
随机森林集成Adaboosting算法与Python实现(二)
AdaBoost是Freund和Schapire于1996年提出的一种集成学习方法。它的核心思想是通过迭代训练一系列弱分类器,每次调整样本权重以便更好地拟合被前一轮分类器错误分类的样本,从而构建一个强分类器。最终的模型是基于这些弱分类器的加权组合。AdaBoost广泛应用于二分类和多分类问题,尤其在图像识别、人脸检测、然语言处理、金融风控、生物信息学等领域取得了很好的效果。Boosting算法相对于其他机器学习算法的优点在于:集成了多个弱分类器,能够有效减少过拟合的风险,提高模型的泛化能力;相对于单个分类器,集成分类器更加健壮,具有更高的鲁棒性,可以在一定程度上抵抗数据集中的噪声和异常点。需要注意的是,Boosting算法通常需要耗费较长的时间进行训练,而且对于不平衡的数据集,可能会出现分类器在某些类别上表现较差的情况,因此在实际应用中需要结合具体问题进行算法选择和参数调优。
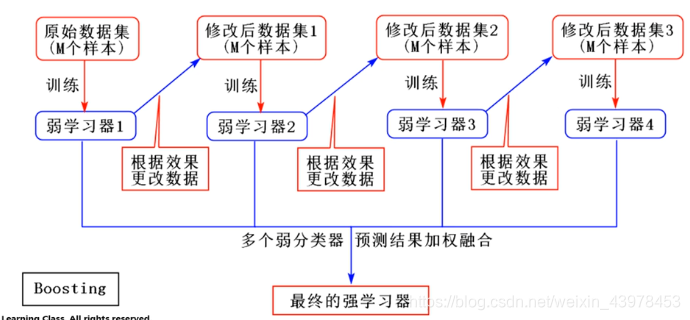
一、基于原生Python实现随机森林
AdaBoost(Adaptive Boosting)是一种经典的集成学习算法,其思想是将多个弱分类器(weak classifier)组合成一个强分类器(strong classifier),以提高分类性能。它是由 Yoav Freund 和 Robert Schapire 在1996年提出的。AdaBoost算法的基本思想是针对一个训练数据集,使用不同的分类算法(如决策树、神经网络、支持向量机等)构建一系列弱分类器,然后通过加权组合这些弱分类器,形成一个强分类器。
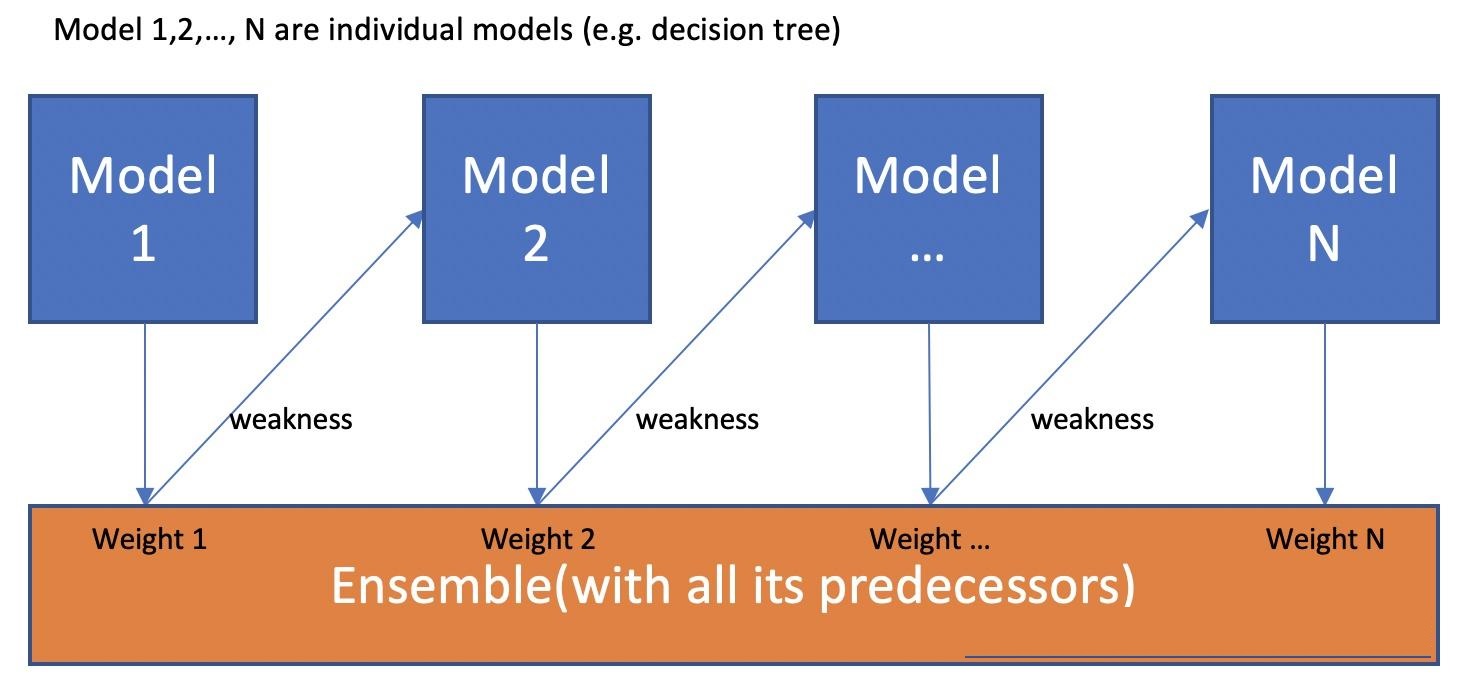
二、Boosting算法思想
Boosting算法的本质是将弱学习器提升为强学习器,它和Bagging的区别在于,Bagging对待所有的基础模型一视同仁。而Boosting则做到了对于基础模型的“区别对待”,通俗来讲,Boosting算法注重“培养精英”和“重视错误”。“培养精英”,即每一轮对于预测结果较为准确的基础模型,会给予它一个较大的权重,表现不好的基础模型则会降低它的权重。这样在最终预测时,“优秀模型”的权重是大的,相当于它可以投出多票,而“一般模型”只能在投票时投出一票或不能投票。“重视错误”,即在每一轮训练后改变训练数据的权值或概率分布,通过提高那些在前一轮被基础模型预测错误样例的权值,减小前一轮预测正确样例的权值,来使得分类器对误分的数据有较高的重视程度,从而提升模型的整体效果。
Boosting是一种集成学习方法,它的基本思想是通过对多个弱学习器(弱分类器)的集成来构建一个强学习器(强分类器)。它通过反复迭代训练弱分类器,将多个弱分类器进行加权组合,得到一个具有较高性能的强分类器。Boosting算法的核心在于样本的权重调整。在每一轮迭代中,Boosting算法会将上一轮分类错误的样本赋予更高的权重,使得这些样本在下一轮迭代中更加容易被正确分类。同时,它会通过加权求和的方式将多个弱分类器组合成一个强分类器,使得这个强分类器具有更好的泛化性能。Boosting算法有多种变种,如 AdaBoost、Gradient Boosting、XGBoost 等,它们在样本权重调整、损失函数设计等方面有所不同,但是它们的核心思想都是一致的:通过对多个弱分类器的集成,构建一个性能更好的强分类器。
2.1 Boosting算法原理
