

python全栈学习--day31(正则)
1 2 3 4 5 6 7 8 | <br><br><br>try: '''可能会出现异常的代码'''except ValueError: ''''打印一些提示或者处理的内容'''except NameError: '''...'''except Exception: '''万能异常不能乱用''' |
1 2 3 4 5 6 7 8 9 10 | try: '''可能会出现异常的代码'''except ValueError: ''''打印一些提示或者处理的内容'''except NameError: '''...'''except Exception: '''万能异常不能乱用'''else: '''以上所有的except都不执行''' |
1 2 3 4 5 6 7 8 | try: '''可能会出现异常的代码'''except ValueError: '''打印一些提示或者处理的内容'''else: '''try中的代码正常执行了'''finally: '''无论错误是否发生,都会执行这段代码,用来做一些首尾工作''' |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | number = input('please input your phone number:')if number.isdigit() and number.startswith('13')\ or number.startswith('14')\ or number.startswith('15')\ or number.startswith('16')\ or number.startswith('17')\ or number.startswith('18')\ or number.startswith('19'): print('通过检查')else: print('格式错误')上面的代码太冗长了,使用正则number = input('please input your phone number:')ret = re.match('(13|14|15|16|17|18|19)[0-9]{9}',number)if ret:print('通过初检查') |
实例一:
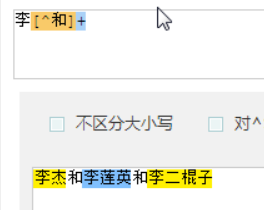
匹配出手机号码,就可以使用正则了。
1 2 3 4 5 6 7 | with open('a',encoding='utf-8')as f1: li = [] for i in f1: i = i.strip() ret = re.findall('1[3-9]\d{9}',i) li.extend(ret) #extend 合并print(li) |
正则表达式本身也和python没有什么关系,就是匹配字符串内容的一种规则。
官方定义:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式
在线测试工具 http://tool.chinaz.com/regex/
这个是最好的正则表达式工具
正则可以随时匹配

缺点:
如果只会用这个工具,而不会自己写的话。就不行了。主要是自己写,不要太依赖它。
字符组 字符串用[]表示
它只能匹配一个字符串


那么在之后我们更多要考虑的是在同一个位置上可以出现的字符的范围。
字符组 : [字符组]
在同一个位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字、字母、标点等等。
假如你现在要求一个位置"只能出现一个数字",那么这个位置上的字符只能是0、1、2...9这10个数之一。

[9-0] 是不可以的,为啥?
它比较的是ascii码
[5-9] 这种是可以的
[5.5-9] 这种是不可以的
不允许输出小数点
匹配3位数字
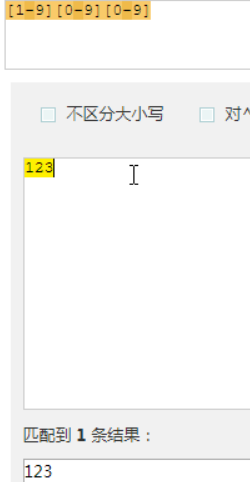

匹配大写

大小写匹配

[A-z] 这样写是不对的。ascii码的大小写不是连续的
它不能匹配特殊字符
[0-9a-fA-F] 表示匹配十六进制
总结:


.是万能的,除了换行符以外
匹配空白
重点
|
^
|
匹配字符串的开始
|
|
$
|
匹配字符串的结尾
|

以海开头
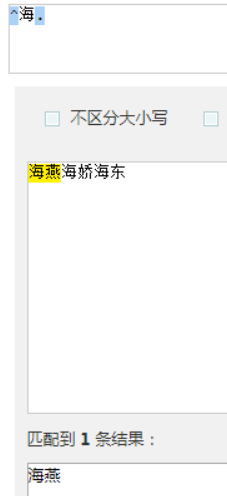
正则表达式,不能写在后面

它只能出现在开始位置不能在中间或者后面位置




这种情况,是唯一ke可以放到任意位置的


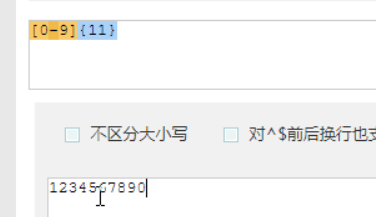

表示匹配11位以上,不能低于11位

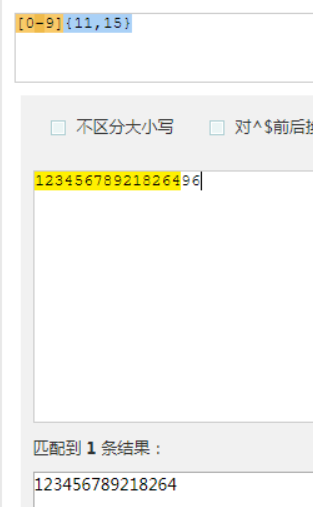
匹配15位,往多的匹配

*表示0次或者多次。
这里匹配了0次,虽然没匹配上。

匹配1次或者多次

?匹配一次或者0次
匹配不上,就是0次

重点:
量词只能约束一个字符串
这里的约束[A-Z]
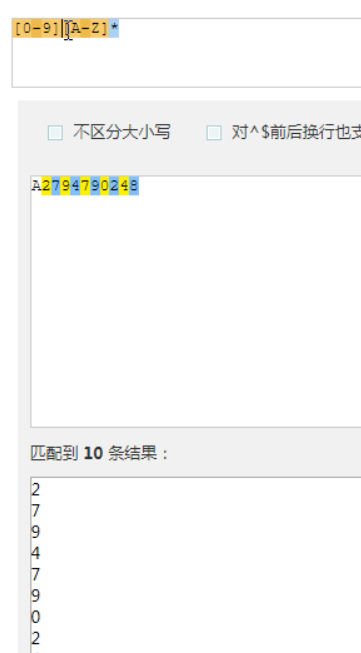
同时约束[0-9]和[A-Z]
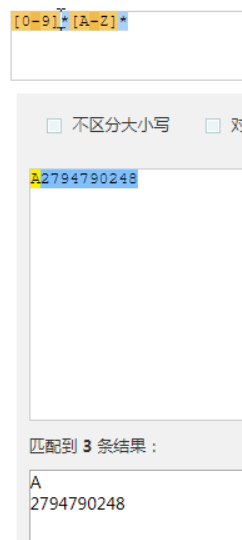
没有匹配上,就是匹配0次
匹配0次

tool.chinaz.com/regex/
这个工具,显示的结果,可能跟真实的有区别
?表示0次或多次
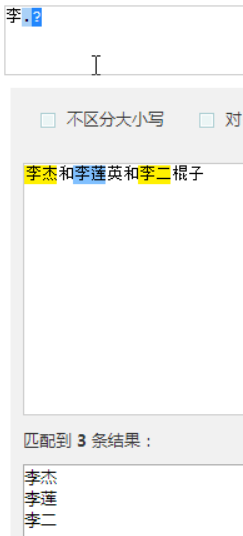
默认的正则是贪婪匹配
如果能匹配1次,绝不匹配0次
.* 表示匹配所有
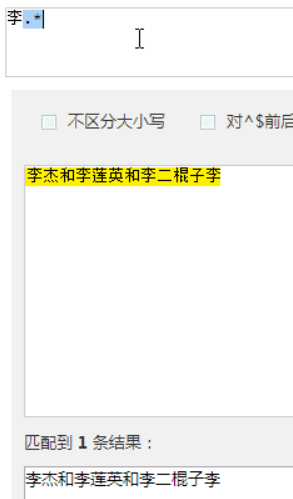
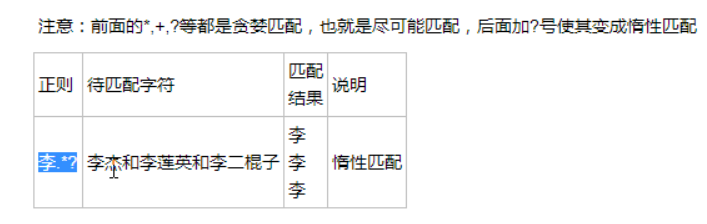
非贪婪匹配,加一个?,就是非贪婪
在规则内,越少越好

