
R语言数据加工厂——plyr包使用
plyr包是Hadley Wickham大神为解决split – apply – combine问题而写的一个包,其动机在与提供超越for循环和内置的apply函数族的一个一揽子解决方案。使用plyr包可以针对不同的数据类型,在一个函数内同时完成split – apply – combine三个步骤。plyr 的功能已经远远超出数据整容的范围,Hadley在plyr中应用了split-apply-combine的数据处理哲学,即:先将数据分离,然后应用某些处理函数,最后将结果重新组合成所需的形式返回。某些人士喜欢用“揉”来表述这样的数据处理;“揉”把数据当面团捣来捣去。

一、plyr包设计思想
在数据分析中,有许多问题可以由类似的类型和方法步骤解决,可称之为模式,设计模式或者分析模式。下面要讨论的是数据转换的一个常用模式:split – apply – combine。
1.1 plyr包的特点
for的显式循环缺点很明显,代码长,易出错,也难以并行化;拜R语言的向量计算特点所赐,在R当中,大多数问题不需要用显示循环方式,而代之以base包中的apply函数族及其它的一些函数,直接对向量,数组,列表和数据框实现循环的操作。Hadley Wickham大神觉得apply族还是不够简洁,所以开发了pylr包,以更少的代码来解决split – apply – combine问题。
1.2 plyr包的split-apply-combine 模式
大型数据集通常是高度结构化的,结构使得我们可以按不同的方式分组,有时候我们需要关注单个组的数据片断,有时需要聚合不同组内的信息,并相互比较。因此对数据的转换,可以采用split-apply-combine模式来进行处理:
split:把要处理的数据分割成小片断;
apply:对每个小片断独立进行操作;
combine:把片断重新组合。
1.3 split函数
R当中是split( ),*apply( ),aggregate( )…,以及plyr包。split函数这个步骤是由split( ),subset( )等等函数完成的。下面主要介绍split这个函数。函数split可以按照分组因子,把向量,矩阵和数据框进行适当的分组。它的返回值是一个列表,代表分组变量每个水平的观测。这个列表可以使用sapply,lappy进行处理(apply-combine步骤),得到问题的最终结果。
split( )的基本用法是:group <- split(X,f),其中X是待分组的向量,矩阵或数据框。f是分组因子。split还有一个逆函数,unsplit,可以让分组完好如初。在base包里和split功能接近的函数有cut(对属性数据分划),strsplit(对字符串分划)以及subset(对向量,矩阵或数据框按给定条件取子集)等。
library(MASS)
#使用Cars93数据集,利用其中的Origin变量(两个水平),对Price变量分组
g<-split(Cars93$Price,Cars93$Origin)
#计算组内均值
sapply(g,mean)
g[[1]]
[1] 15.7 20.8 23.7 26.3 34.7 40.1 13.4 11.4 15.1 15.9 16.3 16.6 18.8 38.0 18.4 15.8 29.5
[18] 9.2 11.3 13.3 19.0 15.6 25.8 12.2 19.3 7.4 10.1 11.3 15.9 14.0 19.9 20.2 20.9 34.3
[35] 36.1 14.1 14.9 13.5 16.3 19.5 20.7 14.4 9.0 11.1 17.7 18.5 24.4 11.1
1.4 aggregate函数
这个函数的功能比较强大,它首先将数据进行分组(按行),然后对每一组数据进行函数统计,最后把结果组合成一个比较nice的表格返回。根据数据对象不同它有三种用法,分别应用于数据框(data.frame)、公式(formula)和时间序列(ts)。
aggregate(x, by, FUN, ..., simplify = TRUE)
aggregate(formula, data, FUN, ..., subset, na.action = na.omit)
aggregate(x, nfrequency = 1, FUN = sum, ndeltat = 1, ts.eps = getOption("ts.eps"), ...)
