
决策论——朴素贝叶斯的两个判断准则(四)
在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同。对于大多数的分类算法,比如决策树,KNN,逻辑回归,支持向量机等,他们都是判别方法,也就是直接学习出特征输出YY和特征XX之间的关系,要么是决策函数Y=f(X)Y=f(X),要么是条件分布P(Y|X)P(Y|X)。但是朴素贝叶斯却是生成方法,也就是直接找出特征输出YY和特征XX的联合分布P(X,Y)P(X,Y),然后用P(Y|X)=P(X,Y)/P(X)P(Y|X)=P(X,Y)/P(X)得出。朴素贝叶斯很直观,计算量也不大,在很多领域有广泛的应用。

一、贝叶斯模型描述
贝叶斯学派很古老,但是从诞生到一百年前一直不是主流,主流是频率学派。频率学派的权威皮尔逊和费歇尔都对贝叶斯学派不屑一顾,但是贝叶斯学派硬是凭借在现代特定领域的出色应用表现为自己赢得了半壁江山。贝叶斯学派的思想可以概括为先验概率+数据=后验概率。也就是说我们在实际问题中需要得到的后验概率,可以通过先验概率和数据一起综合得到。数据大家好理解,被频率学派攻击的是先验概率,一般来说先验概率就是我们对于数据所在领域的历史经验,但是这个经验常常难以量化或者模型化,于是贝叶斯学派大胆的假设先验分布的模型,比如正态分布,ββ分布等。这个假设一般没有特定的依据,因此一直被频率学派认为很荒谬。虽然难以从严密的数学逻辑里推出贝叶斯学派的逻辑,但是在很多实际应用中,贝叶斯理论很好用,比如垃圾邮件分类,文本分类。为便于理解,借用生物细胞的简单二分法,引入本部分的阐述。
设ω1ω1代表正常细胞, ω2ω2代表异常细胞(癌细胞)。
P(X)=c∑j=1P(X|ωj)P(ωj)c表示总类别数P(X)=c∑j=1P(X|ωj)P(ωj)c表示总类别数
先验概率:预先已知的或者可以估计的模式识别系统位于某种类型的概率。 P(ω1),P(ω2)P(ω1),P(ω2)称为先验概率,根据统计资料估计得到,
P(ω1)+P(ω2)=1P(ω1)>P(ω2)P(ω1)+P(ω2)=1P(ω1)>P(ω2)
类条件概率:系统位于某种类型条件下模式样本xx出现的概率。P(x|ω1),P(x|ω2)P(x|ω1),P(x|ω2)称为类条件概率,根据训练样本统计分析得到。
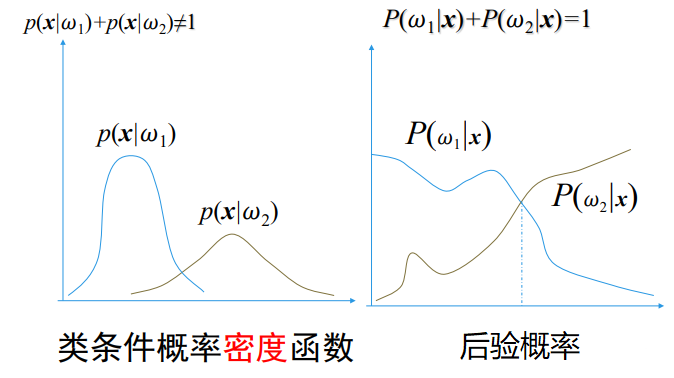
后验概率:系统在某个具体的模式样本 xx条件下位于某种类型的概率,可根据贝叶斯公式计算,用作分类判决的依据。P(ω1|x),P(ω2|x)P(ω1|x),P(ω2|x) 称为后验概率,
联合概率:P(X,ωi)P(X,ωi)
贝叶斯决策:在类条件概率密度和先验概率已知的情况下,通过贝叶斯公式比较样本属于两类的后验概率,为使总体错误率最小,将类别决策为后验概率大的一类。
二、最小错误率贝叶斯决策
贝叶斯判别规则是把某特征向量XX落入某类集群的条件概率当成分类判别函数(概率判别函数),XX落入某集群的条件概率最大的类为XX的类别,这种判决规则就是贝叶斯判别规则。贝叶斯判别规则是以错分概率或风险最小为准则的判别规则。
模式特征 XX: dd维特征向量 X=[x1,x2,...,xd]TX=[x1,x2,...,xd]T
