阿里出品Excel工具EasyExcel使用小结
阿里出品Excel工具EasyExcel使用小结
前提
笔者做小数据和零号提数工具人已经有一段时间,服务的对象是运营和商务的大佬,一般要求导出的数据是Excel文件,考虑到初创团队机器资源十分有限的前提下,选用了阿里出品的Excel工具EasyExcel。这里简单分享一下EasyExcel的使用心得。EasyExcel从其依赖树来看是对apache-poi的封装,笔者从开始接触Excel处理就选用了EasyExcel,避免了广泛流传的apache-poi导致的内存泄漏问题。
引入EasyExcel依赖
引入EasyExcel的Maven如下:
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>${easyexcel.version}</version>
</dependency>2020-09-08)的最新版本为2.2.6。API简介
Excel文件主要围绕读和写操作进行处理,EasyExcel的API也是围绕这两个方面进行设计。先看读操作的相关API:
// 新建一个ExcelReaderBuilder实例 ExcelReaderBuilder readerBuilder = EasyExcel.read(); // 读取的文件对象,可以是File、路径(字符串)或者InputStream实例 readerBuilder.file(""); // 文件的密码 readerBuilder.password(""); // 指定sheet,可以是数字序号sheetNo或者字符串sheetName,若不指定则会读取所有的sheet readerBuilder.sheet(""); // 是否自动关闭输入流 readerBuilder.autoCloseStream(true); // Excel文件格式,包括ExcelTypeEnum.XLSX和ExcelTypeEnum.XLS readerBuilder.excelType(ExcelTypeEnum.XLSX); // 指定文件的标题行,可以是Class对象(结合@ExcelProperty注解使用),或者List<List<String>>实例 readerBuilder.head(Collections.singletonList(Collections.singletonList("head"))); // 注册读取事件的监听器,默认的数据类型为Map<Integer,String>,第一列的元素的下标从0开始 readerBuilder.registerReadListener(new AnalysisEventListener() { @Override public void invokeHeadMap(Map headMap, AnalysisContext context) { // 这里会回调标题行,文件内容的首行会认为是标题行 } @Override public void invoke(Object o, AnalysisContext analysisContext) { // 这里会回调每行的数据 } @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { } }); // 构建读取器 ExcelReader excelReader = readerBuilder.build(); // 读取数据 excelReader.readAll(); excelReader.finish();
Builder模式和事件监听(或者可以理解为观察者模式)的设计。一般情况下,上面的代码可以简化如下:Map<Integer, String> head = new HashMap<>(); List<Map<Integer, String>> data = new LinkedList<>(); EasyExcel.read("文件的绝对路径").sheet() .registerReadListener(new AnalysisEventListener<Map<Integer, String>>() { @Override public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) { head.putAll(headMap); } @Override public void invoke(Map<Integer, String> row, AnalysisContext analysisContext) { data.add(row); } @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { // 这里可以打印日志告知所有行读取完毕 } }).doRead();
Class,结合注解@ExcelProperty使用:文件内容: |订单编号|手机号| |ORDER_ID_1|112222| |ORDER_ID_2|334455| @Data private static class OrderDTO { @ExcelProperty(value = "订单编号") private String orderId; @ExcelProperty(value = "手机号") private String phone; } Map<Integer, String> head = new HashMap<>(); List<OrderDTO> data = new LinkedList<>(); EasyExcel.read("文件的绝对路径").head(OrderDTO.class).sheet() .registerReadListener(new AnalysisEventListener<OrderDTO>() { @Override public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) { head.putAll(headMap); } @Override public void invoke(OrderDTO row, AnalysisContext analysisContext) { data.add(row); } @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { // 这里可以打印日志告知所有行读取完毕 } }).doRead();
