
决策树算法思想及其Python实现
决策树算法是一种在机器学习和数据挖掘领域广泛应用的强大工具,它模拟人类决策过程,通过对数据集进行逐步的分析和判定,最终生成一颗树状结构,每个节点代表一个决策或一个特征。决策树的核心思想是通过一系列问题将数据集划分成不同的类别或值,从而实现对未知数据的预测和分类。这一算法的开发灵感源自人类在解决问题时的思考方式,我们往往通过一系列简单而直观的问题逐步缩小解决方案的范围。决策树的构建过程也是类似的,它通过对数据的特征进行提问,选择最能区分不同类别的特征,逐渐生成树状结构,最终形成一个可用于预测的模型。决策树算法具有很多优势,其中之一是模型的可解释性强,即便对非专业人士来说也较容易理解。此外,决策树对于处理分类和回归问题都表现出色,适用于各种类型的数据。算法的训练和预测速度较快,且对异常值和缺失值相对鲁棒。然而,决策树也存在一些挑战,如容易过拟合、对数据噪声敏感等问题。为了解决这些问题,研究人员提出了许多改进和集成方法,如剪枝技术和随机森林。
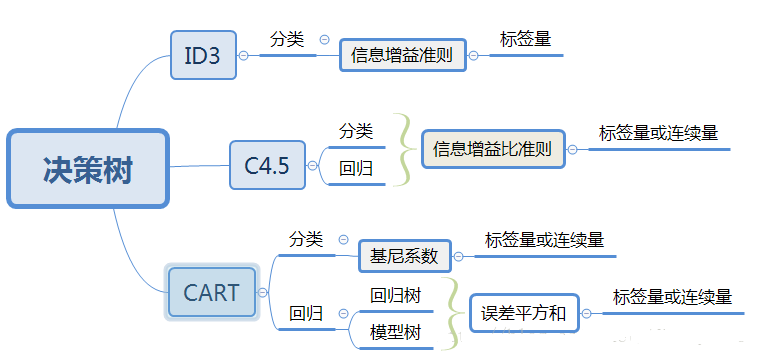
一、决策树算法的发展和思想
1.1 决策树算法发展
决策树算法作为一种基础而强大的机器学习工具,其发展历程与演进思想呈现出丰富多彩的面貌。从早期的基本决策树到如今的集成学习和深度学习技术,决策树算法的发展经历了多个阶段,不断吸收新的理念与方法,以更好地适应不同领域的应用需求。
早期的决策树算法主要集中在ID3(Iterative Dichotomiser 3)和C4.5(Classification and Regression Trees)等基础算法上。ID3由Ross Quinlan于1986年提出,通过递归地将数据集划分成子集,选择具有最大信息增益的特征进行决策。C4.5是ID3的改进版本,引入了信息增益比来解决信息增益在处理多值属性时的偏好问题。这两者为决策树算法的发展奠定了基础。
随着研究的深入,研究者们逐渐认识到信息熵和信息增益等指标在处理连续属性和多分类问题时存在一定的不足。于是,基于基尼指数的决策树算法逐渐兴起。CART(Classification and Regression Trees)算法是基于基尼指数的典型代表,它使用基尼指数来度量数据集的不纯度,通过选择最小化基尼指数的特征进行分裂,以达到更精准的分类和回归。
随着计算能力的提升和数据规模的扩大,集成学习成为决策树算法发展的重要方向之一。随机森林作为集成学习中的代表,通过构建多个决策树并将它们组合,既提高了模型的稳定性,又降低了过拟合的风险。此外,梯度提升树(Gradient Boosting Trees)等算法也逐渐崭露头角,通过迭代地训练弱分类器,不断提升整体模型的性能。近年来,深度学习的兴起对决策树算法产生了深远的影响。神经网络的强大拟合能力和对复杂特征的自动学习使得决策树算法在处理大规模数据和高维特征时更为灵活。深度决策树(Deep Decision Tree)等混合模型的出现,将传统决策树与深度学习相结合,为复杂任务提供了更有力的解决方案。
总体而言,决策树算法的发展历程表现出不断创新与融合的趋势。从最初的基础算法到集成学习和深度学习的兴起,决策树算法在理论和实践中不断演进,为各领域的问题提供了灵活而高效的解决方案。未来,随着人工智能领域的不断拓展,决策树算法有望在更多领域展现其强大的潜力。
