第十一章 图论 Part8
单源最短路径算法
dijkstra(朴素版)
适用范围(权值不能为负数的单源最短路径)
思路
基本类似Prim算法,只是新加入(确定)点的时候,当前算法算的是距离源点的最短路径,而Prim算法算的是距离最小生成树的最短路径。
minValVec 记录当前每个点到源点的最短路径(随着遍历的过程而更新)
每次并入的步骤:
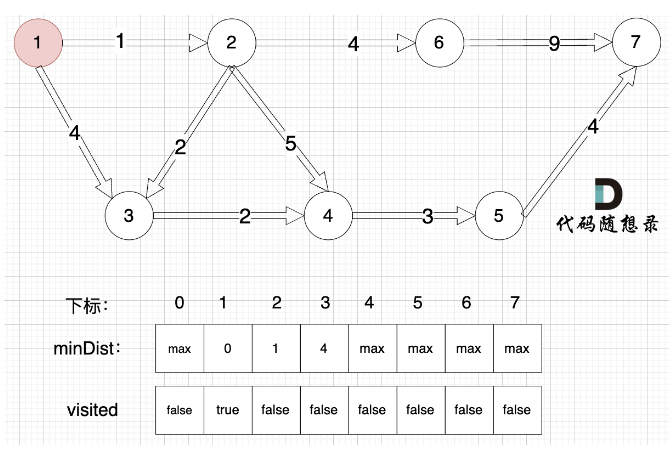
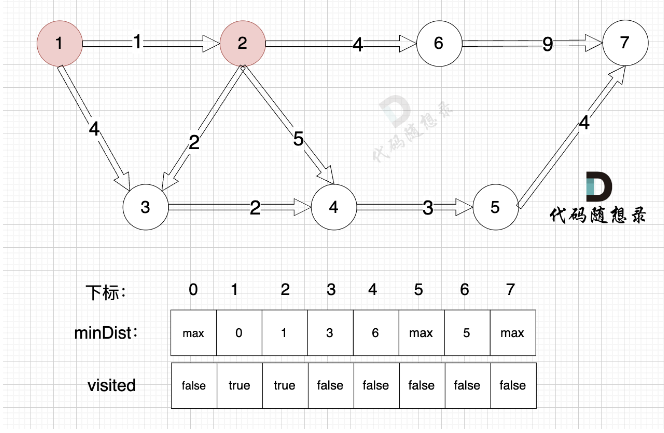
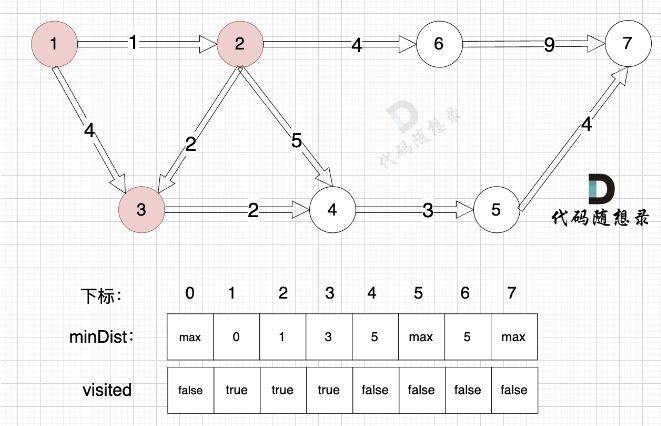
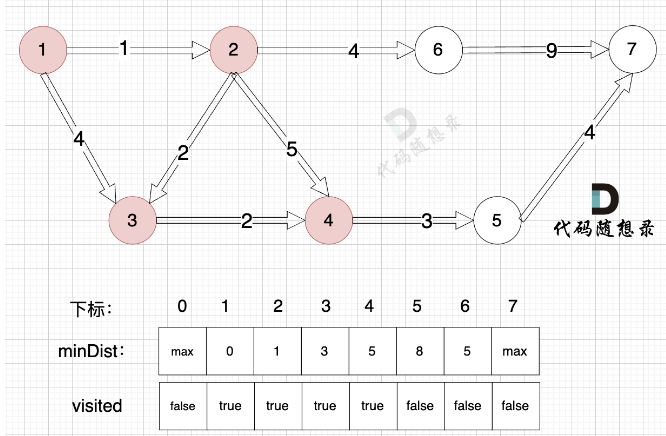
- 确定选哪个节点并入 (不在已访问节点中,距离源点最小的节点) 遍历每个点,得到最小距离的那个点及最小距离。 (顶点编号)
- 将第一步选到的点加入到visited中,用一个bool列表记录已经访问的点。
- 更新未访问的节点到源点的距离。 (与cur相连的j节点距离源点的距离,比cur加入之前j节点到源点的距离小) =》 因为cur变成访问过的节点后,其他节点需要更新距离这个最新形成的与源点的距离) =》 观察4这个节点随着各个节点的加入,距离源点的最短路径的变化;以及最终作为被选取的点和确认该点最短路径的过程。
如果想记录这个最短路径的边,则使用parent数组(元素值表示使当前节点更新的前一个节点),在第三步更新时记录即可,如果后续节点的加入还会使该点更新,则parent数组实际也会更新。
v,e = map(int,input().split()) # 顶点数,边数 graph = [[float('inf')]* (v+1) for _ in range(v+1)] #邻接矩阵 for _ in range(e): x,y,k = map(int,input().split()) #有向图 graph[x][y] = k visited = [False]* (v+1) #是否访问过 minValVec = [float('inf')]* (v+1) #所有点的最小距离列表,初始化每个距离为inf minValVec[1] = 0 #源点到自己的距离为0 for i in range(1,v+1): # 确认每个点的最短距离 #1. 确认新加入的点的编号(谁距离源点最近就加谁) cur = -1 minDist = float('inf') #最大的权值 for j in range(1,v+1): #遍历所有还未访问点,确认要新加入的点的编号 if not visited[j] and minValVec[j] < minDist: minDist = minValVec[j] #更新最小距离,以便在后续迭代中继续比较 cur = j #更新新加入的点的编号,当循环退出时,确定新加入的点的编号 if cur == -1: #未找到最小距离的点,说明剩下的点和已经访问的点不连通,退出循环 break #2.记录新加入的点 visited[cur] = True #3.因为路径中有了新加入的点,更新每个未确定的点到源点的最小距离 for j in range(1,v+1): if (not visited[j] and graph[cur][j] != float('inf') and minValVec[cur] + graph[cur][j] < minValVec[j]):#某点到源点的距离可能由于新加入了点而改变 minValVec[j] = minValVec[cur] + graph[cur][j] minValVec[v] = -1 if minValVec[v] == float('inf') else minValVec[v] print(minValVec[v])
