、在一段代码中,可能出现多种异常(虽然一次运行只能出现一个异常,但是出现哪个异常我们是不清楚的),所以要准备多种异常情况的处理机制。
try {
可能出现异常的代码
} catch (异常类型1 异常对象名1) {
异常类型1出现之后的处理办法
} catch (异常类型2 异常对象名2) {
异常类型2出现之后的处理办法
}
....
} catch (异常类型n 异常对象名n) {
异常类型n出现之后的处理办法
}
2、执行流程:
1、执行try中的内容,如果没有异常,try...catch语句直接结束
2、如果有异常,那么就在发生异常的代码位置直接跳转到catch块中,try中后面的代码就不再继续运行了
3、继续匹配各个catch块中的异常类型,从上到下,一旦匹配到某个catch声明的异常类型,就直接执行该catch块的处理方式。处理完成之后,try...catch语句就直接结束了,不会再去匹配后面其他的catch块的异常类型
3、注意事项:
如果在各个catch块中,出现了子父类的异常类型,那么子类异常的catch块,必须在父类异常catch块的上面,因为从上到下匹配方式,如果父类的catch块在上面,下面的catch块就没有出现的意义了,无法到达的代码。
import java.io.FileNotFoundException;
public class TryMoreCatchDemo {
public static void main(String[] args) {
/* try{
checkFile(null);
}catch(FileNotFoundException e){ // 如果多catch语句需要捕获多种异常, 多种异常之间存在子父类继承关系, 一定要先捕获子类异常, 后捕获父类异常; 或者直接捕获一个父类异常; 因为多态的发生, 会让父类异常之后的子类异常没有运行机会, 从而代码报错
System.out.println("catch捕获到了FileNotFoundException");
}catch(Exception e){
System.out.println("catch捕获到了Exception");
}*/
try{
checkFile("123.txt"); // new FileNotFoundException("提供的文件不是abc.txt")
}catch(Exception e){
// Exception e = new FileNotFoundException("提供的文件不是abc.txt"); 多态
System.out.println("catch捕获到了Exception");
}/*catch(FileNotFoundException e){
System.out.println("catch捕获到了FileNotFoundException");
}*/
System.out.println("end");
}
// 验证目标文件abc.txt是否存在
public static void checkFile(String str) throws Exception, FileNotFoundException {
if(str == null){
// NullPointerException 运行时异常, 不需要进行处理, 代码也不会提示处理
throw new Exception("提供字符串文件不能为null");
}
if(!"abc.txt".equals(str)){
// FileNotFoundException 编译时期异常, 一旦出现, 必须要进行异常处理
// 代码也提示要处理
throw new FileNotFoundException("提供的文件不是abc.txt");
}else{
System.out.println("文件找到了");
}
}
}
扩展 : 异常发生, 可以通过throws关键字进行异常声明; 也可以通过try...catch语句进行异常捕获处理
具体选择的处理方式, 看实际开发场景
- 如果这种异常发生, 代码必须停止, 使用throws关键字声明异常
验证, 客户余额与需要支付金额之间比较关系
public void pay() throws Exception{
double sum = 5999;
double yuE = 3999;
if(yuE < sum){ // 代码必须停止
throw new Exception(“客户余额不足”);
}
}
- 如果有异常发生, 代码不需要停止, 可以使用try...catch将问题解决
try...catch...finally语句
try {
可能发生异常的代码
} catch (可能发生的异常类型 异常对象名称) {
当前异常类型的处理方式
}... finally {
一定要执行的代码
}
finally:关键字, 一定要执行的代码
1、如果把某句代码放在try中,可能在这句话前面有异常,那么这句话就无法执行;如果把某句代码放在catch中,有可能try中没有异常,就无法执行这句话;如果把某句代码放在try...catch之后,可能有未捕获的异常,那么这句代码也无法执行。
2、finally:也是一个代码块,在这个代码块中的代码,一定会执行,无论上面描述的哪种情况,都会执行。甚至在代码中有return语句,都会先执行finally中的代码。
3、作用:一般使用关闭资源
public class TryCatchFinallyDemo {
public static void main(String[] args) {
/*int i;
try{
i = 10 / 1;
System.out.println(i);
}catch(Exception e){
System.out.println("catch捕获异常成功");
i = 99;
}finally{
System.out.println("我必须的运行");
}*/
// System.out.println("end" + i);
System.out.println(getI());// 109
}
public static int getI(){
int i;
try{
i = 10 / 1; // 10
System.out.println(i);// 输出10
return i; // return 没有执行, 先执行finally
}catch(Exception e){
System.out.println("catch捕获异常成功");
i = 99;
return i;
}finally{
System.out.println("我必须的运行");
i = 109;
return i;
}
}
}
try...finally
try {
可能发生异常的代码
} finally {
一定要执行的代码
}
作用:
1、第三种格式无法捕获和处理异常,一旦发生任何异常,仍然会按照默认的处理方式,一层一层向上抛出,到达jvm,结束虚拟机
2、无论try中的语句是否发生异常,finally中的代码都一定有执行的机会
3、如果有两句代码,都需要有执行的机会,不希望第一句的成功与否影响到第二句的执行机会,那么就把这两句代码分别放在try和finally中
使用场景 : 如果代码中发生异常, 不处理, 交给JVM默认处理, 还有一定需要执行逻辑, 那么try...finally可以使用
异常体系中的常用方法
1、发现在异常的继承体系中,所有的方法定义在了Throwable这个顶层父类中,子类中几乎没有什么特有方法
2、Throwable中的构造方法:
Throwable()://创建一个没有任何参数的异常对象
Throwable(String message)://创建一个带有指定消息的异常对象
3、常用成员方法:
getMessage()://获取异常的详细信息
toString()://获取异常对象的详细信息
printStackTrace()://打印异常的调用栈轨迹(有关异常的方法调用路径), 对于异常信息追全面的输出方式, 本身返回值结果void, 但是在方法中已经有打印功能, 将异常进行输出,包括异常类型, 异常详细信息, 代码发生异常的行数
public class ExceptionMethod {
public static void main(String[] args) {
int[] arr = {1,2};
try {
getArrayEle(arr,3);
} catch (Exception e) {// Exception e = new Exception(index + "在数组中不存在");
// 1. 将封装在异常中的信息以字符串形式获取到
/*String s = e.getMessage();
System.out.println(s);// 3在数组中不存在*/
// 2. 将封装在异常中的信息和发生的异常类型以字符串形式获取到
/*String s = e.toString();
System.out.println(s);*/
// 3.printStackTrace():打印异常的调用栈轨迹(有关异常的方法调用路径),
// 对于异常信息追全面的输出方式, 本身返回值结果void,
// 但是在方法中已经有打印功能, 将异常进行输出,包括异常类型,
// 异常详细信息, 代码发生异常的行数
e.printStackTrace();
}
System.out.println("end-----");
}
public static void getArrayEle(int[] arr , int index) throws Exception{
