

【Redis】缓存穿透与缓存雪崩
一、缓存雪崩
1.1 缓存雪崩产生的原因
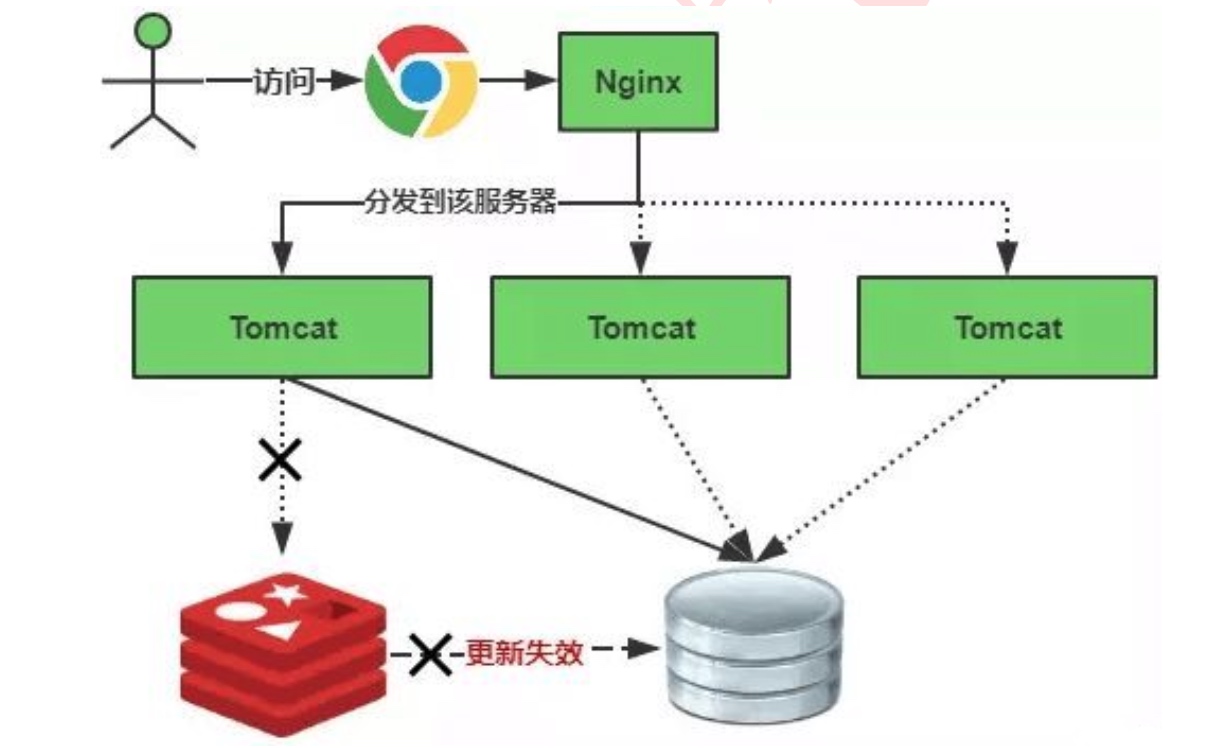
缓存雪崩通俗简单的理解就是:由于原有缓存失效(或者数据未加载到缓存中),新缓存未到期间(缓存正常从Redis中获取,如下图)所有原本应该访问缓存的请求都去查询数据库了,而对数据库CPU和内存造成巨大压力,严重的会造成数据库宕机,造成系统的崩溃。
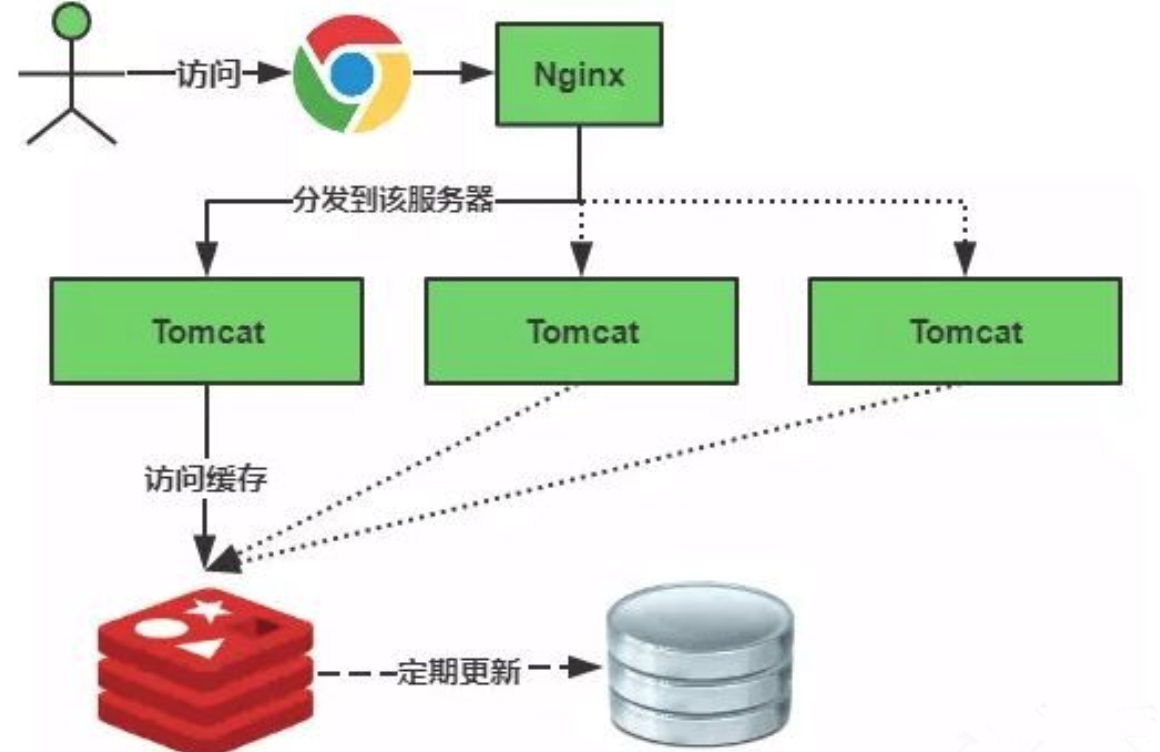
缓存失效的时候
1.2 解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!那有什么办法来解决这个问题呢?基本解决思路如下:
- 分布式锁:大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,避免缓存失效时对数据库造成太大的压力,虽然能够在一定的程度上缓解了数据库的压力但是与此同时又降低了系统的吞吐量。
- 使用消息中间件
- 一级和二级缓存(Redis+Ehcache)
- 均摊分配redis key的失效时间,分析用户的行为,尽量让缓存失效的时间均匀分布。
- 如果是因为某台缓存服务器宕机,可以考虑做主备,比如:redis主备,但是双缓存涉及到更新事务的问题,update可能读到脏数据,需要好好解决。
1.3 锁的方式
- 使用分布式锁(本地锁)解决学崩效应当突然有大量的请求到数据库的服务器的时候,进行对数据库服务请求限制。这个我们可以使用锁的机制,保证只有一个线程(请求)进行数据库的操作访问,否则情况直接排队等待。 (如果是集群服务器的话,那么就需要使用分布锁、单机版本可以使用本锁),确实可以解决服务雪崩效应,但是会减少服务器吞吐量问题。(适合于小项目)