attach(mtcars)
aggregate(mtcars, by=list(cyl), FUN=mean)
aggregate(mtcars, by=list(cyl, gear), FUN=mean)
aggregate(cbind(mpg,hp) ~ cyl+gear, FUN=mean)
detach(mtcars)
aggregate(cbind(mpg,hp) ~ cyl+gear, FUN=mean)
cyl gear mpg hp
1 4 3 21.500 97.0000
2 6 3 19.750 107.5000
3 8 3 15.050 194.1667
4 4 4 26.925 76.0000
5 6 4 19.750 116.5000
6 4 5 28.200 102.0000
7 6 5 19.700 175.0000
8 8 5 15.400 299.5000
二、plyr包函数命名规则
apply族函数是R语言中很有特色的一类函数,包括了apply、sapply、lapply、tapply、aggregate等等。这一类函数本质上是将数据进行分割、计算和整合。它们在数据分析的各个阶段都有很好的用处。例如在数据准备阶段,我们可以按某个标准将数据分组,然后获得各组的统计描述。或是在建模阶段,为不同组的数据建立模型并比较建模结果。apply族函数与Google提出的mapreduce策略有着一致的思路。因为mapreduce的思路也是将数据进行分割、计算和整合。只不过它是将分割后的数据分发给多个处理核心进行运算。如果你熟悉了apply族函数,那么将数据转为并行运算是轻而易举的事情。plyr包则可看作是apply族函数的扩展,使之更容易运用,功能更为强大。
plyr包的主函数是**ply形式的,其中首字母可以是(d、l、a),第二个字母可以是(d、l、a、_),不同的字母表示不同的数据格式,d表示数据框格式,l表示列表,a表示数组,_则表示没有输出。第一个字母表示输入的待处理的数据格式,第二个字母表示输出的数据格式。例如ddply函数,即表示输入一个数据框,输出也是一个数据框。
2.1 命名规则
plyr的基本函数集
| array | data frame | list | nothing | |
| array | aaply | adply | alply | a_ply |
| data frame | daply | ddply | dlply | d_ply |
| list | laply | ldply | llply | l_ply |
| n replicates | raply | rdply | rlply | r_ply |
| function arguments | maply | mdply | mlply | m_ply |
命名规则:前三行是基本类型。根据输入类型和输出类型:a=array,d=data frame,l=list,_ 表示输出放弃。第一个字母表示输入,第2个字母表示输出。后两行是对应apply族的replicates和mapply这两个函数,分别表示n次重复和多元函数参数的情况,第2个字母还是表示输出类型。从命名特点来看,我们不需要列出每个函数的情况了,只要从输入和输出两方面分别讨论即可。
2.2 参数说明
a*ply(.data, .margins, .fun, ..., .progress = "none");d*ply(.data, .variables, .fun, ..., .progress = "none");l*ply(.data, .fun, ..., .progress = "none")
这些函数有两到三个主要的参数,依赖于输入的类型:
.data是我们要用来分片-计算-合并的;参数.margins或者.variables****.fun表示用来处理的函数,其它更多的参数(...)是传递给处理函数的;参数.progress用来控制显示一个进度条。
2.3 参数输入
输入类型有三种,每一种类型给出了如何进行分片的不同方法。
a*ply( ):数组(包括矩阵和向量)按维数分为低维的片。
d*ply( ):数据框被变量组合分成子集。
l*ply( ):列表的每个元素就是一个分片。
因此,对输入数据集的分片,不是取决于数据的结构,而是取决于所采用的方法。
三种类型各自的特点:
(a): 输入数组( a*ply )
a*ply的分片特点在于.margins参数,它和apply很相似。对于2维数组, .margins 可以取1,2,或者c(1:2),对应2维数组的3种分片方式。
.margins = 1: Slice up intorows. • .margins = 2: Slice up intocolumns. • .margins = c( 1, 2): Slice up intoindividual cells.