Boosting的思想是将关注点放在被错误分类的样本上,减小上一轮被正确分类的样本权值,提高被错误分类的样本权值;Boosting采用加权投票的方法,分类误差小的弱分类器的权重大,而分类误差大的弱分类器的权重小。假设输入训练数据为:
其中: ,迭代次数即弱分类器个数为 ,基学习器。
- 初始化训练样本的权值分布为:
- 对于
(a) 使用具有权值分布 的训练数据集进行学习, 得到弱分类器
(b) 计算 在训练数据集上的分类误差率:
(c) 计算 在强分类器中所占的比重:
(d)更新训练器的权值分布,这里(是归一化因子,为了使得样本和的概率分布等于1):
- 得到最终的分类器为:
AdaBoost的损失函数是指数损失, 则有:
| 图1 | 图2 | 图3 |
|---|---|---|
 |
 |
 |
2.2 Adaboosting方法分解计算
AdaBoost(自适应Boosting)是一种流行的集成学习算法,它通过组合多个弱分类器来构建一个强分类器。在AdaBoost算法中,初始分类器的选择可以有多种方式,以下是一些常见的方法:
决策树桩(Decision Stumps):这是最简单的分类器,通常是一个单层的决策树,只考虑单个特征的一个分割点。它们计算成本低廉,易于训练,常作为AdaBoost的初始分类器。
感知机(Perceptrons):这是一种线性分类器,可以用于二分类问题。感知机易于实现和训练,也可以作为AdaBoost的基分类器。
朴素贝叶斯分类器(Naive Bayes Classifiers):在特征条件独立假设下,朴素贝叶斯分类器对于某些问题非常有效,可以作为基分类器。
k最近邻分类器(k-Nearest Neighbors, k-NN):k-NN分类器根据一个对象的k个最近邻居,通过投票的方式来预测该对象的类别。
支持向量机(Support Vector Machines, SVM):尽管SVM通常被认为是较为复杂的分类器,但在某些情况下,它们的简化版本也可以用作AdaBoost的基分类器。
随机弱分类器(Random Weak Classifiers):在某些实现中,可以随机选择一个简单的分类规则作为初始分类器。
其他任何分类器:理论上,任何分类器都可以作为AdaBoost的基分类器,只要它能提供一个概率或加权的输出。
在AdaBoost中,基分类器的选择取决于数据集的特性和问题的需求。通常,决策树桩因其简单性和效率而被广泛使用。然而,实验不同的基分类器可能会得到更好的性能。AdaBoost算法的关键在于它的迭代过程,它通过调整每个基分类器的权重和数据点的权重来提高整体性能。每个基分类器都在前一个的基础上改进,专注于前一个分类器分错的样本。这个过程使得即使是弱分类器,也能通过Boosting过程组合成一个强分类器。
决策树桩(Decision Stumps)是决策树的一种简化形式,它只包含一个内部节点(决策节点)和两个或多个叶节点(结果节点)。在二元分类问题中,决策树桩通常基于单个特征来做出决策。假设我们有一组数据,包含两个特征 X1 和 X2,以及一个二分类的目标变量 Y,其中正类用 1 表示,负类用 0 表示。数据集如下:
| 样本编号 | X1(年龄) | X2(收入) | Y(类别) |
|---|---|---|---|
| 1 | 30 | 50000 | 1 |
| 2 | 25 | 45000 | 0 |
| 3 | 40 | 60000 | 1 |
| 4 | 35 | 55000 | 1 |
| 5 | 20 | 40000 | 0 |