if(arr == null){
throw new Exception("数组不能为null");
}
if(index < 0 || index > arr.length-1){
throw new Exception(index + "在数组中不存在");
}
System.out.println(arr[index]);
}
}
异常的注意事项
-
运行时异常抛出可以不处理,既不捕获也不声明抛出; 编译时期异常, 必须进行异常处理,throws声明异常, 或者try...catch语法结构捕获处理异常
-
如果父类抛出了多个编译时异常,子类覆盖(重写)父类的方法时,可以不抛出异常,或者抛出相同的异常,或者父类抛出异常的子类。
-
如果父类方法没有异常抛出,子类覆盖父类方法时,不能抛出编译时异常
总结: 子类重写(覆盖Override)父类中方法功能:
为甚要重写? 子类对于从父类继承来的方法功能并不能满足子类的实际需求, 可以选择重写从父类中继承到的方法, 子类重写时希望方法越来越好
-
重写的方法返回值类型, 参数列表, 方法名都与父类中方法一致
-
权限修饰符使用范围上, 子类重写方法权限大于等于父类的原有权限
-
异常问题: 子类的异常声明小于等于父类的异常类型
- 如果父类有一个大的(父类)异常声明, 那么子类可以保持原有异常声明类型, 也可以声明父类异常的子类异常
- 如果父类方法没有声明任何异常, 那么子类重写之后, 也不能进行异常的声明
import java.util.Arrays;
public class ExtendsExceptionZi extends ExtendsExceptionFu{
@Override
public void eat(){
try{
if(true){
throw new Exception("ok");
}
}catch(Exception e){
System.out.println("我自己处理");
}
}
@Override
public void getEle(int[] arr) throws NullPointerException{
if(arr == null){
throw new NullPointerException("数组不能为null");
}
System.out.println(Arrays.toString(arr));
}
}
自定义异常
1、jdk中提供了很多的异常类型,其中的绝大部分都没有自己特有的方法
2、定义这么多异常,没有特有方法、没有特有属性,原因:
1、如果有了很多的异常类型的名字,将来在不同的异常情况下,就可以使用不同的异常类型创建对象。一旦发生了异常,可以很容易通过异常的类名来判断到底发生了什么异常情况
2、如果有了很多的异常类型,不同的异常类型,就可以有不同的处理方式
3、在自己的业务中,jdk提供的各种异常,都无法描述当前的异常情况,就需要我们自己定义异常类型,用在自己的项目的业务中。
4、自定义异常的步骤:
1、定义一个类,以Exception结尾,IllegleAgeException,表示这是一个非法年龄异常
2、让自己定义的这个类,继承一个Exception或者是RuntimeException
如果定义的是编译时异常,就使用Exception
如果定义的是运行时异常,就使用RuntimeException
3、构造方法不能被继承,需要手动添加
// MyException因为直接继承了Exception, 因此编译时期自定义异常类
// 当代码中发生MyException异常, 必须进行异常处理
public class MyException extends Exception{
// 需要定义出构造方法
public MyException(){}
// 定义出一个有参数构造, 目的为了当异常发生, 可以封装详细的异常信息
public MyException(String message){
// 调用父类中的有参数构造
super(message);
}
public void age(int age){
if(age < 0){
System.out.println("年龄不能为负数");
}
if(age >= 200){
System.out.println("年龄不能大于200岁");
}
}
}
public class MyExceptionTest {
public static void main(String[] args) {
int age = 1500;
try{
if(age >= 200){
throw new MyException("年龄输入有误");
}
}catch(MyException e){
e.printStackTrace();
e.age(age);
}
}
}
集合
集合和数组的区别
-
相同点: 两者都是数据存储容器,可以存储多个数据
-
不同点:
数组:
-
- 数组的长度是不可变的,集合的长度是可变的
-
- 数组可以存基本数据类型和引用数据类型
集合: 只能存引用数据类型,如果要存基本数据类型,需要存对应的包装类
集合体系结构
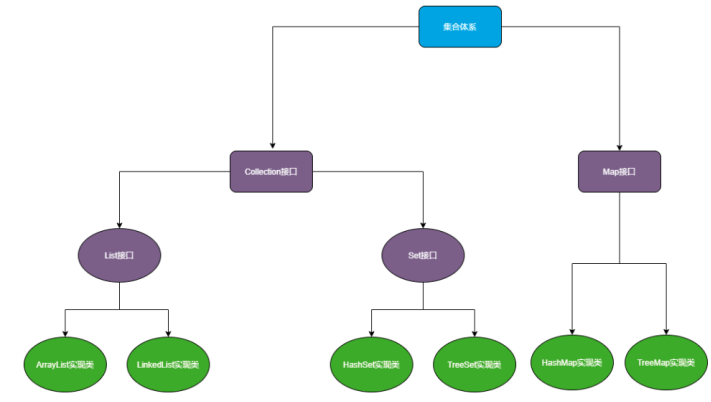
List :
-
元素存取有序
-
元素有索引
-
存储的元素可以重复
Set:
-
元素存取无序
-
没有索引
-
不存储重复元素
单列集合体系
顶层接口Collection常用功能
-
概述: Collection是单列集合的顶层接口,单列集合的顶层接口,定义的是所有单列集合中共有的功能. JDK不提供此接口的任何直接实现.它提供更具体的子接口(如Set和List)实现.
-
创建Collection集合的对象:
Collection接口,不能直接创建对象,需要找一个实现类ArrayList创建对象
- 多态: 多态的方式 -- 父类引用指向子类对象 Collection c = new ArrayList();
- 具体的实现类创建 -- 本类引用指向本类对象 ArrayList a = new ArrayList();
- Collection集合常用方法:
boolean add(Object e): 添加元素
boolean remove (Object o): 从集合中移除指定的元素
void clear(): 清空集合中的元素
boolean contains(Object o): 判断集合中是否存在指定的元素
boolean isEmpty(): 判断集合是否为空(集合存在,没有元素), 如果集合为空, 那么返回true, 如果集合不为空 false
int size(): 返回集合中元素的数量,返回集合的长度。
Object[] toArray(): 返回集合的对象的数组
import java.util.ArrayList;
import java.util.Collection;
public class Demo01_Collection常用方法 {
public static void main(String[] args) {
// 1. 创建出一个集合
Collection c = new ArrayList();
// 2. boolean add(Object e): 添加元素
c.add("a");
c.add("hello");
c.add("b");
System.out.println(c);// [a, hello, b]
// 4. boolean contains(Object o): 判断集合中是否存在指定的元素
System.out.println(c.contains("hello"));// true
System.out.println(c.contains("he"));// false
// 5.boolean isEmpty(): 判断集合是否为空(集合存在,没有元素), 如果集合为空, 那么返回true, 如果集合不为空 false
System.out.println(c.isEmpty());// false
// 3. boolean remove (Object o): 从集合中移除指定的元素
c.remove("a");
System.out.println(c);// [hello, b]
//6. int size(): 返回集合中元素的数量,返回集合的长度。
System.out.println(c.size());// 2
// 4. void clear(): 清空集合中的元素
c.clear();
System.out.println(c);// []
// boolean isEmpty(): 判断集合是否为空(集合存在,没有元素), 如果集合为空, 那么返回true, 如果集合不为空 false
System.out.println(c.isEmpty());// true
//6. int size(): 返回集合中元素的数量,返回集合的长度。
System.out.println(c.size());// 0
System.out.println("-------------------");
// 7. Object[] toArray(): 返回集合的对象的数组
Object[] objArr = c.toArray();
// 通过遍历数组相当于在遍历集合中元素内容
for(int index = 0; index < objArr.length; index++){
Object obj = objArr[index];
String s = (String)obj;
System.out.println(s);
}
}
