


正则表达式
使用正则表达式的目的
(查找)/(取出)/(匹配) 符合 条件 的某个字符或字符串;
正则表达式图标
- 正则很无情 ( 注意准确性 );
- 正则很大度 ( 贪婪匹配 );
- 别忘 '\';
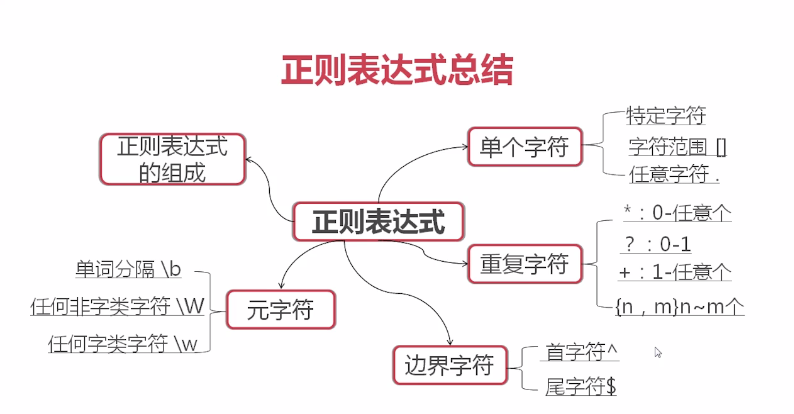
正则表达式层次
基础正则表达式
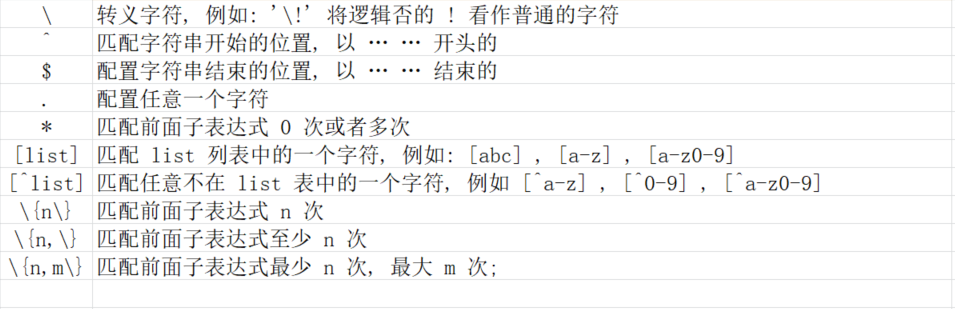
扩展正则表达式