最多2次

带红线,不是重要的

元字符,应该和量词使用
分组 ()与 或 |[^]
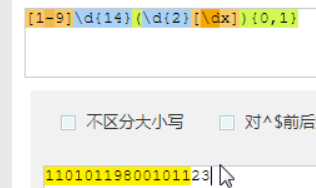
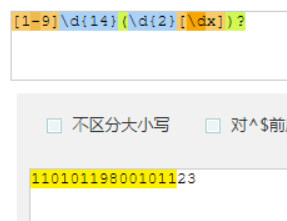
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x,下面我们尝试用正则来表示:






需求对二个约束

写这样写不好


至少匹配15次
这样写,就比较专业

转义符 \
现在要匹配\n,斜杠需要转义

2个下划线就是转义


贪婪匹配
贪婪匹配:在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配

结果就是一项
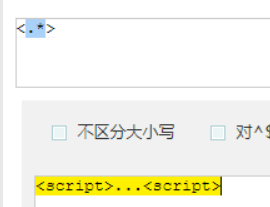
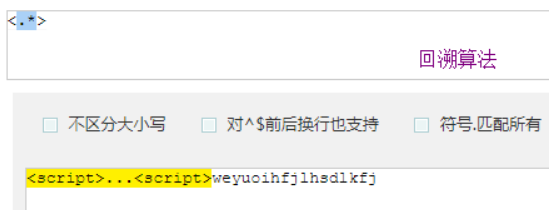
因为它要回到原来很难,所以它尽可能,多匹配一点
匹配多次,直到遇到<停下来
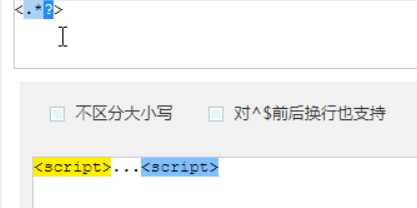
?先匹配后面的。
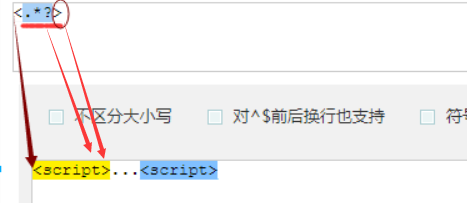
几个常用的非贪婪匹配Pattern
| 匹配字符 | 说明 |
| *? | 重复任意次,但尽可能少重复 |