单列集合的遍历
迭代器遍历:专门对于单列集合进行遍历对象, 称为的迭代器
获取集合的迭代器的方法:
- Iterator
方法返回值类型Iterator接口: 表示对于collection单列集合进行遍历的迭代器
方法的返回值类型是接口, 证明方法实际返回是这个接口的一个实现类对象(接口的多态性)
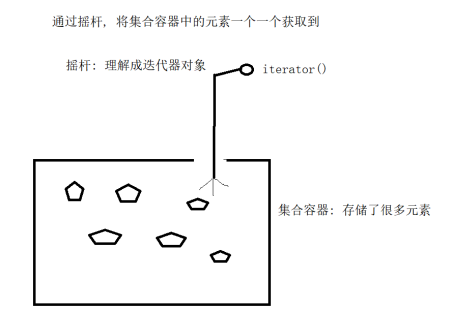
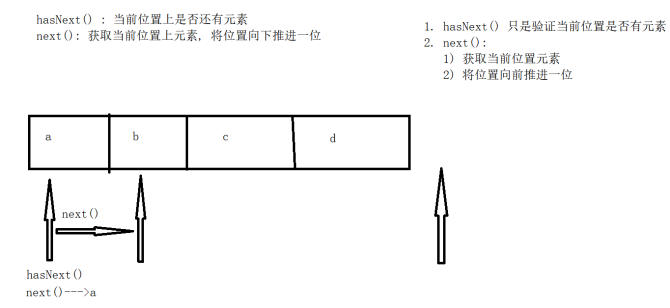
Iterator中的常用方法:
- boolean hasNext(): 判断当前位置是否有元素可以被取出
- E next(): 获取当前位置的元素,将迭代器对象移向下一个索引位置
- void remove(): 删除迭代器对象当前指向的元素
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class IteratorDemo {
public static void main(String[] args) {
// 1. 创建出一个集合容器
Collection c = new ArrayList();
// 2. 虽然存储的看起来是基本数据类型int, 但是实际存储时, 将int类型自动装箱成Integer
c.add(12);
c.add(-15);
c.add(99);
// 3. 获取到c集合的迭代器对象(接口的多态性)
Iterator it = c.iterator();
// 4. hasNext(): 验证,当前位置上是否还有元素, 返回值类型boolean, 如果有返回值true,
// 没有返回false
// next(): 获取到当前位置上的元素, 将位置向下移动一位
while(it.hasNext()){
Object obj = it.next();
Integer i = (Integer)obj;
System.out.println(i + 1);
// 表示将目前正在迭代的元素从集合中删除
it.remove();
}
// 注意 : 如果集合中已经没有元素, 还要通过next方法, 继续向下获取出数据,报出
// NoSuchElementException 没有这个元素异常
// System.out.println(it.next());
System.out.println(c);// []
}
}
增强for(foreach)遍历
- 概述:
增强for是JDK5之后出现的,其内部原理是一个Iterator迭代器
现Iterable接口的类才可以使用迭代器和增强for简化数组和Collection集合遍历
- 格式:
for(集合/数组中元素的数据类型 变量名 : 集合/数组名){
// 已经将当前遍历到的元素封装到变量中了,直接使用变量即可
}
有序单列集合List
-
概述: List集合是Collection接口的子接口,其下有两个常用实现类分别为 ArrayList 和 LinkedList
-
List集合特点:
- 有序:元素存入集合与从集合中取出的顺序一致
- 有索引:每个元素都有自己的索引编号,从0开始,到集合长度-1
- 元素可以重复:即使是值相同的几个元素,位置和索引也各不相同,可以区分这几个值
- List集合的特有方法(E就理解成Object):
- void add(int index,E element): //在此集合中的指定位置插入指定的元素
- E remove(int index): //删除指定索引处的元素,返回被删除的元素
- E set(int index,E element): //修改指定索引处的元素,返回被修改的元素
- E get(int index)://返回指定索引处的元素
- 针对List集合特有的遍历方式
可以通过集合的size方法获取list集合索引的范围,根据索引通过get方法可以获取指定索引的值。
import java.util.ArrayList;
import java.util.List;
public class Demo01_ListMethod {
public static void main(String[] args) {
/*int[] arr = {1,2,3,4,5};
// 数组求长度, length属性
System.out.println(arr.length);
// 字符串求长度
String s = "helloworld";
// 字符串求长度, length()方法
System.out.println(s.length());
// 集合求长度:
Collection c = new ArrayList();
// 2. 虽然存储的看起来是基本数据类型int, 但是实际存储时, 将int类型自动装箱成Integer
c.add(12);
c.add(-15);
c.add(99);
// 集合求长度, size()方法
System.out.println(c.size());*/
listMethod();
}
//
public static void listMethod(){
List list = new ArrayList();
// add(Object o) : 从父接口Collection继承来使用的
list.add("a");
list.add("b");
// 特有方法add(int index, Object obj)
list.add(1,"hello");
System.out.println(list);// [a, hello, b]
// 特有方法remove()
list.remove(0);
System.out.println(list);// [hello, b]
// 特有方法set(int index, Object obj)
list.set(1,"modify");
System.out.println(list);
// 特有方法get(int index)
System.out.println(list.get(0));// hello
System.out.println(list.get(1));// modify
}
}
List集合特有索引遍历方式代码:
import java.util.ArrayList;
import java.util.List;
public class Demo01_List集合特有遍历 {
public static void main(String[] args) {
List li = new ArrayList();
// li集合中有第三个元素, 索引位置0-2
li.add(14);
li.add(15);
li.add(88);
// List集合特有的索引和get方法结合遍历方式
for(int index= 0; index < li.size(); index++){
System.out.println(li.get(index));
}
System.out.println("---------------");
for(Object obj : li){
System.out.println(obj);
}
}
}
并发修异常的产生原因和解决办法
- ConcurrentModificationException 并发修改异常
- 导致异常原因: 在迭代器遍历过程中使用集合的引用进行元素的添加和删除
解决方法:
-
通过for循环遍历集合,在遍历过程中可以进行添加和删除元素
-
使用迭代器中的remove()方法
-
使用ListIterator
listIterator()返回列表中的列表迭代器(按适当的顺序)。
-- add(E e) 添加元素
-- remove() 移除元素
案例 : 定义一个List集合, 存储字符串数据”ok”,”java”,”hello”,”world”, 迭代器遍历集合元素, 如果集合中存在”hello”字符串,向集合中添加”end”字符串
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class Demo03_CurrentModifyException {
/*
案例 : 定义一个List集合, 存储字符串数据”ok”,”java”,”hello”,”world”,
迭代器遍历集合元素, 如果集合中存在”hello”字符串,向集合中添加”end”字符串
*/
public static void main(String[] args) {
List list = new ArrayList();
list.add("ok");
list.add("java");
list.add("hello");
list.add("world");
/* 发生并发修改异常的代码, 因为在遍历的过程中, 集合对象向集合中添加元素
// 1. 获取到list集合迭代器对象
Iterator it = list.iterator();
// 2. 设计循环反复的进行集合的遍历过程
while(it.hasNext()){
String s = (String)it.next();
if("hello".equals(s)){
list.add("end");
}
}
// 3. 查看集合中的元素
System.out.println(list);*/
//addEleToList(list);
//addEleToList2(list);
addEleToList3(list);
}
// 并发修改异常解决方案第一种
// 不使用Iterator进行迭代, 使用List集合特有的迭代器进行集合的遍历
