

深度学习笔记1:在小型数据集上从头开始训练一个卷积神经网络
本文将介绍如何在一个小型的数据集上使用卷积神经网实现图片的分类。在这个例子中,我们将使用一个经典的数据集,包含24000张猫狗图片(12000张猫的图片和12000张狗的图片),提取2000张用于训练和验证,1000张用于测试。我们将首先在2000个训练样本上训练一个简单的小型卷积神经网络模型,然后介绍如何解决过拟合问题,以提高分类精度。
下载数据
import tensorflow as tf import pathlib dataset_url = "https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_5340.zip" data_dir = tf.keras.utils.get_file('dogs-vs-cats', origin=dataset_url, untar=True) data_dir = pathlib.Path(data_dir)
下载完成后笔者的目录结构如下,如果你的目录结构不对自行解压缩压缩包。

构建小数据集
import os, shutil, pathlib import numpy as np def make_subset(subset_name, start_index, end_index): for category in ("cat", "dog"): dir = new_base_dir / subset_name / category src_dir = original_dir / category print(dir) os.makedirs(dir) fnames = [f"{i}.jpg" for i in range(start_index, end_index)] for fname in fnames: shutil.copyfile(src=src_dir / fname, dst=dir / fname) start_index = np.random.randint(0,8000) end_index = start_index + 1000 start_index3 = end_index end_index3 = start_index3 + 500 original_dir = pathlib.Path('C:/Users/FQ/.keras/datasets/dogs-vs-cats') new_base_dir = pathlib.Path('C:/Users/FQ/.keras/datasets/dogs-vs-cats_small') make_subset("train", start_index=start_index, end_index=end_index) make_subset("test", start_index=start_index3, end_index=end_index3)
查看数据集随机图片
import matplotlib.pyplot as plt from PIL import Image fig,ax = plt.subplots(2,4, figsize=[16,8]) cat_fnames = [f"{i}.jpg" for i in np.random.randint(start_index,start_index+1000,4)] dog_fnames = [f"{i}.jpg" for i in np.random.randint(start_index,start_index+1000,4)] for k in range(4): img = Image.open(new_base_dir / 'train' / 'Cat' / cat_fnames[k]) ax[0][k].imshow(img) img = Image.open(new_base_dir / 'train' / 'Dog' / dog_fnames[k]) ax[1][k].imshow(img) plt.show()
构建模型
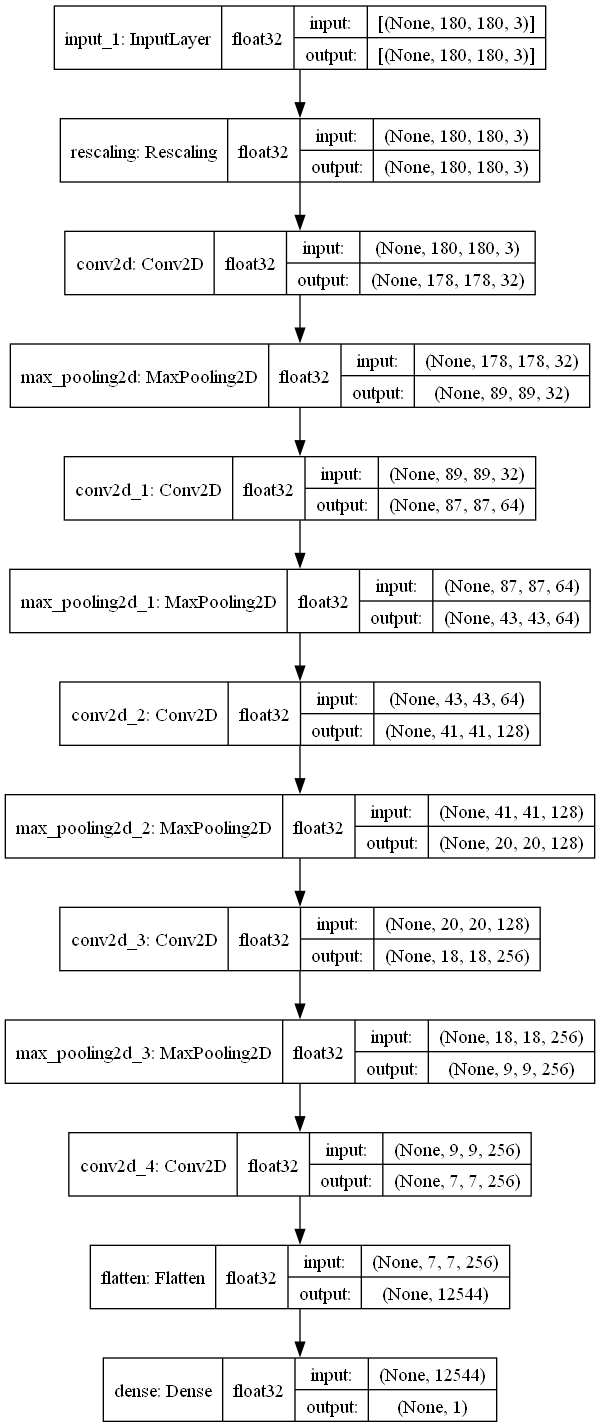
from tensorflow import keras from tensorflow.keras import layers inputs = keras.Input(shape=(180, 180, 3)) x = layers.Rescaling(1./255)(inputs) x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=64, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=128, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x) x = layers.MaxPooling2D(pool_size=2)(x) x = layers.Conv2D(filters=256, kernel_size=3, activation="relu")(x) x = layers.Flatten()(x) outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs=inputs, outputs=outputs) model.compile(loss="binary_crossentropy",optimizer="rmsprop",metrics=["accuracy"])
>>> model.summary() Model: "model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 180, 180, 3)] 0 _________________________________________________________________ rescaling (Rescaling) (None, 180, 180, 3) 0 _________________________________________________________________ conv2d (Conv2D) (None, 178, 178, 32) 896 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 89, 89, 32) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 87, 87, 64) 18496 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 43, 