
Redis(三)、Redis主从复制
一、主从复制
主从复制:主节点负责写数据,从节点负责读数据,从而实现读写分离,提高redis的高可用性。
让一个服务器去复制(replicate)另一个服务器,我们称呼被复制的服务器为主节点(master),而对主服务器进行复制的服务器则被称为从节点(slave),
如下图所示:
主从复制的特点:
1、一个master可以有多个slave
2、一个slave只能有一个master
3、数据流向是单向的,master到slave
主从复制的作用:
1、数据副本:多一份或多份数据拷贝,保证redis高可用
2、扩展性能:单机redis的性能是有限的,主从复制能横向扩展 如容量、QPS等
二、主从复制实现方式
客户端命令:slaveof

配置方式:
新建redis-6380.conf,加入配置
# 1.指明谁是主节点 slaveof your-master-ip your-master-port # 2.让从节点只做读的操作,保证主节点和从节点数据同步一致性和读写分离。 slave-ready-only yes
三、全量复制和增量复制
1. runId:Redis每次启动时,都会生成一个不同的id来标示当前运行的Redis。从节点中会保存主节点的run_id标示,
如果主节点的Redis发生了重启,那么从节点依据ip和端口号连接到主节点时,就会发现主节点的run_id标示的改变(这种改变意味着主节点中的数据可能发生的大量的改动),
所以此时就会引起全量复制,也就是将主节点中的所有数据全部复制过来。 root@f9eb2360ed36:/usr/local/bin# ./redis-cli -p 6379 info server # Server redis_version:4.0.14 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:9ac979c18029eef1 redis_mode:standalone os:Linux 3.10.0-514.26.2.el7.x86_64 x86_64 arch_bits:64 multiplexing_api:epoll atomicvar_api:atomic-builtin gcc_version:6.3.0 process_id:1 run_id:49dbc223587cbdadd158adc21816979722b65ae1 tcp_port:6379 uptime_in_seconds:105535 uptime_in_days:1 hz:10 lru_clock:1086433 executable:/data/redis-server config_file: 2. 偏移量:每当主节点增删改一个数据时,主节点中就会有一个数值来记录这种变化,偏移量就是记录Redis中数据改变的一个标示,当主节点更改一个数据时,
偏移量也会发生对应的改变,而且主节点在将数据更改命令同步给从节点时,也会将该偏移量发送给从节点,这样就可以对比主从节点的偏移量,来观察是否出现主从不一致的问题。
使用 ./redis-cli -p 6379 info replication 该命令即可在主节点中查看主从节点的偏移量
3.1 全量复制
过程:
1. 向主节点发送psync,有两个参数,第一个参数是runId,第二个参数是偏移量,第一次发送不知道主节点的runId,也不知道偏移量,因此从节点发送 ? -1
2. 主节点收到消息,根据? -1 能判断出来是第一次复制,主节点把runId和offset 发送给Slave节点,
3. 从节点保存主节点基本信息
4-5-6. Master节点执行bgsave生成快照,在此期间会记录后续执行的数据更改命令所更改的数据,直到主节点将生成的RDB文件传输到从节点为止,
期间Master节点执行的写操作,主节点会将缓冲区中记录的新更改的数据发送给从节点
7-8 从节点清空此前的所有数据,加载RDB文件恢复数据并存入新更改的数据

