URI与URL区别
URL 与 URI
很多人会混淆这两个名词。
URL:(Uniform/Universal Resource Locator 的缩写,统一资源定位符)。
URI:(Uniform Resource Identifier 的缩写,统一资源标识符)(代表一种标准)。
关系:
URI 属于 URL 更高层次的抽象,一种字符串文本标准。
就是说,URI 属于父类,而 URL 属于 URI 的子类。URL 是 URI 的一个子集。
二者的区别在于,URI 表示请求服务器的路径,定义这么一个资源。而 URL 同时说明要如何访问这个资源(http://)。
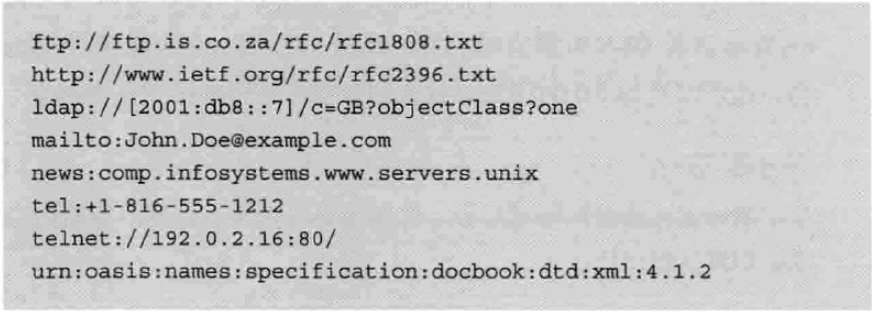
URI 示例
大家把浏览器地址栏里访问网站的地址认为是URL就好了,也就是以HTTP/HTTPS开头的URI子集。
端口 与 URL标准格式
何为端口?端口(Port),相当于一种数据的传输通道。用于接受某些数据,然后传输给相应的服务,而电脑将这些数据处理后,再将相应的回复通过开启的端口传给对方。
端口的作用:因为 IP 地址与网络服务的关系是一对多的关系。所以实际上因特网上是通过 IP 地址加上端口号来区分不同的服务的。
端口是通过端口号来标记的,端口号只有整数,范围是从0 到65535。
URL 标准格式
通常而言,我们所熟悉的 URL 的常见定义格式为:
scheme://host[:port#]/path/.../[;url-params][?query-string][#anchor]
scheme //有我们很熟悉的http、https、ftp以及著名的ed2k,迅雷的thunder等。 host //HTTP服务器的IP地址或者域名 port# //HTTP服务器的默认端口是80,这种情况下端口号可以省略。如果使用了别的端口,必须指明,例如tomcat的默认端口是8080 http://localhost:8080/ path //访问资源的路径 url-params //所带参数 query-string //发送给http服务器的数据 anchor //锚点定位
利用 a 标签自动解析 url
开发当中一个很常见的场景是,需要从 URL 中提取一些需要的元素,譬如 host 、 请求参数等等。
通常的做法是写正则去匹配相应的字段,但是这里参考James 的 blog,原理是动态创建一个 a 标签,利用浏览器的一些原生方法及一些正则(为了健壮性正则还是要的),完美解析 URL ,获取我们想要的任意一个部分。
代码如下:
// This function creates a new anchor element and uses location // properties (inherent) to get the desired URL data. Some String // operations are used (to normalize results across browsers). function parseURL(url) { var a = document.createElement('a'); a.href = url; return { source: url, protocol: a.protocol.replace(':',''), host: a.hostname, port: a.port, query: a.search, params: (function(){ var ret = {}, seg = a.search.replace(/^\?/,'').split('&'), len = seg.length, i = 0, s; for (;i<len;i++) { if (!seg[i]) { continue; } s = seg[i].split('='); ret[s[0]] = s[1]; } return ret; })(), file: (a.pathname.match(/([^/?#]+)$/i) || [,''])[1], hash: a.hash.replace('#',''), path: a.pathname.replace(/^([^/])/,'/$1'), relative: (a.href.match(/tps?:\/[^/]+(.+)/) || [,''])[1], segments: a.pathname.replace(/^\//,'').split('/') }; }
Usage 使用方法:
var myURL = parseURL('http://abc.com:8080/dir/index.html?id=255&m=hello#top'); myURL.file; // = 'index.html' myURL.hash; // = 'top' myURL.host; // = 'abc.com' myURL.query; // = '?id=255&m=hello' myURL.params; // = Object = { id: 255, m: hello } myURL.path; // = '/dir/index.html' myURL.segments; // = Array = ['dir', 'index.html'] myURL.port; // = '8080' myURL.protocol; // = 'http' myURL.source; // = 'http://abc.com:8080/dir/index.html?id=255
利用上述方法,即可解析得到 URL 的任意部分。
参考:https://github.com/chokcoco/cnblogsArticle/issues/6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号