43, 64) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 41, 41, 128) 73856 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 20, 20, 128) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 18, 18, 256) 295168 _________________________________________________________________ max_pooling2d_3 (MaxPooling2 (None, 9, 9, 256) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 7, 7, 256) 590080 _________________________________________________________________ flatten (Flatten) (None, 12544) 0 _________________________________________________________________ dense (Dense) (None, 1) 12545 ================================================================= Total params: 991,041 Trainable params: 991,041 Non-trainable params: 0 _________________________________________________________________ >>>
安装plot_model依赖包
pip install pydot graphviz
这里有个细节要注意安装
graphviz
需要从网址https://graphviz.gitlab.io/download/下载对应系统的安装文件包。
查看模型细节图
keras.utils.plot_model(model, 'model-cats-vs-dogs.png',show_shapes=True,show_dtype=True,show_layer_names=True)
数据预处理
import pathlib new_base_dir = pathlib.Path('C:/Users/FQ/.keras/datasets/dogs-vs-cats_small') batch_size = 32 img_height = 180 img_width = 180 new_base_dir = pathlib.Path('C:/Users/FQ/.keras/datasets/dogs-vs-cats_small') train_dataset = keras.preprocessing.image_dataset_from_directory( new_base_dir / 'train' , validation_split=0.2, subset="training", seed=123, image_size=(img_height, img_width), batch_size=batch_size) validation_dataset = keras.preprocessing.image_dataset_from_directory( new_base_dir / 'train' , validation_split=0.2, subset="validation", seed=123, image_size=(img_height, img_width), batch_size=batch_size)
模型训练
callbacks = [keras.callbacks.ModelCheckpoint(filepath="convnet_from_scratch.keras",save_best_only=True, monitor="val_loss")] history = model.fit(train_dataset,epochs=30,validation_data=validation_dataset,callbacks=callbacks)
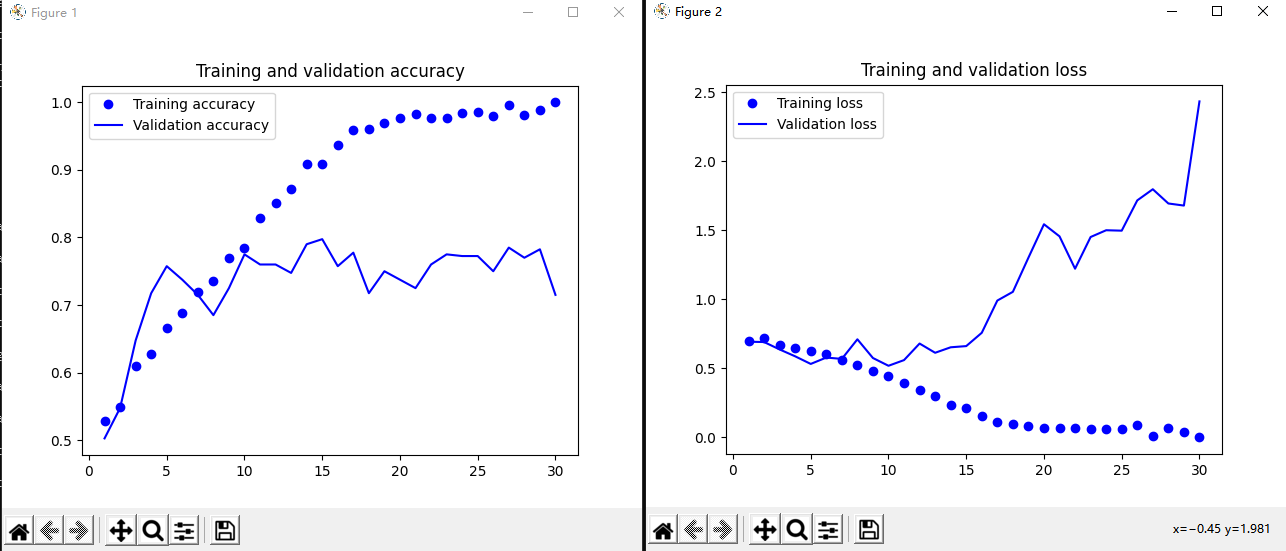
绘制训练过程中的精度曲线和损失曲线
在测试集上评估模型
test_dataset = keras.preprocessing.image_dataset_from_directory( new_base_dir / 'test' , seed=123, image_size=(img_height, img_width), batch_size=batch_size) test_model = keras.models.load_model("convnet_from_scratch.keras") test_loss, test_acc = test_model.evaluate(test_dataset) print(f"Test accuracy: {test_acc:.3f}")
>>> test_model = keras.models.load_model("convnet_from_scratch.keras") >>> test_loss, test_acc = test_model.evaluate(test_dataset) 3/32 [=>............................] - ETA: 2s - loss: 0.5123 - accuracy: 0.7812Corrupt JPEG data: 2226 extraneous bytes before marker 0xd9 9/32 [=======>......................] - ETA: 1s - loss: 0.5634 - accuracy: 0.7500Corrupt JPEG data: 1153 extraneous bytes before marker 0xd9 32/32 [==============================] - 3s 70ms/step - loss: 0.5924 - accuracy: 0.7330
由于存在过拟合问题,我们在小数据集上训练的模型在测试数据集上的表现并不理想,只达到了0.7330的测试精度。在下一章节中,我们将介绍一种有效的方法来解决过拟合问题,即数据增强。通过数据增强,我们可以生成更多的训练数据,从而降低模型过拟合,提高模型的泛化能力。