| +? | 重复1次或更多次,但尽可能少重复 |
| ?? | 重复0次或1次,但尽可能少重复 |
| {n,m}? | 重复n到m次,但尽可能少重复 |
| {n,}? | 重复n次以上,但尽可能少重复 |
*?的用法
. 是任意字符
* 是取 0 至 无限长度
? 是非贪婪模式。 何在一起就是 取尽量少的任意字符,一般不会这么单独写,
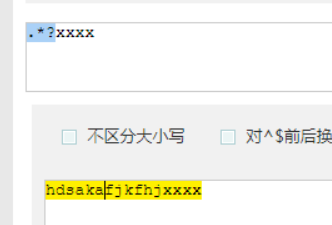
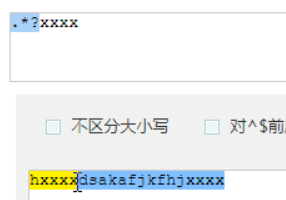
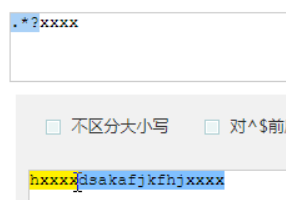
他大多用在: .*?x
就是取前面任意长度的字符,直到一个x出现
用的最多的是.*?
re模块下的常用方法
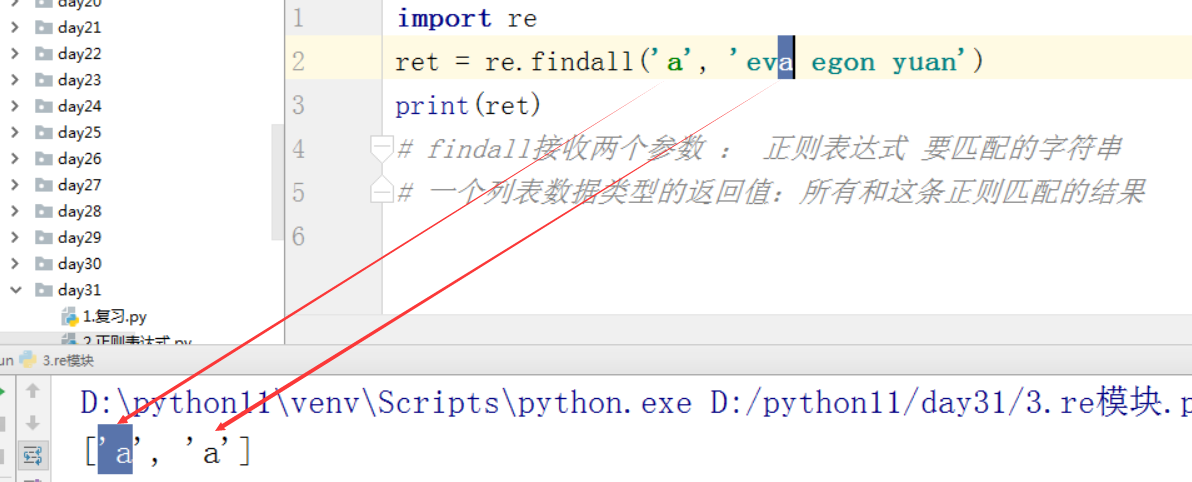
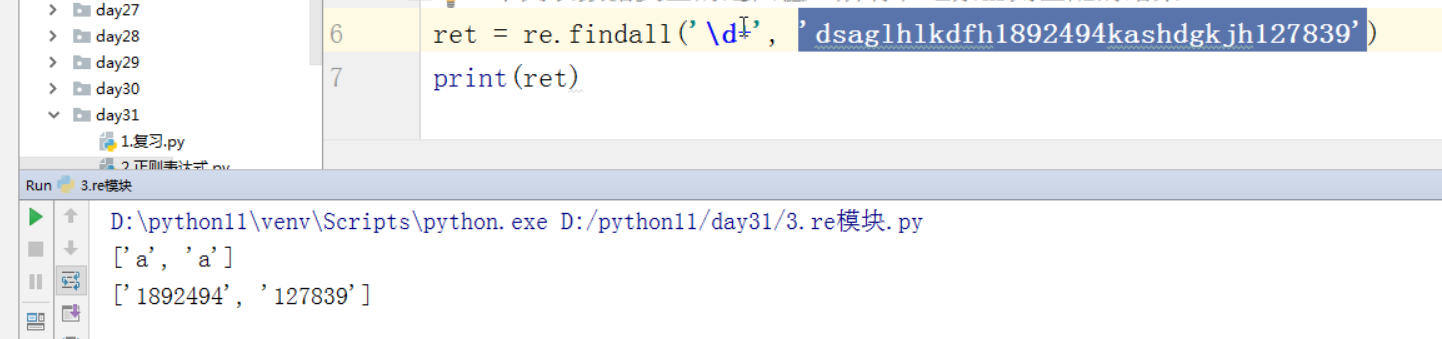
import re ret = re.findall('a', 'eva egon yuan') # 返回所有满足匹配条件的结果,放在列表里 print(ret) #结果 : ['a', 'a']
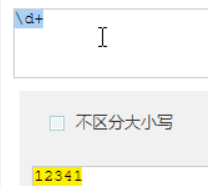
匹配所有数字
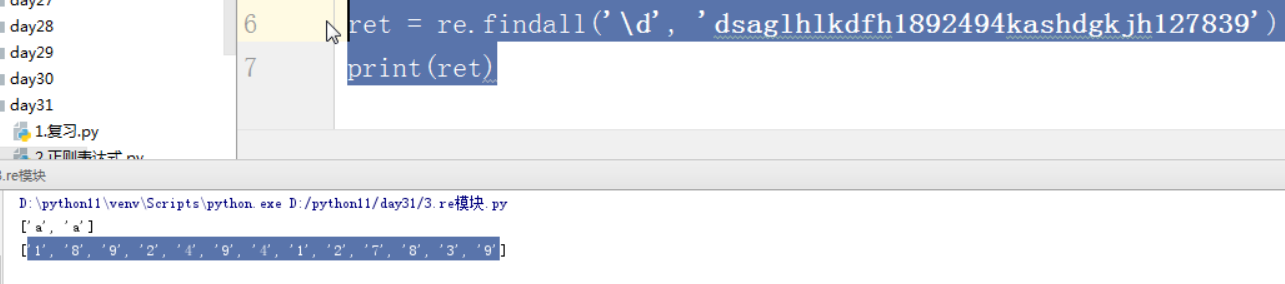