算法正确性
那么这个算法为什么就能确定是最短路径呢?实际上按照算法的步骤解释,我们每次选择距离某点的相邻节点时,都是选择最短的(距离源点),假设值为x,而其他的路径非最短,假设值为y1,y2...,那么绕路的话,假设绕路的边的长度为z1,z2...,由于x < y1,y2... 所以x < y1+ z1,y2+z2.(由于算法的适用范围,权值必须非负,所以这里的x,y,z均大于等于0).. ,就更不可能作为最短路径的选取。简单的说,就是每次选距离源点最短的保证了没有其他方式可以使得这个距离更短。
这也是权值必须非负的原因。反例如下:
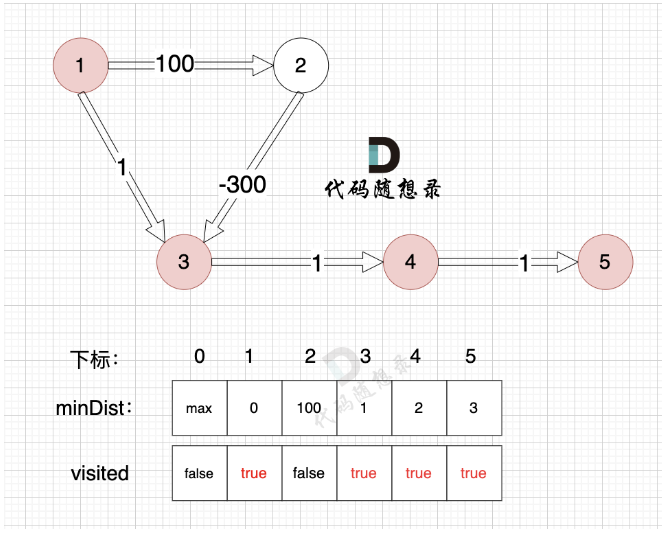
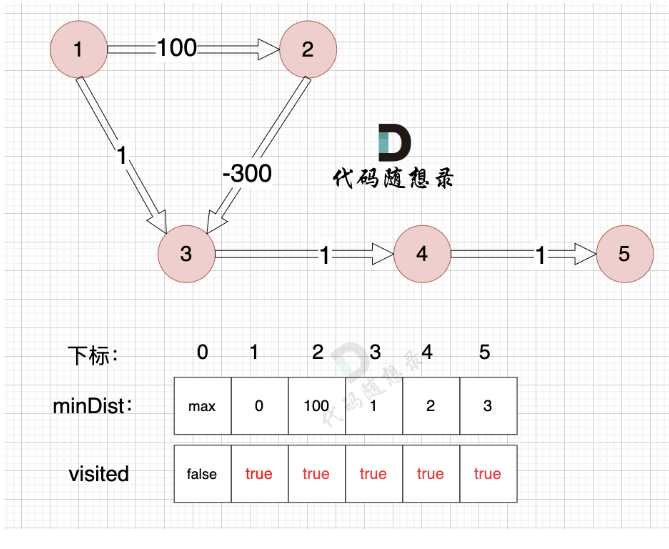
相当于先走一个长路,然后绕路比直接走反而可以使到源点最短路径更短,所以该算法要求权值非负。
dijkstra堆优化版
思路
之前的dijkstra算法的时间复杂度为o(v^2),v为顶点个数。当图为稀疏图(边多节点少)时,这种方法就不是很合适(空间上用的是邻接矩阵和时间上用普通版的dijkstra算法)。因此,当稀疏图时,尝试使用优先级队列(点,点到源点的距离)来考虑问题,并且将存储图的数据结构改为用邻接矩阵。
总体思路和传统dijkstra算法相同,让我们回顾下传统方法:
对于每个节点,并入到已访问(确认到源点最短路径):
- 确定选哪个节点并入 (不在已访问节点中,距离源点最小的节点) 遍历每个点,得到最小距离的那个点及最小距离。 (顶点编号)
- 将第一步选到的点加入到visited中,用一个bool列表记录已经访问的点。
- 更新未访问的节点到源点的距离。 (与cur相连的j节点距离源点的距离,比cur加入之前j节点到源点的距离小) =》 因为cur变成访问过的节点后,其他节点需要更新距离这个最新形成的与源点的距离) =》 观察4这个节点随着各个节点的加入,距离源点的最短路径的变化;以及最终作为被选取的点和确认该点最短路径的过程。
对于稀疏图,总体思路是和流程是一致的,只是以邻接表和优先级队列进行这个流程:
进行并入前的初始化工作:引入优先级队列pq,其中存的是pair<节点,源点到该节点的权值>,初始化队列,源点到源点的距离为0,所以初始为0
节点并入过程:
- 从优先级队列弹出一条权值最小的节点,这个边的to节点就是待并入的节点。如果已经访问过,则跳过。
- 将第一步中的节点加入到visited中
- 更新未访问节点到源点的距离,遍历所有与并入节点的相邻边的点,判断条件与传统版相同,若发生更新,除了更新最短距离数组外,pq中加入新节点。
模拟后会发现,这个优先级队列对于同样的节点可能会多次加入,但是同样节点之前访问过,冗余的加入会被跳过。如下图举例的流程:
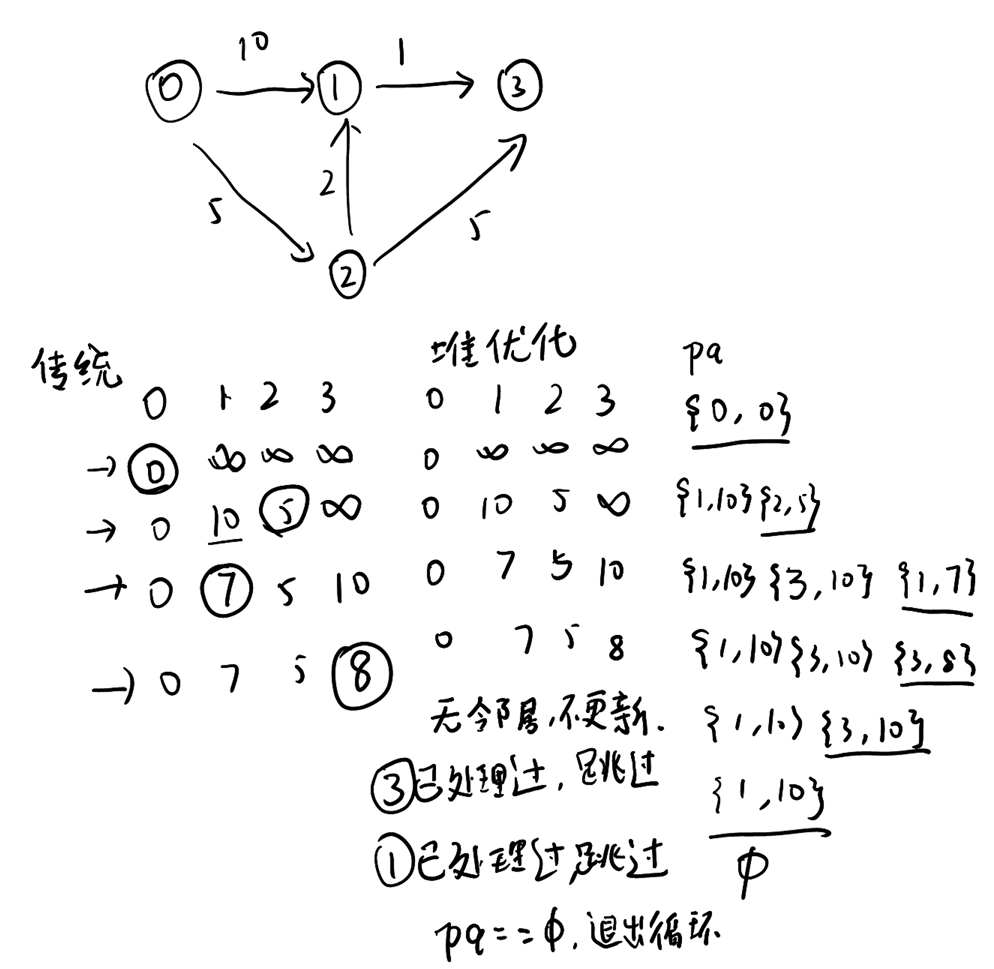
重点是为什么每次从堆中取出的就一定是那个节点的最短路径(到源点的),证明如下:
假设 d[u] 不是最短路径。假设存在另一个路径,它的长度是 d'[u] < d[u]。但是,由于我们每次从优先队列中取出的都是当前最小距离的节点,所以如果存在 d'[u] < d[u],那么 u 应该早就被取出来处理了,这和它当前才被取出来的事实矛盾。因此,d[u] 就是从起点到 u 的最短路径。