现在,我们使用决策树桩来构建一个分类器。我们选择 X1(年龄)作为决策特征,并选择一个阈值(比如 X1 的中位数)来分割数据。假设中位数是 33,那么我们的决策树桩规则可能是:
如果 X1 > 33,则预测 Y = 1(正类)
如果 X1 <= 33,则预测 Y = 0(负类)
根据这个规则,我们可以对每个样本进行分类:
样本 1(30岁):预测为 Y = 0(因为 30 <= 33)
样本 2(25岁):预测为 Y = 0(因为 25 <= 33)
样本 3(40岁):预测为 Y = 1(因为 40 > 33)
...
这个简单的决策树桩可以作为AdaBoost算法中的一个基分类器。在实际应用中,我们通常会考虑所有可能的特征和所有可能的阈值,选择误差最小的规则作为当前的决策树桩。在Python中,我们可以使用 sklearn.tree.DecisionTreeClassifier 并将 max_depth 设置为 1 来创建一个决策树桩。
from sklearn.tree import DecisionTreeClassifier
# 假设 df 是包含数据集的 pandas DataFrame
X = df[['X1', 'X2']] # 特征
y = df['Y'] # 目标变量
# 创建一个决策树桩
tree_stump = DecisionTreeClassifier(max_depth=1, random_state=0)
# 训练决策树桩
tree_stump.fit(X, y)
这个决策树桩将基于训练数据学习一个简单的决策规则。
例:考虑如下表所示的训练样本,弱分类器采用平行于坐标轴的直线,用Adaboost算法的实现强分类过程。
| 样本序号 | 样本点X | 类别 Y |
|---|---|---|
| 1 | (1,5) | 1 |
| 2 | (2,2) | 1 |
| 3 | (3,1) | 1 |
| 4 | (4,6) | 1 |
| 5 | (6,8) | 1 |
| 6 | (6,5) | -1 |
| 7 | (7,9) | 1 |
| 8 | (8,7) | 1 |
| 9 | (9,8) | -1 |
| 10 | (10,2) | -1 |
将这10个样本作为训练数据,根据 X1与X2的对应关系,可把这10个数据分为两类,图中用“+”表示类别1,用“O”表示类别-1。本例使用水平或者垂直的直线作为分类器。
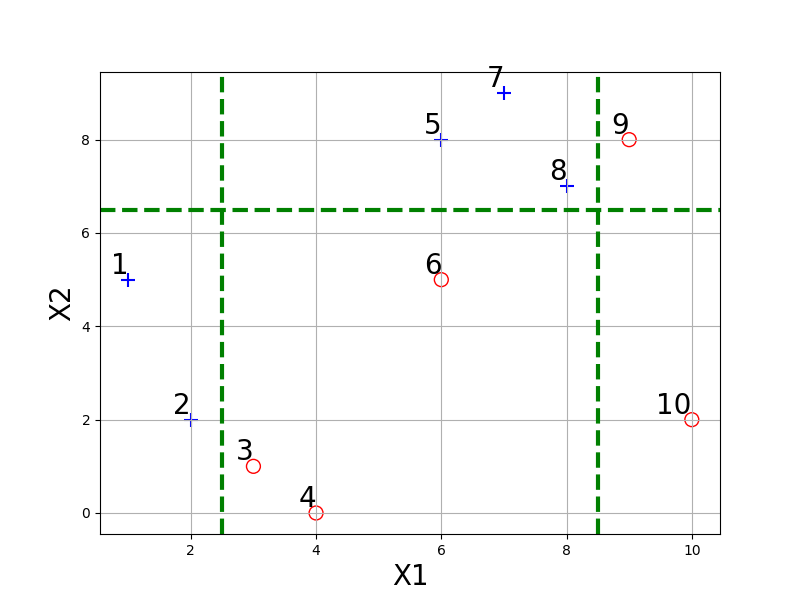
import matplotlib.pyplot as plt
# 样本点X和类别Y的数据
X = [(1 ,5), (2 ,2), (3 ,1), (4 ,0), (6 ,8), (6 ,5), (7 ,9), (8 ,7), (9 ,8), (10 ,2)]
Y = [1, 1, -1, -1, 1, -1, 1, 1, -1, -1]
# 样本序号
sample_numbers = range(1, len(X) + 1)
# 创建散点图
plt.figure(figsize=(8, 6))
# 根据类别Y的值,使用不同的标记和颜色,并放大点的大小
for i, (x_coord, y_coord) in enumerate(X):
color = 'blue' if Y[i] == 1 else 'red'
marker = '+' if Y[i] == 1 else 'o' # 正类使用 '+' 标记,负类使用 'o' 标记
# 为负类样本设置空心标记
if Y[i] == -1:
plt.scatter(x_coord, y_coord, color=color, marker=marker, s=100, facecolors='none', label=f'Y={Y[i]}')
else:
plt.scatter(x_coord, y_coord, color=color, marker=marker, s=100, label=f'Y={Y[i]}')
plt.text(x_coord, y_coord, str(sample_numbers[i]), fontsize=20, ha='right', va='bottom') # 添加样本序号,放大字体大小
# 添加X轴和Y轴的标签
plt.xlabel('X1', fontsize=20)
plt.ylabel('X2', fontsize=20)
# 添加一条 X=2.5 的绿色粗点划线
plt.axvline(x=2.5, color='green', linestyle='--', linewidth=3)
# 添加一条 X=8.5 的绿色粗点划线
plt.axvline(x=8.5, color='green', linestyle='--', linewidth=3)
# 添加一条 Y=6.5 的绿色粗点划线
plt.axhline(y=6.5, color='green', linestyle='--', linewidth=3)
# 显示图表
plt.grid(True)
plt.show()
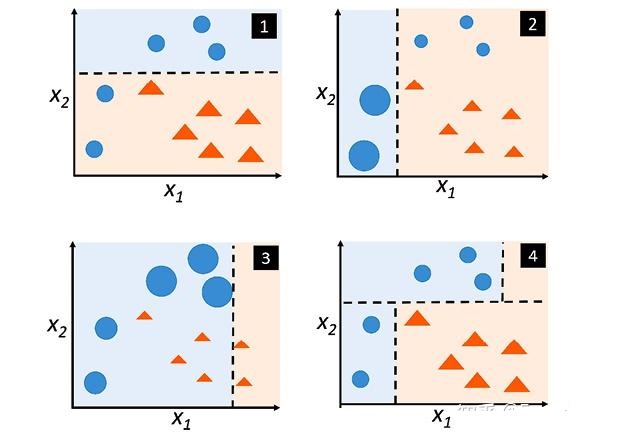
图中已经给出了三个弱分类器(图只作为样例,并非三个分类器真实的分类结果),即
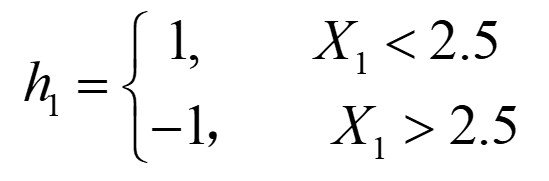 |
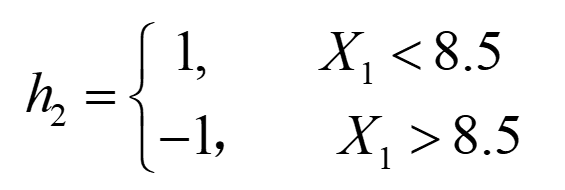 |
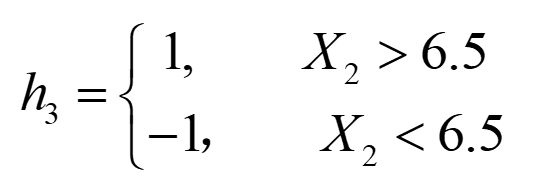 |
首先需要初始化训练样本数据的权值分布,每一个训练样本最开始时都被赋予相同的权值:,这样训练样本集的初始权值分布:令每个权值,其中,然后分别对于等值进行迭代(表示迭代次数,表示第轮),下表已经给出训练样本的权值分布情况:
| 样本序号 | 样本点X | 类别 Y | 权值分布 |
|---|---|---|---|
| 1 | (1,5) | 1 | 0.1 |
| 2 | (2,2) | 1 | 0.1 |
| 3 | (3,1) | 1 | 0.1 |
| 4 | (4,6) | 1 | 0.1 |
| 5 | (6,8) | 1 | 0.1 |
| 6 | (6,5) | -1 | 0.1 |
| 7 | (7,9) | 1 | 0.1 |
| 8 | (8,7) | 1 | 0.1 |
| 9 | (9,8) | -1 | 0.1 |
| 10 | (10,2) | -1 | 0.1 |
第1次迭代:在权值分布的情况下,取已知的三个弱分类器中误差率最小的分类器作为第1个基本分类器(三个弱分类器的误差率都是0.3(即分错样本的权重之和,见图1),那就取第1个吧),即公式()
- 在分类器情况下,样本点“5 7 8”被错分(见图2),因此基本分类器的误差率为:=0.1+0.1+0.1=0.3;
- 根据公式计算,得弱分类器的权重值(即这个代表的分类器在最终的分类函数中所占比重为0.4236):,可见,被误分类样本的权值之和影响误差率,误差率影响基本分类器在最终分类器中所占的权重;
- 根据公式更新训练样本数据的权值分布,用于下一轮迭代