fefsfsd13764800048
f13764800048
13764800048ffsfsd
fdsa13764800048et413764800048


1 2 3 4 5 6 7 | with open('a',encoding='utf-8')as f1: li = [] for i in f1: i = i.strip() ret = re.findall('1[3-9]\d{9}',i) li.extend(ret)print(li) |
执行输出:

1 2 3 4 | ret = re.search('a', 'eva egon yuan').group()print(ret) #结果 : 'a'# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以# 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 |

输出
a
为啥只有一个a呢?
# search 和 findall的区别:
#1.search找到一个就返回,findall是我所有
#2.findall是直接返回一个结果的列表,search返回一个对象
1 2 3 | #用search ,必须要if判断ret = re.match('a','eva egon yuan')print(ret) |
什么结果是None ?


下面的方法,使用的比较少
split根据正则表达式切割
1 2 3 4 5 | ret = re.split('[ab]','abcd')print(ret)#如果不写1,表示全部替换ret = re.sub('\d','H','eva3egon4yuan4') #将数字替换成‘H’,参数1表示只替换1个print(ret)<br><br>ret = re.subn('\d','H','eva3egon4yuan4') #将数字替换成‘H’,返回元祖(替换的结果,替换了多少次)<br>print(ret) |
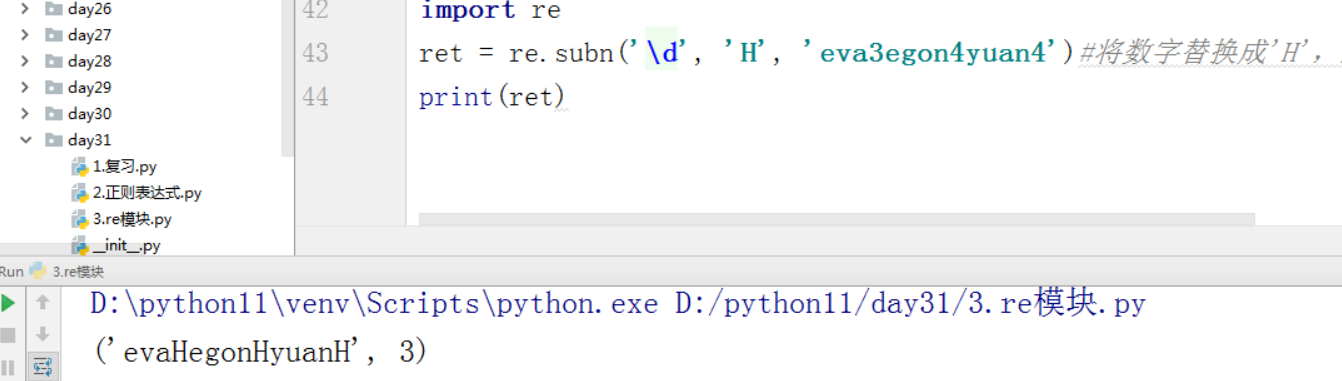
表示替换了3次,返回一个元组
#正则表达式-->根据规则匹配字符串
#从一个字符串中找到符合规则的字符串 --> python
#正则规则 -编译-> python能理解的语言
#多次执行,就需要多次编译 浪费时间 re.findall('1[3-9]\d{9}',line)
这样就快了,提前编译了
1 2 3 4 5 6 | import reobj = re.compile('\d{3}')ret = obj.search('abc123eeee')obj.match('abc123eeee')obj.findall('23t3faabc123eeee')print(ret.group()) |
执行输出:
编译在多次执行同一个正则规则,有效
1 2 3 4 5 6 | import reret = re.finditer('\d','ds2fa24t43fas') #finditer 返回一个存放匹配结果的迭代器print(ret)print(next(ret).group()) #查看一个结果print(exit().group()) #查看第二个结果print([i.group() for i in ret]) #查看剩余的左右结果 |

