

Django REST framework
本章内容;
1. FBV与CBV
FBV: Function Base View
CBV:Class Base View
示例:

from django.shortcuts import render, HttpResponse from django.http import JsonResponse # Create your views here. def index(request): if request.method == "POST": print(request.POST) # 修改数据库 return HttpResponse("OK") return render(request, "index.html") # CBV from django import views class Index(views.View): def get(self, request): return render(request, 'index.html') def post(self, request): print(request.POST) return HttpResponse("OK") # def index2(request): # if request.method == "GET": # return render(request, "index.html") # print(request.POST) # # 修改数据库 # return JsonResponse("OK") def ajax(request): return JsonResponse({"code": 0})
注意事项:
1.CBV定义一定要继承django.views.view
2. 注册路由的时候要写 类名.as_view()
3.具体原理是:dispatch()方法 中利用反射 找到每个请求执行
1 from django import views 2 3 4 class Index(views.View): 5 def get(self, request): 6 return render(request, 'index.html') 7 8 def post(self, request): 9 print(request.POST) 10 return HttpResponse("OK")
一. 什么是RESTful
- REST与技术无关,代表的是一种软件架构风格,REST是Representational State Transfer简称,中文翻译为“表征状态转移”
- REST从资源的角度类审视整个网络,它将分布在网络中某个节点的资源通过URL进行标识,客户端应用通过URL来获取资源的表征,获得这些表致使这些应用转变状态
- 所有的数据,不过是通过网络获取的还是操作(增删改查)的数据,都是资源,将一切数据视为资源是REST区别与其他架构风格的最基本属性
- 对于REST这种面向资源的架构风格,有人提出一种全新的结构理念,即:面向资源架构(ROA:Resource Oriented Architecture)
二. RESTful API设计
- API与用户的通信协议,总是使用HTTPs协议。
- 域名
- https://api.example.com 尽量将API部署在专用域名(会存在跨域问题)
- https://example.org/api/ API很简单
- 版本
- URL,如:https://api.example.com/v1/
- 请求头 跨域时,引发发送多次请求
- 路径,视网络上任何东西都是资源,均使用名词表示(可复数)
- https://api.example.com/v1/zoos
- https://api.example.com/v1/animals
- https://api.example.com/v1/employees
- method
- GET :从服务器取出资源(一项或多项)
- POST :在服务器新建一个资源
- PUT :在服务器更新资源(客户端提供改变后的完整资源)
- PATCH :在服务器更新资源(客户端提供改变的属性)
- DELETE :从服务器删除资源
- 过滤,通过在url上传参的形式传递搜索条件
- https://api.example.com/v1/zoos?limit=10:指定返回记录的数量
- https://api.example.com/v1/zoos?offset=10:指定返回记录的开始位置
- https://api.example.com/v1/zoos?page=2&per_page=100:指定第几页,以及每页的记录数
- https://api.example.com/v1/zoos?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
- https://api.example.com/v1/zoos?animal_type_id=1:指定筛选条件
状态码
200 OK - [GET]:服务器成功返回用户请求的数据,该操作是幂等的(Idempotent)。 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务) 204 NO CONTENT - [DELETE]:用户删除数据成功。 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作,该操作是幂等的。 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。 更多看这里:http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
错误处理,状态码是4xx时,应返回错误信息,error当做key。
{
error: "Invalid API key"
}
返回结果,针对不同操作,服务器向用户返回的结果应该符合以下规范。
GET /collection:返回资源对象的列表(数组) GET /collection/resource:返回单个资源对象 POST /collection:返回新生成的资源对象 PUT /collection/resource:返回完整的资源对象 PATCH /collection/resource:返回完整的资源对象 DELETE /collection/resource:返回一个空文档
Hypermedia API,RESTful API最好做到Hypermedia,即返回结果中提供链接,连向其他API方法,使得用户不查文档,也知道下一步应该做什么。
|
1
2
3
4
5
6
|
{"link": { "rel": "collection https://www.example.com/zoos", "href": "https://api.example.com/zoos", "title": "List of zoos", "type": "application/vnd.yourformat+json"}} |
三. 基于Django实现
路由系统:
|
1
2
3
|
urlpatterns = [ url(r'^users', Users.as_view()),] |