通过上面的图和分析可以发现,Dijkstra算法无论是传统版本还是堆优化版本,实际的思路都是一种贪心的思路,即每次选离源点最近的点一步步向外扩充确定的点,直到达到终点。
def dijkstra(self, source): # 初始化最短距离数组和优先队列 dist = [float('inf')] * self.V dist[source] = 0 priority_queue = [(0, source)] # (距离, 节点) while priority_queue: current_dist, current_vertex = heapq.heappop(priority_queue) # 跳过已经找到更短路径的节点 if current_dist > dist[current_vertex]: continue # 更新邻居的距离 for neighbor, weight in self.adj[current_vertex]: distance = current_dist + weight if distance < dist[neighbor]: dist[neighbor] = distance heapq.heappush(priority_queue, (distance, neighbor))
Bellman_ford算法
适用范围(可以处理负权边,甚至可以检测负权环。如果图中存在从某个节点出发的负权环,Bellman-Ford 能够检测到。)
思路
算法流程:
- 初始化设置源节点的距离为 0,其他所有节点的距离为无穷大。
- 一共处理v-1次(点数),每次对边做松弛操作:对于每一条边,检查是否可以通过当前边来更新目标节点的距离。重复这一过程 V−1
- 再次遍历所有边,如果还可以更新某个节点的距离,则说明图中存在负权环。
与dijkstra算法相似的地方,更新条件的写法。
与dijkstra算法不同的地方,Bellman_ford算法的适用范围更广,写法上,没有visited的限制(不是每次确认一个点),而是通过松弛v-1次数的边来达到更新最短路径的目的。
def bellman_ford(self, source): # 初始化距离数组 dist = [float('inf')] * self.V dist[source] = 0 # 松弛边的过程 for _ in range(self.V - 1): for u, v, weight in self.edges: if dist[u] != float('inf') and dist[u] + weight < dist[v]: dist[v] = dist[u] + weight # 检测负权环 for u, v, weight in self.edges: if dist[u] != float('inf') and dist[u] + weight < dist[v]: print("Graph contains negative weight cycle") return
SPFA算法(对Bellman_ford算法的优化)
思路
SPFA算法是针对Bellman算法的优化,对于每一轮“松弛”,SPFA算法只去松弛那些可能会更新的边(通过队列记录),而不像Bellman算法去处理所有边,达到优化的目的。