如果数据量巨大,建议使用Map<Integer, String>类型读取和操作数据对象,否则大量的反射操作会使读取数据的耗时大大增加,极端情况下,例如属性多的时候反射操作的耗时有可能比读取和遍历的时间长。
接着看写操作的API:
// 新建一个ExcelWriterBuilder实例 ExcelWriterBuilder writerBuilder = EasyExcel.write(); // 输出的文件对象,可以是File、路径(字符串)或者OutputStream实例 writerBuilder.file(""); // 指定sheet,可以是数字序号sheetNo或者字符串sheetName,可以不设置,由下面提到的WriteSheet覆盖 writerBuilder.sheet(""); // 文件的密码 writerBuilder.password(""); // Excel文件格式,包括ExcelTypeEnum.XLSX和ExcelTypeEnum.XLS writerBuilder.excelType(ExcelTypeEnum.XLSX); // 是否自动关闭输出流 writerBuilder.autoCloseStream(true); // 指定文件的标题行,可以是Class对象(结合@ExcelProperty注解使用),或者List<List<String>>实例 writerBuilder.head(Collections.singletonList(Collections.singletonList("head"))); // 构建ExcelWriter实例 ExcelWriter excelWriter = writerBuilder.build(); List<List<String>> data = new ArrayList<>(); // 构建输出的sheet WriteSheet writeSheet = new WriteSheet(); writeSheet.setSheetName("target"); excelWriter.write(data, writeSheet); // 这一步一定要调用,否则输出的文件有可能不完整 excelWriter.finish();
ExcelWriterBuilder中还有很多样式、行处理器、转换器设置等方法,笔者觉得不常用,这里不做举例,内容的样式通常在输出文件之后再次加工会更加容易操作。写操作一般可以简化如下:List<List<String>> head = new ArrayList<>(); List<List<String>> data = new LinkedList<>(); EasyExcel.write("输出文件绝对路径") .head(head) .excelType(ExcelTypeEnum.XLSX) .sheet("target") .doWrite(data);
实用技巧
下面简单介绍一下生产中用到的实用技巧。
多线程读
使用EasyExcel多线程读建议在限定的前提条件下使用:
- 源文件已经被分割成多个小文件,并且每个小文件的标题行和列数一致。
- 机器内存要充足,因为并发读取的结果最后需要合并成一个大的结果集,全部数据存放在内存中。
经常遇到外部反馈的多份文件需要紧急进行数据分析或者交叉校对,为了加快文件读取,笔者通常使用这种方式批量读取格式一致的Excel文件
一个简单的例子如下:
@Slf4j public class EasyExcelConcurrentRead { static final int N_CPU = Runtime.getRuntime().availableProcessors(); public static void main(String[] args) throws Exception { // 假设I盘的temp目录下有一堆同格式的Excel文件 String dir = "I:\\temp"; List<Map<Integer, String>> mergeResult = Lists.newLinkedList(); ThreadPoolExecutor executor = new ThreadPoolExecutor(N_CPU, N_CPU * 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(), new ThreadFactory() { private final AtomicInteger counter = new AtomicInteger(); @Override public Thread newThread(@NotNull Runnable r) { Thread thread = new Thread(r); thread.setDaemon(true); thread.setName("ExcelReadWorker-" + counter.getAndIncrement()); return thread; } }); Path dirPath = Paths.get(dir); if (Files.isDirectory(dirPath)) { List<Future<List<Map<Integer, String>>>> futures = Files.list(dirPath) .map(path -> path.toAbsolutePath().toString()) .filter(absolutePath -> absolutePath.endsWith(".xls") || absolutePath.endsWith(".xlsx")) .map(absolutePath -> executor.submit(new ReadTask(absolutePath))) .collect(Collectors.toList()); for (Future<List<Map<Integer, String>>> future : futures) { mergeResult.addAll(future.get()); } } log.info("读取[{}]目录下的文件成功,一共加载:{}行数据", dir, mergeResult.size()); // 其他业务逻辑..... } @RequiredArgsConstructor private static class ReadTask implements Callable<List<Map<Integer, String>>> { private final String location; @Override public List<Map<Integer, String>> call() throws Exception { List<Map<Integer, String>> data = Lists.newLinkedList(); EasyExcel.read(location).sheet() .registerReadListener(new AnalysisEventListener<Map<Integer, String>>() { @Override public void invoke(Map<Integer, String> row, AnalysisContext analysisContext) { data.add(row); } @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { log.info("读取路径[{}]文件成功,一共[{}]行", location, data.size()); } }).doRead(); return data; } } }
这里采用ThreadPoolExecutor#submit()提交并发读的任务,然后使用Future#get()等待所有任务完成之后再合并最终的读取结果。
注意,一般文件的写操作不能并发执行,否则很大的概率会导致数据错乱
多Sheet写
多Sheet写,其实就是使用同一个ExcelWriter实例,写入多个WriteSheet实例中,每个Sheet的标题行可以通过WriteSheet实例中的配置属性进行覆盖,代码如下:
public class EasyExcelMultiSheetWrite { public static void main(String[] args) throws Exception { ExcelWriterBuilder writerBuilder = EasyExcel.write(); writerBuilder.excelType(ExcelTypeEnum.XLSX); writerBuilder.autoCloseStream(true); writerBuilder.file("I:\\temp\\temp.xlsx"); ExcelWriter excelWriter = writerBuilder.build(); WriteSheet firstSheet = new WriteSheet(); firstSheet.setSheetName("first"); firstSheet.setHead(Collections.singletonList(Collections.singletonList("第一个Sheet的Head"))); // 写入第一个命名为first的Sheet excelWriter.write(Collections.singletonList(Collections.singletonList("第一个Sheet的数据")), firstSheet); WriteSheet secondSheet = new WriteSheet(); secondSheet.setSheetName("second"); secondSheet.setHead(Collections.singletonList(Collections.singletonList("第二个Sheet的Head"))); // 写入第二个命名为second的Sheet excelWriter.write(Collections.singletonList(Collections.singletonList("第二个Sheet的数据")), secondSheet); excelWriter.finish(); } }

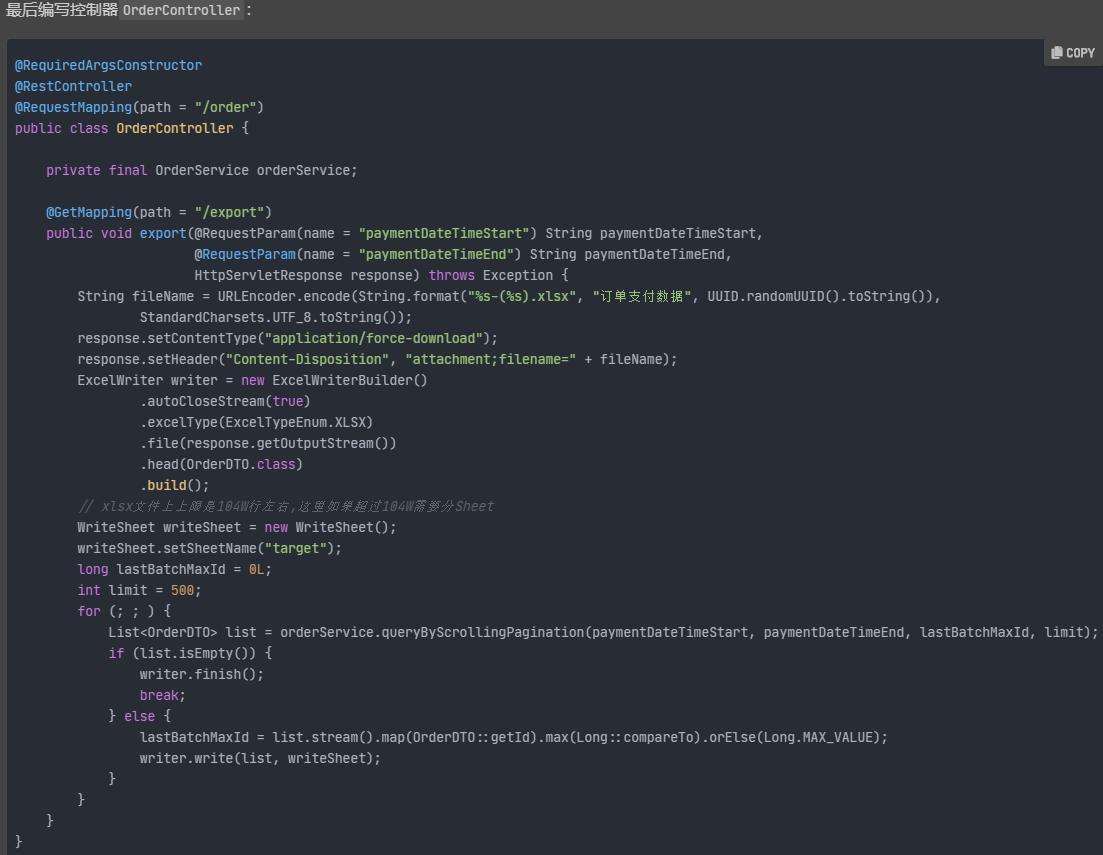
分页查询和批量写
在一些数据量比较大的场景下,可以考虑分页查询和批量写,其实就是分页查询原始数据 -> 数据聚合或者转换 -> 写目标数据 -> 下一页查询....。其实数据量少的情况下,一次性全量查询和全量写也只是分页查询和批量写的一个特例,因此可以把查询、转换和写操作抽象成一个可复用的模板方法:
int batchSize = 定义每篇查询的条数; OutputStream outputStream = 定义写到何处; ExcelWriter writer = new ExcelWriterBuilder() .autoCloseStream(true) .file(outputStream) .excelType(ExcelTypeEnum.XLSX) .head(ExcelModel.class); for (;;){ List<OriginModel> list = originModelRepository.分页查询(); if (list.isEmpty()){ writer.finish(); break; }else { list 转换-> List<ExcelModel> excelModelList; writer.write(excelModelList); } }
Excel上传与下载
下面的例子适用于Servlet容器,常见的如Tomcat,应用于spring-boot-starter-web
Excel文件上传跟普通文件上传的操作差不多,然后使用EasyExcel的ExcelReader读取请求对象MultipartHttpServletRequest中文件部分抽象的InputStream实例即可:
@PostMapping(path = "/upload") public ResponseEntity<?> upload(MultipartHttpServletRequest request) throws Exception { Map<String, MultipartFile> fileMap = request.getFileMap(); for (Map.Entry<String, MultipartFile> part : fileMap.entrySet()) { InputStream inputStream = part.getValue().getInputStream(); Map<Integer, String> head = new HashMap<>(); List<Map<Integer, String>> data = new LinkedList<>(); EasyExcel.read(inputStream).sheet() .registerReadListener(new AnalysisEventListener<Map<Integer, String>>() { @Override public void invokeHeadMap(Map<Integer, String> headMap, AnalysisContext context) { head.putAll(headMap); } @Override public void invoke(Map<Integer, String> row, AnalysisContext analysisContext) { data.add(row); } @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { log.info("读取文件[{}]成功,一共:{}行......", part.getKey(), data.size()); } }).doRead(); // 其他业务逻辑 } return ResponseEntity.ok("success"); }
Postman请求如下: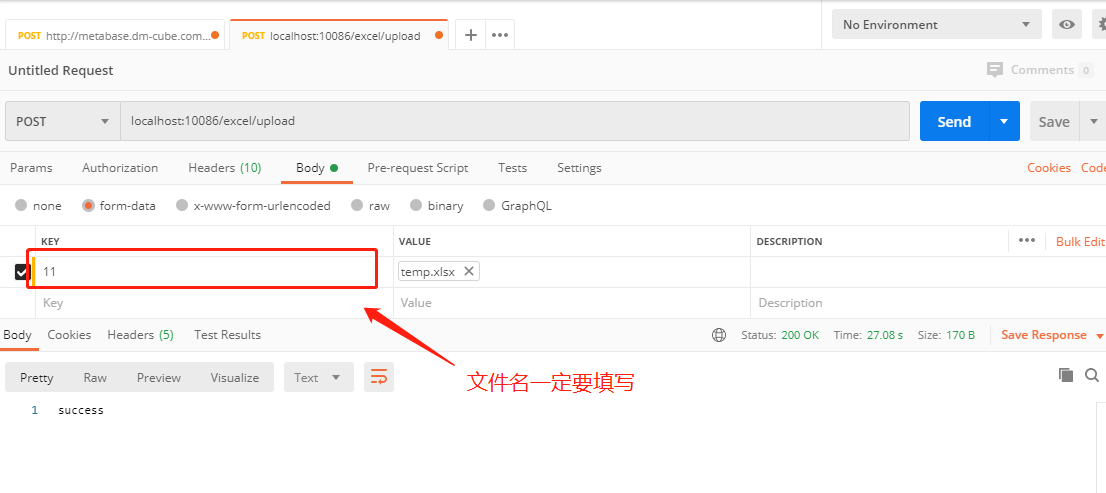
使用EasyExcel进行Excel文件导出也比较简单,只需要把响应对象HttpServletResponse中携带的OutputStream对象附着到EasyExcel的ExcelWriter实例即可:
@GetMapping(path = "/download") public void download(HttpServletResponse response) throws Exception { // 这里文件名如果涉及中文一定要使用URL编码,否则会乱码 String fileName = URLEncoder.encode("文件名.xlsx", StandardCharsets.UTF_8.toString()); // 封装标题行 List<List<String>> head = new ArrayList<>(); // 封装数据 List<List<String>> data = new LinkedList<>(); response.setContentType("application/force-download"); response.setHeader("Content-Disposition", "attachment;filename=" + fileName); EasyExcel.write(response.getOutputStream()) .head(head) .autoCloseStream(true) .excelType(ExcelTypeEnum.XLSX) .sheet("Sheet名字") .doWrite(data); }
这里需要注意一下:
- 文件名如果包含中文,需要进行
URL编码,否则一定会乱码。 - 无论导入或者导出,如果数据量大比较耗时,使用了
Nginx的话记得调整Nginx中的连接、读写超时时间的上限配置。 - 使用
SpringBoot需要调整spring.servlet.multipart.max-request-size和spring.servlet.multipart.max-file-size的配置值,避免上传的文件过大出现异常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号