
re模块
-
re模块就是python中的正则模块,何为正则?正则就是通过特殊的表达式去匹配想要得到的字符串,本文主要介绍re模块的用法,基础的学习一下re
-
help(re.match) : re.match(pattern, string, flags=0)
-
pattern: 正则表达式
-
string: 要匹配的字符串
-
flags: 标志位,用于控制正则的匹配方式,例如不区别大小写
-
-
re.match用于从开头查找,在开头匹配不到就会结束
In [6]: data = 'abcdef' In [7]: res = re.match('a',data) In [8]: res1 = re.match('b',data) In [9]: print(res) # 开始是a所以匹配得到 Out[9]: <_sre.SRE_Match object; span=(0, 1), match='a'> In [10]: print(res1) # 开头不是b所以匹配不到 None
# 可以看到上面输出的是一些信息,没有实际的取到值,是要通过group来取值的,0代表所有值,1代表第一个,默认为0In [11]: res.group(0) Out[11]: 'a' In [12]: res1.group(0) # 没有值则会报错 --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-19-e9206ea902b3> in <module> ----> 1 res1.group(0) AttributeError: 'NoneType' object has no attribute 'group'
# 匹配过程:
匹配值 = 'abcdef'
表达式 = 'a'
a == a -> 结束
表示是 = 'b'
a != b -> 结束 -
help(re.search) : re.search(pattern, string, flags=0)
-
re.search是从头开始匹配,直到匹配到值结束 In [25]: data = 'abcdef' In [26]: res = re.search('b',data) In [27]: res.group(0) # 没有从开头匹配也可以匹配到 Out[27]: 'b # 匹配过程 匹配值 = abcdef 表达式 = b 每次取一个值: a != b -> b == b -> a -> 结束
-
-
help(re.findall) : findall(pattern, string, flags=0)
-
findall查找字符串中所有匹配字符
In [29]: res = 'a1b2c3d4f5' In [30]: re.findall('\d',res) # \d 代表一个数字 Out[30]: ['1', '2', '3', '4', '5'] # 匹配过程 匹配值 = 'a1b2c3d4f5' 表达式 = '\d' a != '\d' -> 1 == '\d' 继续匹配-> -> b != '\d' -> 2 == '\d' 一直匹配到没有值 将所有的值生成为一个列表['1','2','3','4','5']
-
-
help(re.sub): sub(pattern, repl, string, count=0, flags=0)
-
用于字符串的替换
-
pattern: 匹配的字符串
-
repl: 替换成的字符串
-
string:要被查找替换的字符串
-
count: 要被替换的次数
In [32]: data = 'shui zui shuai' In [33]: a = re.sub('shui','wo',data) In [34]: a 'wo zui shuai' In [39]: data = 'wo ni wo ta wo' In [40]: re.sub('wo','dingh',data,2) # 只替换两次 Out[40]: 'dingh ni dingh ta wo'
-
-
-
help(re.compile) : compile(pattern, flags=0)
-
用于编译正则,生成一个正则对象,re.match、re.search、re.findall可以调用
In [43]: reg = re.compile('\d') In [44]: data = 'a1b2c3' In [45]: re.search(reg,data) Out[45]: <_sre.SRE_Match object; span=(1, 2), match='1'> In [46]: res = re.search(reg,data) In [47]: res.group(0) Out[47]: '1'
-
re模块中的标志位(网上摘抄)
-
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为: re.I 忽略大小写 re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境 re.M 多行模式 re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符) re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库 re.X 为了增加可读性,忽略空格和 # 后面的注释
-
-
-
正则表达式的特殊语法
-
. 代表任意单个字符
# 除了换行符以外的所有字符例如:a 2 + ^等等 In [61]: data = '123aaa' In [62]: re.match('.',data).group(0) Out[62]: '1'
-
* 代表前面的字符出现多次
In [50]: data = '123aaa' In [51]: re.match('\d*',data).group(0) Out[51]: '123'
-
? 代表前面的字符出现一次或者零次
In [53]: data = '123aaa' In [54]: re.match('\d?',data).group(0) Out[54]: '1'
-
+ 代表前面的字符出现一次或者多次
In [55]: data = '123aaa' In [56]: re.match('\d+',data).group(0) Out[56]: '123'
-
[] 代表一个范围、一组字符
In [63]: data = 'aaa123BB [0-9] # 代表所有单个数字 In [64]: re.search('[0-9]+',data).group(0) Out[64]: '123' [a-z] # 代表所有单个小写字母 In [65]: re.search('[a-z]+',data).group(0) Out[65]: 'aaa' [A-Z] # 代表所有单个大写字母 In [67]: re.search('[A-Z]+',data).group(0) Out[67]: 'BB' In [70]: data = '1aZ' In [71]: re.search('[0-9][a-z][A-Z]',data).group(0) Out[71]: '1aZ'
-
{} 代表出现次数范围
In [75]: data = '123456' In [76]: re.search('[0-9]{,3}',data).group(0) Out[76]: '123' In [81]: data = '123' In [82]: re.search('[0-9]{4,5}',data).group(0)#一共只有3个字符,但是却最少匹配4次 --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-83-51e38933f9ea> in <module> ----> 1 re.search('[0-9]{4,5}',data).group(0) AttributeError: 'NoneType' object has no attribute 'group'
-
() 匹配括号中的字符,一组字符
In [85]: data = 'www.baidu.com' In [86]: re.match('([a-z]+)\.([a-z]+)\.([a-z]+)',data) Out[86]: <_sre.SRE_Match object; span=(0, 13), match='www.baidu.com'> # 因为 . 是代表特殊意义的,所以需要 \ 转义成普通字符 In [87]: res = re.match('([a-z]+)\.([a-z]+)\.([a-z]+)',data) In [88]: res.groups() # groups 查看所有组元素 Out[88]: ('www', 'baidu', 'com') #每一个小括号都代表一组 In [104]: res.group(1,3) # 打印第一个、第三个元素 Out[104]: ('www', 'com')
-
a|b 代表a或者b
特殊字符
-
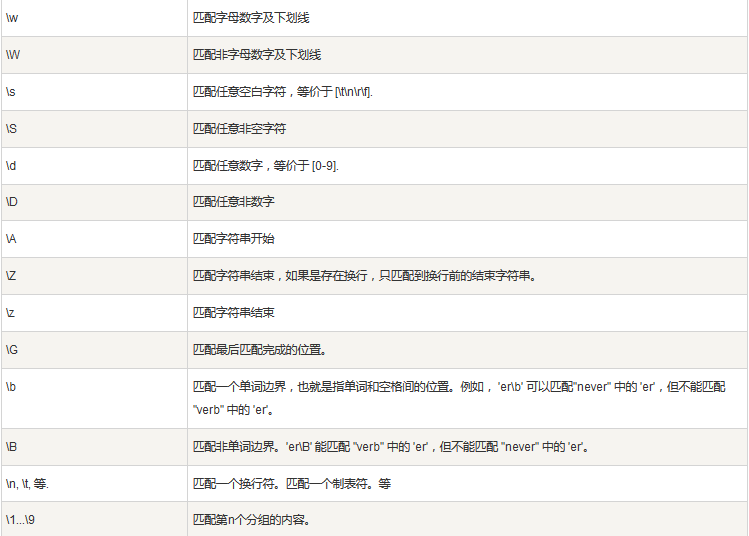
-
-