from collections import deque def spfa(self, source): # 初始化距离数组 dist = [float('inf')] * self.V dist[source] = 0 # 队列来存储待更新的节点 queue = deque([source]) in_queue = [False] * self.V # 记录节点是否在队列中 in_queue[source] = True # 松弛边的过程 while queue: u = queue.popleft() in_queue[u] = False # 遍历与u相邻的边 for v, weight in self.adj[u]: if dist[u] + weight < dist[v]: dist[v] = dist[u] + weight # 如果v不在队列中,加入队列 if not in_queue[v]: queue.append(v) in_queue[v] = True # 检测负权环 for u in range(self.V): for v, weight in self.adj[u]: if dist[u] + weight < dist[v]: print("Graph contains negative weight cycle") return return dist
A*算法(对二维网格中bfs和dijkstra算法的优化)
思路
bfs是采取的一圈一圈向外层遍历的方式,每次找到一步的节点(确认一圈节点(第一步能到达,第二步能到达...第n步能到达)),因此能找到最短路径,适合无权图(相当于每个格子的距离是1步)。
dijkstra算法采取的是贪心的算法,每次确定一个点到源点的最短路径,每次确定点的依据是离起点最近的点。适合有权图。
而对于A*,算法,是一种启发式算法,就是将前面算法的确认每个点的依据改成点的总成本F,F = G + H。
- 其中G为从 起点 到当前节点 n 的 实际代价。它是已知的,表示已经走过的路径长度或消耗的代价。
- H为从当前节点 n 到 目标节点 的 估计代价(启发式函数)。它是一个预估值,表示从当前节点走到目标节点的代价。常见的启发式函数右欧几里得距离(如果图中的路径是可以沿任意方向移动的(例如二维平面中的移动))和曼哈顿距离(用于只能沿水平方向和垂直方向移动的情况)。
以下两段代码片段分别为dijkstra和bfs加入启发式函数后,改为A算法,展示了A算法的过程:
def heuristic(self, u, target): # Euclidean distance between node u and the target (x1, y1) = self.positions[u] (x2, y2) = self.positions[target] return math.sqrt((x2 - x1)**2 + (y2 - y1)**2) def astar(self, source, target): # Initialize the distances and priority queue dist = [float('inf')] * self.V dist[source] = 0 priority_queue = [(0 + self.heuristic(source, target), source)] # (F, node) while priority_queue: current_f, current_vertex = heapq.heappop(priority_queue) # If we