- 在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
@RequestMapping("/getUsers")
public Users getByUsers(Long id) {
// 1.先查询redis
String key = this.getClass().getName() + "-" + Thread.currentThread().getStackTrace()[1].getMethodName()
+ "-id:" + id;
String userJson = redisService.getString(key);
if (!StringUtils.isEmpty(userJson)) {
Users users = JSONObject.parseObject(userJson, Users.class);
return users;
}
Users user = null;
try {
lock.lock();
// 查询db
user = userMapper.getUser(id);
redisService.setSet(key, JSONObject.toJSONString(user));
} catch (Exception e) {
} finally {
lock.unlock(); // 释放锁
}
return user;
}
- 注意:加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。假设在高并发下,缓存重建期间key是锁着的,这是过来1000个请求999个都在阻塞的。同样会导致用户等待超时,这是个治标不治本的方法。
1.4 消息中间件
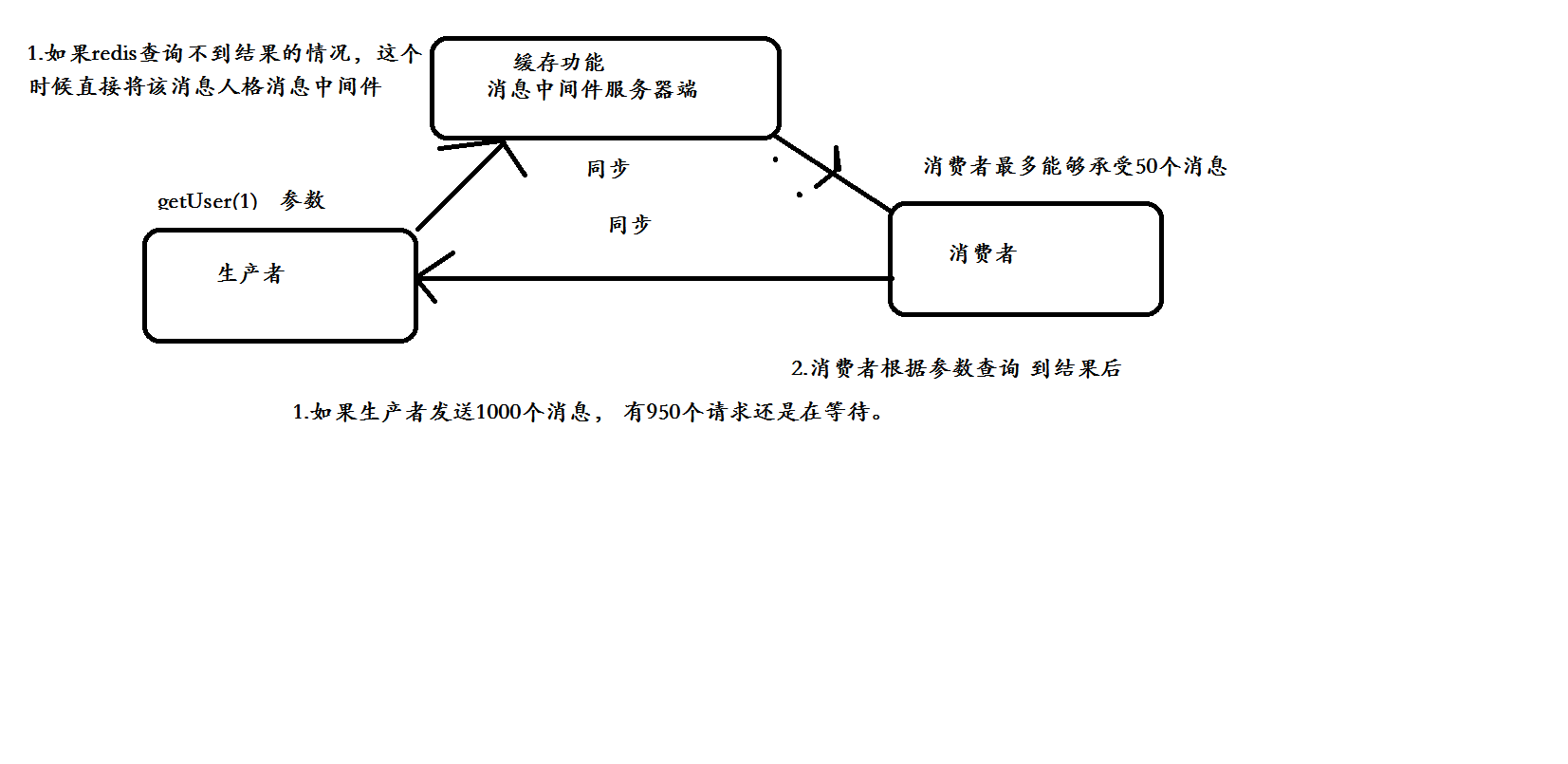
1.5 一级和二级缓存
做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期(此点为补充)
1.6 均摊分配redis key 失效时间
不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。Redis的数据失效时间不要设置为一致
二、缓存穿透
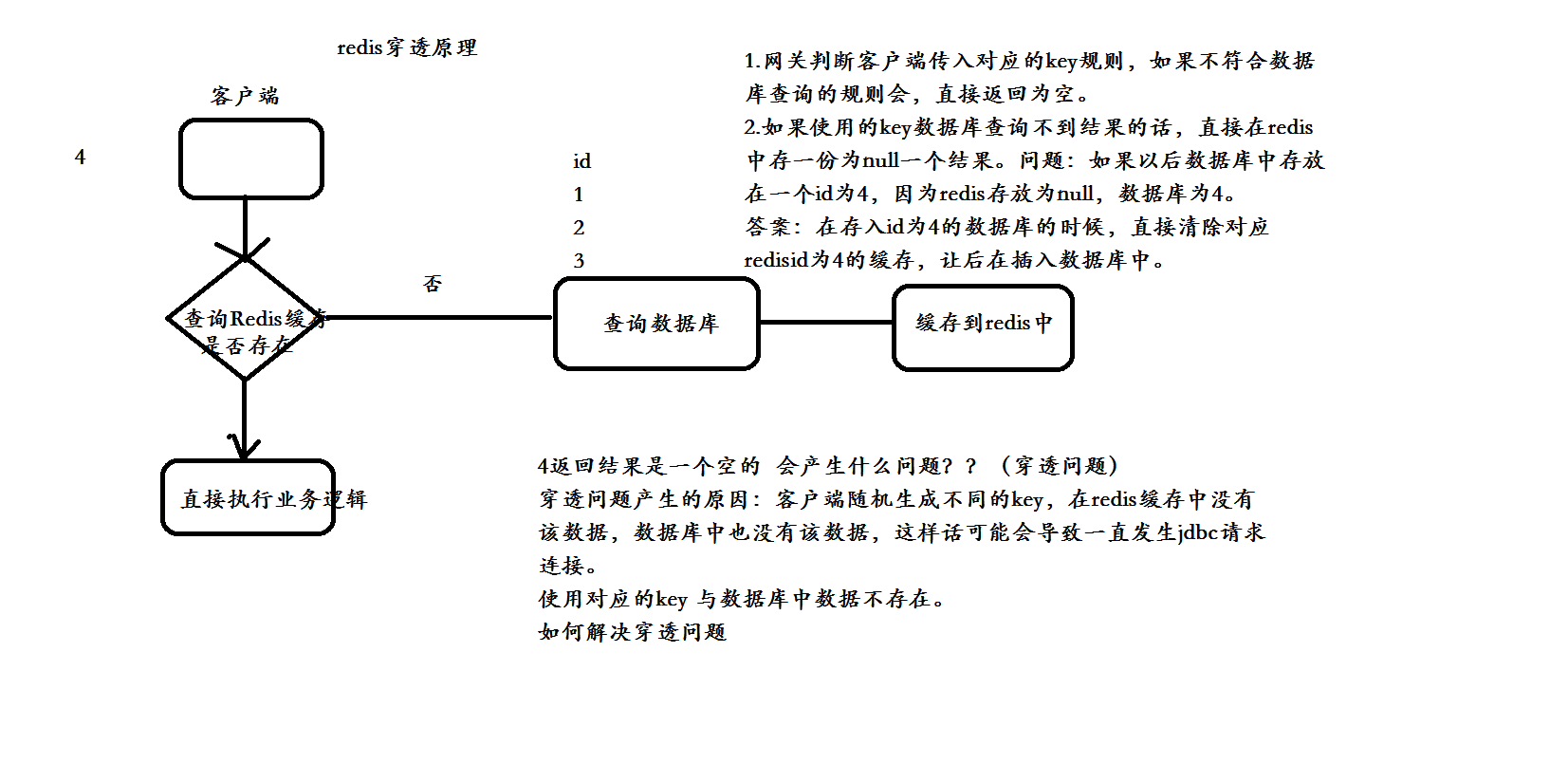
- 缓存穿透是指用户查询数据,在数据库没有,自然在缓存中也不会有。这样就导致用户查询的时候,在缓存中找不到,每次都要去数据库再查询一遍,然后返回空。这样请求就绕过缓存直接查数据库,这也是经常提的缓存命中率问题。
- 解决的办法就是:如果查询数据库也为空,直接设置一个默认值存放到缓存,这样第二次到缓冲中获取就有值了,而不会继续访问数据库,这种办法最简单粗暴。
- 把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
private String SIGN_KEY = "${NULL}";
public String getByUsers2(Long id) {
// 1.先查询redis
String key = this.getClass().getName() + "-" + Thread.currentThread().getStackTrace()[1].getMethodName()
+ "-id:" + id;