// ListIterator 在原有迭代功能的基础上可以进行集合元素的修改
public static void addEleToList(List list){
ListIterator it = list.listIterator();
while(it.hasNext()){
String s = (String)it.next();
if("hello".equals(s)){
// 在集合中添加元素"end",一定要使用迭代器中的add功能向集合中添加元素
it.add("end");
}
}
System.out.println(list);
}
// 并发修改异常解决方案第二种
// 使用List集合特有的遍历方式: 索引位+ get(index)
public static void addEleToList2(List list){
for(int index = 0; index < list.size(); index++){
String s = (String)list.get(index);
if("hello".equals(s)){
list.add("end");
}
}
System.out.println(list);
}
// 并发修改异常在增强for中出现
// 证明 : 增强for就是迭代器实现原理, 因此增强for也有可能发生并发修改异常
public static void addEleToList3(List list){
for (Object obj : list){
String s = (String)obj;
if("hello".equals(s)){
list.add("end");
}
}
}
}
数据结构之栈和队列
数据结构是计算机存储,组织数据的方式,通常情况下, 精心选择的数据结构可以带来更高的运行和存储效率
栈: stack,又称堆栈,它是运算受限的线性表,其限制是仅允许在标的一端进行插入和删除操作,不允许在其他任何位置进行添加、查找、删除等操作。
特点: 先进后出
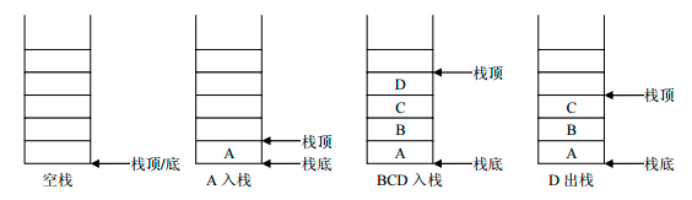
压栈:就是存元素。即,把元素存储到栈的顶端位置,栈中已有元素依次向栈底方向移动一个位置。
弹栈:就是取元素。即,把栈的顶端位置元素取出,栈中已有元素依次向栈顶方向移动一个位置。
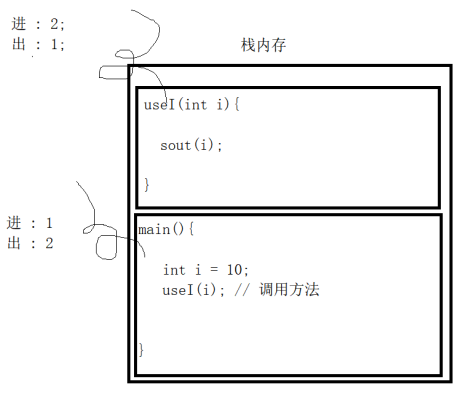
队列:queue,简称队,它同堆栈一样,也是一种运算受限的线性表,其限制是仅允许在表的一端进行插入,而在表的另一端进行删除。
特点:
-
先进先出(即,存进去的元素,要在后它前面的元素依次取出后,才能取出该元素)。例如,小火车过山洞,车头先进去,车尾后进去;车头先出来,车尾后出来。
-
队列的入口、出口各占一侧。例如,下图中的左侧为入口,右侧为出口

数据结构之数组和链表
1.数组: ArrayList
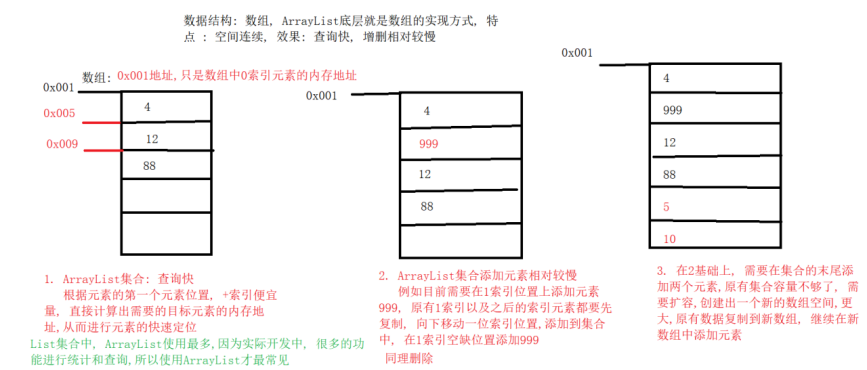
Array:是有序的元素序列,数组是在内存中开辟一段连续的空间,并在此空间存放元素。就像是一排出租屋,有100个房间,从001到100每个房间都有固定编号,通过编号就可以快速找到租房子的人。
特点查找元素快:
通过可以快速访问指定位置的元素

增删元素慢:
指定索引位置增加元素:需要创建一个新数组,将指定新元素存储在指定索引位置,再把原数组元素根据索引,复制到新数组对应索引的位置。如下图
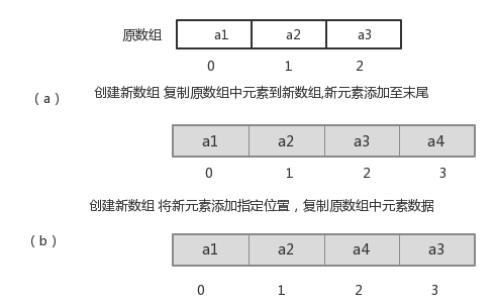
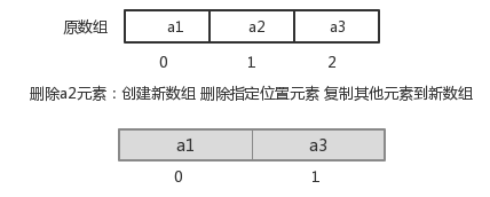
指定索引位置删除元素:需要创建一个新数组,把原数组元素根据索引,复制到新数组对应索引的位置,原数组中指定索引位置元素不复制到新数组中。如下图
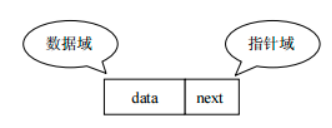
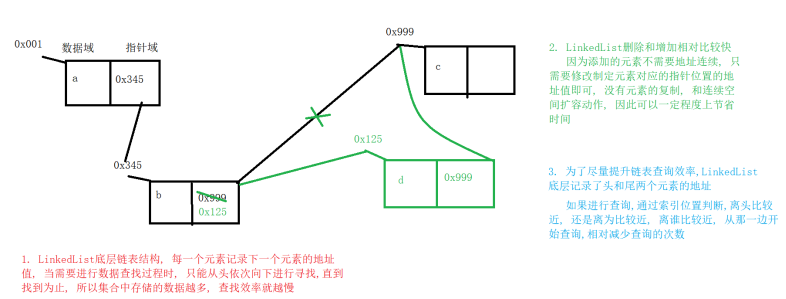
2. 链表:linked list
由一系列结点node(链表中每一个元素称为结点)组成,结点可以在运行时i动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。我们常说的链表结构有单向链表与双向链表,那么这里给大家介绍的是单向链表。
简单的说,采用该结构的集合,对元素的存取有如下的特点:
多个结点之间,通过地址进行连接。例如,多个人手拉手,每个人使用自己的右手拉住下个人的左手,依次类推,这样多个人就连在一起了。
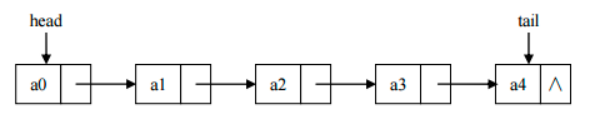
查找元素慢:想查找某个元素,需要通过连接的节点,依次向后查找指定元素
增删元素快: 增加元素 --> 只需要修改连接下个元素的地址即可。
删除元素:只需要修改连接下个元素的地址即可。
ArrayList和LinkedList
- ArrayList集合:
- 在创建ArrayList集合对象的时候,会维护一个长度为10的Object类型的数组.
- 当插入数据10个长度不够,这时候以1.5倍的形式进行扩容
- 存储特点 : 查询快, 增删慢
2.LinkedList:集合数据存储的结构是链表结构。方便元素添加、删除的集合。LinkedList是一个双向链表,那么双向链表是什么样子的呢,我们用个图了解下
LinkedList特点 : 查询慢, 增删快, 链表结构不需要连续内存空间, 可以利用内存中零散空间
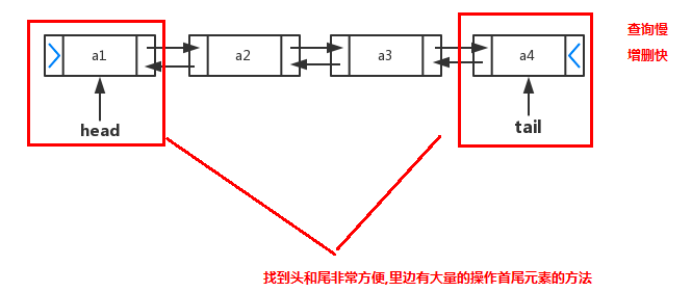
实际开发中对一个集合元素的添加与删除经常涉及到首尾操作,而LinkedList提供了大量首尾操作的方法。这些方法我们作为了解即可:
public void addFirst(E e)://将指定元素插入此列表的开头。
public void addLast(E e)://将指定元素添加到此列表的结尾。
public E getFirst()://返回此列表的第一个元素。
public E getLast()://返回此列表的最后一个元素。
public E removeFirst()://移除并返回此列表的第一个元素。
public E removeLast()://移除并返回此列表的最后一个元素。
import java.util.LinkedList;
public class LinkedListMethod {
public static void main(String[] args) {
LinkedList list = new LinkedList();
list.addFirst("a");
list.addFirst("c");
list.addLast("end");
System.out.println(list);// [c, a, end]
System.out.println(list.getFirst()); // c
System.out.println(list.getLast());// end
list.removeFirst();
list.removeLast();
System.out.println(list);// [a]
}
}
泛型
泛型的概述和使用
1、泛型:广泛的类型,在定义一个类的时候,类型中有些方法参数、返回值类型不确定,就使用一个符号,来表示那些尚未确定的类型,这个符号,就称为泛型。
2、使用:对于有泛型的类型,在这些类型后面跟上尖括号,尖括号里面写上泛型的确定类型(在使用某个类创建对象时,已经可以确定这个具体的类型了,那么就直接写出具体类型)
例如:ArrayList<Integer> al = new ArrayList<Integer>();
3、泛型的好处:
- 提高了数据的安全性,将运行时的问题,提前暴露在编译时期
- 避免了强转的麻烦
4、注意事项:
- 前后一致:在创建对象时,赋值符号前面和后面的类型的泛型,必须一致
- 泛型推断:如果前面的引用所属的类型已经写好了泛型,后面创建对象的类型就可以只写一个尖括号,尖括号中可以不写任何内容。<>特别像菱形,称为“菱形泛型”,jdk1.7特性
import java.util.ArrayList;
public class Demo01_有无泛型的比较 {
public static void main(String[] args) {
// 1. 没有泛型的场景:
// 1) 集合容器中存储的数据类型过于复杂, 导致从集合中获取数据,类型转换错误
// 2) 集合没有指定存储的数据类型时, 所有的数据默认都是Object类型, 使用
// 时需要向下转型, 麻烦
/*ArrayList list = new ArrayList();
list.add(12);
list.add("abc");
list.add(3.14);
for(Object obj : list){
String s = (String)obj;
System.out.println(s);
}*/
// 2. 所有的集合都是带有泛型, 泛型在集合中作用简单理解 : 限定容器中可以存储的数据类型
// 优势
// 1. 限定数据类型, 其他数据类型不能添加到集合中, 保证代码的安全性提高
// 2. 不需要进行向下转型, 简洁
// 注意 : 带有泛型类型, ArrayList<E>-->广泛的类型, E可以转换成任意的引用数据类型使用
// 当创建出一个集合对象时, 泛型需要确定出具体的数据类型
// 总结 : 以后使用集合, 一定要添加泛型
ArrayList<String> list = new ArrayList<>();