常见的转义字符

正则使用方式举例
“^\d+$” //非负整数(正整数 + 0) “^[0-9]*[1-9][0-9]*$” //正整数 “^((-\d+)|(0+))$” //非正整数(负整数 + 0) “^-[0-9]*[1-9][0-9]*$” //负整数 “^-?\d+$” //整数 “^\d+(\.\d+)?$” //非负浮点数(正浮点数 + 0) “^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$” //正浮点数 “^((-\d+(\.\d+)?)|(0+(\.0+)?))$” //非正浮点数(负浮点数 + 0) “^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$” //负浮点数 “^(-?\d+)(\.\d+)?$” //浮点数 “^[A-Za-z]+$” //由26个英文字母组成的字符串 “^[A-Z]+$” //由26个英文字母的大写组成的字符串 “^[a-z]+$” //由26个英文字母的小写组成的字符串 “^[A-Za-z0-9]+$” //由数字和26个英文字母组成的字符串 “^\w+$” //由数字、26个英文字母或者下划线组成的字符串 ^[A-Za-z\d]+([-_.][A-Za-z\d]+)*@([A-Za-z\d]+[-.])+[A-Za-z\d]{2,4}$ // 邮箱 “^[a-zA-z]+://(\w+(-\w+)*)(\.(\w+(-\w+)*))*(\?\S*)?$” //url /^(\d{2}|\d{4})-((0([1-9]{1}))|(1[12]))-(([0-2]([1-9]{1}))|(3[01]))$/ // 年-月-日 /^((0([1-9]{1}))|(1[1|2]))/(([0-2]([1-9]{1}))|(3[0|1]))/(d{2}|d{4})$/ // 月/日/年 “^([w-.]+)@(([[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.)|(([w-]+.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(]?)$” //Email
正则表达式单字符
// 特定字符: 某个具体的字符 (例如 "1" , "a" ) [root@server ~]# grep '1' passwd bin:x:1:1:bin:/bin:/sbin/nologin mail:x:8:12:mail:/var/spool/mail:/sbin/nologin uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin operator:x:11:0:operator:/root:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ...... // 范围内字符: // ** 单个字符 [] (例如 [0-9], [259] , [a-z] , [A-Z] , [bcdq] , [a-zA-Z] , [,:_/]) // ** 配置范围中的单个字符;可混合写,直接范围拼接就行 (例如 [a-zA-Z0-9:,_/]) // ** 反向字符 ^ (例如 [^0-9] , [^0] ) [root@server ~]# grep '[0-9]' passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync ...... [root@server ~]# grep '[259]' passwd // 缩小范围 daemon:x:2:2:daemon:/sbin:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync mail:x:8:12:mail:/var/spool/mail:/sbin/nologin games:x:12:100:games:/usr/games:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin ...... [root@server ~]# grep '[a-g]' passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown ...... [root@server ~]# grep '[^0-9]' passwd // 取反 root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync // 任意字符 // ** 代表任何一个字符 '.' ; *** 注意 '[.]' 和 '\.' 的区别; [root@server ~]# grep '.' passwd // 匹配任意字符 root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync [root@server ~]# grep '[.]' passwd // 此处为匹配'.'; [root@server ~]# grep '\.' passwd // 转义为普通的'.',而非任意字符; // 边界字符 // ** 头尾字符 ^ (头字符) : ^root 表示以什么开头; ** 注意与[^]的区别; // $ (尾字符) : false$ 表示以什么结尾; // ^$ 表示空行; [root@server ~]# grep '^root' passwd root:x:0:0:root:/root:/bin/bash [root@server ~]# grep 'false$' passwd // 元字符(代表普通字符或特殊字符) // ** \w: 匹配任何字类字符,包括下划线,等同于 [a-zA-Z0-9_] // ** \W: 匹配任何非字类字符,等同于 [^a-zA-Z0-9_] // ** \b: 代表单词的分割; [root@server ~]# grep '\bx\b' passwd // 只匹配放置密码的单个 'x',而不匹配单词中的x; root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin adm:x:3:4:adm:/var/adm:/sbin/nologin lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin sync:x:5:0:sync:/sbin:/bin/sync ......
正则表达式字符组合
// 字符串 // ** 'root' '1000' 'r..t' [root@server ~]# grep 'root' passwd // 匹配root字符串 root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin [root@server ~]# grep 'r..t' passwd // 匹配r与t中间两个任意的字符; root:x:0:0:root:/root:/bin/bash operator:x:11:0:operator:/root:/sbin/nologin ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin // ** '[A-Z][a-z]' '[0-9][0-9]' [root@server ~]# grep '[A-Z][a-z]' passwd ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin nobody:x:99:99:Nobody:/:/sbin/nologin dbus:x:81:81:System message bus:/:/sbin/nologin ... // *** 重复 (se)*-->针对字符串的重复,正则表达式中()也需要加上'\',如'\(se\)*'; // *: 零次或者多次匹配前面的字符或子表达式; // +: 一次或者多次匹配前面的字符或子表达式; (需要配合'\'使用) // ?: 零次或者一次匹配前面的字符或子表达式; (同样需要配合'\'使用) // {n,m}: 重复特定次数 grep '[0-9]\{2,3\}' passwd // *** 任意字符串 '.*' 例如:^r.* m.*t (贪婪匹配) // *** 逻辑的表示 '|' 例如:'/bin\(false\|true\)'
正则表达式案例
// 案例一, 匹配4-10位的QQ号 [root@server ~]# grep '\b[0-9]\{4,10\}\b' qq.txt [root@server ~]# grep '^[0-9]\{4,10\}$' qq.txt // 案例二, 匹配15位或18位的身份证号(支持带X的) // 分析: 身份证号开头不能是0,结尾有可能为X,两头确定好,中间为13或16的逻辑与. [root@server ~]# grep '^[1-9]\([0-9]\{13\}\|[0-9]\{16\}\)[0-9xX]$' cert.txt // 案例三, 匹配密码(由数字,26个字母和下划线组成) // 分析: 按描述,确定\w可符合,重复一次或者多次 [root@server ~]# grep '^\w\+$' cert.txt
作者:TZHR —— 世间一散人
出处:https://www.cnblogs.com/haorong/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明