reached the target, return the distance if current_vertex == target: return dist[target] # Update neighbors for neighbor, weight in self.adj[current_vertex]: distance = dist[current_vertex] + weight if distance < dist[neighbor]: dist[neighbor] = distance f = distance + self.heuristic(neighbor, target) heapq.heappush(priority_queue, (f, neighbor)) # If the target is unreachable return float('inf')
import heapq import math # 表示四个方向 dirs = [(0, 1), (1, 0), (-1, 0), (0, -1)] def heuristic(x1, y1, x2, y2): # 使用曼哈顿距离作为启发式函数 return abs(x1 - x2) + abs(y1 - y2) def astar(grid, start, goal): rows, cols = len(grid), len(grid[0]) # 初始化 open_set = [] heapq.heappush(open_set, (0 + heuristic(start[0], start[1], goal[0], goal[1]), start)) # (F, (x, y)) came_from = {} # 记录路径 g_score = { (x, y): float('inf') for x in range(rows) for y in range(cols) } # 从起点到每个节点的代价 g_score[start] = 0 f_score = { (x, y): float('inf') for x in range(rows) for y in range(cols) } # 估计的总代价 f_score[start] = heuristic(start[0], start[1], goal[0], goal[1]) while open_set: # 从优先队列中取出 F 值最小的节点 _, current = heapq.heappop(open_set) current_x, current_y = current # 如果到达目标节点 if current == goal: path = [] while current in came_from: path.append(current) current = came_from[current] path.append(start) path.reverse() return path # 遍历邻居节点 for dx, dy in dirs: next_x, next_y = current_x + dx, current_y + dy if 0 <= next_x < rows and 0 <= next_y < cols and grid[next_x][next_y] != 1: # 确保在网格范围内且不是障碍物 tentative_g_score = g_score[(current_x, current_y)] + 