| 图1 | 图2 |
|---|---|
 |
 |
1.2 决策树算法思想
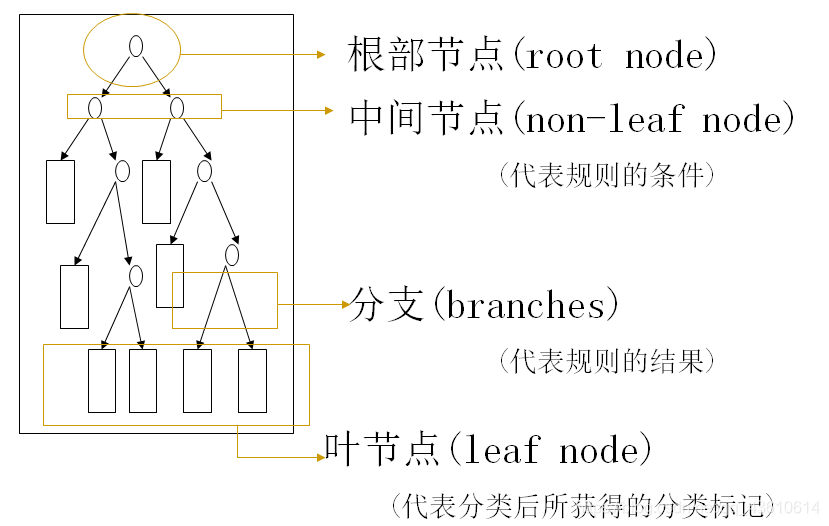
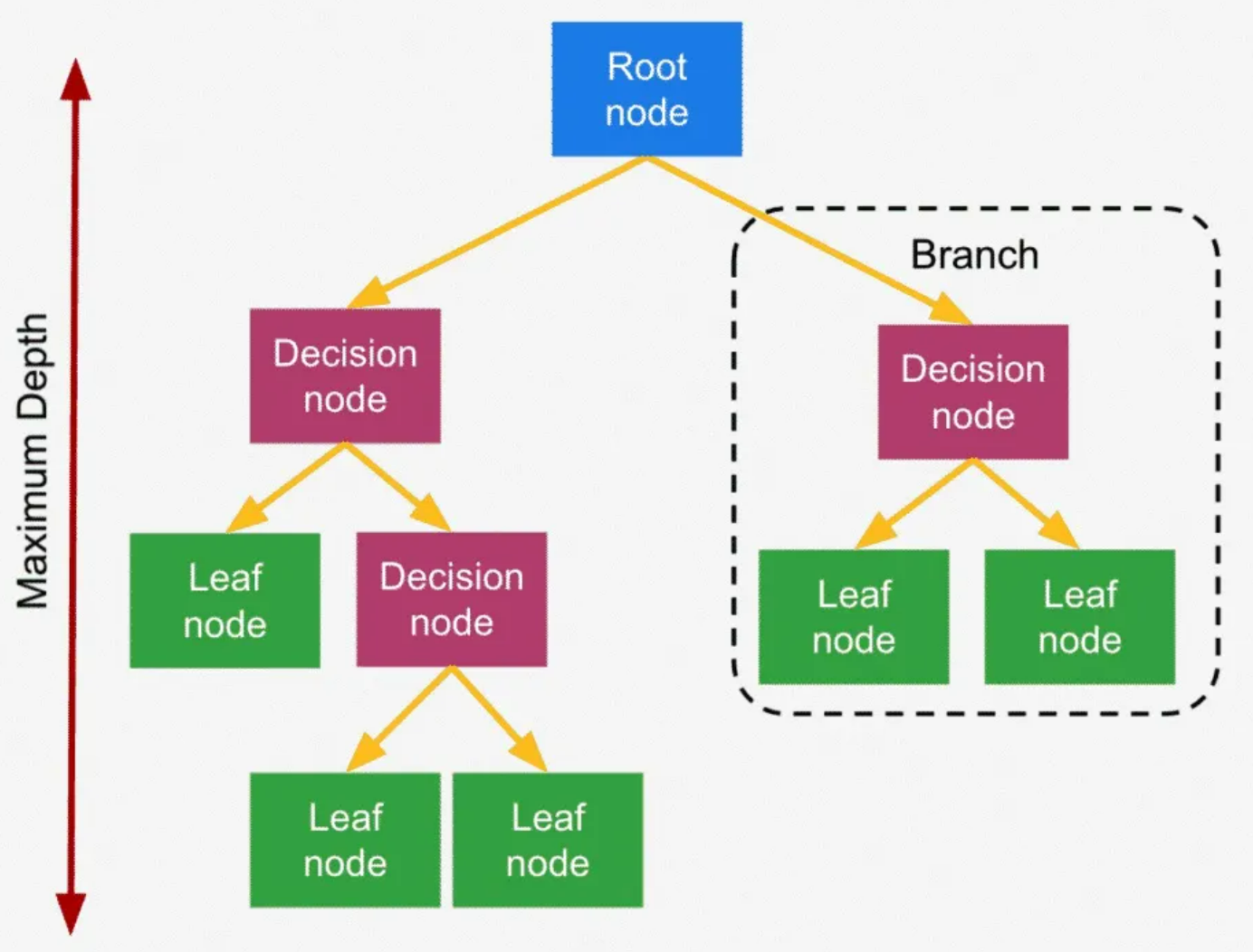
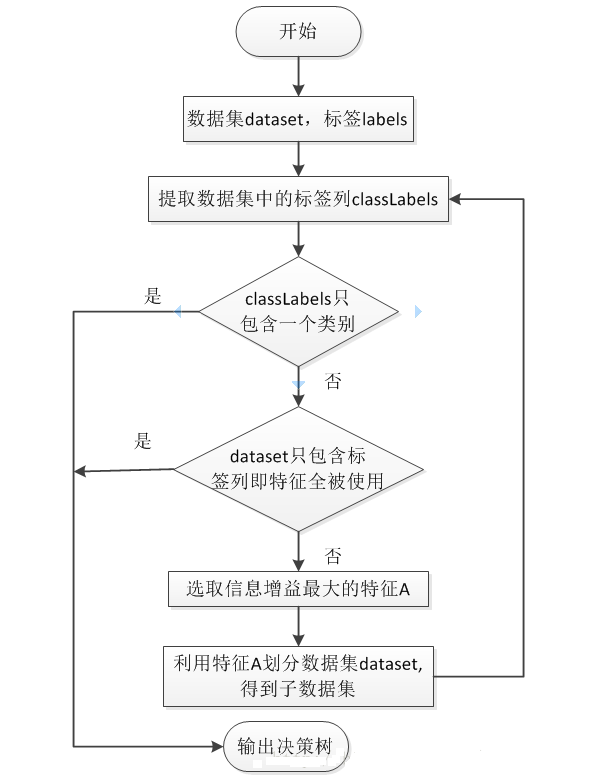
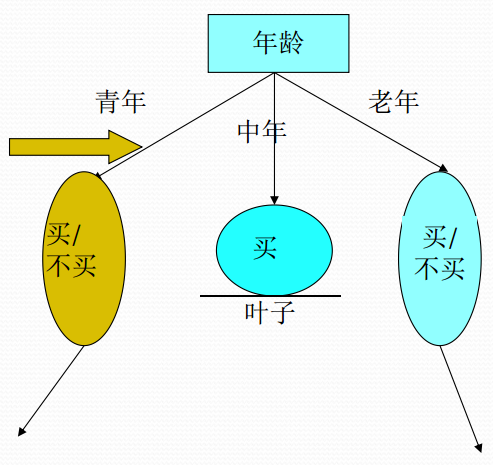
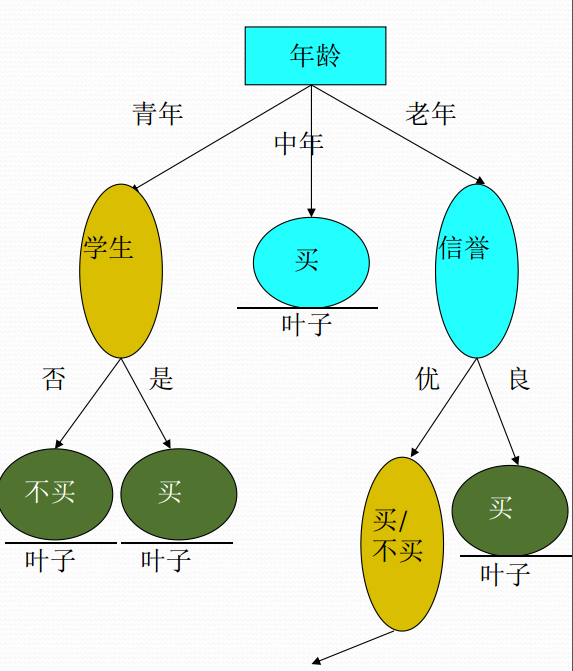
决策树是另一种非常重要的用来处理分类问题的结构,它形似一个嵌套N层的IF…ELSE结构,但是它的判断标准不再是一个关系表达式,而是对应的模块的信息增益。它通过信息增益的大小,从根节点开始,选择一个分支,如同进入一个IF结构的statement,通过属性值的取值不同进入新的IF结构的statement,直到到达叶子节点,找到它所属的“分类”标签。决策树是一种基于树状结构的模型,用于对数据集进行分类和回归分析,其核心思想是通过对数据集的反复划分,构建一颗树状结构,每个节点代表一个决策或特征,每条分支代表一个可能的结果。这种树状结构模拟了人类在面临决策问题时的思考过程,是一种直观而易于理解的机器学习模型。
特征选择: 决策树的构建始于对数据集特征的选择。在每个节点,算法会选择能够最好地划分数据集的特征,以达到将数据集分成最具相似性的子集。常用的划分指标包括信息增益、基尼指数等,它们衡量了特征对数据集划分的优劣程度。
递归划分: 一旦选择了划分特征,数据集就会根据该特征的取值被划分成若干子集。这个划分过程是递归的,对每个子集都会重复选择划分特征的步骤,直到满足某个停止条件,例如节点中的样本数量达到预定阈值或数据集已经完全分类。
叶节点赋值: 当决策树的构建过程达到停止条件时,叶节点被赋予一个特定的类别标签(对于分类问题)或数值(对于回归问题)。这代表了模型对于该子集的最终判定。
剪枝: 为防止过拟合,决策树常常会进行剪枝操作。剪枝可以是预剪枝(在构建树的过程中进行,提前停止分裂)或后剪枝(在构建完整树之后,通过去除部分节点来提高泛化性能)。
模型解释性: 决策树具有很强的模型解释性,因为其生成的树状结构可以直观地表示出模型的决策过程。这使得决策树在需要理解和解释模型预测原因时非常有用。
处理连续特征和多分类问题: 决策树算法可以自然地处理连续特征,通过选择合适的切分点。同时,它也适用于多分类问题,可以通过扩展二叉树结构来支持多个类别。
决策树的思想简洁而直观,使得其在实际应用中得到广泛使用。它不仅可以用于分类和回归问题,还可以被扩展应用于异常检测等领域。然而,决策树也面临着容易过拟合、对噪声敏感等挑战,因此需要结合剪枝等技术进行优化,或者使用集成学习方法如随机森林,以提高模型的性能和稳定性。
| 流程图 | 数据集 |
|---|---|
 |
 |
二、ID3算例
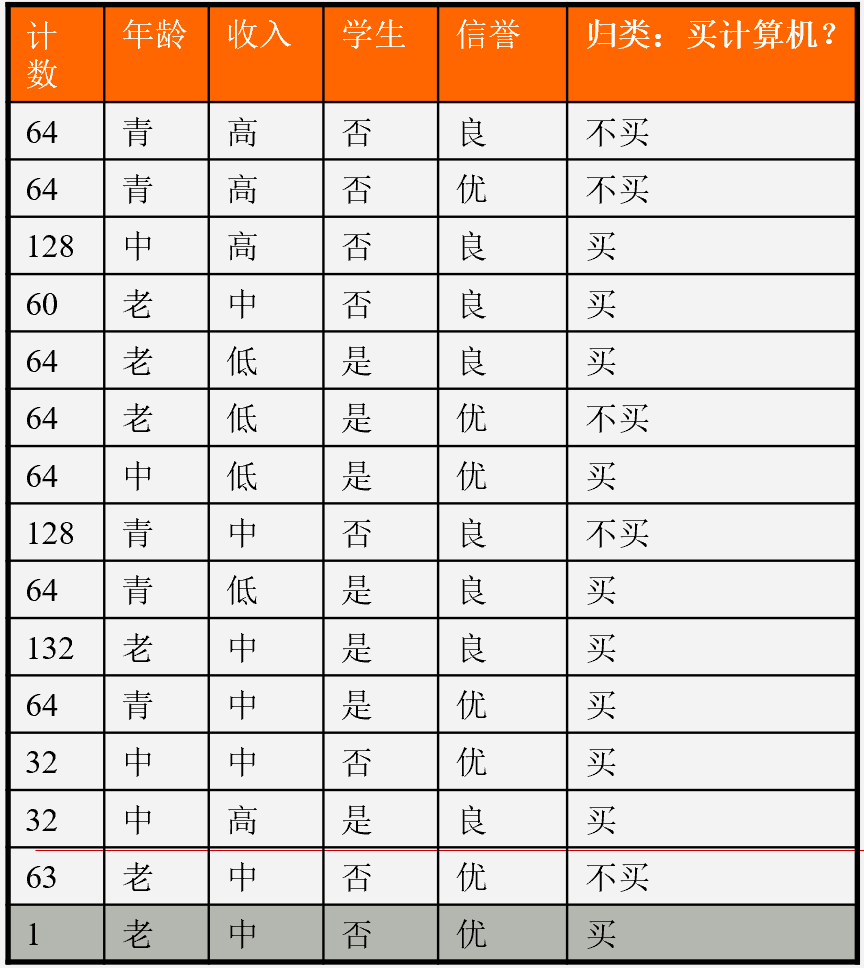
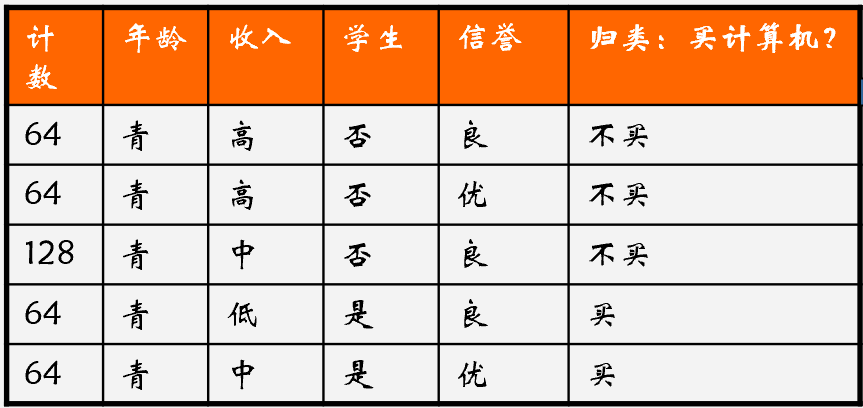