// list.add(12);
list.add("abc");
list.add("a");
for(String s : list){
System.out.println(s);
}
// 3. 泛型使用的注意事项
// 1) 泛型的设计方式非常向菱形块, 因此称泛型为菱形泛型<E>--->泛型就是任意一个大写字母表示
// 2) 泛型一致: 前面的泛型必须与后面的泛型保持一致
ArrayList<Integer> list1 = new ArrayList<Integer>();
list1.add(12);
// list1.add(3.14);
// 3) 泛型推断: 从JDK1.7版本开始, 后面的泛型可以不写的, 可以空着, 默认将后面
// 泛型推断成与前面的泛型保持一致
ArrayList<String> list2 = new ArrayList<>();
}
}
泛型类的定义
1、泛型类:带着泛型定义的类
2、格式:
class 类名<泛型类型1, 泛型类型2, .....> {
}
3、说明:
1、类名后面跟着的泛型类型,是泛型的声明,一旦泛型声明出来,就相当于这个类型成为了已知类型,这个类型就可以在整个类中使用
2、泛型的声明名称,只需要是一个合法的标识符即可,但是通常我们使用单个大写字母来表示,常用字母:T、W、Q、K、V、E
3、泛型确定的时机:将来在使用和这个类,创建对象的时候
import java.util.ArrayList;
// 1. FanXingClass目前就是一个带有泛型的类, 类上的泛型K可以表示任意引用数据类型
// K在FanXingClass类中作为已知数据类型进行使用即可
public class FanXingClass<K> {
ArrayList<K> list = new ArrayList<>();
// 定义出一个方法功能, 向成员变量list中添加一个元素数据
public void add(K k){
list.add(k);
System.out.println(list);
}
}
package com.ujiuye.fanxing;
public class TestFanXing {
public static void main(String[] args) {
// 1. 当创建出一个泛型类对象, 类上的泛型需要指定具体的数据类型
FanXingClass<Integer> fan = new FanXingClass<>();
// 2. 调用带有泛型的方法功能 : add
fan.add(14);
FanXingClass<String> fan1 = new FanXingClass<>();
fan1.add("abc");
}
}
泛型方法的定义
1、在方法声明中,带着泛型声明的方法,就是泛型方法
2、格式:
修饰符 <泛型声明1, 泛型声明2,.....> 返回值类型 方法名称(参数列表) {
}
3、说明:
1、在方法上声明的泛型,可以在整个方法中,当做已知类型来使用
2、如果【非静态】方法上没有任何泛型的声明,那么可以使用类中定义的泛型
3、如果【静态】方法上没有任何的泛型声明,那么就不能使用泛型,连类中定义的泛型,也不能使用,因为类中的泛型需要在创建对象的时候才能确定。所以【静态】方法想使用泛型,就必须在自己的方法上单独声明。
import java.util.Arrays;
public class FanXingMethod {
// 定义出一个方法功能 : 可以将任意类型数组中的两个指定索引位置元素进行交换
// 1) 方法上泛型在调用方法时,确定具体类型
// 2) 方法上泛型, 只能在当前方法中使用(方法上泛型作为方法中一个已知的数据类型)
public static<W> void changeArrayELe(W[] arr,int index1, int index2){
W temp = arr[index1];
arr[index1] = arr[index2];
arr[index2] = temp;
System.out.println(Arrays.toString(arr));
}
}
public class TestFanXing {
public static void main(String[] args) {
// 3. 测试带有泛型的静态方法功能
String[] arr = {"a","b","c","d"};
// W[] arr,int index1, int index2
FanXingMethod.changeArrayELe(arr,1,2);// [a, c, b, d]
Integer[] arr1 = {1,2,3,4,56};
FanXingMethod.changeArrayELe(arr1,1,2);// [1, 3, 2, 4, 56]
}
}
泛型的通配符
1、使用泛型的时候,没有使用具体的泛型声明T,而是使用了和声明过的某个泛型T有关的一类类型,就称为泛型的通配符。三种形式:
2、第一种形式,使用?来表示可以是任意类型,例如:
Collection
3、第二种形式,使用? extends E来表示必须是某个泛型类型或是该泛型类型的子类,例如:
Collection
4、第三种形式,使用? super E来表示必须是某个泛型类型或者是该泛型类型的父类,例如:
Arrays工具类中,排序方法static
import java.util.ArrayList;
import java.util.Arrays;
public class Demo02_泛型通配符 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
ArrayList<Integer> li = new ArrayList<>();
li.add(1);
li.add(2);
// 1. removeAll(Collection<?> c): 参数集合可以是任意泛型类型
// ? : 表示泛型的通配符,表示任意泛型类型
list.removeAll(li);
// 2. addAll(Collection<? extends E> c):
// 1) E泛型表示方法调用集合中具有的泛型类型--->list中的String类型
// 2) ? extends E : ? 表示的泛型需要是E类型本身或者是E类型的任意一个子类类型
// 3) 为什么限定 ? extends E, 方法是添加功能, 只有参数集合中的数据可以添加到list集合中才能让这个方法正常进行添加
// list.addAll(li);
ArrayList<Object> list2 = new ArrayList<>();
list2.addAll(list);
// 3. ? super T :
// sort(T[] arr,Comparator<? super T> c)
// ? 表示的泛型类型需要是T类型本身, 或者是T类型的父类类型
}
}
无序单列集合Set
概述
-
java.util.Set接口和java.util.List接口一样,同样继承自Collection接口,它与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格了。与List接口不同的是,Set接口中元素无序,并且都会以某种规则保证存入的元素不出现重复。
-
特点:
无序:没有任何前后的分别,存入的顺序和取出的顺序不一定一致(Set集合有自己算法,对于存入的元素确定 应该存放位置, 只不过存放位置不是按照先开后到方式而已)
没有索引:集合中没有任何位置,元素也就没有位置的属性
不能重复:没有位置的区分,相同值的元素没有任何分别,所以不能重复
-
Set的常用实现类:HashSet(最常用) 和 TreeSet
-
Set集合的遍历方式: 迭代器遍历, 增强for遍历
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Demo01_Set {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("hello");
set.add("1");
set.add("a");
set.add("hello");
// System.out.println(set);// [1, a, hello]
// 1. 迭代器也可以带有泛型
Iterator<String> it = set.iterator();
while(it.hasNext()){
String s = it.next();
System.out.println(s + "----iterator");
}
// 2. 增强for
for(String s : set){
System.out.println(s + "---foreach");
}
// 3. Collection--->toArray() 将一个集合转换成Object类型的数组
Object[] objArr = set.toArray();
for(Object o : objArr){
System.out.println((String)o + "----toArray");
}
}
}
TreeSet的自然排序和比较器排序
TreeSet集合的特点
-
概述 : TreeSet集合是Set接口的其中一个实现类,主要使用场景是对存储在集合中的元素进行排序存储
-
特点:
元素有序, 这里的顺序不是存储和取出的顺序, 而是按照一定的规则排序, 具体排序规则取决于构造方法.