(a)对于正确分类的训练样本“1 2 3 4 6 9 10”(共7个)的权值更新为:显然分类正确的样本权重降低了
(b)对于错误分类的训练样本“5 7 8”(共3个)的权值更新为:显然分类错误的样本权重升高了
(c)第1轮迭代后,最后得到各个样本数据新的权值分布:,由于样本数据“5 7 8”被分错了,所以它们的权值由之前的0.1增大到1/6;反之,其它数据皆被分正确,所以它们的权值皆由之前的0.1减小到1/14,下表给出了权值分布的变换情况:
| 样本序号 | 样本点X | 类别 Y | 权值分布 | 权值分布 | sign() |
|---|---|---|---|---|---|
| 1 | (1,5) | 1 | 0.1 | 1/14 | 1 |
| 2 | (2,2) | 1 | 0.1 | 1/14 | 1 |
| 3 | (3,1) | -1 | 0.1 | 1/14 | -1 |
| 4 | (4,0) | -1 | 0.1 | 1/14 | -1 |
| 5 | (6,8) | 1 | 0.1 | 1/6 | -1 |
| 6 | (6,5) | -1 | 0.1 | 1/14 | -1 |
| 7 | (7,9) | 1 | 0.1 | 1/6 | -1 |
| 8 | (8,7) | 1 | 0.1 | 1/14 | 1 |
| 9 | (9,8) | -1 | 0.1 | 1/14 | -1 |
| 10 | (10,2) | -1 | 0.1 | 1/14 | -1 |
可得分类函数:。此时,组合一个基本分类器作为强分类器在训练数据集上有3个误分类点(即5 7 8),此时强分类器的训练错误为:0.3。
| 图1 | 图2 |
|---|---|
 |
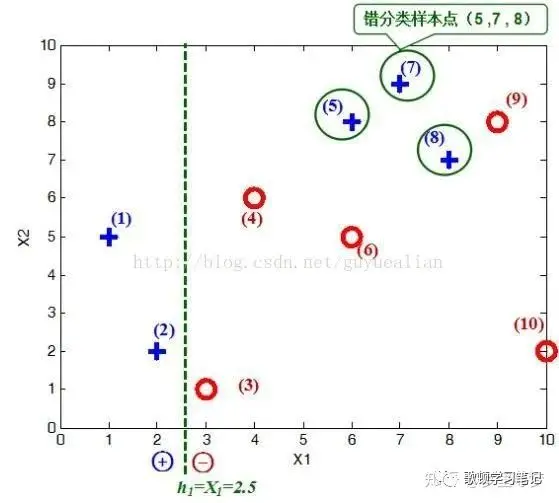 |
第二次迭代=2:
- 在权值分布的情况下,再取三个弱分类器h1、h2和h3中误差率最小的分类器作为第2个基本分类器:
① 当取弱分类器=X1=2.5时,此时被错分的样本点为“5 7 8”:
误差率e=1/6+1/6+1/6=3/6=1/2;
② 当取弱分类器=X1=8.5时,此时被错分的样本点为“3 4 6”:
误差率e=1/14+1/14+1/14=3/14;
③ 当取弱分类器=X2=6.5时,此时被错分的样本点为“1 2 9”:
误差率e=1/14+1/14+1/14=3/14
因此,取当前最小的分类器作为第2个基本分类器; - 把样本“3 4 6”分错了,根据可知它们的权值为=1/14,=1/14,=1/14,所以在训练数据集上的误差率:
根据误差率 计算 的权重:
更新训练样本数据的权值分布,对于正确分类的样本权值更新为:
对于错误分类的权值更新为: - 第2轮迭代后,最后得到各个样本数据新的权值分布:
下表给出了权值分布的变换情况:
| 序号 | 样本点X | 类别 | 权值分布 | 权值分布 | sign() | 权值分布 | sign() |
|---|---|---|---|---|---|---|---|
| 1 | (1,5) | 1 | 0.1 | 1/14 | 1 | 1/22 | 1 |
| 2 | (2,2) | 1 | 0.1 | 1/14 | 1 | 1/22 | 1 |
| 3 | (3,1) | -1 | 0.1 | 1/14 | -1 | 1/6 | 1 |
| 4 | (4,6) | -1 | 0.1 | 1/14 | -1 | 1/6 | 1 |
| 5 | (6,8) | 1 | 0.1 | 1/6 | -1 | 7/66 | 1 |