决策树算法最原始的版本是ID3算法,ID3算法由Ross Quinlan发明,建立在“奥卡姆剃刀”的基础上:越是小型的决策树越优于大的决策树(be simple简单理论)。ID3算法中根据信息增益评估和选择特征,每次选择信息增益最大的特征作为判断模块建立子结点。ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。使用信息增益的话其实是有一个缺点,那就是它偏向于具有大量值的属性。就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的,另外ID3不能处理连续分布的数据特征,于是就有了C4.5算法。CART算法也支持连续分布的数据特征。
- 信息熵
对于常见分类系统来说,假设类别 是变量, 可能取值 ,每个类别出现的概率为 ,共 类。分类系统的摘为:
参看上面数据集,我们先不考虑特征,该样本最终分为结果只有买与不买两类,根据统计可知在 1024 个样本中有 641 个数据结果为买, 383 个数据结果为不买。显然买的概率为 , 不买的概率为 。通过这两个统计得到的概率计算的熵为:
信息熵是信息论中的一个重要概念,用于衡量随机变量中的不确定性或信息量。它最初由香农(Claude Shannon)在1948年提出,是信息论的核心概念之一。在信息论中,信息熵是对一系列消息或事件发生概率的度量。高概率事件携带较少信息,因为它们较为预测和常见;而低概率事件携带较多信息,因为它们较为罕见和意外。比如,某市发生了一件凶杀案,警察对案发现场进行了调查后锁定了3个嫌疑人。而对他们审问后得到的信息均是警察已经获知的确定性内容(高概率事件),所以信息量少。如果有人提供了警察尚未掌握的关键情报(低概率事件),那么信息量也就大。信息熵可以用来衡量信息源的平均不确定性,或者说信息源中所包含的平均信息量。当一个信息源的信息熵最大时,意味着它具有最大的不确定性,其中的每个事件概率相等,信息最丰富。相反,当信息熵为0时,信息源是确定性的,每个事件概率都为1,不包含任何信息。

- 条件熵
条件摘 表示在已知随机变量X的条件下随机变量 的不确定性。
我们用 表示在给定的特征 的条件下 的经验条件熵。假设特征 将 划分为 个子集 ,例:年龄特征(A),将我们的数据集分成了三份 青年,中年,老年 。此时条件熵为:
上面数据集年龄共分三个组:青年、中年、老年。青年买与不买比例为 ,则
中年买与不买比例为 ,则
老年买与不买比例为 ,则
- 信息增益(information gain)
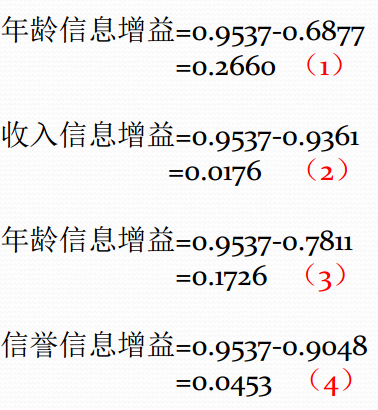
计算完决策属性的摘以后,我们要根据信息增益来排序特征,那什么是信息增益呢?信息增益是相对于特征而言的,表示得知特征A的信息而使得类Y的信息的不确定性减少的程度。信息增益越大,特征对最终的分类结果影响也就越大,因此此特征就被选上作为我们的分类特征。简单地讲,可以理解为一个特征对最终结果相关程度,信息增益大说明该特征与分类结果的关联性很强。特征的信息增益小,则说明该特征对分类的结果影响很小。特征 信息增益 决策属性的熵 - 特征 的平均信息期望,定义为:
青年、中年、老年的所占比例为,所以年龄的平均信息期望为
