
kubelet源码分析: CNI 插件处理流程
整体介绍
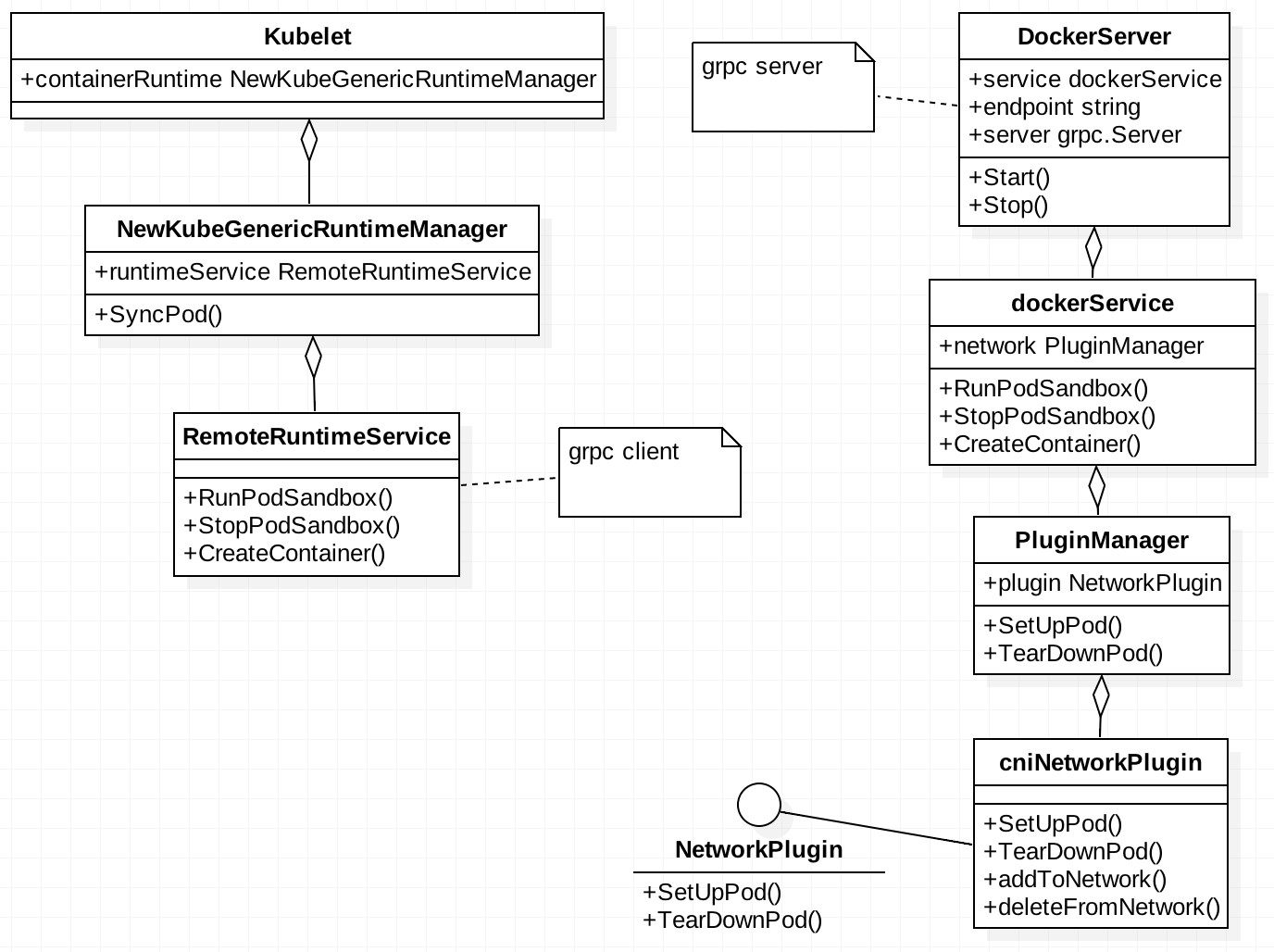
kubelet通过调用 grpc 接口调用实现了 CRI 的 dockershim 完成 rpc 通信,CNI 是由 dockershim grpc server 中调用的
kubelet -> CRI shim -> container runtime -> container
POD 创建过程中从 kubelet 到 docker server 到 cni 的 UML 结构如下
CNI 插件初始化
kubelet 在初始化的时候如果使用containerRuntime为Docker,则会起动dockershim rpc server
case kubetypes.DockerContainerRuntime:
// Create and start the CRI shim running as a grpc server.