| 6 | (6,5) | -1 | 0.1 | 1/14 | -1 | 1/6 | 1 |
| 7 | (7,9) | 1 | 0.1 | 1/6 | -1 | 7/66 | 1 |
| 8 | (8,7) | 1 | 0.1 | 1/14 | 1 | 7/66 | 1 |
| 9 | (9,8) | -1 | 0.1 | 1/14 | -1 | 1/22 | -1 |
| 10 | (10,2) | -1 | 0.1 | 1/14 | -1 | 1/22 | -1 |
可得分类函数:。此时,组合两个基本分类器作为强分类器在训练数据集上有3个误分类点(即3 4 6),此时强分类器的训练错误为:0.3。
第三次迭代=3:
- 在权值分布的情况下,再取三个弱分类器中误差率最小的分类器作为第3个基本分类器:
① 当取弱分类器=X1=2.5时,此时被错分的样本点为“5 7 8”:误差率e=7/66+7/66+7/66=7/22;
② 当取弱分类器=X1=8.5时,此时被错分的样本点为“3 4 6”:误差率e=1/6+1/6+1/6=1/2=0.5;
③ 当取弱分类器=X2=6.5时,此时被错分的样本点为“1 2 9”:误差率e=1/22+1/22+1/22=3/22;
取当前最小的分类器作为第3个基本分类器: - 把样本“1 2 9”分错了,根据可知它们的权值为=1/22,=1/22,=1/22,所以在训练数据集上的误差率:
根据误差率 计算 的权重:
更新训练样本数据的权值分布,对于正确分类的样本权值更新为:
对于错误分类的权值更新为: - 第2轮迭代后,最后得到各个样本数据新的权值分布:
下表给出了权值分布的变换情况:
| 序号 | 样本点X | 类别Y | 权值分布 | 权值分布 | sign() | 权值分布 | sign() | 权值分布 | sign() |
|---|---|---|---|---|---|---|---|---|---|
| 1 | (1,5) | 1 | 0.1 | 1/14 | 1 | 1/22 | 1 | 1/6 | 1 |
| 2 | (2,2) | 1 | 0.1 | 1/14 | 1 | 1/22 | 1 | 1/6 | 1 |
| 3 | (3,1) | -1 | 0.1 | 1/14 | -1 | 1/6 | 1 | 11/114 | -1 |
| 4 | (4,6) | -1 | 0.1 | 1/14 | -1 | 1/6 | 1 | 11/114 | -1 |
| 5 | (6,8) | 1 | 0.1 | 1/6 | -1 | 7/66 | 1 | 7/114 | 1 |
| 6 | (6,5) | -1 | 0.1 | 1/14 | -1 | 1/6 | 1 | 11/114 | -1 |
| 7 | (7,9) | 1 | 0.1 | 1/6 | -1 | 7/66 | 1 | 7/114 | 1 |
| 8 | (8,7) | -1 | 0.1 | 1/14 | -1 | 1/22 | 1 | 1/6 | -1 |
| 9 | (9,8) | -1 | 0.1 | 1/14 | -1 | 1/22 | 1 | 1/38 | -1 |
| 10 | (10,2) | -1 | 0.1 | 1/14 | -1 | 1/22 | 1 | 1/6 | -1 |
可得分类函数:。此时,组合三个基本分类器sign()作为强分类器,在训练数据集上有0个误分类点。至此,整个训练过程结束,这个强分类器对训练样本的错误率为0!