年龄(A)属性特征的信息增益为:
同理可得其他属性的信息增益为
import math
data_list = [
[64, '青', '高', '否', '良', '不买'],
[64, '青', '高', '否', '优', '不买'],
[128, '中', '高', '否', '良', '买'],
[60, '老', '中', '否', '良', '买'],
[64, '老', '低', '是', '良', '买'],
[64, '老', '低', '是', '优', '不买'],
[64, '中', '低', '是', '优', '买'],
[128, '青', '中', '否', '良', '不买'],
[64, '青', '低', '是', '良', '买'],
[132, '老', '中', '是', '良', '买'],
[64, '青', '中', '是', '优', '买'],
[32, '中', '中', '否', '优', '买'],
[32, '中', '高', '是', '良', '买'],
[63, '老', '中', '否', '优', '不买'],
[1, '老', '中', '否', '优', '买']
]
# 选取某列的相同特征的数据
def get_same_column_value(column_index,value,data_list):
new_data_list = []
for i in data_list:
if i[column_index] == value :
new_data_list.append(i)
return new_data_list
# 计算总计数
def get_total_count(data_list):
count = 0
for i in data_list:
count += i[0]
return count
# 计算熵公式
def get_entropy(p1,p2):
if p1 == 1 and p2 == 0 or p1 == 0 and p2 == 1:
return 0.0
return -(p1*math.log(p1, 2)+p2*math.log(p2, 2))
# 第1步计算决策属性的熵
c5_1,c5_2 = get_total_count(get_same_column_value(5, '买',data_list)),get_total_count(get_same_column_value(5, '不买',data_list))
p5_1,p5_2 = c5_1/(c5_1 + c5_2), c5_2/(c5_1 + c5_2)
Hd_5 = get_entropy(p5_1,p5_2)
print(Hd_5)
# 第2步计算条件属性的熵,以年龄为例
# 计算年龄中青年的熵
c0_1_1,c0_1_2 = get_total_count(get_same_column_value(1, '青',get_same_column_value(5, '买',data_list))
),get_total_count(get_same_column_value(1, '青',get_same_column_value(5, '不买',data_list)))
