

MIT-6.824 lab1
github:https://github.com/haoweiz/MIT-6.824
Part1:
第一部分比较简单,我们只需要修改doMap和doReduce函数即可,主要涉及Go语言对Json文件的读写。简单说说part1的测试流程吧,Sequential部分代码如下
1 func TestSequentialSingle(t *testing.T) { 2 mr := Sequential("test", makeInputs(1), 1, MapFunc, ReduceFunc) 3 mr.Wait() 4 check(t, mr.files) 5 checkWorker(t, mr.stats) 6 cleanup(mr) 7 } 8 9 func TestSequentialMany(t *testing.T) { 10 mr := Sequential("test", makeInputs(5), 3, MapFunc, ReduceFunc) 11 mr.Wait() 12 check(t, mr.files) 13 checkWorker(t, mr.stats) 14 cleanup(mr)
makeInputs(M int)对于0-100000个数字平均分成了M个文件写入,,根据题目要求,我们需要将每个文件分成N个文件写出,因此doMap过程总共产生M*N个文件,我们可以先将文件的所有键值对通过mapF函数(本质上是test_test.go中的MapFunc函数)存储在数组keyvalue中,然后创建nReduce个文件并对每个键值对用ihash()%nReduce得到该键值对应存储的文件位置,利用Encoder写入文件即可
1 // doMap manages one map task: it reads one of the input files 2 // (inFile), calls the user-defined map function (mapF) for that file's 3 // contents, and partitions the output into nReduce intermediate files. 4 func doMap( 5 jobName string, // the name of the MapReduce job 6 mapTaskNumber int, // which map task this is 7 inFile string, 8 nReduce int, // the number of reduce task that will be run ("R" in the paper) 9 mapF func(file string, contents string) []KeyValue, 10 ) { 11 // 12 // You will need to write this function. 13 // 14 // The intermediate output of a map task is stored as multiple 15 // files, one per destination reduce task. The file name includes 16 // both the map task number and the reduce task number. Use the 17 // filename generated by reduceName(jobName, mapTaskNumber, r) as 18 // the intermediate file for reduce task r. Call ihash() (see below) 19 // on each key, mod nReduce, to pick r for a key/value pair. 20 // 21 // mapF() is the map function provided by the application. The first 22 // argument should be the input file name, though the map function 23 // typically ignores it. The second argument should be the entire 24 // input file contents. mapF() returns a slice containing the 25 // key/value pairs for reduce; see common.go for the definition of 26 // KeyValue. 27 // 28 // Look at Go's ioutil and os packages for functions to read 29 // and write files. 30 // 31 // Coming up with a scheme for how to format the key/value pairs on 32 // disk can be tricky, especially when taking into account that both 33 // keys and values could contain newlines, quotes, and any other 34 // character you can think of. 35 // 36 // One format often used for serializing data to a byte stream that the 37 // other end can correctly reconstruct is JSON. You are not required to 38 // use JSON, but as the output of the reduce tasks *must* be JSON, 39 // familiarizing yourself with it here may prove useful. You can write 40 // out a data structure as a JSON string to a file using the commented 41 // code below. The corresponding decoding functions can be found in 42 // common_reduce.go. 43 // 44 // enc := json.NewEncoder(file) 45 // for _, kv := ... { 46 // err := enc.Encode(&kv) 47 // 48 // Remember to close the file after you have written all the values! 