树状数组 - 区间可加可拼凑的信息
I.综述&解释
树状数组,一听就知道是长得像树的数组。emm
其内部节点的长度都是2的整数次幂,用一个数组存储,这样做利用了“任意一个正整数都能被唯一分解为不同的若干二的次幂的和的形式”这个定理,从而可用若干节点之和拼凑成为一个整体,表示一个前缀区间的信息。
II.起源
树状数组最基础的用法是用于维护前缀和的。
不过如果只需要维护前缀信息,那么任意一个满足区间可加性的二元运算符均可。
它本质上还是一种分治、倍增的思想,其实只是借助2的性质进行信息分割,不过就因为以上定理(从0开始加),使其只能维护前缀信息。
无关话题:
至于网上有人搞出的那些可维护区间最大值的树状数组,我认为实际上只是借了树状数组的名头在做分块罢了,其实读来有“有则用之,无则作罢”的感觉。现贴出博客链接Link
就比如它的修改操作:
void update(int position){
int len_x;
while(position<=n){
len_x=lowbit(position);
h[position]=a[position];
for(int i=1;i<len_x;i<<=1){
h[position]=max(h[position],h[position-i]);
}
position+=len_x;
}
}你仔细读,它实际上是在普通的修改过程中加了一次特殊的修改,这就意味着进行了以下操作:
看见了吗,它把每个受影响区间重构了!
这点,在OI-wiki上有解释:
事实上,对于不可差分信息,不存在通过 p 直接修改 c[y] 的方式。这是因为修改本身就相当于是把旧数从原区间「移除」,然后加入一个新数。「移除」时对区间信息的影响,相当于做「逆运算」,而不可差分信息不存在「逆运算」,所以无法直接修改 c[y]。
那么查询呢?
int query(int x, int y) {
int ans=0;
while(y>=x) {
ans=max(ans,a[y]), --y;
while(y-lowbit(y)>=x) {
ans=max(ans,b[y]);
y-=lowbit(y);
}
}
return ans;
}可以看到,这个查询就是这样的过程:
我们还是基于之前的思路,从 r 沿着 一直向前跳,但是我们不能跳到 l 的左边。
因此,如果我们跳到了 ,先判断下一次要跳到的 是否小于 l:
如果小于 l,我们直接把 单点 合并到总信息里,然后跳到。 如果大于等于 l,说明没越界,正常合并,然后跳到 即可。
所以我才说它是为了迎合条件有则用之,无则作罢
算法时间复杂度劣于线段树
当然,这是因为其存储与索引方式的无奈之举,在我们讨论了线段树后就知道,线段树能更有效的对区间执行二进制划分
对于有更多性质的运算,例如满足区间可减性的运算(e.g. +)还可以求区间。
它还能便捷地将区间修改转化为单点操作差分数组。
III.基本操作
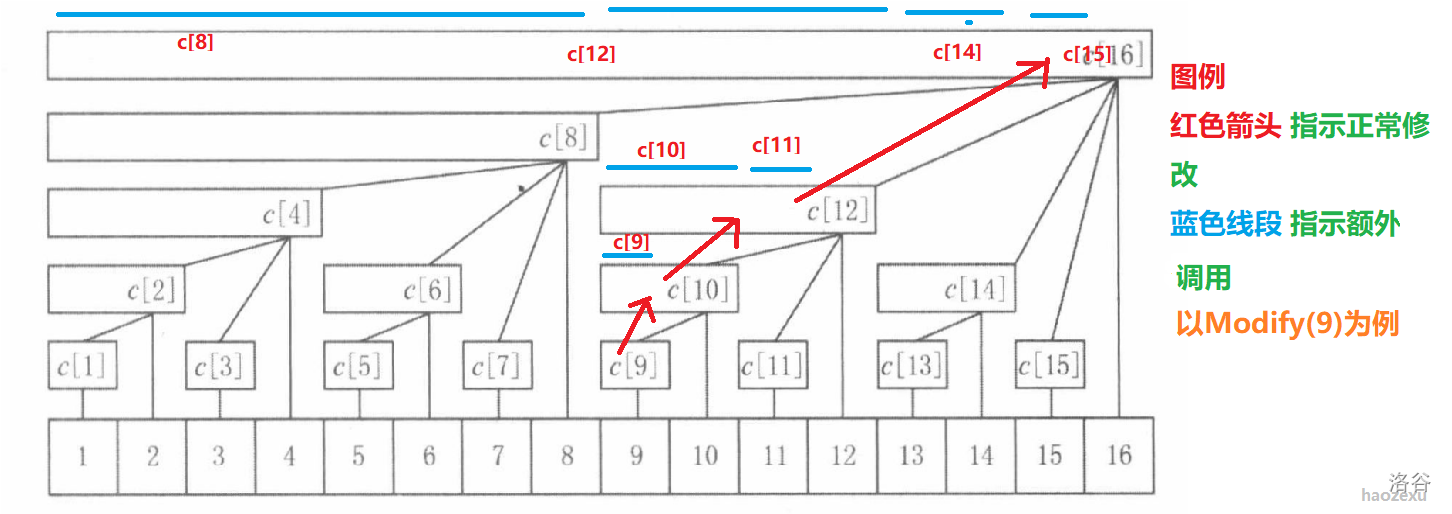
- 单点修改(modify)
对修改的起点“向上”对所有包括它的父节点进行修改,这里利用了一个技巧,快速地找出它的父节点,即lowbit运算。因为实际上二进制表示下每一个1都是代表2的次幂,即一个区间的长度。
- 单点查询
对查询的节点“向下”(其实不准确,因为这些点不是包含关系的)累计答案。也借助lowbit运算。
本文来自博客园,作者:haozexu,转载请注明原文链接:https://www.cnblogs.com/haozexu/p/18281778