p0_1_1,p0_1_2 = c0_1_1/(c0_1_1 + c0_1_2), c0_1_2/(c0_1_1 + c0_1_2)
Hd_0_1 = get_entropy(p0_1_1,p0_1_2)
print(Hd_0_1)
# 计算年龄中中年的熵
c0_2_1,c0_2_2 = get_total_count(get_same_column_value(1, '中',get_same_column_value(5, '买',data_list))
),get_total_count(get_same_column_value(1, '中',get_same_column_value(5, '不买',data_list)))
p0_2_1,p0_2_2 = c0_2_1/(c0_2_1 + c0_2_2), c0_1_2/(c0_2_1 + c0_2_2)
Hd_0_2 = get_entropy(p0_2_1,p0_2_2)
print(Hd_0_2)
# 计算年龄中老年的熵
c0_3_1,c0_3_2 = get_total_count(get_same_column_value(1, '老',get_same_column_value(5, '买',data_list))
),get_total_count(get_same_column_value(1, '老',get_same_column_value(5, '不买',data_list)))
p0_3_1,p0_3_2 = c0_3_1/(c0_3_1 + c0_3_2), c0_3_2/(c0_3_1 + c0_3_2)
Hd_0_3 = get_entropy(p0_3_1,p0_3_2)
print(Hd_0_3)
# 计算年龄的平均信息期望
E = get_total_count(get_same_column_value(1, '青',data_list))/get_total_count(data_list)*Hd_0_1 + \
get_total_count(get_same_column_value(1, '中',data_list))/get_total_count(data_list)*Hd_0_2 + \
get_total_count(get_same_column_value(1, '老',data_list))/get_total_count(data_list)*Hd_0_3
print(E)
# 年龄信息增益
G = Hd_5 - E
print(G)
| 属性信息增益 | 构建决策树 |
|---|---|
 |
 |
 |
 |
三、决策树Python程序
数据文件下载https://github.com/Ouxiaolong/Machine-Learning/tree/master/4%20Decision%20Tree
"""
Please note, this code is only for python 3+. If you are using python 2+, please modify the code accordingly.