说明:
- 全量复制的性能开销:1. bgsave生成RDB文件需要的时间,2. RDB文件在网络间的传输时间,3. 从节点的数据清空时间 , 4. 加载RDB文件的时间 5. 可能的 AOF 重写时间
- 数据更改命令缓冲区repl_back_buffer用于:当Redis通过Linux中的fork()函数开辟一个子进程处理其他事务(比如主进程执行bgsave生成一个RDB文件时,或者主进程执行bgrewriteaof生成一个AOF文件时), 而主进程(即处理客户端命令的进程)后续执行的一些数据更改命令会被暂时保存在该区域,而且该区域空间有限(配置文件中repl-backlog-size 1mb即可配置该处空间大小)
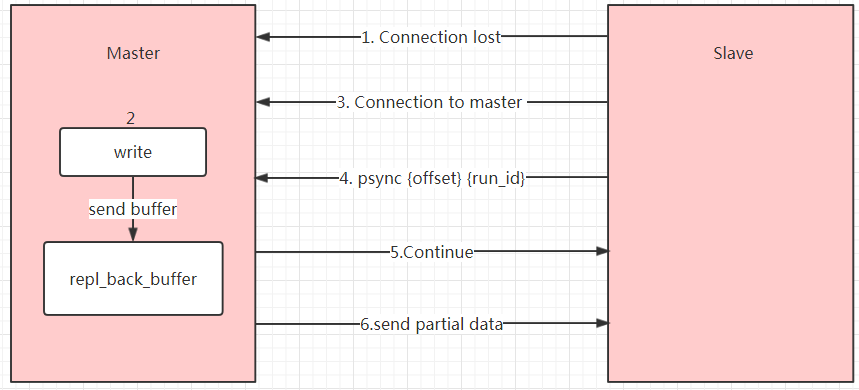
3.2 部分复制
部分复制解决的问题:在实际环境中,主节点与从节点之间可能会发生一些网络波动等情况,导致从节点与主节点之间的网络连接断开(主从节点的Redis均未关闭),如果重新连接上后,可以使用全量复制来重新进行一次主从节点数据同步,但是全量复制会带来一个性能开销的问题,而且从节点中可能有大量数据是主节点中没有更该过的,也就是不需要进行再次同步的数据,如果使用全量复制肯定是带来了一些不必要的浪费。所以,部分复制功能就是为了解决该问题的。
过程:
1. 主从节点直接连接断开,
2. 此时主节点继续执行的数据更改命令会被记录在一个缓冲区 repl_back_buffer 中
3. 当从节点重新连接主节点时,
4. 自动发出一条命令(psync offset run_id),将从节点中存储的主节点的Redis运行时id和从节点中保存的偏移量发送给主节点
5. 主节点接收从节点发送的偏移量和id,对比此时主节点的偏移量和接收的偏移量,如果两个偏移量之差大于repl_back_buffer中的数据,那么就表示在断开连接期间从节点已经丢失了超出规定数量的数据,此时就需要进行全量复制了,否则就进行部分复制
6. 将主节点缓冲区中的数据同步更新到从节点中,这样就实现了部分数据的复制同步,降低了性能开销
四、主从节点的故障处理
- 故障发生时服务自动转移(自动故障转移):即当某个节点发生故障导致停止服务时,该节点提供的服务会有另一个节点自动代替提供,这样就实现了一个高可用的效果
- 从节点故障:即如果某个从节点发生了故障,导致无法向在该节点上的客户端提供读服务,解决办法就是使该客户端转移到另一个可用从节点上,但是在转移时,应该考虑该从节点能承受几个客户端的压力
- 主节点故障:如果主节点发生故障,在使用主节点进行读写操作的客户端就无法使用了,而使用从节点只进行读操作的客户端还是可以继续使用的,解决办法就是从从节点中选一个节点更改为主节点,并且将原主节点的客户端连接到新的主节点上,然后通过该客户端将其他从节点连接到新的主节点中
- 主从复制确实可以解决故障问题,但是主从复制不能实现自动故障转移,其必须要通过一些手动操作,而且非常麻烦,所以要实现自动故障转移还需要另一个功能,Redis中提供了sentinel功能来实现自动故障转移。
五、主从节点的故障处理
1. 读写分离:即客户端发来的读写命令分开,写命令交给主节点执行,读命令交给从节点执行,不仅减少了主节点的压力,而且增强了读操作的能力;但也会造成一些问题
- 但是主从节点之间数据复制造成的阻塞延迟也可能会导致主从不一致的情况,也就是主节点先进行了写操作,但可能因为数据复制造成的阻塞延迟,导致在从节点上进行的读操作获取的数据与主节点不一致
- 读取过期数据:主从复制会将带有过期时间的数据一并复制到从节点中,但是从节点是没有删除数据的能力的,即使是过期数据,所以主节点中的已经删除了过期数据,但是因为主从复制的阻塞延迟问题导致从节点中的过期数据没有删除,此时客户端就会读到一个过期数据
2. 主从配置不一致:造成的问题有
- 比如配置中的maxmemory参数如果配置不一致,比如主节点2Gb,从节点1Gb,那么就可能会导致数据丢失;以及一些其他配置问题
3. 规避全量复制:全量复制的性能开销较大,所以要尽量避免全量复制,
- 在第一次建立主从节点关系式一定会发生全量复制;可以适当减小Redis的maxmemory参数,这样可以使得RDB更快,或者选择在客户端操作低峰期进行,比如深夜
- 从节点中保存的主节点run_id不一致时也一定会发生全量复制(比如主节点的重启);可以通过故障转移来尽量避免,例如Redis Sentinel 与 Redis Cluster
- 当主从节点的偏移量之差大于命令缓冲区repl_back_buffer中对应数据的偏移差时,也会发生全量复制,也就是上面的部分复制的复制过程中所说的;可以适当增大配置文件中repl-backlog-size即数据缓冲区可尽量避免
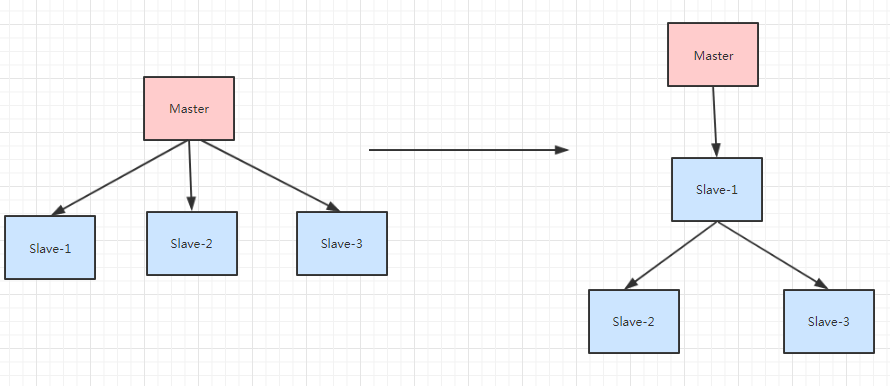
4. 规避复制风暴:
- 单主节点导致的复制风暴,即当主节点重启后,要向其所有的从节点都进行一次全量复制,这非常消耗性能;可以更换主从节点的拓扑结构,更换为类似树形的结构,一个主节点只与少量的从节点建立主从关系,而而这些主节点又与其他从节点构成主从关系,
- 如图所示
- 单主节点机器复制风暴:即如果过一台机器专门用来部署多个主节点,然后其他机器部署从节点,那么一旦主节点机器宕机重启,就会引起所有的主从节点之间的全量复制,造成非常大的性能开销;可以采用多台机器,分散部署主节点,或者使用自动故障转移来将某个从节点变为主节点实现一个高可用
感谢支持,感谢观看。
参考:https://my.oschina.net/ProgramerLife/blog/2254321

 浙公网安备 33010602011771号
浙公网安备 33010602011771号