

深度学习笔记4:在卷积基上添加数据增强代码块和分类器
特征提取的另一种方式是将原有模型与一个新的密集分类器相连接,以构建一个新的模型,然后对整个模型进行端到端的训练。这种方法在输入数据上进行整体训练,使模型能够更好地适应数据特性并提取更有效的特征。通过这种方式,模型的性能可以得到进一步提高,同时也能更好地捕捉到数据中的复杂模式。
冻结卷积基
from tensorflow import keras conv_base = keras.applications.vgg16.VGG16( weights="imagenet", include_top=False, #input_shape=(180, 180, 3) ) conv_base.trainable = False
在卷积基上添加数据增强代码块和分类器
data_augmentation = keras.Sequential([ layers.RandomFlip("horizontal"), layers.RandomRotation(0.1), layers.RandomZoom(0.2), ]) inputs = keras.Input(shape=(180, 180, 3)) x = data_augmentation(inputs) x = keras.applications.vgg16.preprocess_input(x) x = conv_base(x) x = layers.Flatten()(x) x = layers.Dense(256)(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs, outputs) model.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=["accuracy"])
加载训练数据
import pathlib batch_size = 32 img_height = 180 img_width = 180 new_base_dir = pathlib.Path('C:/Users/wuchh/.keras/datasets/dogs-vs-cats-small') train_dataset = keras.preprocessing.image_dataset_from_directory( new_base_dir / 'train' , validation_split=0.2, subset="training", seed=123, image_size=(img_height, img_width), batch_size=batch_size ) validation_dataset = keras.preprocessing.image_dataset_from_directory( new_base_dir / 'train' , validation_split=0.2, subset="validation", seed=123, image_size=(img_height, img_width), batch_size=batch_size ) test_dataset = keras.preprocessing.image_dataset_from_directory( new_base_dir / 'test' , seed=123, image_size=(img_height, img_width), batch_size=batch_size )
训练模型
callbacks = [keras.callbacks.ModelCheckpoint( filepath="feature_extraction_with_data_augmentation.model", save_best_only=True, monitor="val_loss")] history = model.fit( train_dataset, epochs=50, validation_data=validation_dataset, callbacks=callbacks)
绘制训练结果
import matplotlib.pyplot as plt acc = history.history["accuracy"] val_acc = history.history["val_accuracy"] loss = history.history["loss"] val_loss = history.history["val_loss"] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, "bo", label="Training accuracy") plt.plot(epochs, val_acc, "b", label="Validation accuracy") plt.title("Training and validation accuracy") plt.legend() plt.figure() plt.plot(epochs, loss, "bo", label="Training loss") plt.plot(epochs, val_loss, "b", label="Validation loss") plt.title("Training and validation loss") plt.legend() plt.show()
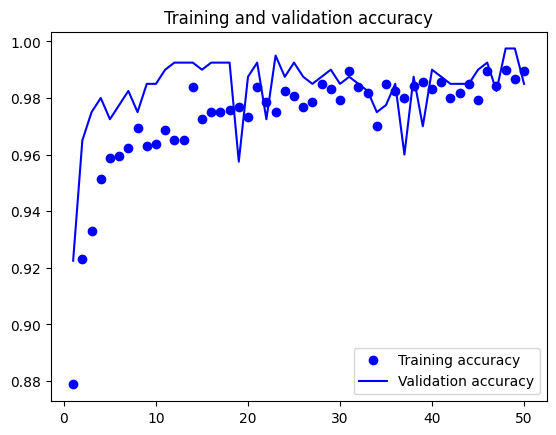
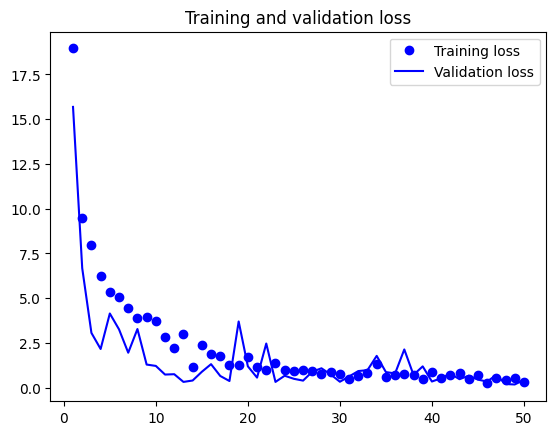
在测试集上评估模型
test_model = keras.models.load_model("feature_extraction_with_data_augmentation.model") test_loss, test_acc = test_model.evaluate(test_dataset) print(f"Test accuracy: {test_acc:.3f}") 32/32 [==============================] - 15s 452ms/step - loss: 2.0066 - accuracy: 0.9790 Test accuracy: 0.979
总之,鉴于模型在验证数据上取得的好结果,这有点令人失望。模型的精度始终取决于评估模型的样本集。有些样本集可能比其他样本集更难以预测,在一个样本集上得到的好结果,并不一定能够在其他样本集上完全复现。