三、AdaBoosting算法Python代码
3.1 示例1
import numpy as np
class DecisionStump:
def __init__(self):
self.feature_index = None
self.threshold = None
self.alpha = None
self.prediction = None
def train(self, X, y, weights):
m, n = X.shape
best_error = float('inf')
for feature_index in range(n):
feature_values = np.unique(X[:, feature_index])
for threshold in feature_values:
prediction = np.ones(m)
prediction[X[:, feature_index] < threshold] = -1
error = np.sum(weights[prediction != y])
if error < best_error:
best_error = error
self.feature_index = feature_index
self.threshold = threshold
self.prediction = prediction.copy()
self.alpha = 0.5 * np.log((1 - best_error) / (best_error + 1e-10))
return best_error
def predict(self, X):
prediction = np.ones(X.shape[0])
prediction[X[:, self.feature_index] < self.threshold] = -1
return prediction
class AdaBoost:
def __init__(self, n_estimators=50):
self.n_estimators = n_estimators
self.models = []
self.alphas = []
def train(self, X, y):
m = X.shape[0]
weights = np.ones(m) / m
print("Initial weights:", weights)
for i in range(self.n_estimators):
print("\nIteration", i+ 1)
model = DecisionStump()
error = model.train(X, y, weights)
alpha = model.alpha
predictions = model.predict(X)
incorrect = predictions != y
weights *= np.exp(alpha * incorrect)
weights /= np.sum(weights)
self.models.append(model)
self.alphas.append(alpha)
print("Classifier", i + 1, "weights:", weights)
def predict(self, X):
predictions = np.zeros(X.shape[0])
for model, alpha in zip(self.models, self.alphas):
predictions += alpha * model.predict(X)
return np.sign(predictions)
# 准备数据集
data = np.array([
[0.697, 0.460, 1],
[0.774, 0.376, 1],
[0.634, 0.264, 1],
[0.608, 0.318, 1],
[0.556, 0.215, 1],
[0.403, 0.237, 1],
[0.481, 0.149, 1],
[0.437, 0.211, 1],
[0.666, 0.091, -1],
[0.243, 0.267, -1],
[0.245, 0.057, -1],
[0.343, 0.099, -1],
[0.639, 0.161, -1],
[0.657, 0.198, -1],
[0.360, 0.370, -1],
[0.593, 0.042, -1],
[0.719, 0.103, -1]
])
X = data[:, :-1] # 特征
y = data[:, -1] # 标签
# 训练AdaBoost模型
ada_boost = AdaBoost(n_estimators=10)
ada_boost.train(X, y)
# 测试样本
test_samples = np.array([[0.697, 0.460], [0.243, 0.267], [0.639, 0.161]])
# 预测
predictions = ada_boost.predict(test_samples)
print("\nTest Samples:")
print(test_samples)
print("Original Labels:")
print(y[[1, 9, 12]]) # Original labels for test samples 2, 10, 13
print("Predicted Labels:")
print(predictions) # Predicted labels for test samples 2, 10, 13
3.2 示例2
# 导入所需库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 定义AdaBoost算法类
class AdaBoostClassifier:
def __init__(self, n_estimators=50, learning_rate=1.0):
self.n_estimators = n_estimators # 弱分类器个数
self.learning_rate = learning_rate # 学习率
self.alpha = np.zeros(n_estimators) # 弱分类器权重
self.classifiers = [] # 弱分类器集合
def fit(self, X, y):
n_samples, n_features = X.shape
weights = np.ones(n_samples) / n_samples # 初始化样本权重