"""
"""
# @Date : 2018-09-16
# @Author : BruceOu
# @Language : Python3.6
"""
# -*- coding: utf-8 -*-
from sklearn import tree
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
# 测试
if __name__ == '__main__':
## Step 1: load data
print("Step 1: load data...")
# Read in the csv file and put features into list of dict and list of class label
Data = open("data.csv", "rt")
# 读取文件的原始数据
reader = csv.reader(Data) # 返回的值是csv文件中每行的列表,将每行读取的值作为列表返回
# 3.x版本使用该语法,2.7版本则使用headers=reader.next()
headers = next(reader) # 读取行的文件对象,reader指向下一行
# headers存放的是csv的第一行元素,也是后文rowDict的键值
# print("headers :\n" + str(headers))
featureList = []
labelList = []
for row in reader:
labelList.append(row[len(row) - 1])
rowDict = {}
for i in range(1, len(row) - 1):
rowDict[headers[i]] = row[i]
featureList.append(rowDict)
# print("featureList:\n" + str(featureList))
# print("labelList:\n" + str(labelList))
## Step 2: Vetorize data...
print("Step 2: Vetorize data...")
# 提取数据
# Vetorize features
vec = DictVectorizer() # 初始化字典特征抽取器
dummyX = vec.fit_transform(featureList).toarray()
# 查看提取后的特征值
# 输出转化后的特征矩阵
# print("dummyX: \n" + str(dummyX))
# 输出各个维度的特征含义
# print(vec.get_feature_names())
# vectorize class labels
lb = preprocessing.LabelBinarizer() # 将标签矩阵二值化
dummyY = lb.fit_transform(labelList)
# print("dummyY: \n" + str(dummyY))
## Step 3: init DT...
print("Step 3: init DT...")
# Using decision tree for classification
# http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html#sklearn.tree.DecisionTreeClassifier
# clf = tree.DecisionTreeClassifier()
## criterion可选‘gini’, ‘entropy’,默认为gini(对应CART算法),entropy为信息增益(对应ID3算法)
clf = tree.DecisionTreeClassifier(criterion='entropy')
## Step 4: training...
print("Step 4: training...")
clf = clf.fit(dummyX, dummyY)
# 预测数据
oneRowX = dummyX[0, :]
# print("oneRowX: " + str(oneRowX))
newRowX = oneRowX
newRowX[0] = 1