CBV视图:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from django.views import Viewfrom django.http import JsonResponseclass Users(View): def get(self, request, *args, **kwargs): result = { 'status': True, 'data': 'response data' } return JsonResponse(result, status=200) def post(self, request, *args, **kwargs): result = { 'status': True, 'data': 'response data' } return JsonResponse(result, status=200)
|
四. 基于Django Rest Framework框架实现
基于django实现的API许多功能都需要我们自己开发,这时候djangorestframework就给我们提供了方便,直接基于它来返回数据,总之原理都是一样的,就是给一个接口也就是url,让前端的人去请求这个url去获取数据,在页面上显示出来。这样也就达到了前后端分离的效果。下面我们来看看基于Django Rest Framework框架实现
1. 基本流程
实验案例:新闻系统
实现方式一:
1 from django.db import models 2 3 # Create your models here. 4 5 6 # 文章表 7 class Article(models.Model): 8 title = models.CharField(max_length=32) 9 # 文章发布时间 10 # auto_now每次更新的时候会把当前时间保存 11 create_time = models.DateField(auto_now_add=True) 12 # auto_now_add 第一次创建的时候把当前时间保存 13 update_time = models.DateField(auto_now=True) 14 # 文章的类型 15 type = models.SmallIntegerField( 16 choices=((1, "原创"), (2, "转载")), 17 default=1 18 ) 19 # 来源 20 school = models.ForeignKey(to='School', on_delete=models.CASCADE) 21 # 标签 22 tag = models.ManyToManyField(to='Tag') 23 24 25 # 文章来源表 26 class School(models.Model): 27 name = models.CharField(max_length=16) 28 29 30 # 文章标签表 31 class Tag(models.Model): 32 name = models.CharField(max_length=16)
执行命令:
migrate makemigrations
插入数据库数据
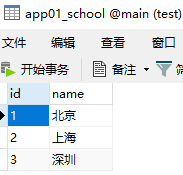
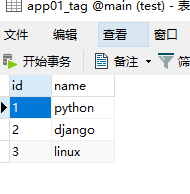

以上有了数据信息,然后进行json API接口的方式展示
1 from django.contrib import admin 2 from django.urls import path 3 from app01 import views 4 5 urlpatterns = [ 6 path('admin/', admin.site.urls), 7 path('article_list/',views.article_list), 8 ]
from django.shortcuts import render,HttpResponse from app01 import models import json # Create your views here. def article_list(request): #去数据库查询所有的文章数据 quest_set = models.Article.objects.all().values("id","title") #values是字典,values_list是列表 #序列化成json格式 data = json.dumps(list(quest_set),ensure_ascii=False) #返回 return HttpResponse(data)
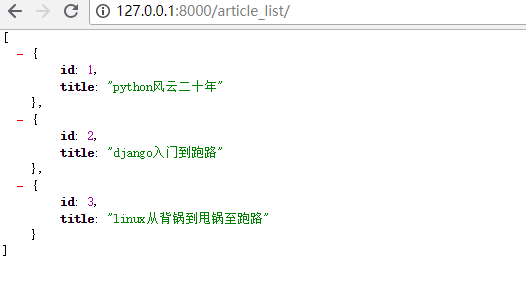
注意:json只支持7种数据类型,ORM查询出来的结果为QuerySet类型,它是不支持的。
日期对象也是不支持的,需要转换为字符串。
启动django项目,访问URL: http://127.0.0.1/article_list/,因此每一个时间,都要转换为字符串,太麻烦了。
转换方式:
1 from django.shortcuts import render,HttpResponse 2 from app01 import models 3 import json 4 5 # Create your views here. 6 def article_list(request): 7 #去数据库查询所有的文章数据 8 quest_set = models.Article.objects.all().values("id","title","create_time") #values是字典,values_list是列表 9 #序列化成json格式 10 11 #1.先把时间对象转换成字符串格式 12 for i in quest_set: 13 i["create_time"] = i["create_time"].strftime('%Y-%m-%d') 14 15 data = json.dumps(list(quest_set), ensure_ascii=False) 16 #返回 17 return HttpResponse(data)
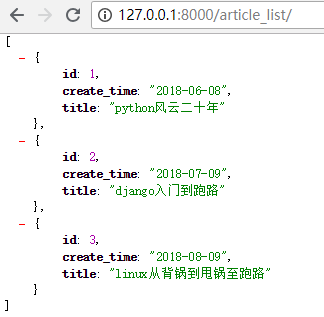
第二个版本:JsonResponse
JsonResponse 对象:
class JsonResponse(data, encoder=DjangoJSONEncoder, safe=True, json_dumps_params=None,**kwargs)
这个类是HttpRespon的子类,它主要和父类的区别在于:
- 1.它的默认Content-Type 被设置为: application/json
- 2.第一个参数,data应该是一个字典类型,当 safe 这个参数被设置为:False ,那data可以填入任何能被转换为JSON格式的对象,比如list, tuple, set。 默认的safe 参数是 True. 如果你传入的data数据类型不是字典类型,那么它就会抛出 TypeError的异常。