String userName = redisService.getString(key);
if (!StringUtils.isEmpty(userName)) {
return userName;
}
System.out.println("######开始发送数据库DB请求########");
Users user = userMapper.getUser(id);
String value = null;
if (user == null) {
// 标识为null
value = SIGN_KEY;
} else {
value = user.getName();
}
redisService.setString(key, value);
return value;
}
- 把空结果,也给缓存起来,这样下次同样的请求就可以直接返回空了,即可以避免当查询的值为空时引起的缓存穿透。同时也可以单独设置个缓存区域存储空值,对要查询的key进行预先校验,然后再放行给后面的正常缓存处理逻辑。
- 注意:再给对应的ip存放真值的时候,需要先清除对应的之前的空缓存。
热点key
热点key:某个key访问非常频繁,当key失效的时候有打量线程来构建缓存,导致负载增加,系统崩溃。解决办法:
- 使用锁,单机用synchronized,lock等,分布式用分布式锁。
- 缓存过期时间不设置,而是设置在key对应的value里。如果检测到存的时间超过过期时间则异步更新缓存。
- 在value设置一个比过期时间t0小的过期时间值t1,当t1过期的时候,延长t1并做更新缓存操作。
************ **供自己学习查阅使用(我只想静静的写篇博客,自我总结下[手动狗头]) by Pavel** *********