49 // 50 51 // Read from inFile and save all keys and values in keyvalue 52 var keyvalue []KeyValue 53 fi, err := os.Open(inFile) 54 if err != nil { 55 log.Fatal("doMap Open: ", err) 56 } 57 defer fi.Close() 58 br := bufio.NewReader(fi) 59 for { 60 a, _, c := br.ReadLine() 61 if c == io.EOF { 62 break 63 } 64 kv := mapF(inFile, string(a)) 65 for i := 0; i != len(kv); i++ { 66 keyvalue = append(keyvalue, kv[i]) 67 } 68 } 69 70 // Create nReduce files and create encoder for each of them 71 var names []string 72 files := make([]*os.File, 0, nReduce) 73 enc := make([]*json.Encoder, 0, nReduce) 74 for r := 0; r != nReduce; r++ { 75 names = append(names, fmt.Sprintf("mrtmp.%s-%d-%d", jobName, mapTaskNumber, r)) 76 file, err := os.Create(names[r]) 77 if err != nil { 78 log.Fatal("doMap Create: ", err) 79 } 80 files = append(files, file) 81 enc = append(enc, json.NewEncoder(file)) 82 } 83 84 // Choose which file to store for each keyvalue 85 for _, kv := range keyvalue { 86 index := ihash(kv.Key)%nReduce 87 enc[index].Encode(kv) 88 } 89 90 // Close all files 91 for _, f := range files { 92 f.Close() 93 } 94 }
对于doReduce函数我们需要读取nMap个文件,将所有键值对解码并重新编码写出到outFile中
1 // doReduce manages one reduce task: it reads the intermediate 2 // key/value pairs (produced by the map phase) for this task, sorts the 3 // intermediate key/value pairs by key, calls the user-defined reduce function 4 // (reduceF) for each key, and writes the output to disk. 5 func doReduce( 6 jobName string, // the name of the whole MapReduce job 7 reduceTaskNumber int, // which reduce task this is 8 outFile string, // write the output here 9 nMap int, // the number of map tasks that were run ("M" in the paper) 10 reduceF func(key string, values []string) string, 11 ) { 12 // 13 // You will need to write this function. 14 // 15 // You'll need to read one intermediate file from each map task; 16 // reduceName(jobName, m, reduceTaskNumber) yields the file 17 // name from map task m. 18 // 19 // Your doMap() encoded the key/value pairs in the intermediate 20 // files, so you will need to decode them. If you used JSON, you can 21 // read and decode by creating a decoder and repeatedly calling 22 // .Decode(&kv) on it until it returns an error. 23 // 24 // You may find the first example in the golang sort package 25 // documentation useful. 26 // 27 // reduceF() is the application's reduce function. You should 28 // call it once per distinct key, with a slice of all the values 29 // for that key. reduceF() returns the reduced value for that key. 30 // 31 // You should write the reduce output as JSON encoded KeyValue 32 // objects to the file named outFile. We require you to use JSON 33 // because that is what the merger than combines the output 34 // from all the reduce tasks expects. There is nothing special about 35 // JSON -- it is just the marshalling format we chose to use. Your 36 // output code will look something like this: 37 // 38 // enc := json.NewEncoder(file) 39 // for key := ... { 40 // enc.Encode(KeyValue{key, reduceF(...)}) 41 // } 42 // file.Close() 43 // 44 45 // Read all mrtmp.xxx-m-reduceTaskNumber and write to outFile 46 var names []string 47 file, err := os.Create(outFile) 48 if err != nil { 49 log.Fatal("doReduce Create: ", err) 50 } 51 enc := json.NewEncoder(file) 52 defer file.Close() 53 54 // Read all contents from mrtmp.xxx-m-reduceTaskNumber 55 kvs := make(map[string][]string) 56 for m := 0; m != nMap; m++ { 57 names = append(names, fmt.Sprintf("mrtmp.%s-%d-%d", jobName, m, reduceTaskNumber)) 58 fi, err := os.Open(names[m]) 59 if err != nil { 60 log.Fatal("doReduce Open: ", err) 61 } 62 dec := json.NewDecoder(fi) 63 for { 64 var kv KeyValue 65 err = dec.Decode(&kv) 66 if err != nil { 67 break 68 } 69 kvs[kv.Key] = append(kvs[kv.Key], kv.Value) 70 } 71 fi.Close() 72 } 73 for k, v := range kvs { 74 enc.Encode(KeyValue{k, reduceF(k, v)}) 75 } 76 }