- 3.json_dumps_params参数是一个字典,它将调用json.dumps()方法并将字典中的参数传入给该方法。
1 from django.shortcuts import render,HttpResponse 2 from django.http import JsonResponse 3 from app01 import models 4 import json 5 6 # Create your views here. 7 #第二种方式 8 def article_list(request): 9 #去数据库查询所有的文章数据,返回queryset,每一个元素都是字典 10 query_set = models.Article.objects.all().values("id","title","create_time","type","school") 11 print(query_set) 12 for i in query_set: 13 print(i) 14 15 #学校对象 16 school_obj = models.School.objects.filter(id=i['school']).first() 17 #学校id 18 id = school_obj.id 19 #学校的名字 20 name = school_obj.name 21 #修改字典,key为school的值 22 i['school'] = {"id":id,"name":name} 23 24 #返回json对象,safe=False表示任何能转换为json格式的对象 25 return JsonResponse(list(query_set),safe=False)

查看JsonResponse源代码
def __init__(self, data, encoder=DjangoJSONEncoder, safe=True,
json_dumps_params=None, **kwargs):
if safe and not isinstance(data, dict):
raise TypeError(
'In order to allow non-dict objects to be serialized set the '
'safe parameter to False.'
)
if json_dumps_params is None:
json_dumps_params = {}
kwargs.setdefault('content_type', 'application/json')
data = json.dumps(data, cls=encoder, **json_dumps_params)
super(JsonResponse, self).__init__(content=data, **kwargs)
注意:从上面的代码中,可以看出。针对查询对应的学校信息,使用了for循环。它是一个外键字段,
那如果再查询一个外键字段呢?再来一个for循环?代码太冗长了!
第三个版本:serializers
serializers
serializer 允许复杂数据(比如 querysets 和 model 实例)转换成python数据类型,然后可以更容易的转换成 json 或 xml 等。同时,serializer也提供了反序列化功能,允许解析数据转换成复杂数据类型。
中文文档链接:
https://q1mi.github.io/Django-REST-framework-documentation/api-guide/serializers_zh/
声明序列化器
class DBG(serializers.Serializer): # 声明序列化器
id = serializers.IntegerField()
title = serializers.CharField()
create_time = serializers.DateField()
type = serializers.IntegerField()
school = serializers.CharField(source="school.name")
注意:source = "school.name" 表示school表中的name字段
可以使用它来序列化和反序化与DBG对象相应的数据。
申明一个序列化看起来非常像申明一个form。我们之前学习form组件时,将需要的字段类型都指定好了!
声明ModelSerializer
通常你会想要与Django模型相对应的序列化类。
ModelSerializer类能够让你自动创建一个具有模型中相应字段的Serializer类。
这个ModelSerializer类和常规的Serializer类一样,不同的是:
- 它根据模型自动生成一组字段。
- 它自动生成序列化器的验证器,比如unique_together验证器。
- 它默认简单实现了
.create()方法和.update()方法。
声明一个ModelSerializer如下:


class CYM(serializers.ModelSerializer):
type = serializers.CharField(source='get_type_display')
class Meta:
model = models.Article
fields = "__all__" # ("id", "title", "type")
depth = 1 # 官方推荐不超过10层
默认情况下,所有的模型的字段都将映射到序列化器上相应的字段。
模型中任何关联字段比如外键都将映射到PrimaryKeyRelatedField字段。默认情况下不包括反向关联,除非像serializer relations文档中规定的那样显示包含。
Model.get_FOO_display
查看官方文档
https://docs.djangoproject.com/en/dev/ref/models/instances/#django.db.models.Model.get_FOO_display
对于具有选择集的每个字段,该对象将具有一个get_FOO_display()方法,其中FOO是该字段的名称。 此方法返回字段的“可读”值。
参数解释:
source='get_type_display' 表获取type字段中选择集的值。
不懂?看一下models.py中的Article表,看这一段
# 文章的类型
type = models.SmallIntegerField(
choices=((1, "原创"), (2, "转载")),
default=1
)
ORM是查询表的数据,那么这个type在真正存储时,是1或2。
但是我想要得到"原创"和"转载",怎么办?那就需要我上面提到的get_type_display。
注意:type的变量名和字段名必须保持一致,那么使用serializers后,结果集中type的值为"原创"和"转载",而不是1和2
model = models.Article 表示Article表
fields = "__all__" 表示所有字段,如果需要指定字段。可以写成这样fields = ("id", "title", "type")
depth = 1 表示深度为1层。有外键关联时,才需要设置depth参数!