迭代器



结论
结论

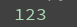
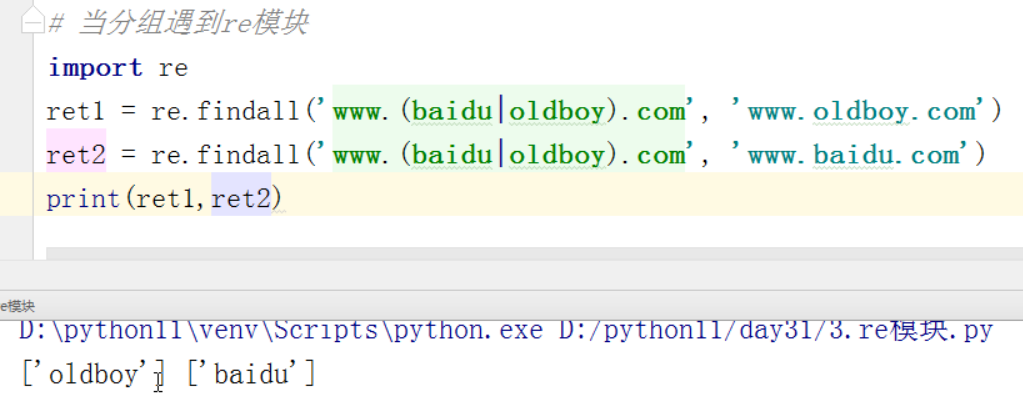
2 split的优先级查询
以数字为分割点
分割的数字,会留下来

