volatile关键字是干啥用的呢?
关键字:
可见性:当一个修改一个共享变量时,另一个线程可以读取到修改的值
内存屏障:是一组处理器指令,用于实现对内存操作顺序的限制
缓存行:缓存中可以分配的最小存储空间,处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期
原子操作:不可中断的一个或一系列操作
缓存行填充:当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个缓存行到适当的缓存(L1,L2,L3的或所有)
缓存命中:如果进行高速缓存操作的内存位置任然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是内存中
写命中:当处理器将操作数写回到一个内存的区域时,他会首先检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存中
写缺失:一个有效的缓存行被写入到不存在的内存区域
volatile简介:保证共享变量可见性,属于轻量级的synchronized,,但是比synchronized的使用和执行成本低,不会引起上下文切换与调度
再给volatile修饰的值赋值时候,会用到lock前缀指令,lock前缀指令的作用:
1、将当前缓存行的数据写回到内存中
2、这个写回内存的操作会使在其他cpu里缓存了该内存地址的数据无效
为了提高运行速率,处理器不会直接读取内存中的数据,而是将内存中的数据缓存在内部缓存中,内部缓存是以缓存行为单位进行工作的,在没有volatile关键字修饰的情况下,处理器只会与内部缓存交互,当我们程序修改内部缓存中值的情况下,不知道什么时候才能写回到内存中(synchronized关键字除外),即便写到了内存中,其他线程也不一定能够及时读取到修改后的最新值。
volatile修饰过的变量在进行写操作时,会向处理器发送一个lock前缀指令,将这个变量所在缓存行的变量写回到内存中,但是即便写回到内存中,其他线程依旧读取的是旧值,程序运行依旧有问题,因此就在多核心处理器下,为了保证每个处理器缓存区数据一致,就有了MESI缓存一致性协议,每个处理器通过总线嗅探机制自己缓存的数据是否过期,当处理器发现自己缓存行数据所对应的地址被修改时,就会将当前缓存行设置为无效状态,,当处理器对该缓存行数据进行修改时,会重新从内存中读取该数据到处理器中
MESI缓存一致性协议的两条实现原则:
一、Lock前缀指令会引起处理器缓存回写到内存中:
lock前缀指令导致在执行指令期间声言处理器的lock信号,在多处理器中,lock信号确保在声言该信号期间,处理器可以独享任何共享内存(这样做消耗过大,在最近的处理器里一般不会锁总线,因为锁住总线会导致总线不能被CPU访问,也就意味着不能访问系统内存,而是锁缓存)
1.M 修改 (Modified) 这行数据有效情况下,缓存行数据被修改了,与主内存中的数据不一致情况下,数据只存在于本处理器缓存中,该数据为M状态。
2.E 独享 (Exclusive) 这行数据有效,数据和主内存中的数据一致,数据只存在于本处理器缓存中(可以理解为单核处理器情况下,数据缓存与内存中数据一致)。
3.S 共享 (Shared) 这行数据有效,数据和主内存中的数据一致,数据存在于很多处理器缓存中
4. I 无效 (Invalid) 这行数据无效,当总线嗅探机制发现处理器缓存中数据与主内存数据不一直情况下,会将缓存中数据置为无效
二、volatile 的优化
LinkedTransferQueue:在使用volatile修饰时,会使用增加字节的方式来优化出队与入队的性能(使用许多4个字节的引用增加到64个字节)
为什么追加到64个字节能够提高并发编程效率呢?