分类错误的概率 P(e|x)P(e|x):是模式特征XX 的函数
平均错误率P(e)P(e):是随机函数 P(e|x)P(e|x)的期望
P(e)=∫P(e|x)P(x)dxP(e)=∫P(e|x)P(x)dx
最小错误率:
若 P(ωk|x)=maxi=1,2P(ωi|x)P(ωk|x)=maxi=1,2P(ωi|x),则x∈ωkx∈ωk
以两分类问题(癌细胞与正常细胞)为例。

假设根据某种分类规则,模式(特征)空间被分成两个部分(以 HH为分界面)其中R1R1中的样本被分为第一类,R2R2中的样本被分为第二类。
已知先验概率P(ω1),P(ω2)P(ω1),P(ω2),根据数据得到类条件概率P(x|ω1),P(x|ω2)P(x|ω1),P(x|ω2)。 利用贝叶斯公式得到后验概率P(ω1|x),P(ω2|x)P(ω1|x),P(ω2|x)
当 P(ω1|x)=P(ω2|x)P(ω1|x)=P(ω2|x) 时的分界线称为决策边界或分类线。
计算错误率:
第一类样本分类错误率:∫R2P(x|ω1)P(ω1)dx∫R2P(x|ω1)P(ω1)dx
第二类样本分类错误率:∫R1P(x|ω2)P(ω2)dx∫R1P(x|ω2)P(ω2)dx
平均分类出错率:
当R1R1中的样本满足P(ω2|x)<P(ω1|x)P(ω2|x)<P(ω1|x)时,P(e)P(e)取得最小值。即当P(ω2|x)=P(ω1|x)P(ω2|x)=P(ω1|x)时,错误率最小。
等价判定公式
朴素贝叶斯决策规则
则X∈ωiX∈ωi类。
根据贝叶斯公式,将后验概率转化为先验概率来表示
上面公式分母与ii无关,也就与分类无关,故分类规则又可表示为
对两分类问题,若P(X|ω1)P(ω1)>P(X|ω2)P(ω2),则X∈ω1P(X|ω1)P(ω1)>P(X|ω2)P(ω2),则X∈ω1
还可改写为,若
统计学称P(X|ω1)P(X|ω2)P(X|ω1)P(X|ω2)为似然比;P(ω2)P(ω1)P(ω2)P(ω1) 为似然比阈值。
例1:对某一地震高发区进行统计,地震以ω1ω1类表示,正常以ω2ω2类表示。统计的时间区间内,每周发生地震的概率为20%,即P(ω1)=0.2P(ω1)=0.2,当然P(ω2)=0.8P(ω2)=0.8。通常地震与生物异常反应之间有一定的联系,若用生物是否有异常反应这一观察现象来对地震进行预测,生物是否异常这一结果以模式xx代表,这里xx为一维特征,且只有xx=“异常”和xx=“正常”两种结果。假设根据观测记录,发现这种方法有以下统计结果:
地震前一周内出现生物异常反应的概率 =0.6=0.6 ,即 P(x=P(x= 异常 ∣ω1)=0.6∣ω1)=0.6
地震前一周内出现生物正常反应的概率 =0.4=0.4 ,即 P(x=P(x= 正常 ∣ω1)=0.4∣ω1)=0.4
一周内没有发生地震但出现生物异常的概率 =0.1=0.1 ,即 P(x=P(x= 异常 ∣ω2)=0.1∣ω2)=0.1
一周内没有发生地震时生物正常的概率 =0.9=0.9 ,即 P(x=P(x= 正常 ∣ω2)=0.9∣ω2)=0.9
若某日观察到明显的生物异常反应现象,此情况属于地震还是正常?