1 # 假设每步代价为 1 if tentative_g_score < g_score[(next_x, next_y)]: came_from[(next_x, next_y)] = (current_x, current_y) g_score[(next_x, next_y)] = tentative_g_score f_score[(next_x, next_y)] = tentative_g_score + heuristic(next_x, next_y, goal[0], goal[1]) if (next_x, next_y) not in [i[1] for i in open_set]: heapq.heappush(open_set, (f_score[(next_x, next_y)], (next_x, next_y))) return None # 如果没有找到路径
多源最短路径算法
Floyd算法
思路
dp思路,求dp[1][4]的最短距离,相当于 求 dp[1][x] 的最短距离 + dp[x][4]的最短距离 x在合法范围内
那么确认实际的dp的意义及递推公式:dp意义为 dp[i][j][k]表示 从i到j的最短路径,经过[1,k]这个区间内的任意节点中转
递推公式逻辑:
- 当路径经过k点时,dp[i][j][k] = dp[i][k][k-1] + dp[k][j][k-1]
- 当路径步经过k点时,dp[i][j][k] = dp[i][j][k-1]
因此,递推公式为dp[i][j][k] = min(dp[i][k][k-1] + dp[k][j][k-1],dp[i][j][k-1])
抽象成三维空间,i,j相当于向前和向右轴,构成一个平面,k相当于向上的轴,那么问题转化为求解其中一个点的值dp[i][j][k],顺序为从k=0的平面开始向上求解。
注意初始化即k为0的时候,即不使用任何中间顶点的情况下,i到j的最短距离,直接初始化为graph[i][j]
# Floyd-Warshall Algorithm in Python with 3D dp array INF = float('inf') def floyd_warshall(graph): n = len(graph) # Initialize 3D dp array: dp[i][j][k] represents the shortest distance from i to j using the first k vertices dp = [[[INF] * (n + 1) for _ in range(n)] for _ in range(n)] # Initialize dp[i][j][0] to the direct distance between i and j from the graph (without any intermediate nodes) for i in range(n): for j in range(n): dp[i][j][0] = graph[i][j] # Main Floyd-Warshall logic for k in range(1, n + 1): # considering the first k vertices as intermediates for i in range(n): # for every starting vertex i for j in range(n): # for every