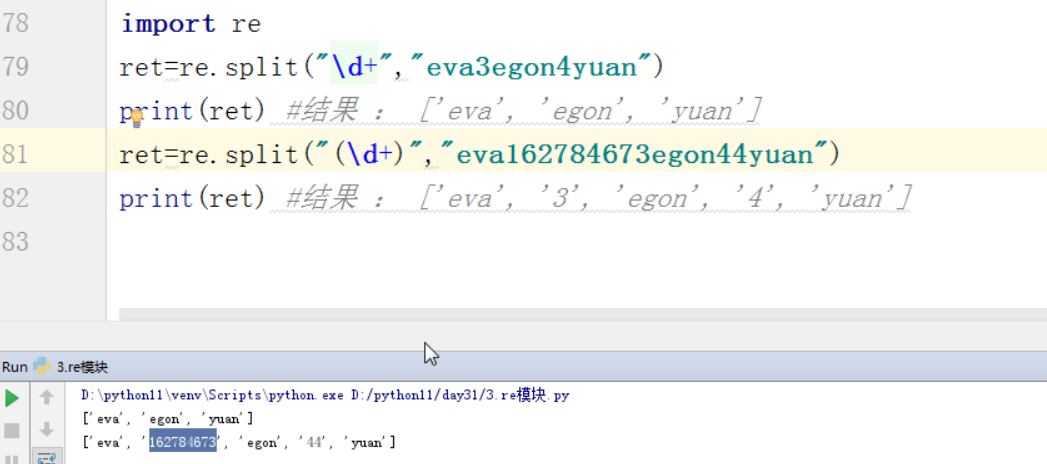
1 2 | ret = re.split("\d+","eva3egon4yuan")print(ret) |
2 将以数字分割的数字也留下来。
1 2 | ret = re.split("(\d+)","eva3egon4yuan")print(ret) |

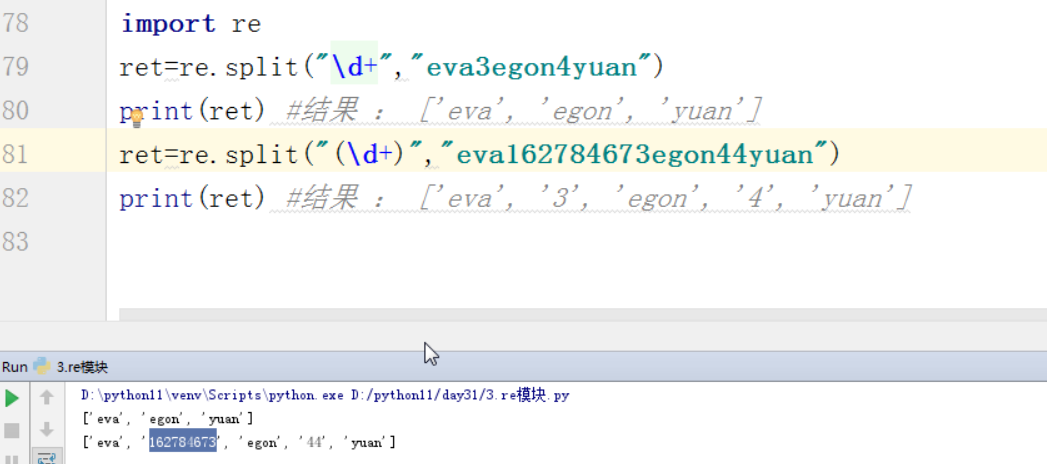
split分割一个字符串,默认被匹配到的分隔符不会出现在结果列表中
如果将匹配的正则放到组内,就会将分隔符放到结果列表里。
综合练习与扩展
1.匹配标签
#分组命名 和 search 遇到分组
#标签 .html网页文件,标签文件
#<h1>aaaaaa</h1>
1 2 3 | import reret = re.search("<\w+>\w+</\w+>","<h1>hello</h1>")print(ret.group()) |
这不是我想要的
import re
ret = re.search("<\w+>\w+</\w+>","<h1>hello</h2>")
print(ret.group())
 #假如这里我想他以<h1>这个成对的标签来做匹配呢?显然上面的在这个示例是不行的。
#假如这里我想他以<h1>这个成对的标签来做匹配呢?显然上面的在这个示例是不行的。
ret = re.findall('\w+',"<h1>hello</h2>") print(ret)

不通过匹配周围的,无法匹配到想要的内容,所以分组就有意义了!
1 2 3 4 5 | import re#分组的意义#<h1>hell0</h1>ret = re.findall('<\w+>(\w+)</\w+>',"<h1>hello</h1>")print(ret) |
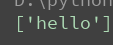
#分组的意义:
#1.对一组正则规则进行量词约束
#2.从一整条正规则匹配的结果中优先显示组内的内容
#分组命名

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步