newRowX[2] = 0
print("newRowX: " + str(newRowX))
## Step 5: testing
print("Step 5: testing...")
# predictedLabel = clf.predict([newRowX])#方法一
predictedLabel = clf.predict(newRowX.reshape(1, -1)) # 方法二
## Step 6: show the result
print("Step 4: show the result...")
# print("predictedLabel" + str(predictedLabel))
if predictedLabel == 1:
print("要购买")
else:
print("不购买")
### Step 6: Plot Decision Tree
print("Step 6: Plot Decision Tree...")
# Import necessary libraries for plotting
from sklearn.tree import export_text
import matplotlib.pyplot as plt
# Convert feature names array to a list
feature_names_list = vec.get_feature_names_out().tolist()
# Export the decision tree to a text representation
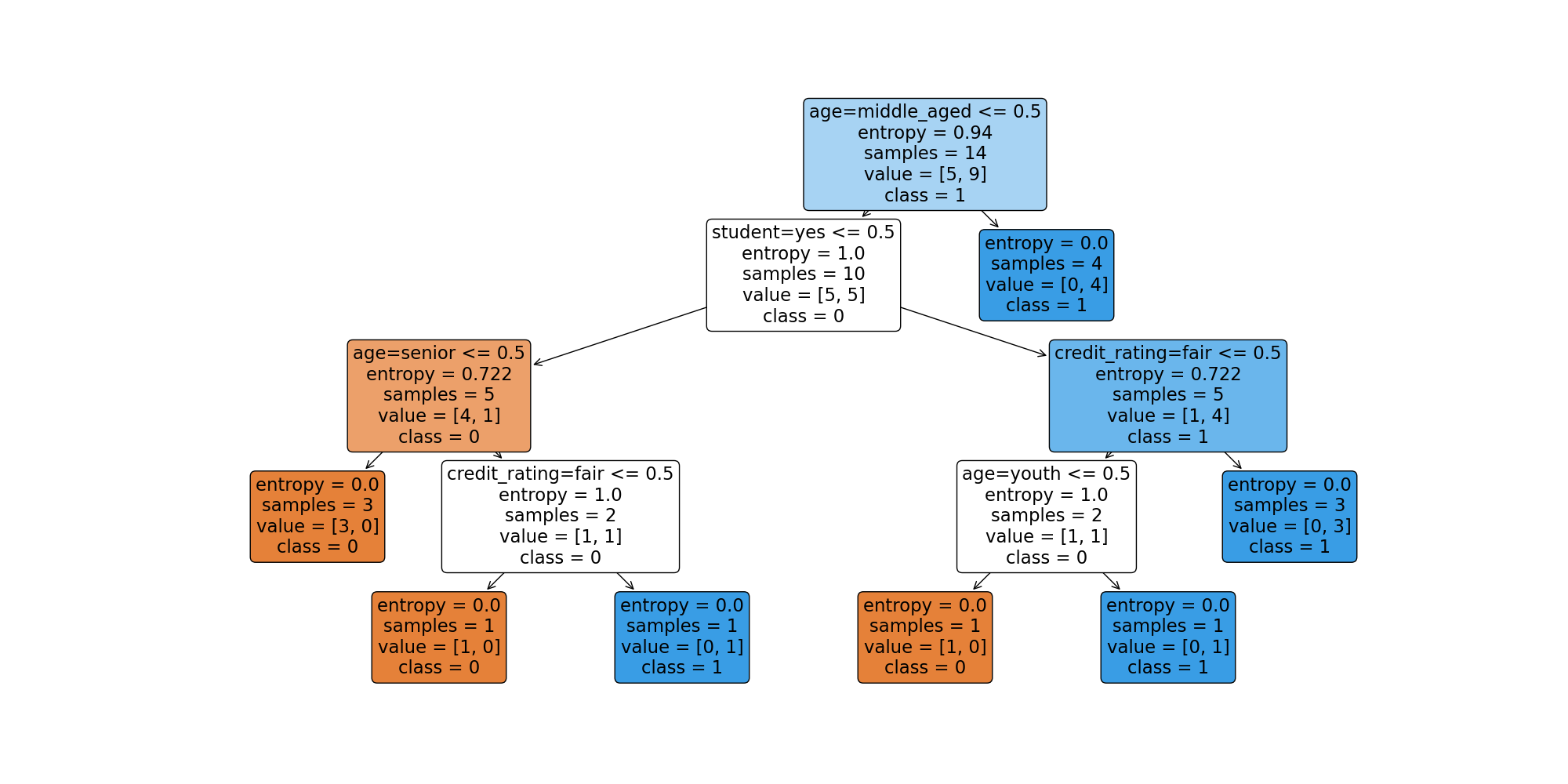
tree_rules = export_text(clf, feature_names=feature_names_list)
print("Decision Tree Rules:\n", tree_rules)
# Plot the decision tree
plt.figure(figsize=(20, 10))
tree.plot_tree(clf, feature_names=feature_names_list, class_names=['0', '1'], filled=True, rounded=True)
plt.show()
| 数据集 | 决策树 |
|---|---|
 |
 |
四、算法评价
| 混淆矩阵 | ROC和Lift曲线 |
|---|---|
 |
 |
混淆矩阵主要是做出来模型后,判断模型的准确度;敏感性和特异性的分子都是用预测准确的真实数据
,预测成正例的比例
,预测正例的比例比上实际正例的比例
# Import necessary libraries for performance evaluation
from sklearn.metrics import confusion_matrix, roc_curve, auc
# Step 7: Evaluate the model
print("Step 7: Evaluate the model...")
# Predict on the entire dataset
predictions = clf.predict(dummyX)
# Convert dummyY to 1D array if it's not already
if len(dummyY.shape) > 1 and dummyY.shape[1] > 1:
dummyY = dummyY.argmax(axis=1)
# Convert predictions to 1D array if it's not already
if len(predictions.shape) > 1 and predictions.shape[1] > 1:
predictions = predictions.argmax(axis=1)
# Confusion Matrix
conf_matrix = confusion_matrix(dummyY, predictions)
print("Confusion Matrix:\n", conf_matrix)
