我是如何利用Hadoop做大规模日志压缩的
背景
刚毕业那几年有幸进入了当时非常热门的某社交网站,在数据平台部从事大数据开发相关的工作。从日志收集、存储、数据仓库建设、数据统计、数据展示都接触了一遍,比较早的赶上了大数据热这波浪潮。虽然今天的人工智能的热度要远高于大数据,但是大家还是不能否定大数据在人工智能中不可取代的地位。
话回正题,当时遇到了一个需要解决的问题就是如何快速对日志进行压缩。那时一天的日志量大概是3TB左右,共100+种日志,最大的一个日志一天要1TB,最小的日志只有几十M。统计需求大部分是用HIVE完成,HIVE中的表每天建立一个分区,每个分区对应一种日志的压缩文件(有天级和小时级)。
当时日志压缩方式是一个日志一个日志进行压缩,利用crontab进行任务并行,效率非常低。经常出现的情况是到了第二天中午12点钟,前一天的日志还没有压缩完,统计需求就没法用hive去做,报表数据就出不来,给我们的压力很大。
也许有小伙伴说,hive可以利用前一天不经过压缩的日志进行统计,后台慢慢进行日志压缩,压缩完成后在重新load一下分区不就ok了吗?这个方案确实可行。但是当时的实际情况是,有好多的表load的都是压缩后的数据,修改成本比较高(几百张表)。不得已还是得尽量缩短压缩时间,这个问题经过我的一番折腾,终于把日志压缩完成时间提前到凌晨1点钟之前,各种报表数据的统计可以在早晨八点钟之前完成。接下来我就把详细做法介绍给大家。
Hadoop并行压缩
压缩格式
首先我们就要讨论压缩格式,我们选择的压缩格式是bz2,原因是bz2算法支持分片压缩合并:即每个小bz2文件头尾相连拼接到一起就是一个大的bz2文件。map/reduce也支持对bz2文件的分块:即利用多个map同时对压缩文件的不同部分进行处理。当时也试过gzip算法,但是gzip没法分片,hive生成的任务只会有一个map,统计效率低下。
压缩方案
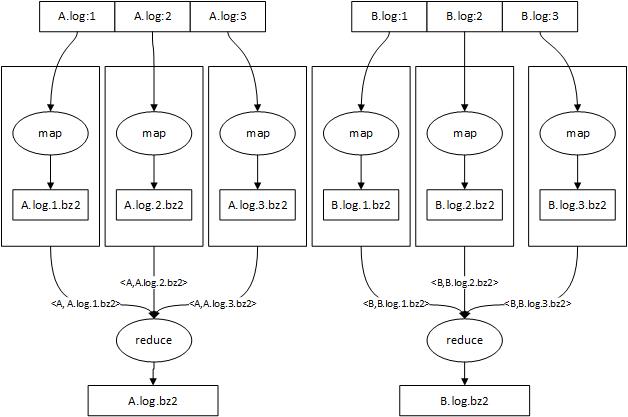
如图所示,有两个日志文件A.log和B.log需要压缩,利用map/reduce并行处理这两个日志。假设map/reduce自动为A.log和B.log分别生成3个map任务同时进行压缩,每个map任务读取日志文件的一部分并用bz2算法进行压缩后写入到集群的HDFS中。A.log通过map端压缩生成了3个压缩文件:A.log.1.bz2,A.log.2.bz2,A.log.3.bz2,之后map通过k-v对把<源文件名称,压缩文件名称>发送给reduce,这样相同日志就会分配到同一个reduce上。reduce做的事情很简单,首先根据压缩文件编号从小到大排序,然后从hadoop上读取压缩文件并merge到一起,最后在HDFS上生成一个新的压缩文件。
注:这里每个日志分成1,2,3三个块是为了描述方便,实际上使用的是map处理文件块时文件的偏移量。
存在的问题
- reduce性能瓶颈 这么做之后reduce就成为性能瓶颈了,因为一个日志最终都交给一个reduce进行合并,还是比较慢。解决方案是压缩前的日志不能按天存放,需要按小时存放,这样大日志可以分批次压缩合并到天级别的压缩文件中。由于我们只是保证在第二天及时产生前一天的压缩文件,我们在前一天就可以对已存在的部分日志进行分批压缩,而只在每天零点对前一天最后面几个小时的日志进行压缩合并,缩短延迟。当时我采用每6个小时压缩一次,这样一天的日志分四次压缩完成,每天凌晨只对前一天最后6小时日志压缩,延迟保证在一小时之内。
- 集群流量风暴 这个方案会大量的从HDFS上读写数据,非常容易造成集群流量风暴,导致集群上其它计算任务失败。解决方案是每次读写一定大小的数据后sleep几秒。
- map端读数据优化 我们知道map/reduce默认是按行读取数据并处理,这对于我们来说效率很低。比如一个大的日志可能有几亿条日志,那么就要调用map几亿次,而我们的map只对数据进行压缩,不要求按行传递,最好的方式是按块。解决方案是重写RecordReader类,实现自己的读数据方案。
- 如何让一个Reduce只merge一种日志 如果只按文件名进行reduce路由,就会出现有两种日志都分配到一个reduce上merge的情况。因为选择reduce的时候,默认行为是根据key计算哈希值后对reduce数取模得到编号,这样就有可能两个不同的key的哈希值是相同的。如果两个日志都分配到同一个reduce上,那么排在后面的日志必须等前面的日志merge完之后才能merge,效率不高。解决方案是:设置reduce数为日志种类数,覆写Partitioner类,把日志种类与reduce编号一一对应,这样就能达到所有日志不用排队同时merge的效果。
具体实现
在这里把需要实现的代码简要的列出来,这里面以java版本为例。
- FileInputFormat类:必须自己写一个类继承该类,覆写其createRecordReader方法。这个方法是一个工厂方法,告诉map/reduce需要一个什么样的RecordReader,RecordReader就是map读取数据所用到的类。
-
public class CompressMergeInputFormat extends FileInputFormat<FileAndPos, ByteBuffer> { @Override public RecordReader<FileAndPos, ByteBuffer> createRecordReader( InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { return new CompressMergeRecordReader(); } /** * 由于数据量较大,默认以8个blockSize作为一个Split分配给一个map。hadoop默认一个blockSize是64M,当日志量太大时会产生很多小压缩文件。 * */ @Override protected long computeSplitSize(long blockSize, long minSize, long maxSize) { return 8 * blockSize; } }