destination vertex j # Update dp[i][j][k] by considering whether vertex k-1 should be used as an intermediate dp[i][j][k] = min(dp[i][j][k-1], dp[i][k-1][k-1] + dp[k-1][j][k-1]) # Final result is in dp[i][j][n], which considers all vertices as intermediates return [[dp[i][j][n] for j in range(n)] for i in range(n)]
拓扑排序
拓扑排序是经典的图论问题。
先说说 拓扑排序的应用场景。
大学排课,例如 先上A课,才能上B课,上了B课才能上C课,上了A课才能上D课,等等一系列这样的依赖顺序。 问给规划出一条 完整的上课顺序。
拓扑排序在文件处理上也有应用,我们在做项目安装文件包的时候,经常发现 复杂的文件依赖关系, A依赖B,B依赖C,B依赖D,C依赖E 等等。
思路
找到当前入度为0的点(当前入度为0的节点是由zerolist来记录的),加入到结果集,删除它对原图的影响(更新它影响节点的入度,即它的出边连接的点的入度减1),继续这一过程,直到zerolist中没有节点,此时结束,res中记录的即是拓扑排序的过程,表示找完或者没有入度为0的点(有环)。
v,e = map(int,input().split()) # 顶点数,边数 graph = [[float('inf')]* (v+1) for _ in range(v+1)] #邻接矩阵 inDegree = [0] * v #剩余入度(随着选取的进行会更新) for _ in range(e): x,y = map(int,input().split()) #有向图 graph[x][y] = 1 inDegree[y] += 1 from collections import deque #剩余入度为0的点(用deque是为了删除头部时复杂度o(1) zeroList = deque() for i in range(len(inDegree)): if inDegree[i] == 0: zeroList.append(i) #拓扑排序的结果放入res res = [] while(len(zeroList) > 0): cur = zeroList.popleft() res.append(cur) #更新该点影响的点的入度,若修改后入度为0,则加入到zero列表中 for i in range(v): if graph[cur][i] == 1: inDegree[i] -= 1 if inDegree[i] == 0: zeroList.append(i) #print(res) if len(res) != v: print('-1') else: print(' '.join(map(str,res)))
心得
图的算法中,特别是最近几节的最小生成树,单源最短路径,多源最短路径以及拓扑排序,从算法和模拟上是相对可以理解以及模拟出流程(比如手写),但是由于编码上需要一些技巧,编码的逻辑并没有那么容易(包含算法的流程和图的各种输入格式,以及需要引入哪些数据结构来帮助算法的完成),需要熟悉算法流程并多多练习。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律