streamingConfig := getStreamingConfig(kubeCfg, kubeDeps)
ds, err := dockershim.NewDockerService(kubeDeps.DockerClientConfig, crOptions.PodSandboxImage, streamingConfig,
&pluginSettings, runtimeCgroups, kubeCfg.CgroupDriver, crOptions.DockershimRootDirectory,
crOptions.DockerDisableSharedPID)
if err != nil {
return nil, err
}
// For now, the CRI shim redirects the streaming requests to the
// kubelet, which handles the requests using DockerService..
klet.criHandler = ds
// The unix socket for kubelet <-> dockershim communication.
glog.V(5).Infof("RemoteRuntimeEndpoint: %q, RemoteImageEndpoint: %q",
remoteRuntimeEndpoint,
remoteImageEndpoint)
glog.V(2).Infof("Starting the GRPC server for the docker CRI shim.")
server := dockerremote.NewDockerServer(remoteRuntimeEndpoint, ds)
if err := server.Start(); err != nil {
return nil, err
}
创建 dockerservice 对象时初始化cniplugin
cniPlugins := cni.ProbeNetworkPlugins(pluginSettings.PluginConfDir, pluginSettings.PluginBinDir)
cniPlugins = append(cniPlugins, kubenet.NewPlugin(pluginSettings.PluginBinDir))
初始化cniplugin,会根据pluginDir查找符合条件的第一个 CNI config 文件,并以此 config 文件查找到对应的 CNI bin
func probeNetworkPluginsWithVendorCNIDirPrefix(pluginDir, binDir, vendorCNIDirPrefix string) []network.NetworkPlugin {
if binDir == "" {
binDir = DefaultCNIDir
}
plugin := &cniNetworkPlugin{
defaultNetwork: nil,
loNetwork: getLoNetwork(binDir, vendorCNIDirPrefix),
execer: utilexec.New(),
pluginDir: pluginDir,
binDir: binDir,
vendorCNIDirPrefix: vendorCNIDirPrefix,
}
// sync NetworkConfig in best effort during probing.
plugin.syncNetworkConfig()
return []network.NetworkPlugin{plugin}
}
func (plugin *cniNetworkPlugin) syncNetworkConfig() {
network, err := getDefaultCNINetwork(plugin.pluginDir, plugin.binDir, plugin.vendorCNIDirPrefix)
if err != nil {
glog.Warningf("Unable to update cni config: %s", err)
return
}
plugin.setDefaultNetwork(network)
}
// plugin目录中找到符合.conf,.conflist,.json为后缀的文件,用文件名来排序,并从文件
// 名列表中找到符合cni 配置规则的plugin配置文件并返回。
func getDefaultCNINetwork(pluginDir, binDir, vendorCNIDirPrefix string) (*cniNetwork, error) {
if pluginDir == "" {
pluginDir = DefaultNetDir
}
files, err := libcni.ConfFiles(pluginDir, []string{".conf", ".conflist", ".json"})
switch {
case err != nil:
return nil, err
case len(files) == 0:
return nil, fmt.Errorf("No networks found in %s", pluginDir)
}
sort.Strings(files)
for _, confFile := range files {
var confList *libcni.NetworkConfigList
if strings.HasSuffix(confFile, ".conflist") {
confList, err = libcni.ConfListFromFile(confFile)
if err != nil {
glog.Warningf("Error loading CNI config list file %s: %v", confFile, err)
continue
}
} else {
conf, err := libcni.ConfFromFile(confFile)
if err != nil {
glog.Warningf("Error loading CNI config file %s: %v", confFile, err)
continue
}
// Ensure the config has a "type" so we know what plugin to run.
