
Python模块之struct
0 背景
在工作中,有些二进制文件,是通过结构体写入文件而形成,我们有时候想解析这些文件,那如何操作呢?python 的struct 模块和C 语言的结构体是相对应的,这样,只要知道结构体的定义,我们就可以通过struct 模块写出一些解析工具。
1. strcut 模块介绍
class struct.Struct(format)
返回:一个struct 对象(相对于C 的结构体)
作用:该对象可以根据 格式化字符串的格式 来读写二进制数据。
参数:格式化字符串(类似C语言中printf 打印输出的格式化字符串),其中第一个字符,指定字节的顺序(大端或者小端)。
注意:以大端或者小端的方式读写数据可以根据系统默认,不用指定;但是也可以指定。
例:struct.Struct('>I4sf') 里面的格式化字符串,参考后面的附表。
>: 大端模式
I: unsigned int
4s: 4 个 char
f: float
1.1 方法pack
属性:
format :格式化字符串
size:结构体的大小
方法:
pack(v1,v2, ....)
返回:一个字节流对象
s. pack(v1,v2, ....) : 按照fmt(格式化字符串)的格式,来打包参数v1,v2,....。
s.pack_into(buffer, offset, v1, v2, …) :按照fmt(格式化字符串)的格式,来打包参数v1,v2,....,并将打包的字节从offset(偏移位置)处开始,写入可写缓冲buffer 中。(注意:这里的offset 是必需的参数)
s.unpack_from(buffer,offset=) :按照fmt(格式化字符串)的格式,在offset偏移处开始,从缓冲区解包。其结果是一个元组。缓冲区的大小(以字节为单位,减去偏移量)必需至少为格式所需的大小,如calcsize() 所反映的。
2. 相关实例
这里来写几个常见的实例
2.1 一般情况
代码:
先将数据对象,放到一个元组中,然后创建一个Struct对象,并使用pack()方法打包该元组;然后解包该元组。
# -*- coding: utf-8 -*-
"""
打包和解包
"""
import struct
import binascii
values = (1, b'good', 1.22) #查看格式化对照表可知,字符串必须为字节流类型。
s = struct.Struct('I4sf')
packed_data = s.pack(*values)
unpacked_data = s.unpack(packed_data)
print('Original values:', values)
print('Format string :', s.format)
print('Uses :', s.size, 'bytes')
print('Packed Value :', binascii.hexlify(packed_data))
print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data)
结果:
('Original values:', (1, 'good', 1.22))
('Format string :', 'I4sf')
('Uses :', 12, 'bytes')
('Packed Value :', '01000000676f6f64f6289c3f')
('Unpacked Type :', <type 'tuple'>, ' Value:', (1, 'good', 1.2200000286102295))
2.2 库函数binascii.hexlify
返回:字节流(十六进制)
例子:
>>> a = 'hello' >>> b = a.encode() >>> b b'hello' >>> c = binascii.hexlify(b) >>> c b'68656c6c6f'
2.3 使用buffer来进行打包和解包
使用通常方式打包和解包,会造成内存的浪费,所以python提供了buffer的方式。
例子:
# -*- coding: utf-8 -*-
"""
通过buffer方式打包和解包
"""
import struct
import binascii
import ctypes
values = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。
s = struct.Struct('I4sf')
buff = ctypes.create_string_buffer(s.size)
packed_data = s.pack_into(buff,0,*values)
unpacked_data = s.unpack_from(buff,0)
print('Original values:', values)
print('Format string :', s.format)
print('buff :', buff)
print('Packed Value :', binascii.hexlify(buff))
print('Unpacked Type :', type(unpacked_data), ' Value:', unpacked_data)
结果:
('Original values:', (1, 'good', 1.22))
('Format string :', 'I4sf')
('buff :', <ctypes.c_char_Array_12 object at 0x7f75bfafddd0>)
('Packed Value :', '01000000676f6f64f6289c3f')
('Unpacked Type :', <type 'tuple'>, ' Value:', (1, 'good', 1.2200000286102295))
说明:
这里用到了函数:ctypes.create_string_buffer(init_or_size,size = None),创建可变字符缓冲区。
- 返回的对象是:c_char 的ctypes 数组
- init_or_size 必须是一个整数,它指定数组的大小,或者用于初始化数组项的字节对象。
2.4 使用buffer的方式来打包多个对象
例子:
# -*- coding: utf-8 -*-
"""
buffer方式打包和解包多个对象
"""
import struct
import binascii
import ctypes
values1 = (1, b'good', 1.22) #查看格式化字符串可知,字符串必须为字节流类型。
values2 = (b'hello',True)
s1 = struct.Struct('I4sf')
s2 = struct.Struct('5s?')
buff = ctypes.create_string_buffer(s1.size+s2.size)
packed_data_s1 = s1.pack_into(buff,0,*values1)
packed_data_s2 = s2.pack_into(buff,s1.size,*values2)
unpacked_data_s1 = s1.unpack_from(buff,0)
unpacked_data_s2 = s2.unpack_from(buff,s1.size)
print('Original values1:', values1)
print('Original values2:', values2)
print('buff :', buff)
print('Packed Value :', binascii.hexlify(buff))
print('Unpacked Type :', type(unpacked_data_s1), ' Value:', unpacked_data_s1)
print('Unpacked Type :', type(unpacked_data_s2), ' Value:', unpacked_data_s2)
结果:
('Original values1:', (1, 'good', 1.22))
('Original values2:', ('hello', True))
('buff :', <ctypes.c_char_Array_18 object at 0x7f5daa99ddd0>)
('Packed Value :', '01000000676f6f64f6289c3f68656c6c6f01')
('Unpacked Type :', <type 'tuple'>, ' Value:', (1, 'good', 1.2200000286102295))
('Unpacked Type :', <type 'tuple'>, ' Value:', ('hello', True))
3. 对照表
3.1 格式对照表
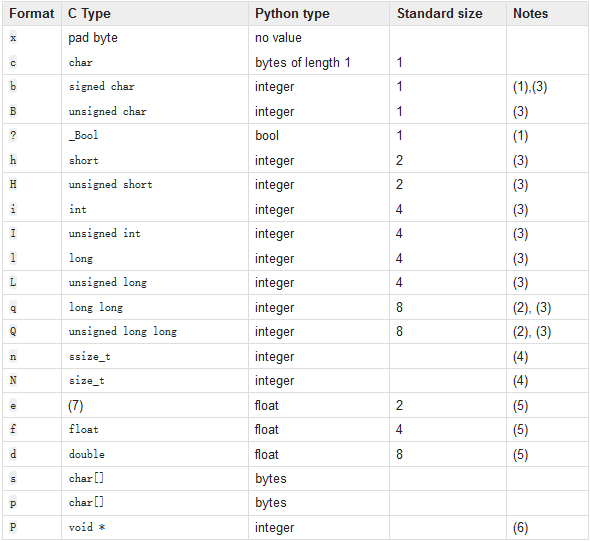
注意:
signed char(有符号位)取值范围是 -128 到 127(有符号位)
unsigned char (无符号位)取值范围是 0 到 255
3.2 字节顺序
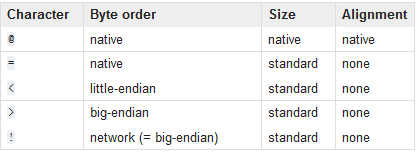
参考链接:
https://www.lmlphp.com/user/63990/article/item/721809/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号