多数处理器的L1,L2,L3缓存的高速缓存行都是64个字节宽,不支持部分填充,如果队列的头节点与尾节点都不足64个字节的话处理器会将他们读取到同一个缓存行,在多处理器下,每个处理器都会缓存同样的头节点和尾节点,当一个处理器试图修改头节点时,会将整个缓存行锁定,那么在缓存一致性机制的作用下,那么,会导致其他处理器不能访问自己高速缓存的尾节点,从而严重影响了队列的执行效率,从而在该队列中将其追加到64个字节后,使其不在同一个缓存行中,防止其头节点与尾节点相互锁定。当然也有部分处理器缓存行为32个字节,只需补齐到32个字节,也能达到同样的效果;如果共享变量如果不会被经常刷新的话也没必要补充字节(毕竟这是一种以空间换时间的做法)
注意:在jdk7下单纯的增加无用字段是无法达到这样效果的,jdk会淘汰货重新排列无用字段,需要使用其他方式来扩充(如将无用字段写在父类中继承)
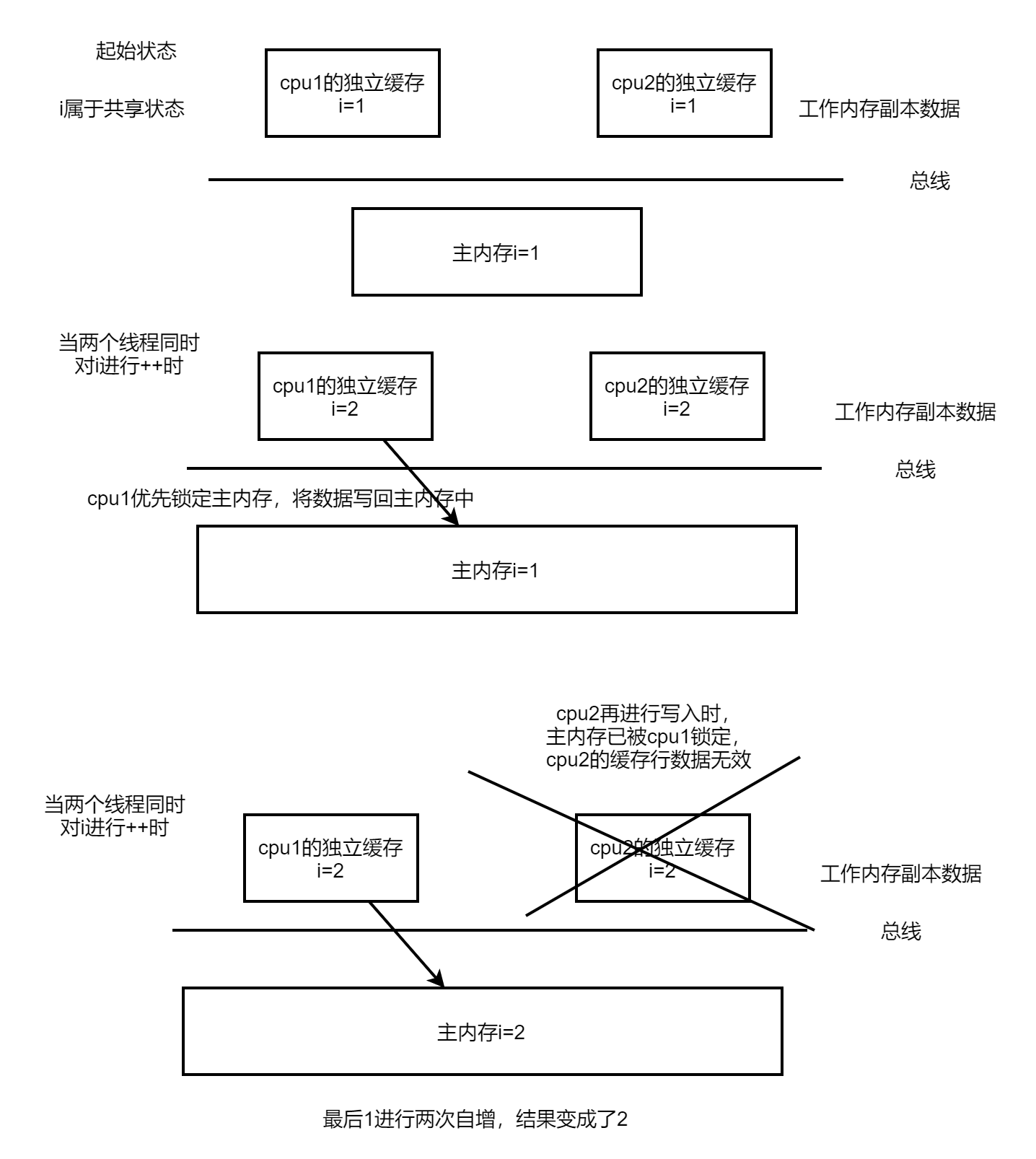
三、volatile关键字不能保证原子性?
| CPU1 | CPU2 |
| i=1 | i=1 |
| i+1 | i+1 |
| i=2 | i=2 |