

Spark高可用集群搭建
node1 node2 node3
1.node1修改spark-env.sh,注释掉hadoop(就不用开启Hadoop集群了),添加如下语句
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark20170302"

2.同步到其他spark节点node2,node3

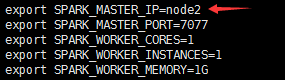
3.node2中spark-env.sh修改master为node2
4.启动spark集群--Spark run on Standalone

node2中启动master,这样master就成高可用了
sbin下./start-master.sh
5.测试Spark高可用


./bin/spark-submit --class org.apache.spark.examples.SparkPi--master spark://node1:7077,node2:7077 --driver-memory 512m --deploy-mode cluster --supervise --executor-memory 512M --total-executor-cores 1 ./lib/spark-examples-1.6.0-hadoop2.6.0.jar 100000
kill -9 node1中master的进程,看是否还能继续执行