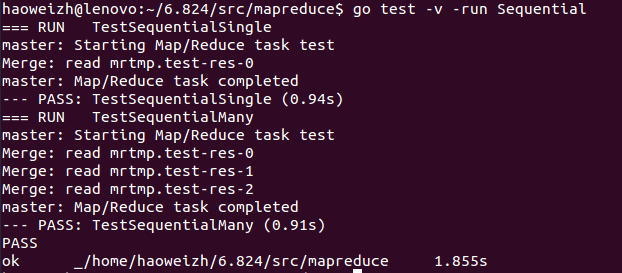
通过测试
Part2:
第二部分建立在第一部分的基础上,要进行词频统计,就很简单,对于mapF函数我们产生键值对,对于reduceF函数我们返回值出现的次数即可
1 // 2 // The map function is called once for each file of input. The first 3 // argument is the name of the input file, and the second is the 4 // file's complete contents. You should ignore the input file name, 5 // and look only at the contents argument. The return value is a slice 6 // of key/value pairs. 7 // 8 func mapF(filename string, contents string) []mapreduce.KeyValue { 9 // TODO: you have to write this function 10 f := func(c rune) bool { 11 return !unicode.IsLetter(c) 12 } 13 words := strings.FieldsFunc(contents, f) 14 var keyvalue []mapreduce.KeyValue 15 for _, word := range words { 16 keyvalue = append(keyvalue, mapreduce.KeyValue{word,""}) 17 } 18 return keyvalue 19 } 20 21 // 22 // The reduce function is called once for each key generated by the 23 // map tasks, with a list of all the values created for that key by 24 // any map task. 25 // 26 func reduceF(key string, values []string) string { 27 // TODO: you also have to write this function 28 return strconv.Itoa(len(values)) 29 }
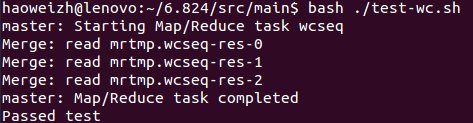
通过测试
Part3:
这一部分有点难,主要是对Go的并发机制要有一些了解才能做,阅读源代码,这个测试将100000以内的数字生成了100个文件,即100个Map任务,并产生50个Reduce任务,同时产生了两个worker,当全部map结束后进入reduce,所以schedule被调用了两次,先整体把握下该怎么写,由于这次需要分布式计算,所以我们可以分配ntasks个go程每次从registerChan中得到一个空闲的worker后调用call函数分配任务,然后结束后重新将其放到registerChan中(这里是第一个小坑,原本以为call函数调用结束后会自动将worker重新放入registerChan中,后来发现registerChan根本没有作为参数传入call函数,自然不能实现这个操作)
1 func TestBasic(t *testing.T) { 2 mr := setup() 3 for i := 0; i < 2; i++ { 4 go RunWorker(mr.address, port("worker"+strconv.Itoa(i)), 5 MapFunc, ReduceFunc, -1) 6 } 7 mr.Wait() 8 check(t, mr.files) 9 checkWorker(t, mr.stats) 10 cleanup(mr) 11 }
阅读文档可知这一部分的核心是call函数,用于任务的分配。
1 // call() sends an RPC to the rpcname handler on server srv 2 // with arguments args, waits for the reply, and leaves the 3 // reply in reply. the reply argument should be the address 4 // of a reply structure. 5 // 6 // call() returns true if the server responded, and false 7 // if call() was not able to contact the server. in particular, 8 // reply's contents are valid if and only if call() returned true. 9 // 10 // you should assume that call() will time out and return an 11 // error after a while if it doesn't get a reply from the server. 12 // 13 // please use call() to send all RPCs, in master.go, mapreduce.go, 14 // and worker.go. please don't change this function. 15 // 16 func call(srv string, rpcname string, 17 args interface{}, reply interface{}) bool { 18 c, errx := rpc.Dial("unix", srv) 19 if errx != nil { 20 return false 21 } 22 defer c.Close() 23 24 err := c.Call(rpcname, args, reply) 25 if err == nil { 26 return true 27 } 28 29 fmt.Println(err) 30 return false 31 }
首先我们需要明确四个参数的值,文档中说了,第一个参数从registerChan中获得,第二个参数是给定的字符串"Worker.DoTask",第四个参数是nil,第三个参数是个结构体DoTaskArgs,看看这个结构体长啥样
