


python全栈学习--day8
一,文件操作基本流程。
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量 f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r #2. 通过句柄对文件进行操作 data=f.read() #3. 关闭文件 f.close()
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为: 1、f.close() #回收操作系统级打开的文件 2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源, 而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 虽然我这么说,但是很多人是会忘记f.close(),这里我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文 with open('a.txt','w') as f: pass with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data=read_f.read() write_f.write(data) 注意
二,文件编码
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
三,文件的打开模式
#1.打开文件的模式有(默认为文本模式:) r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】 w,只写模式【不可读;不存在则创建;存在则清空内容】 a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】
#1. 全部读出来f.read()
f = open('log.txt',encoding='utf-8',mode='r')
content = f.read()
print(content)
f.close()
#2. 一行行的读
f = open('log.txt',encoding='utf-8')
print(f.readline())
print(f.readline())
print(f.readline())
f.close()
#3: 将原文件的每一行作为一个列表的元素
f = open('log.txt',encoding='utf-8')
print(f.readlines())
f.close()
#4:读取一部分read(n)
#在r模式下,read(n) 按照字符去读取。
f = open('log.txt',encoding='utf-8')
print(f.read(3))
f.close()
##5.循环读取
f = open('log.txt',encoding='utf-8')
for i in f:
print(i.strip())
f.close()
#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式) rb wb ab 注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
#非文字类的文件时,用rb
f = open('log.txt',encoding='utf-8')
content = f.read()
f.close()
#w
#没有文件,创建一个文件写入内容
f = open('log1.txt',encoding='utf-8',mode='w')
f.write('wefjiwnadihewgasdj')
f.close()
#有文件,将原文件内容清空,在写入内容。
f = open('log1',mode='w')
f.write('66666'.encode('utf-8'))
f.close()
#wb #二进制方式写入
f = open('log1',mode='wb')
f.write('weiwnsfd'.encode('utf-8'))
f.close()
#a
f = open('log2',encoding='utf-8',mode='a')
f.write('24we')
f.close()
#有文件,直接追加内容。
f = open('log2',encoding='utf-8',mode='a')
f.write('2242w')
f.close()
#3,‘+’模式(就是增加了一个功能) r+, 读写【可读,可写】 w+,写读【可写,可读】 a+, 写读【可写,可读】
# r+ 先读,后追加 一定要先读后写
f = open('log2',encoding='utf-8',mode='r+')
content = f.read()
print(content)
f.write('eweeafda')
f.close()
#4,以bytes类型操作的读写,写读,写读模式 r+b, 读写【可读,可写】 w+b,写读【可写,可读】 a+b, 写读【可写,可读】
#w+ 先写后读
f = open('log2',encoding='utf-8',mode='w+')
f.write('中国')
# print(f.tell()) #按字节去读取光标位置
f.seek(3) #按照字节调整光标位置
print(f.read())
f.close()
#a+ 追加读
f = open('log',encoding='utf-8',mode='a+')
f.write('wefwn')
content = f.read()
print(content)
f.close()
#其他方法
f = open('log',encoding='utf-8')
print(f.read())
print(f.writable())
f.close()
执行后输出的结果:
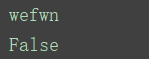
总结:
功能一:自动关闭文件句柄
功能二:一次性操作多个文件句柄
with open('log',encoding='utf-8') as f:
print(f.read())
with open('log1',encoding='utf-8')as f1:
print(f1.read())
with open('log',encoding='utf-8') as f1,\
open('log1',encoding='utf-8')as f2:
print(f1.read())
print(f2.read())
所有的文件操作步骤:
# 1,将原文件读取到内存。
# 2,在内存中进行修改,形成新的内容。
# 3,将新的字符串写入新文件。
# 4,将原文件删除。
# 5,将新文件重命名成原文件。
###本章练习--案例
1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数。
apple 10 3
tesla 100000 1
mac 3000 2
lenovo 30000 3
chicken 10 3
通过代码,将其构建成这种数据类型:
[{'name':'apple','price':10,'amount':3},{'name':'tesla','price':1000000,'amount':1}......] 并计算出总价钱。
'''
#总列表
li = []
#总价格
the_sum = 0
with open('a.txt',encoding='utf-8') as f:
for i in f:
#默认使用空格分割
i = i.strip().split()
#将字典追加到列表中
li.append({'name': i[0], 'price': i[1], 'amount': i[2]})
#遍历列表
for i in li:
#计算总价格(单价*个数)
the_sum += int(i['price']) * int(i['amount'])
print(li)
print('总价钱为: {}'.format(the_sum))
文件a2.txt内容:
文件内容:
序号 部门 人数 平均年龄 备注
1 python 30
26 单身狗
2 Linux 26
30 没对象
3 运营部 20
24 女生多
通过代码,将其构建成这种数据类型:
[{'序号':'1','部门':Python,'人数':30,'平均年龄':26,'备注':'单身狗'},
......]
li = []
count = 0
with open('a2', encoding='utf-8') as f1:
for i in f1:
count += 1
if count == 1:
l2 = i.strip().split()
else:
l1 = i.strip().split()
li.append({l2[0]: l1[0], l2[1]: l1[1], l2[2]: l1[2], l2[3]: l1[3], l2[4]: l1[4]})
print(li)
执行输出:
[{'序号': '1', '人数': '30', '部门': 'python', '备注': '单身狗', '平均年龄': '26'}, {'序号': '2', '人数': '26', '部门': 'Linux', '备注': '没对象', '平均年龄': '30'}, {'序号': '3', '人数': '20', '部门': '运营部', '备注': '女生多', '平均年龄': '24'}]