- RecordReader<KEY, VALUE>类:必须自己写一个类继承该类,该类是一个模板类,模板参数分别由Key和Value类型指定,实际上是kv对。map/reduce默认key是当前读取数据在文件中的偏移量,value是内容。我们必须覆写其initialize,nextKeyValue,getCurrentKey,getCurrentValue方法,并且实现KEY和VALUE。
-
public class CompressMergeRecordReader extends RecordReader<FileAndPos, ByteBuffer> { private Path file; private long pos; private long readed = 0; private long length; private FileSystem fs; private FSDataInputStream in; private Configuration config = null; private FileAndPos currentKey = new FileAndPos(); private ByteBuffer currentValue = new ByteBuffer(); @Override public void initialize(InputSplit split, TaskAttemptContext context){ FileSplit filesplit = (FileSplit) split; file = filesplit.getPath(); //获取文件路径 pos = filesplit.getStart(); //获取split块偏移,每个split都会被map压缩成1个单独的文件 length = filesplit.getLength(); currentKey.setFile(file.toString()); currentKey.setPos(pos); config = context.getConfiguration(); fs = file.getFileSystem(context.getConfiguration()); in = fs.open(file); in.seek(pos); } @Override public boolean nextKeyValue(){ //读取下一个k-v if (readed >= length) { return false; } int once = in.read(currentValue.buffer); currentValue.length = once; if (once == -1) { return false; } if(readed + once > length){ //如果大于本文件块则要少读一些 currentValue.length = (int)(length - readed); readed = length; } else { readed += once; }
return true; } @Override public FileAndPos getCurrentKey() throws IOException, InterruptedException { return currentKey; } @Override public ByteBuffer getCurrentValue() throws IOException, InterruptedException { return currentValue; } //... 其它省略
} - 实现KEY:必须是一个Writable对象,实现readFields和write和compareTo方法。我们的key中记录文件路径以及当前数据偏移量。
-
public class FileAndPos implements WritableComparable<FileAndPos> { private String file; private long pos; @Override public void write(DataOutput out) throws IOException { out.writeUTF(file); out.writeLong(pos); } @Override public void readFields(DataInput in) throws IOException { file = in.readUTF(); pos = in.readLong(); } @Override public int compareTo(FileAndPos o) { //需要自己实现比较函数,map会把读到的一批key-value安装这个顺序排序 int filecompare = file.compareTo(o.file); if (filecompare == 0) { if (pos < o.pos) { return -1; } else if (pos > o.pos) { return 1; } else { return 0; } } else { return filecompare; } } //... 省略 }