for t in range(self.n_estimators):
# 使用权重训练基分类器
classifier = DecisionStump()
classifier.fit(X, y, sample_weight=weights)
# 计算基分类器错误率
y_pred = classifier.predict(X)
err = np.sum(weights * (y_pred != y))
# 计算基分类器权重
alpha_t = 0.5 * np.log((1 - err) / max(err, 1e-10)) # 防止除零错误
self.alpha[t] = alpha_t
# 更新样本权重
weights *= np.exp(-alpha_t * y * y_pred)
weights /= np.sum(weights)
# 保存基分类器
self.classifiers.append(classifier)
def predict(self, X):
# 根据基分类器的加权结果进行预测
y_pred = np.zeros(len(X))
for alpha, classifier in zip(self.alpha, self.classifiers):
y_pred += alpha * classifier.predict(X)
return np.sign(y_pred)
# 计算准确率
def score(self, y_pred, y):
return np.mean(y_pred == y)
# 定义决策树桩类
class DecisionStump:
def __init__(self):
self.feature_idx = None
self.threshold = None
self.polarity = None
def fit(self, X, y, sample_weight=None):
n_samples, n_features = X.shape
if sample_weight is None:
sample_weight = np.ones(n_samples) / n_samples
min_err = float('inf')
for feature_idx in range(n_features):
thresholds = np.unique(X[:, feature_idx])
for threshold in thresholds:
for polarity in [1, -1]:
y_pred = np.ones(n_samples)
y_pred[polarity * X[:, feature_idx] < polarity * threshold] = -1
err = np.sum(sample_weight * (y_pred != y))
if err < min_err:
min_err = err
self.feature_idx = feature_idx
self.threshold = threshold
self.polarity = polarity
def predict(self, X):
n_samples = X.shape[0]
y_pred = np.ones(n_samples)
y_pred[self.polarity * X[:, self.feature_idx] < self.polarity * self.threshold] = -1
return y_pred
# 导入数据
X, y = load_iris(return_X_y=True)
X = X[:, :2] # 只选择两个特征以便可视化
y = (y != 0) * 1 # 将标签转换成二分类
# 划分训练集、测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.15, random_state=42)
# 训练AdaBoost
model = AdaBoostClassifier(n_estimators=10, learning_rate=1)
model.fit(X_train, y_train)
# 打印结果
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
score_train = model.score(y_train_pred, y_train)
score_test = model.score(y_test_pred, y_test)
print('训练集Accuracy: ', score_train)
print('测试集Accuracy: ', score_test)
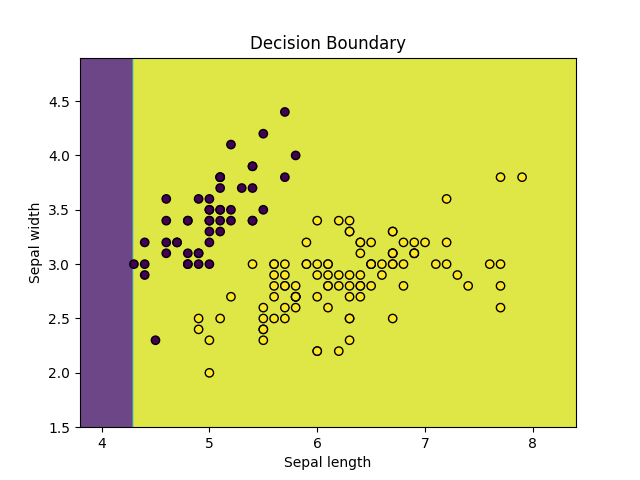
# 可视化决策边界
x1_min, x1_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
x2_min, x2_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, 0.02),
np.arange(x2_min, x2_max, 0.02))
Z = model.predict(np.c_[xx1.ravel(), xx2.ravel()])
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, marker='o', edgecolors='k')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.title('Decision Boundary')
plt.show()
总结
AdaBoost和随机森林都是强大的集成学习算法,它们在不同的场景下展现出各自的优势。AdaBoost通过迭代调整样本权重来提高模型的准确性,适用于中等规模的数据集和简单的分类问题;而随机森林通过构建多棵随机决策树并对它们的结果进行组合来提高模型的泛化能力,适用于处理大规模、高维数据集和复杂的分类和回归问题。在实际应用中,选择合适的算法取决于数据特点、问题复杂度和准确性要求。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2022-05-02 数据挖掘关联分析—R实现
2022-05-02 数据挖掘神经网络—R实现
2022-05-02 数据挖掘决策树—R实现
2022-05-02 数据挖掘系统聚类—R实现