对于2维数组,则有3种分片方式:
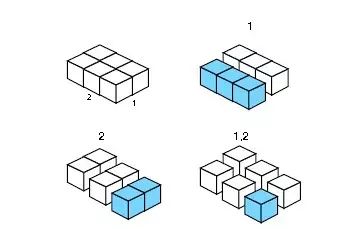
对于3维数组,则有7种分片方式:
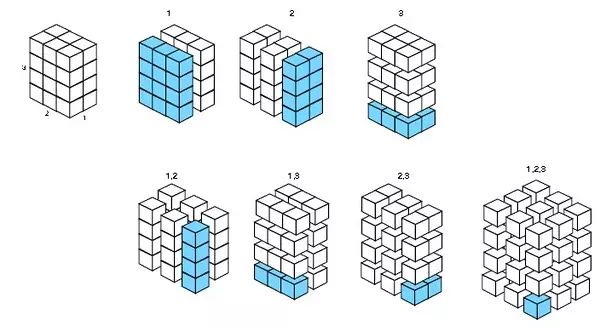
.margins对应更高维的情况,可能会面临一种爆发式的组合。
(b)输入数据框( d*ply )
使用d*ply时,需要特别指定分组所用的变量或变量函数,它们会被首先计算,然后才是整个数据框。
有下面几种指定方式:
.(var1)。按照变量var1的值来对数据框分组 • 多重变量 .(a,b, c)。将按照三个变量的交互值来分组。
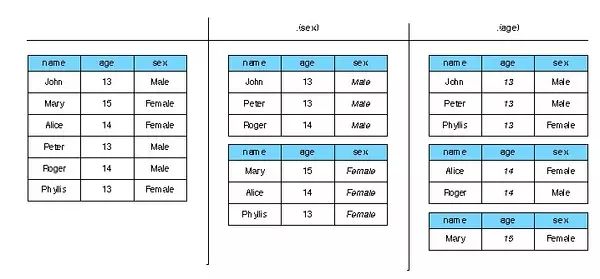
这种形式输出的时候,有点复杂。如果输出为数组,则数组会有三个维度,分别以 a,b,c 的值作为维数名。如果输出为数据框,将会包含 a,b,c 取值的三个额外的列。如果输出为列表,则列表元素名为按周期分割的 a,b,c 的值。
作为列名的字符向量: c( "var1", "var2")。 • 公式~ var1 + var2。
(c) 输入列表( l*ply )
l * ply 不需要描述如何分片的函数,因为列表本身就是按照元素的分划。使用l * ply相当于a*ply作用于一维数组的效果。
三、plyr包应用
这里使用plyr包来进行数据处理,重点在于plyr包的应用,而不是深入地探讨数据的分析。此例来源于 Wickham 的论文[Hadley Wickham :The Split-Apply-Combine Strategy for Data Analysis Journal of Statistical Software,April 2011, Volume 40, Issue 1.],布拉德.皮特在《点球成金》里用数据方法发掘棒球运动员的价值。plyr包的baseball数据集包括了1887-2007年间1228位美国职业棒球运动员15年以上的击球记录。
library(plyr)
data(baseball)
dim(baseball) #数据集和数据结构
baberuth <- subset(baseball, id== "ruthba01")
baberuth <- transform(baberuth, cyear = year - min(year) + 1)
baseball <- ddply( baseball, .( id), transform, cyear = year - min( year) + 1)
library(ggplot2)
cyear <- baberuth$cyear
ra <- (baberuth$rbi)/(baberuth$ab)
a <- data.frame(cyear,ra)
p <- ggplot(a,aes(cyear,ra))
p + geom_line
qplot(cyear, rbi / ab, data= baberuth, geom = "line")
四、plyr包其他函数
plyr包还有几个简单的函数:arrange, mutate,summarise, join, match_df, rename, round_any, count. 这几个函数在plyr包精华ddply系列函数中有不同程度的应用。
4.1 arrange函数
语法:arrange(data.frame,colnames|desc(colnames))),用于对数据框的一列或几列排序
set.seed(124)
data <- data.frame(A=LETTERS[sample(5,replace=TRUE)],B=letters[sample(5,replace=TRUE)],C=round(runif(5,0,1),3),D=sample(100,1:5))
#对数据框data先按A升序排列在按D降序排列
arrange(data,A,desc(D))
4.2 mutate
语法:mutate(data.frame,newcolname=expression(oldcolname)),用于对数据框中的列进行某种函数运算生成新列。
mutate(data,AD=paste(A,D,sep=''),CD=C*100+D,CCD=CD+C)
4.3 summarise
语法:summarise(data.frame,newcolname=expression(oldcolname)),类似与mutate,但创造新的数据框。
summarise(data,AD=paste(A,D,sep=''),CD=C*100+D,CCD=CD+C)
4.4 colwise
语法:colwise(.fun, .cols = true, ...) #全部
catcolwise(.fun, ...) #非数值型
numcolwise(.fun, ...) #数值型
用于迭代地对数据框中的每一列运行函数fun。
nmissing <- function(x) sum(is.na(x))
colwise(nmissing)(baseball)
numcolwise(nmissing)(baseball)
catcolwise(nmissing)(baseball)
4.5 rename
语法:rename(x, replace, warn_missing = TRUE, warn_duplicated = TRUE)
x <- c("a" = 1, "b" = 2, d = 3, 4)
x <- rename(x, replace = c("d" = "c"))
4.6 count
语法:count(data.frame, vars = NULL, wt_var = NULL),对数据框进行计数操作,类似于table
count(baseball[1:100,], vars = "id")
参考文献
(R语言中plyr包 )[https://i.cnblogs.com/posts/edit]



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!