因为Article表和School表,是一对多的关系,它们之间的关系只有一层。假设说:School表和另外一个表(简称B表)有关系。Article表通过School表,要去查询B表的数据,那么层数就是2,以此类推!
使用ModelSerializer
def article_list(request): # 查询所有
# 去数据库查询所有的文章数据
query_set = models.Article.objects.all()
xbg = CYM(query_set, many=True)
print(xbg.data)
# 返回
return JsonResponse(xbg.data, safe=False)
def article_list(request): # 查询所有
# 去数据库查询所有的文章数据
query_set = models.Article.objects.all()
xbg = CYM(query_set, many=True)
print(xbg.data)
# 返回
return JsonResponse(xbg.data, safe=False)
参数解释:
many=True 表示能序列化多个对象。
什么意思?article表有多条数据,每一条数据,就是一个对象。我们需要查询表的所有记录,所以必须指定many=True。返回一条数据时,不需要指定many=True
获取多条数据
views.py完整代码如下:
from django.shortcuts import render,HttpResponse
from django.http import JsonResponse
from app01 import models
import json
from rest_framework import serializers
# Create your views here.
class DBG(serializers.Serializer): # 声明序列化器
id = serializers.IntegerField()
title = serializers.CharField()
create_time = serializers.DateField()
type = serializers.IntegerField()
school = serializers.CharField(source="school.name")
class CYM(serializers.ModelSerializer): # 声明ModelSerializer
#
type = serializers.CharField(source='get_type_display')
class Meta:
model = models.Article
fields = "__all__" # ("id", "title", "type")
depth = 1 # 官方推荐不超过10层
def article_list(request): # 查询所有
# 去数据库查询所有的文章数据
query_set = models.Article.objects.all()
xbg = CYM(query_set, many=True)
print(xbg.data)
# 返回
return JsonResponse(xbg.data, safe=False)

可以看到type的值不是数字,而是选择集中的值,它做了替换。是下面这一行,做了替换
type = serializers.CharField(source='get_type_display')
school的值,也能显示相关联的数据。
CYM是通用的,可以多条,也可以一条。
注意:多条的时候,需要加参数many=True。而一条,则不用!
获取一条数据
修改urls.py,增加一个路径
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^article_list/', views.article_list),
url(r'article_detail/(\d+)', views.article_detail),
]
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^article_list/', views.article_list),
url(r'article_detail/(\d+)', views.article_detail),
]
修改views.py,增加视图函数