TreeSet() : 根据元素的自然排序进行排序
TreeSet(Comparator c) : 根据指定的比较器进行排序
注意 : 因为TreeSet也是Set集合, 没有索引, 因此不能使用普通for循环进行遍历, 可以使用迭代器和增强for遍历
案例1 : TreeSet集合存储整数并遍历
import java.util.TreeSet;
public class Demo03_TreeSet {
public static void main(String[] args) {
// 注意 : TreeSet空参数构造方法, 对于存储的引用类型数据, 进行默认的自然排序
// 例如 : 数字从小到大, 字母从a-z
TreeSet<Integer> set = new TreeSet<>();
set.add(78);
set.add(0);
set.add(12);
set.add(-1);
set.add(12);
System.out.println(set);// // [-1, 0, 12, 78]
}
}
自然排序Comparable接口的使用
- Comparable接口: 是一个比较接口
接口中的方法: public int compareTo(T o)
排序原理:
返回值为0 -- 相等
返回值为正 -- this 大于 o
返回值为负 -- this 小于 o
- 实现步骤:
- 使用空参构造创建TreeSet集合,用TreeSet集合存储自定义对象,无参构造方法使用的是自然排序对元素进行排序的
- 自定义的Student类实现Comparable接口自然排序,就是让元素所属的类实现Comparable接口,重写compareTo(T o)方法
- 重写接口中的compareTo方法重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
案例: Student类中有年龄和姓名两个属性, 将几个Student对象存储在集合中, 要求按照年龄从小到大进行排序, 年龄相同时, 按照姓名的字母顺序排序
思路 :
-
Student类实现默认排序的Comparable接口(因为TreeSet空参数构造, 默认调用存储对象中重写的Comparable接口的compareTo方法作为自然排序的规则)
-
Student类重写compareTo排序方法, 排序方法每次比较两个对象是否重复以及大小关系
a : 得出0结果, 证明两个对象重复, 后面的对象无法存储进集合中 b : 得出”正数”结果, 证明后面的对象比前面对象大, 因此需要存储的位置在后 c : 得出”负数”结果, 证明后面的对象比前面对象小, 因此需要存储的位置在前
就是根据compareTo比较对象的结果, 决定对象是否可以存储进入集合, 以及存储在集合中的位置
注意事项 : 接下来存储进集合的对象是compareTo方法中this关键字的引用, compareTo方法参数中的参数为集合中已存在的对象
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
// 所有Set集合都可以去重复
// compareTo本质是一个比较方法, 比较下一个对象, 与参数o对象大小关系,是否重复关系
// 1) 0 : 证明下一个对象与当前对象重复, 无法存储在set集合中
// 2) 负数 : 表示后面的对象比前面的对象小
// 3) 正数 : 表示后面的对象比前面的对象大
// 自然排序 : 小的对象在前, 大的对象在后, 相同的对象只能存储一个
@Override
public int compareTo(Student o) {
// return 0;
// return -1;
// return 1;
// 集合 : 对象1, 对象2 , 设计到对象之间比较, 对象2与对象1比较
// 关键字 : this, 表示调用当前compareTo方法的对象, 对象2调用compareTo
// 1) 计算出对象的年龄比较结果
int number = this.age - o.age;
// 2) 验证,如果年龄相同, 使用name的字母排序, 决定对象的先后顺序
int num2 = number == 0 ? this.name.compareTo(o.name) : number;
return num2;
}
}
import java.util.TreeSet;
public class Demo04_TreeSet自然排序 {
public static void main(String[] args) {
// 1. TreeSet() : 空参数构造, 就是默认使用存储的对象自然排序接口中排序规则存储
TreeSet<Student> tree = new TreeSet<>();
// 2. 添加4个学生信息到tree集合中
tree.add(new Student("张三",12));
tree.add(new Student("李四",15));
tree.add(new Student("王五",10));
tree.add(new Student("赵六",18));// z
tree.add(new Student("田七",18));// t
tree.add(new Student("赵六",18));
for(Student ss : tree){
System.out.println(ss.getName() + "," + ss.getAge());
}
}
}
代码运行结果:
Comparator比较器使用
-
用TreeSet集合存储自定义对象,带参构造方法使用的是比较器排序对元素进行排序的
-
比较器排序,就是让集合构造方法接收Comparator的实现类对象,
重写compare(T o1,T o2)方法
-
重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
import java.util.Comparator;
import java.util.TreeSet;
public class Demo05_TreeSet比较器排序 {
public static void main(String[] args) {
TreeSet<Student> tree = new TreeSet<>(
// 需要的是一个Comparator接口的实现类实现出比较规则
// 利用了匿名内部类对象, 简化了实现类过程
new Comparator<Student>(){
// 第一个参数s1 : 表示预计即将要添加进集合中元素 this
// 第二个参数s2 : 表示集合中已经存在的对象
@Override
public int compare(Student s1, Student s2) {
int number = s1.getAge() - s2.getAge();
// 2) 验证,如果年龄相同, 使用name的字母排序, 决定对象的先后顺序
int num2 = number == 0 ? s1.getName().compareTo(s2.getName()) : number;
return num2;
}
}
);
tree.add(new Student("张三",12));
tree.add(new Student("孙",15));
tree.add(new Student("李",15));
tree.add(new Student("王五",10));
tree.add(new Student("赵六",18));
tree.add(new Student("田七",18));
tree.add(new Student("赵六",18));
for(Student ss : tree){
System.out.println(ss.getName() + "," + ss.getAge());
}
}
}
HashSet保证元素唯一源码分析
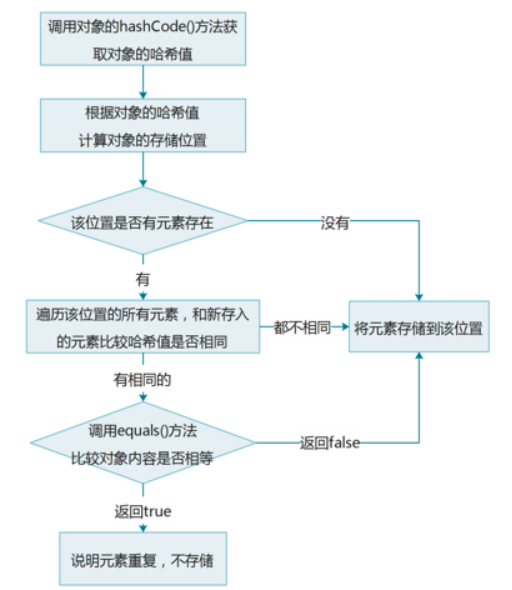
1、某个对象obj,在即将要存储到HashSet集合的时候,首先计算obj的hashCode值
2、在集合中的所有元素的哈希值,都和obj的哈希值不同,说明在集合中不存在obj,可以直接将obj存储到HashSet中
3、在集合中有若干元素的哈希值,和obj的哈希值相同,并不能说明obj已经存在于集合中,需要使用equals判断obj是否和那些与自己哈希值相同的元素是否相等
4、如果这些元素所有的和obj比较equals之后,都不相等,那么就说明obj不存在于集合中,可以将obj存储到HashSet中
5、如果这些元素有任意一个和obj比较equals之后,发现相等,那么就说明obj已经存在于集合中,所以obj就不能存储,存储失败
总结: 如果一个自定义的引用数据类型, 想通过成员变量决定去重复, 需要重写hashCode和equals两个方法
1、重写hashCode
相同的对象,一定要有相同的哈希值
不同的对象,尽量有不同的哈希值
操作:根据对象的属性来生成哈希值
2、重写equals方法:
比较的就是各个对象的属性值,是否全都相同
3、最终操作:
使用快捷键,直接全部生成:alt + insert
import java.util.Objects;
public class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && name.equals(person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
import java.util.HashSet;
public class Demo06_HashSet {
public static void main(String[] args) {
// 1. HashSet集合存储JDK定义好的数据类型 : String, Integer,Double...
// 直接可以保证去重复, 全部重写过HashCode和equals
HashSet<Integer> hash = new HashSet<>();
hash.add(12);
hash.add(10);
hash.add(9);
hash.add(12);
System.out.println(hash);// [9,10,12]
// 2. HashSet集合存储自定义引用数据类型 : Student, Person ,Animal...