1 // What follows are RPC types and methods. 2 // Field names must start with capital letters, otherwise RPC will break. 3 4 // DoTaskArgs holds the arguments that are passed to a worker when a job is 5 // scheduled on it. 6 type DoTaskArgs struct { 7 JobName string 8 File string // only for map, the input file 9 Phase jobPhase // are we in mapPhase or reducePhase? 10 TaskNumber int // this task's index in the current phase 11 12 // NumOtherPhase is the total number of tasks in other phase; mappers 13 // need this to compute the number of output bins, and reducers needs 14 // this to know how many input files to collect. 15 NumOtherPhase int 16 }
再对照schedule的参数赋值即可,所有参数均有对应。基本上了解了以上几点可以得到下面的代码,和上面的思路一样,创建ntasks个go程,然后将doTaskArgs参数设置好,连同registerChan一并传入,一旦channel中有空闲的worker,随机找一个被阻塞的go程运行即可,因为都是并发的,所以谁先执行都没关系,然后用waitGroup阻塞主程,看起来很完美,但运行一半时会卡住,这是这个部分最大的坑,现在来分析下原因。
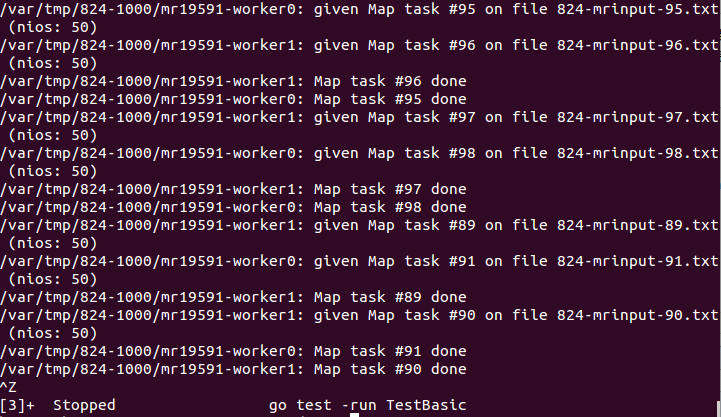
咱们先反复运行一下测试,发现得到下面的信息,仔细观察可以发现,这90和91号任务已经是最后两个任务了,为什么到最后会卡住,这是因为channel是阻塞式的(Distributed函数中定义channel时并未为其分配缓存),当倒数第二个任务完成后重新加到channel中时,已经没有go程会取出这个worker了,此时最后一个go程再想将worker添加到channel中时就会阻塞,所以这个代码会阻塞在最后一个go程的下面代码的第八行。
1 var wg sync.WaitGroup 2 wg.Add(ntasks) 3 for i := 0; i != ntasks; i++ { 4 doTaskArgs := DoTaskArgs{jobName, mapFiles[i] , phase, i, n_other} 5 go func(doTaskArgs DoTaskArgs, registerChan chan string) { 6 address := <-registerChan 7 call(address, "Worker.DoTask", doTaskArgs, nil) 8 registerChan <- address 9 wg.Done() 10 return 11 }(doTaskArgs, registerChan) 12 } 13 wg.Wait()
最简单的做法就是为第八行创建一个新协程,这样最后一个任务虽然无法添加到channel中,但由于它是另一个go程,所以当主程退出后,这个子程虽然还阻塞着,但也会强制退出。修改方式修改后得到如下代码
1 // 2 // schedule() starts and waits for all tasks in the given phase (Map 3 // or Reduce). the mapFiles argument holds the names of the files that 4 // are the inputs to the map phase, one per map task. nReduce is the 5 // number of reduce tasks. the registerChan argument yields a stream 6 // of registered workers; each item is the worker's RPC address, 7 // suitable for passing to call(). registerChan will yield all 8 // existing registered workers (if any) and new ones as they register. 9 // 10 func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) { 11 var ntasks int 12 var n_other int // number of inputs (for reduce) or outputs (for map) 13 switch phase { 14 case mapPhase: 15 ntasks = len(mapFiles) 16 n_other = nReduce 17 case reducePhase: 18 ntasks = nReduce 19 n_other = len(mapFiles) 20 } 21 22 fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other) 23 24 // All ntasks tasks have to be scheduled on workers, and only once all of 25 // them have been completed successfully should the function return. 26 // Remember that workers may fail, and that any given worker may finish 27 // multiple tasks. 28 // 29 // TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO 30 // 31 var wg sync.WaitGroup 32 wg.Add(ntasks) 33 for i := 0; i != ntasks; i++ { 34 doTaskArgs := DoTaskArgs{jobName, mapFiles[i] , phase, i, n_other} 35 go func(doTaskArgs DoTaskArgs, registerChan chan string) { 36 address := <-registerChan 37 call(address, "Worker.DoTask", doTaskArgs, nil) 38 go func() { 39 registerChan <- address 40 }() 41 wg.Done() 42 return 43 }(doTaskArgs, registerChan) 44 } 45 wg.Wait() 46 fmt.Printf("Schedule: %v phase done\n", phase) 47 }
通过测试

Part4:
有了第三部分铺垫,这一部分就非常简单了,如果worker失效,那么call函数会返回false,此时我们需要从channel中获得下一个worker直到call返回true为止,因此将获取worker和call函数放在一个for循环中即可。