# True Positive, True Negative, False Positive, False Negative
tp = conf_matrix[1, 1]
tn = conf_matrix[0, 0]
fp = conf_matrix[0, 1]
fn = conf_matrix[1, 0]
# Accuracy, Precision, Recall, F1 Score
accuracy = (tp + tn) / (tp + tn + fp + fn)
precision = tp / (tp + fp)
recall = tp / (tp + fn)
f1_score = 2 * (precision * recall) / (precision + recall)
print("Accuracy:", accuracy)
print("Precision:", precision)
print("Recall:", recall)
print("F1 Score:", f1_score)
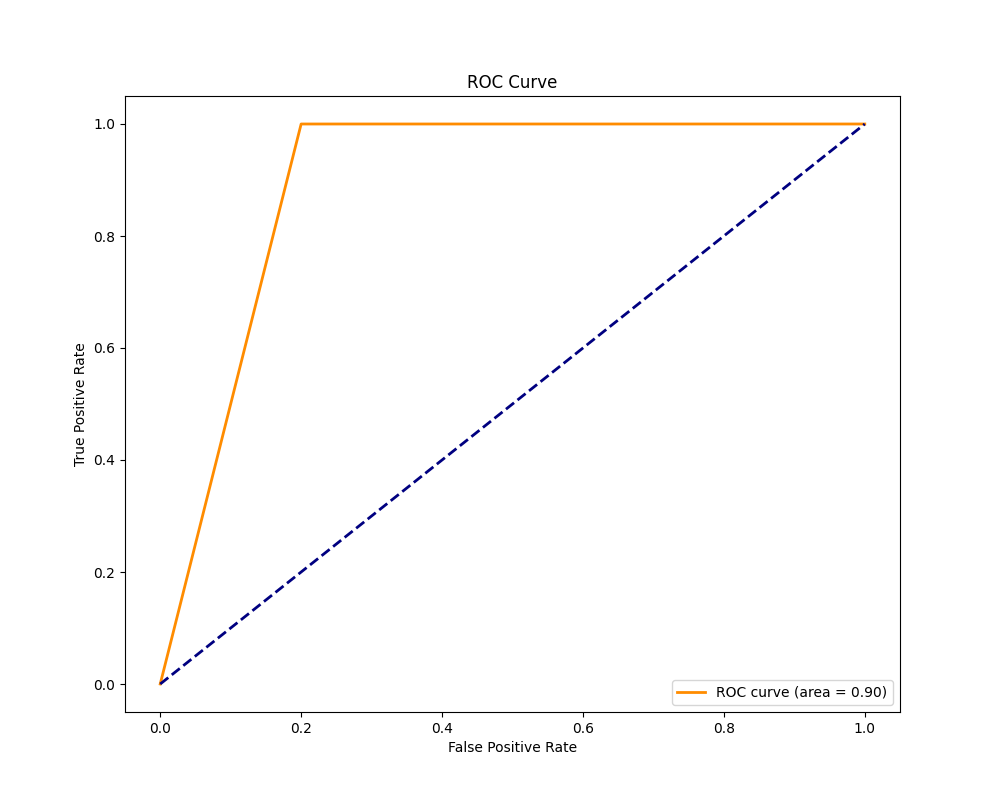
# ROC Curve and AUC
fpr, tpr, thresholds = roc_curve(dummyY, predictions)
roc_auc = auc(fpr, tpr)
plt.figure(figsize=(10, 8))
plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = {:.2f})'.format(roc_auc))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Curve')
plt.legend(loc="lower right")
plt.show()
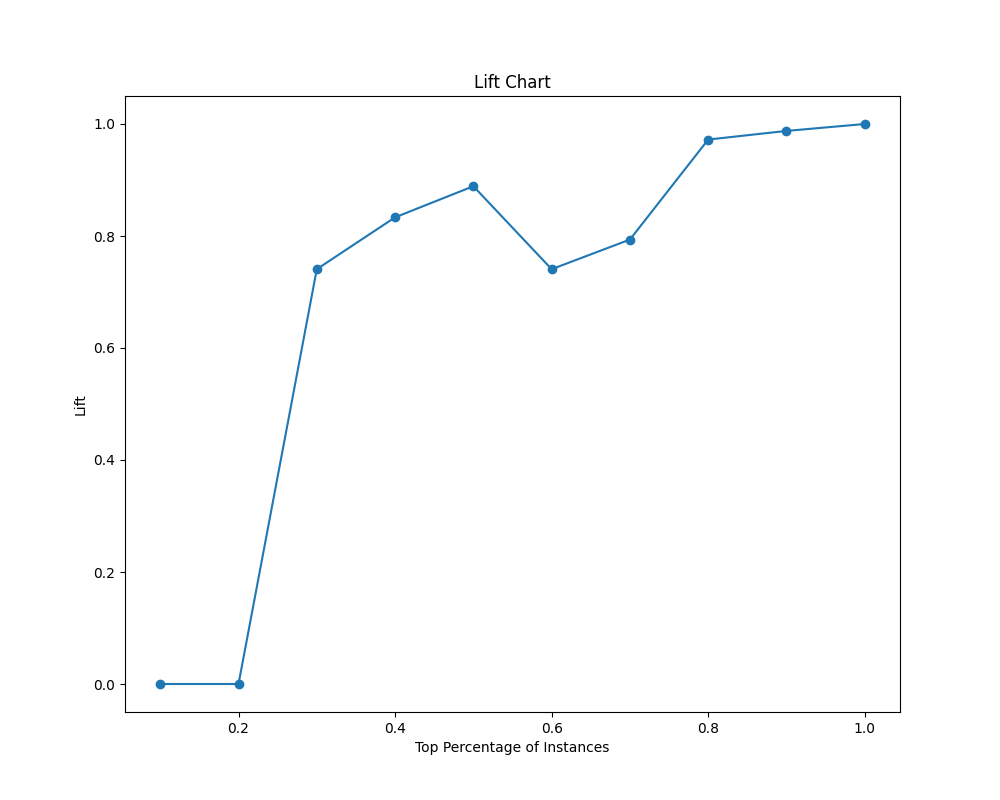
# Lift Chart
total_positive = tp + fn
total_instances = len(dummyY)
lift_values = []
x_values = []
for i in range(1, 11):
threshold = i / 10
top_percentile = int(total_instances * threshold)
top_predictions = predictions[:top_percentile]
top_actual = dummyY[:top_percentile]
top_true_positive = sum(top_actual)
lift = (top_true_positive / total_positive) / threshold
lift_values.append(lift)
x_values.append(threshold)
plt.figure(figsize=(10, 8))
plt.plot(x_values, lift_values, marker='o')
plt.xlabel('Top Percentage of Instances')
plt.ylabel('Lift')
plt.title('Lift Chart')
plt.show()
| ROC曲线 | Lift曲线 |
|---|---|
 |
 |
总结
决策树算法是一种基于树状结构的监督学习方法,用于分类和回归任务。通过递归地将数据集划分为不同的子集,决策树以树形图的方式表示决策过程。每个节点代表一个特征,每个分支代表特征的取值,而叶子节点则表示最终的分类或回归结果。决策树的主要优点之一是易于理解和解释,因为它反映了基于数据特征的决策逻辑。算法的训练过程基于信息熵或基尼系数等指标,选择最佳的特征进行数据划分。决策树具有较好的拟合能力,能够处理非线性关系和多类别问题。目前无论是各大比赛各种大杀器的XGBoost、lightgbm、还是像随机森林、AdaBoost等典型集成学习模型,都是以决策树模型为基础的。ID3算法选择特征的依据是信息增益、C4.5是信息增益比,而CART则是基尼指数。作为一种基础的分类和回归方法,决策树可以有以下两种理解方法:可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)