// HashSet没有根据对象中的成员变量进行去重复动作
// 原因 : 分析源代码
// HashSet集合中的add方法
HashSet<Person> ha = new HashSet<>();
// 因为Person没有重写HashCode和equals方法,
// HashCode和equals源代码比较的都是对象的地址是否是同一个
ha.add(new Person("张三",15));
ha.add(new Person("李四",15));
ha.add(new Person("张三",15));
ha.add(new Person("李四",18));
for(Person per : ha){
System.out.println(per.getName() + "--" + per.getAge());
}
}
}
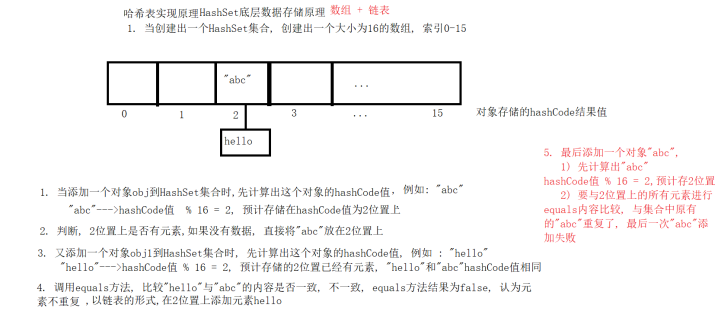
数据结构之哈希表
-
哈希值简介
哈希值是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值、
如何获取哈希值
Object类中的public int hashCode():返回对象的哈希码值
哈希值的特点
同一个对象多次调用hashCode()方法返回的哈希值是相同的
默认情况下,不同对象的哈希值是不同的。而重写hashCode()方法,可以实现让不同对象的哈希值相同
- 哈希表结构
- JDK1.8以前: 数组 + 链表
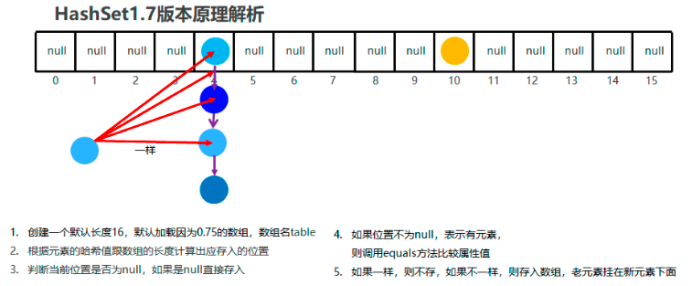
HashSet集合添加元素的模拟过程:
双列集合体系
Map概述
1、体系位置:双列集合的顶层接口
2、类比理解:map单词含义,地图,地图上的每个点,都表示了生活中的一个具体位置。地图的点和生活中的位置,有一个一一对应的关系,这种关系是通过穷举的方式来描述的。
3、数据结构:描述的就是一个数据(key)到另一个数据(value)的映射关系(对应关系)
4、Map<K,V>的特点:称为键值对映射关系(一对一)
Key(键)是唯一的(不重复),value(值)不是唯一的
每个键都只能对应确定唯一的值
5、Map集合没有索引, 因此存储的元素不能保证顺序

Map常用的子类
通过查看Map接口描述,看到Map有多个实现类,这里我们主要讲解常用的HashMap集合 LinkedHashMap集合.
HashMap<K,V>://存储数据采用的哈希表结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
LinkedHashMap<K,V>://HashMap下有个子类LinkedHashMap,存储数据采用的哈希表结构+链表结构。通过链表结构可以保证元素的存取顺序一致;通过哈希表结构可以保证的键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。
Map接口中常用的方法
1. public V put(K key, V value):
// 如果添加的key值在map集合中不存在, 那么put方法表示将键值对添加到map集合中
// 如果添加的key值在map集合中存在, 那么put方法表示修改value值
2. public V remove(Object key): //把指定的键所对应的键值对元素在Map集合中删除,返回被删除元素的值。
3. public V get(Object key)://根据指定的键,在Map集合中获取对应的值。
4. boolean containsKey(Object key): //判断集合中是否包含指定的键。
5. void clear() : //表示清空Map集合中所有键值对数据
6. boolean isEmpty() : //验证Map集合中是否还是键值对数据, 如果没有返回true, 如果有返回false
7. int size() : //获取到Map集合中键值对数据个数(求Map集合的长度)
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
public class Demo01_MapMethod {
public static void main(String[] args) {
// 1. 创建出一个Map双列集合
Map<Integer,String> map = new HashMap<>();
/*Map<Integer,String> map1 = new LinkedHashMap<>();
HashMap<Double,Integer> map2 = new HashMap<>();*/
//public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。
// 1) 如果添加的key值在map集合中不存在, 那么put方法表示将键值对添加到map集合中
map.put(1,"a");
map.put(2,"b");
map.put(3,"c");
System.out.println(map);// {1=a, 2=b, 3=c}
// 8) size()
System.out.println(map.size());// 3
// 2) 如果添加的key值在map集合中存在, 那么put方法表示修改value值
map.put(2,"替换");
System.out.println(map);// {1=a, 2=替换, 3=c}
// 3) remove(Object key) : 通过map集合中唯一的key值,删除键值对关系
String value = map.remove(1);
System.out.println(value);// a
System.out.println(map);// {2=替换, 3=c}
// 4) get(K key) : 通过参数的key值获取到对应的value值
String value1 = map.get(2);
String value2 = map.get(3);
System.out.println(value1 + "--" + value2);// 替换--c
// 5) containsKey(K key): map集合中是否包含参数中给出的key值, 如果包含返回true
// 否则返回false
boolean boo = map.containsKey(1);
boolean boo1 = map.containsKey(2);
System.out.println(boo + "--" + boo1);// false--true
// 6) clear():
map.clear();
System.out.println(map);// {}
// 7) isEmpty():
System.out.println(map.isEmpty());// true
// 8) size()
System.out.println(map.size());// 0
}
}
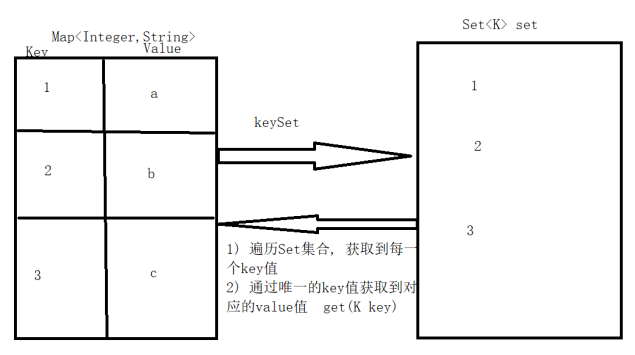
Map集合的遍历方式
键遍历
1、获取Map集合中的所有键,放到一个Set集合中,遍历该Set集合,获取到每一个键,根据键再来获取对应的值。【根据键获取值】
2、获取Map集合中的所有键
Set<K> keySet()
3、遍历Set集合的两种方法:
- 迭代器
- 增强for循环
4、拿到每个键之后,获取对应的值
V get(K key)
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Demo02_Map遍历1 {
public static void main(String[] args) {
// 1. 创建出一个Map双列集合
Map<Integer,String> map = new HashMap<>();
map.put(1,"a");
map.put(2,"b");
map.put(3,"c");
// 2. 通过keySet获取到所有的key值
Set<Integer> set = map.keySet();
// 3. 遍历set集合,获取到每一个Key值
for(Integer key : set){
System.out.println(key + "---" + map.get(key));
}
}
}
键值对遍历
-
获取Map<K,V>集合中,所有的键值对(Entry)对象,以Set集合形式返回。方法提示:entrySet()。
-
遍历包含键值对(Entry)对象的Set集合,得到每一个键值对(Entry)对象。
-
通过键值对(Entry)对象,获取Entry对象中的键与值。 方法提示:getkey(), getValue()
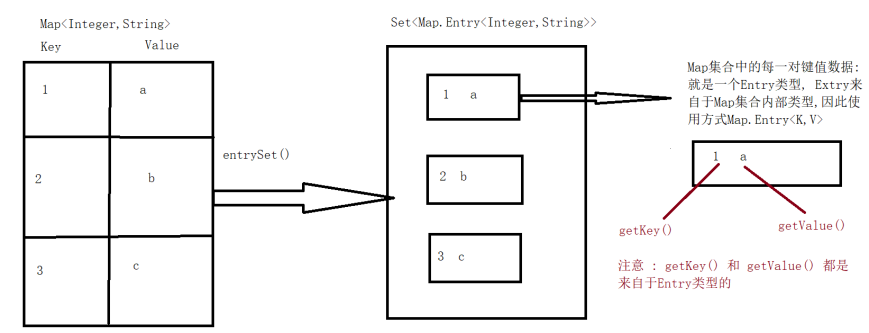
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Demo03_Map遍历2 {
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("1",99);
map.put("11",88);
map.put("2",14);
map.put("a",99);
// System.out.println(map);// {11=88, 1=99, a=99, 2=14}
Set<Map.Entry<String,Integer>> set = map.entrySet();
for(Map.Entry<String,Integer> entry : set){
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + "---" + value);
}
}
}
HashMap中key值唯一分析
1、HashMap就是Map集合使用哈希表的存储方式的一种实现类
2、HashMap存储的是jdk中提供的类型的键,就可以直接保证键的唯一性
3、HashMap中存储的键,是自定义类型,无法保证键的唯一性;原因:虽然都是张三、23,但是这些对象并不是相同的对象,这些对象的哈希值计算结果各不相同,就说明一定不是相同的对象,所以无法保证键的唯一。重写hashCode和equals方法
说明:HashMap的键的唯一性和HashSet的元素的唯一性,保证方式都一样
4、HashMap和HashSet的关系:
- HashSet是由HashMap实现出来的,HashSet就是HashMap的键的那一列
- 将HashMap中的值的那一列隐藏掉,就变成了HashSet
HashSet保证元素唯一原理, 就是使用了HashMap中Key值唯一的原理

import java.util.Objects;
public class Student {
private String name;
private int age;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
import java.util.HashMap;
import java.util.HashSet;
import java.util.Set;
public class Demo05_HashMap中Key值唯一 {
public static void main(String[] args) {