1 // 2 // schedule() starts and waits for all tasks in the given phase (Map 3 // or Reduce). the mapFiles argument holds the names of the files that 4 // are the inputs to the map phase, one per map task. nReduce is the 5 // number of reduce tasks. the registerChan argument yields a stream 6 // of registered workers; each item is the worker's RPC address, 7 // suitable for passing to call(). registerChan will yield all 8 // existing registered workers (if any) and new ones as they register. 9 // 10 func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) { 11 var ntasks int 12 var n_other int // number of inputs (for reduce) or outputs (for map) 13 switch phase { 14 case mapPhase: 15 ntasks = len(mapFiles) 16 n_other = nReduce 17 case reducePhase: 18 ntasks = nReduce 19 n_other = len(mapFiles) 20 } 21 22 fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other) 23 24 // All ntasks tasks have to be scheduled on workers, and only once all of 25 // them have been completed successfully should the function return. 26 // Remember that workers may fail, and that any given worker may finish 27 // multiple tasks. 28 // 29 // TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO 30 // 31 var wg sync.WaitGroup 32 wg.Add(ntasks) 33 for i := 0; i != ntasks; i++ { 34 doTaskArgs := DoTaskArgs{jobName, mapFiles[i] , phase, i, n_other} 35 go func(doTaskArgs DoTaskArgs, registerChan chan string) { 36 success := false 37 var address string 38 for success==false { 39 address = <-registerChan 40 success = call(address, "Worker.DoTask", doTaskArgs, nil) 41 } 42 go func() { 43 registerChan <- address 44 }() 45 wg.Done() 46 }(doTaskArgs, registerChan) 47 } 48 wg.Wait() 49 fmt.Printf("Schedule: %v phase done\n", phase) 50 }
通过测试

Part5:
第五部分让我们实现一个inverted index,说白了就是每个出现过的单词->所有出现过该单词的文件,所以map过程输出单词->文件名,reduce过程构建所有独一无二的文件个数(利用哈希表,因为一个单词可能在同一文件出现多次,所以要去除重复文件名)以及所有文件名组成的长字符串(注意需要进行排序)。注意那个源代码上的注释有点误导人,忽略即可。
1 // The mapping function is called once for each piece of the input. 2 // In this framework, the key is the name of the file that is being processed, 3 // and the value is the file's contents. The return value should be a slice of 4 // key/value pairs, each represented by a mapreduce.KeyValue. 5 func mapF(document string, value string) (res []mapreduce.KeyValue) { 6 // TODO: you should complete this to do the inverted index challenge 7 f := func(c rune) bool { 8 return !unicode.IsLetter(c) 9 } 10 words := strings.FieldsFunc(value, f) 11 for _, word := range words { 12 res = append(res, mapreduce.KeyValue{word, document}) 13 } 14 return 15 } 16 17 // The reduce function is called once for each key generated by Map, with a 18 // list of that key's string value (merged across all inputs). The return value 19 // should be a single output value for that key. 20 func reduceF(key string, values []string) string { 21 // TODO: you should complete this to do the inverted index challenge 22 m := make(map[string]string) 23 for _, value := range values { 24 m[value] = value 25 } 26 var uniqueValues []string 27 for _, value := range m { 28 uniqueValues = append(uniqueValues, value) 29 } 30 sort.Strings(uniqueValues) 31 s := strconv.Itoa(len(m)) 32 s += " " 33 s += uniqueValues[0] 34 for i := 1; i != len(uniqueValues); i++ { 35 s += "," 36 s += uniqueValues[i] 37 } 38 return s 39 }
通过所有测试