from django.shortcuts import render,HttpResponse from django.http import JsonResponse from app01 import models import json from rest_framework import serializers # Create your views here. class DBG(serializers.Serializer): # 声明序列化器 id = serializers.IntegerField() title = serializers.CharField() create_time = serializers.DateField() type = serializers.IntegerField() school = serializers.CharField(source="school.name") class CYM(serializers.ModelSerializer): # 声明ModelSerializer # type = serializers.CharField(source='get_type_display') class Meta: model = models.Article fields = "__all__" # ("id", "title", "type") depth = 1 # 官方推荐不超过10层 def article_list(request): # 查询所有 # 去数据库查询所有的文章数据 query_set = models.Article.objects.all() xbg = CYM(query_set, many=True) print(xbg.data) # 返回 return JsonResponse(xbg.data, safe=False) def article_detail(request, id): # 查询单条数据 article_obj = models.Article.objects.filter(id=id).first() xcym = CYM(article_obj) return JsonResponse(xcym.data)
刷新页面,访问url: http://127.0.0.1:8000/article_detail/1
使用格式化工具,效果如下:

总结:
使用ORM对象转换为json对象时,推荐使用serializers
七、Postman使用
Postman一款非常流行的API调试工具。不仅可以调试简单的css、html、脚本等简单的网页基本信息,它还能够发送任何类型的HTTP 请求 (GET, HEAD, POST, PUT..),附带任何数量的参数+ headers。对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。
官网地址:
使用windows安装之后,打开主程序,跳过登录
访问文章列表 http://127.0.0.1:8000/article_list/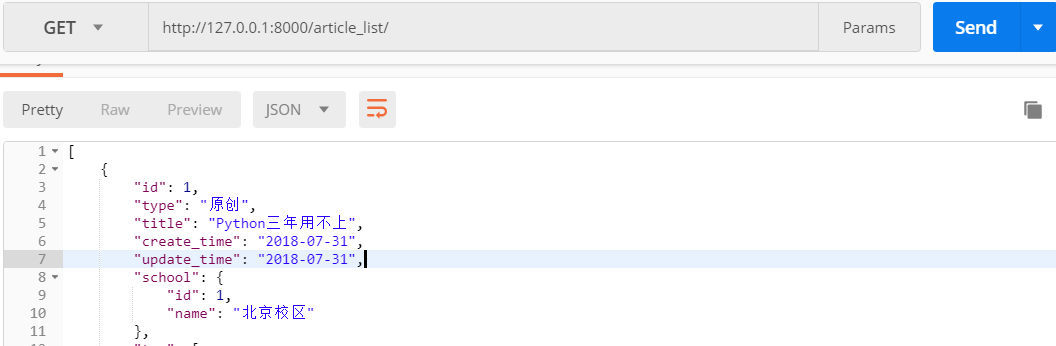
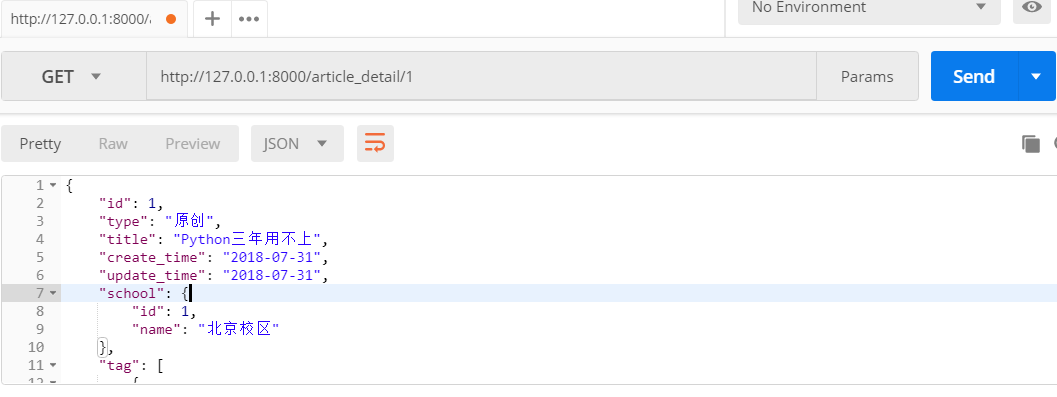
访问文章详情 http://127.0.0.1:8000/article_detail/1
总结:
1. 使用Django 的视图 自己序列化
1. HttpResponse
2. JsonResponse
3. serializers
2. 使用Django REST Framework 框架的序列化工具类
1. 安装
pip install djangorestframework
2. 导入
from rest_framework import serializers
3. 使用
class ArticleSerializer(serializers.Serializer):
...
外部python脚本调用django
有些情况下,我们需要使用python脚本来调用django,从而方便使用django提供的一些指令!
调试ORM
在django项目根目录下创建文件test_orm.py,它和manage.py是同级的
import os
if __name__ == "__main__":
# 设置django环境
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "about_drf.settings")
import django
django.setup()
from app01 import models
obj = models.Article.objects.filter(id=1).values()
print(obj)
执行脚本,输出如下:
<QuerySet [{'title': 'Python三年用不上', 'id': 1, 'school_id': 1, 'type': 1, 'update_time': datetime.date(2018, 7, 31), 'create_time': datetime.date(2018, 7, 31)}]>
清理过期session
如果用户主动退出,session会自动清除,如果没有退出就一直保留,记录数越来越大,要定时清理没用的session。
django中已经提供了这个方法,推荐把它加入到crontab中自动清理过期的session,防止session表记录过大,影响访问速度。
python E:\python_script\django框架\day15\about_drf\manage.py clearsessions