- 实现VALUE:可以实现成一个固定大小的数组(1M),代表调用一次map函数传递多少数据。
-
public class ByteBuffer { public byte[] buffer = new byte[1024 * 1024]; public int length = 0; }
- 实现Partitioner:当map完成时,在map的cleanup函数中向reduce发送一条kv。Partioner的默认行为是对key计算hash值,根据hash值对reduce数取模得到reduce编号。但是由于我们的key带有文件路径以及偏移信息,直接使用hadoop默认行为会把本应分到同一个reduce上的kv对分配到多个reduce上,造成多个reduce同时写一个文件的问题,所以我们必须重写Partitioner类,对同一个日志的kv对产生固定的reduce编号,这样达到所有种类日志同时merge,并且每个reduce只merge一种日志,不存在一个日志分配到多个reduce上的效果。
-
public class CompressMergePartitioner extends Partitioner<Text, Text> { @Override public int getPartition(Text key, Text value, int numPartitions) { String str = key.toString(); //查表得到日志对应的reduce编号,需要提前做好这张表 return reduceIndex; } }
- 实现OutputFormat 由于我们的reduce是自己写文件,必须阻止reduce自己的默认行为(把value写入一个part_xxx文件),需要覆写OutputFormat类,使其不产生任何输出文件
-
public class CompressMergeOutputFormat<K, V> extends OutputFormat<K, V> { @Override public RecordWriter<K, V> getRecordWriter(TaskAttemptContext context) { return new RecordWriter<K, V>() { public void write(K key, V value) { //啥都不做 } public void close(TaskAttemptContext context) { } }; } //...其它代码忽略
- map实现
-
public class CompressMergeMap extends Mapper<FileAndPos, ByteBuffer, Text, Text> { //...省略 private CompressionOutputStream out; @Override protected void setup(Context context) throws IOException, InterruptedException { String buf = null; Configuration conf = context.getConfiguration(); long pos = ((FileSplit) context.getInputSplit()).getStart(); String path = ((FileSplit) context.getInputSplit()).getPath().toString(); //....省略 } @Override protected void cleanup(Context context) throws IOException, InterruptedException { //根据path和pos生成你的key-value,key中包含日志名以及偏移量,value是这个Split的压缩文件路径 context.write(key,value); } @Override protected void map( FileAndPos key, ByteBuffer value, org.apache.hadoop.mapreduce.Mapper<FileAndPos, ByteBuffer, Text, Text>.Context context) throws IOException, InterruptedException { out.write(value.buffer, 0, value.length); delta += value.length; if(delta >= 5 * 1024 * 1024){ //写5M休息一会 Thread.sleep(10); delta = 0; } } }
- reduce实现
-
public class CompressMergeReduce extends Reducer<Text, Text, NullWritable, NullWritable> { private FileSystem fs; //...省略 @Override protected void reduce( Text key, java.lang.Iterable<Text> values, org.apache.hadoop.mapreduce.Reducer<Text, Text, NullWritable, NullWritable>.Context context) throws IOException, InterruptedException { //根据key中的offset排序,然后merge到最终的bz2文件中 } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号