由于0.6<0.9,P(ω1|x=异常)<P(ω2|x=正常)P(ω1|x=异常)<P(ω2|x=正常)
似然比: p(x= 异常 ∣ω1)p(x= 正常 ∣ω2)=0.60.1=6p(x= 异常 ∣ω1)p(x= 正常 ∣ω2)=0.60.1=6
似然比阈值: p(ω2)p(ω1)=0.80.2=4p(ω2)p(ω1)=0.80.2=4
似然比>似然比阈值,则第一类错误率更小,即某日观察到明显的生物异常反应现象,此情况为地震。
三、最小风险贝叶斯决策
样本XX:dd维随机向量 X=[x1,x2,...,xd]TX=[x1,x2,...,xd]T(构成自然空间)
类别ww:Ω={ω1,ω2,...,ωc}Ω={ω1,ω2,...,ωc} (构成状态空间ΩΩ)
决策 αα:分类时所采取的决定。决策αiαi表示将模式XX 指判为ωiωi。
损失函数:对于真实状态为ωiωi的模式XX,采取决策αjαj所带来的损失
若希望尽可能避免将状态ωiωi错判为ωjωj (即该分类错误损失较大),则可以将相应的λijλij的值调大一些。
决策表:决策表的形成是困难的,需要大量的领域知识。决策表不同会导致决策结果的不同。
| α1α1 | α2α2 | ...... | αcαc | |
|---|---|---|---|---|
| ω1ω1 | λ11=λ(α1,ω1)λ11=λ(α1,ω1) | λ12=λ(α2,ω1)λ12=λ(α2,ω1) | ...... | λ1c=λ(αc,ω1)λ1c=λ(αc,ω1) |
| ω2ω2 | λ21=λ(α1,ω2)λ21=λ(α1,ω2) | λ22=λ(α2,ω2)λ22=λ(α2,ω2) | ...... | λ11=λ(αc,ω2)λ11=λ(αc,ω2) |
| ...... | ...... | ...... | λijλij | ...... |
| ωcωc | λc1=λ(α1,ωc)λc1=λ(α1,ωc) | λc2=λ(α2,ωc)λc2=λ(α2,ωc) | ...... | λcc=λ(αc,ωc)λcc=λ(αc,ωc) |
最小风险:把各种分类错误引起的损失考虑进去的贝叶斯决策法则,以使得期望的损失最小。
模式XX的期望损失:通过对属于不同状态ωjωj的后验概率P(ωj|X)P(ωj|X) 采取决策αjαj的期望损失(期望风险)
最小风险:
若R(αk|X)=mini=1,...,cR(αi|X)R(αk|X)=mini=1,...,cR(αi|X),则α=αkα=αk
最小风险和最小错误率贝叶斯决策法则的关系:
两类最小错误率贝叶斯决策规则
多类最小错误率贝叶斯决策规则
多类最小风险贝叶斯决策规则
考虑特殊的损失函数:λii=0,λij=1,i≠jλii=0,λij=1,i≠j
根据贝叶斯公式,将后验概率转化为先验概率来表示
上面公式分母与ii无关,也就与分类无关,故Ri(X)Ri(X)又可转化表示为
当X∈ωiX∈ωi时,应满足
这时最小风险贝叶斯决策准则就是最小错误率贝叶斯准则,所以最小风险准则是最小错误率准则的推广与扩展,二者意义上是一致的。

例2:已知某个局部组织中有异常细胞,且正常细胞ω1ω1和异常细胞ω2ω2的先验概率为P(ω1)=0.9P(ω1)=0.9和P(ω2)=0.1P(ω2)=0.1 。现给一个待识别的细胞,其观测值为xx,从类条件概率密度函数中可以查到:P(x|ω1)=0.2P(x|ω1)=0.2,P(x|ω2)=0.4P(x|ω2)=0.4。
我们给定损失值 Λ=(λ11,λ12,λ21,λ22)=(0,6,1,0)Λ=(λ11,λ12,λ21,λ22)=(0,6,1,0)
施加代价后的贝叶斯风险为:
显然,R1>R2R1>R2,应把xx判断为异常细胞。
四、扩展案例
设有19人进行体检,结果如下表。但事后发现4人忘了写性别,试问这4人是男是女?
| 序号 | 身高 | 体重 | 性别 | 序号 | 身高 | 体重 | 性别 |
|---|---|---|---|---|---|---|---|
| 1 | 170 | 68 | 男 | 11 | 140 | 62 | 男 |
| 2 | 130 | 66 | 女 | 12 | 150 | 64 | 女 |
| 3 | 180 | 71 | 男 | 13 | 120 | 66 | 女 |
| 4 | 190 | 73 | 男 | 14 | 150 | 66 | 男 |
| 5 | 160 | 70 | 女 | 15 | 130 | 65 | 男 |
| 6 | 150 | 66 | 男 | 16 | 140 | 70 | α? |
| 7 | 190 | 68 | 男 | 17 | 150 | 60 | β? |
| 8 | 210 | 76 | 男 | 18 | 145 | 65 | γ? |
| 9 | 100 | 58 | 女 | 19 | 160 | 75 | δ? |
| 10 | 170 | 75 | 男 |
总结
朴素贝叶斯算法的主要原理基本讲清楚了,这里对朴素贝叶斯的优缺点做一个总结。
朴素贝叶斯的主要优点有:
1)朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率。
2)对小规模的数据表现很好,能个处理多分类任务,适合增量式训练,尤其是数据量超出内存时,我们可以一批批的去增量训练。
3)对缺失数据不太敏感,算法也比较简单,常用于文本分类。
朴素贝叶斯的主要缺点有:
1) 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型给定输出类别的情况下,假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
2)需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3)由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
4)对输入数据的表达形式很敏感。



【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek “源神”启动!「GitHub 热点速览」
· 我与微信审核的“相爱相杀”看个人小程序副业
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· C# 集成 DeepSeek 模型实现 AI 私有化(本地部署与 API 调用教程)
· spring官宣接入deepseek,真的太香了~