/*
HashSet--->哈希表结构
通过: add(Object obj) 决定对象是否可以存储在set集合中
* HashMap--->中的key值也是哈希表结构
通过: put(K key, V value) 决定键值对是否能添加到map集合中
*
* 通过源代码发现 : HashSet中的add方法, 实际上就是的调用了HashMap中的put方法, 因此HashSet中元素唯一, 与HashMap中key值唯一的原理一致, 都是哈希表结构
如果存储自定义类型, 并且想通过成员变量进行去重复, 需要alt + insert 自动
重写hashCode和equals方法
* */
HashMap<Student,String> hash = new HashMap<>();
hash.put(new Student("张三",15),"新加坡");
hash.put(new Student("李四",15),"香港");
hash.put(new Student("张三",16),"北京");
hash.put(new Student("王五",18),"上海");
hash.put(new Student("王五",18),"深圳");
Set<Student> set = hash.keySet();
for(Student s : set){
System.out.println(s.getName() + "--" + s.getAge()+ "--" + hash.get(s)) ;
}
}
LinkedHashMap
1、是HashMap的一个子类
2、和HashMap的不同之处在于,具有可预知的迭代顺序,存储键值对的顺序和遍历集合时取出键值对的顺序一致。
扩展: LinkedHashSet: 是HashSet的子类, 与HashSet 的不同在于, LinkedHashSet维护了一个双向链表, 作用 : 保证存储在set集合中的元素有序(存和取的顺序一致, 其他功能完全与HashSet父类一致)
LinkedHashMap代码
import java.util.LinkedHashMap;
import java.util.Set;
public class Demo06_LinkedHashMap {
public static void main(String[] args) {
LinkedHashMap<Student,String> hash = new LinkedHashMap<>();
hash.put(new Student("张三",15),"新加坡");
hash.put(new Student("李四",15),"香港");
hash.put(new Student("张三",16),"北京");
hash.put(new Student("王五",18),"上海");
hash.put(new Student("王五",18),"深圳");
Set<Student> set = hash.keySet();
for(Student s : set){
System.out.println(s.getName() + "--" + s.getAge()+ "--" + hash.get(s)) ;
}
}
}
LinkedHashSet代码
import java.util.HashSet;
import java.util.LinkedHashSet;
public class Demo07_LinkedHashSet {
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<>();
set.add(12);
set.add(1);
set.add(6);
set.add(10);
System.out.println(set);// [1, 6, 10, 12]
LinkedHashSet<Integer> set1 = new LinkedHashSet<>();
set1.add(12);
set1.add(1);
set1.add(6);
set1.add(10);
System.out.println(set1);// [12, 1, 6, 10]
}
}
Collections 工具类
可变参数的使用和注意事项
-
概述: 可变参数又称参数个数可变,用作方法的形参出现,那么方法参数个数就是可变的了,方法的参数类型已经确定,个数不确定,我们可以使用可变参数.
-
格式:
修饰符 返回值类型 方法名(数据类型...变量名) { // 可变参数可以表示的参数个数0-n
}
- 注意事项:
可变参数在方法中其实是一个数组
如果一个方法有多个参数,包含可变参数,可变参数必须要放在最后
方法中只能有一个可变参数
案例 : 定义出一个方法功能, 求任意个数整的累加和
public class Demo01_可变参数 {
public static void main(String[] args) {
// 可变参数可以表示0-n个数据
System.out.println(getSum());// 0
System.out.println(getSum(5));// 5
System.out.println(getSum(2,3,4,67));// 76
// 可变参数也可以是一个指定类型的数组传递
int[] arr = {12,14,16};
System.out.println(getSum(arr));// 42
}
// 案例 : 定义出一个方法功能, 求任意个数整的累加和
public static int getSum(int...x){
// 1) 可变参数在方法中相当于是一个数组
int sum = 0;
for(int i : x){
sum += i;
}
return sum;
}
// 可变参数使用的注意事项
// 1) 方法参数列表中, 如果设计出可变参数, 这个可变参必须是最后一个参数
// 2,5,6,7
public static void getSum1(double d, int...x){
}
// 如果可变参数不设计在最后,那么实际参数无法进行明确的划分
// 2--->2数据,无法明确出是x赋值, 或者d赋值? 不允许发生, 在Java中就是语法结构错误
/*public static void getSum2(int...x,double d){
}*/
// 2) 一个方法中只能有一个可变参数
public static void getSum3(double d, double d1){
}
// 2,3,4,5--->实际参数, 无法划分哪些数据是给d赋值, 哪些给d1赋值
/*public static void getSum4(double...d, double...d1){
}*/
}
Collections单列集合工具类常用功能
-
Collections类是一个单列集合的工具类,在类中封装类很多常用的操作集合的方法.因为Collections工具类中, 没有对外提供构造方法, 因此不能创建对象, 导致类中所有成员和方法全部静态修饰, 类名.直接调用
-
Collections类中的常用方法:
sort(List<T> list): //将指定的列表按升序排序,从小到大
max、min(Collection c)://获取集合的最大值或者最小值
replaceAll(List<E> list, E oldVal, E newVal)://将集合list中的所有指定老元素oldVal都替换成新元素newVal
reverse(List<E> list)://将参数集合list进行反转
shuffle(List<E> list)://将list集合中的元素进行随机置换
import java.util.ArrayList;
import java.util.Collections;
public class Demo02_Collections {
public static void main(String[] args) {
// 1. sort(List<T> list): 默认将集合中元素进行升序排序
ArrayList<Integer> list = new ArrayList<>();
list.add(12);
list.add(1);
list.add(999);
list.add(10);
list.add(12);
Collections.sort(list);
System.out.println(list);// [1, 10, 12, 12,999]
// 2. max、min(Collection c):获取集合的最大值或者最小值
System.out.println(Collections.max(list));// 999
System.out.println(Collections.min(list));// 1
// 3. replaceAll(List<E> list, E oldVal, E newVal):
// 将集合list中的所有指定老元素oldVal都替换成新元素newVal
Collections.replaceAll(list,12,888);
System.out.println(list);// [1, 10, 888, 888, 999]
// 4. reverse(List<E> list):将参数集合list进行反转
Collections.reverse(list);
System.out.println(list);// [999, 888, 888, 10, 1]
// 5. shuffle(List<E> list): 将参数list集合中的元素进行随机的混乱排序
Collections.shuffle(list);
System.out.println(list);
}
}
集合的使用总结:
-
集合分类: 单列集合(Collection), 双列集合(Map)
-
分类区别 : 单例集合, 每一个对象数据都是一个独立的个体存储在集合中
双列集合, 一对元素作为一个整体存储在集合中
- 集合的使用场景和区别:
1.单列集合 :
List : //存取有序, 有索引, 可以存储重复元素
ArrayList : //主要使用在统计查询(实际开发中使用最多的单列集合)
LinkedList : //主要使用在增加和删除
Set : //存取无序, 没有索引 , 不存储重复元素
TreeSet : //主要使用在存储的元素需要有指定排序规则
HashSet: //底层主要哈希表结构, 数组 + 链表存储形式, 存取无序
LinkedHashSet : //作为HashSet子类, 作用, 可以让集合中的元素存取有序
注意 : 如果自定义的引用数据类型要存储在Set集合中, 并且通过成员变量进行去重复动作, 那么需要使用alt + insert快捷键, 生成hashCode和equals方法的重写
2.双列集合: 使用在数据需要有对应关系存储的情况下
HashMap : //哈希表结构, 数组 + 链表实现, HashMapKey值唯一原理与HashSet一致, 底层使用同一套代码
注意 : 如果自定义的引用数据类型作为了HashMap的key值进行存储, 并且通过成员变量进行去重复动作, 那么需要使用alt + insert快捷键, 生成hashCode和equals方法的重写
LinkedHashMap : //作为HashMap子类, 作用, 可以让集合中的元素存取有序