// Also catches the case where somebody put a conflist into a conf file.
if conf.Network.Type == "" {
glog.Warningf("Error loading CNI config file %s: no 'type'; perhaps this is a .conflist?", confFile)
continue
}
confList, err = libcni.ConfListFromConf(conf)
if err != nil {
glog.Warningf("Error converting CNI config file %s to list: %v", confFile, err)
continue
}
}
if len(confList.Plugins) == 0 {
glog.Warningf("CNI config list %s has no networks, skipping", confFile)
continue
}
confType := confList.Plugins[0].Network.Type
// Search for vendor-specific plugins as well as default plugins in the CNI codebase.
vendorDir := vendorCNIDir(vendorCNIDirPrefix, confType)
cninet := &libcni.CNIConfig{
Path: []string{vendorDir, binDir},
}
network := &cniNetwork{name: confList.Name, NetworkConfig: confList, CNIConfig: cninet}
return network, nil
}
return nil, fmt.Errorf("No valid networks found in %s", pluginDir)
}
POD 创建来源
在分析 POD 创建的流程之前,我们先看下 kubelet 是怎么获取 POD 资源。 总结下来有三种 POD 来源:
- 最常见的是 kubelet list & watch apiserver 获取 POD 资源的更新
- 静态目录下 static POD
- kubelet 提供的 http 服务
后面两者都是 static POD, kubelet 为了能够在 apiserver 也能管理 static POD,在 apiserver 创建了 mirror POD。
// makePodSourceConfig 为kubelet 提供 pod update 事件来源,目前支持三种,监听url,
// 监听目录,watch apiserver,每种来源都有对应的channel
func makePodSourceConfig(kubeCfg *kubeletconfiginternal.KubeletConfiguration, kubeDeps *Dependencies, nodeName types.NodeName, bootstrapCheckpointPath string) (*config.PodConfig, error) {
manifestURLHeader := make(http.Header)
if len(kubeCfg.ManifestURLHeader) > 0 {
for k, v := range kubeCfg.ManifestURLHeader {
for i := range v {
manifestURLHeader.Add(k, v[i])
}
}
}
// source of all configuration
cfg := config.NewPodConfig(config.PodConfigNotificationIncremental, kubeDeps.Recorder)
// define file config source
if kubeCfg.PodManifestPath != "" {
glog.Infof("Adding manifest path: %v", kubeCfg.PodManifestPath)
config.NewSourceFile(kubeCfg.PodManifestPath, nodeName, kubeCfg.FileCheckFrequency.Duration, cfg.Channel(kubetypes.FileSource))
}
// define url config source
if kubeCfg.ManifestURL != "" {
glog.Infof("Adding manifest url %q with HTTP header %v", kubeCfg.ManifestURL, manifestURLHeader)
config.NewSourceURL(kubeCfg.ManifestURL, manifestURLHeader, nodeName, kubeCfg.HTTPCheckFrequency.Duration, cfg.Channel(kubetypes.HTTPSource))
}
// Restore from the checkpoint path
// NOTE: This MUST happen before creating the apiserver source
// below, or the checkpoint would override the source of truth.
var updatechannel chan<- interface{}
if bootstrapCheckpointPath != "" {
glog.Infof("Adding checkpoint path: %v", bootstrapCheckpointPath)
updatechannel = cfg.Channel(kubetypes.ApiserverSource)
err := cfg.Restore(bootstrapCheckpointPath, updatechannel)
if err != nil {
return nil, err
}
}
if kubeDeps.KubeClient != nil {
glog.Infof("Watching apiserver")
if updatechannel == nil {
updatechannel = cfg.Channel(kubetypes.ApiserverSource)
}
config.NewSourceApiserver(kubeDeps.KubeClient, nodeName, updatechannel)
}
return cfg, nil
}
之后每个pod来源的更新都会发送事件到podcfg的update channel
// syncLoop is the main loop for processing changes. It watches for changes from
// three channels (file, apiserver, and http) and creates a union of them. For
// any new change seen, will run a sync against desired state and running state. If
// no changes are seen to the configuration, will synchronize the last known desired
// state every sync-frequency seconds. Never returns.
func (kl *Kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
glog.Info("Starting kubelet main sync loop.")
// The resyncTicker wakes up kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
const (
base = 100 * time.Millisecond
max = 5 * time.Second
factor = 2
)
duration := base
for {
if rs := kl.runtimeState.runtimeErrors(); len(rs) != 0 {
glog.Infof("skipping pod synchronization - %v", rs)
// exponential backoff
time.Sleep(duration)
duration = time.Duration(math.Min(float64(max), factor*float64(duration)))
continue
}
// reset backoff if we have a success
duration = base
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
POD create
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
glog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
glog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
glog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletiontimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
glog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
glog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
glog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
... ...
return true
}
pod_works用于为pod update分配goroutine执行具体任务。
result := kl.containerRuntime.SyncPod(pod, apiPodStatus, podStatus, pullSecrets, kl.backOff)
syncpod时会调用createPodSandbox 来创建pause container(infrastructure container),pause pod 创建后所有的业务容器共享该pause 容器的网络。
在创建 pause 容器时调用如下方法配置网络,
err = ds.network.SetUpPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID, config.Annotations)
// 为了能够保证业务pod在异常退出时仍然能够保存网络信息,因此创建pause (infra)容器来共享网络配置
// pause container也叫做 infrastructure-container,
// RunPodSandbox creates and starts a pod-level sandbox. Runtimes should ensure
// the sandbox is in ready state.
// For docker, PodSandbox is implemented by a container holding the network
// namespace for the pod.
// Note: docker doesn't use LogDirectory (yet).
func (ds *dockerService) RunPodSandbox(config *runtimeapi.PodSandboxConfig) (id string, err error) {
// Step 1: Pull the image for the sandbox.
... ...
// Step 2: Create the sandbox container.
... ....
// Step 3: Create Sandbox Checkpoint.
... ...
// Step 4: Start the sandbox container.
... ...
// Step 5: Setup networking for the sandbox.
// All pod networking is setup by a CNI plugin discovered at startup time.
// This plugin assigns the pod ip, sets up routes inside the sandbox,
// creates interfaces etc. In theory, its jurisdiction ends with pod
// sandbox networking, but it might insert iptables rules or open ports
// on the host as well, to satisfy parts of the pod spec that aren't
// recognized by the CNI standard yet.
cID := kubecontainer.BuildContainerID(runtimeName, createResp.ID)
err = ds.network.SetUpPod(config.GetMetadata().Namespace, config.GetMetadata().Name, cID, config.Annotations)
if err != nil {
// TODO(random-liu): Do we need to teardown network here?
if err := ds.client.StopContainer(createResp.ID, defaultSandboxGracePeriod); err != nil {
glog.Warningf("Failed to stop sandbox container %q for pod %q: %v", createResp.ID, config.Metadata.Name, err)
}
}
return createResp.ID, err
}
SetUpPod -> addToNetwork,cniNet.AddNetworkList 根据 CNI 执行 CNI binary,并将 CNI config 文件内容作为 stdin ,将podName, podNamespace, podSandboxID 等以 env 的形式传递给 CNI binary
func (plugin *cniNetworkPlugin) addToNetwork(network *cniNetwork, podName string, podNamespace string, podSandboxID kubecontainer.ContainerID, podNetnsPath string, annotations map[string]string) (cnitypes.Result, error) {
rt, err := plugin.buildCNIRuntimeConf(podName, podNamespace, podSandboxID, podNetnsPath, annotations)
if err != nil {
glog.Errorf("Error adding network when building cni runtime conf: %v", err)
return nil, err
}
netConf, cniNet := network.NetworkConfig, network.CNIConfig
glog.V(4).Infof("About to add CNI network %v (type=%v)", netConf.Name, netConf.Plugins[0].Network.Type)
res, err := cniNet.AddNetworkList(netConf, rt)
if err != nil {
glog.Errorf("Error adding network: %v", err)
return nil, err
}
return res, nil
}

