阿里云OSS迁移bucket(政务云迁移至公共云)🥥
阿里云OSS迁移bucket(政务云迁移至公共云)🥥
使用ossimport迁移数据
ossimport有单机模式和分布式模式两种部署方式。
-
单机模式:当您需要迁移的数据小于30 TB时,推荐部署单机模式。您可以将ossimport部署在任意一台可以访问您待迁移数据,且可以访问OSS的机器上。
-
分布式模式:当您需要迁移的数据大于30 TB时,推荐部署分布式模式。您可以将ossimport部署在任意多台可以访问您待迁移数据,且可以访问OSS的机器上。
下面介绍单机模式部署:
前提条件
已安装Java 1.7或Java 1.8。
快速使用
1.下载ossimport-2.3.7.zip并解压。
解压后的文件结构如下:
ossimport ├── bin │ └── ossimport2.jar # 包括Master、Worker、TaskTracker、Console四个模块的总jar ├── conf │ ├── local_job.cfg # Job配置文件 │ └── sys.properties # 系统运行参数配置文件 ├── console.bat # Windows命令行,可以分布执行调入任务 ├── console.sh # Linux命令行,可以分布执行调入任务 ├── import.bat # Windows一键导入,执行配置文件为conf/local_job.cfg配置的数据迁移任务,包括启动、迁移、校验、重试 ├── import.sh # Linux一键导入,执行配置文件为conf/local_job.cfg配置的数据迁移任务,包括启动、迁移、校验、重试 ├── logs # 日志目录 └── README.md # 说明文档,强烈建议使用前仔细阅读
2.根据需求编辑conf/sys.properties、conf/local_job.cfg文件。
将ossimport工具解压后,进入conf目录,修改local_job.cfg文件对应内容
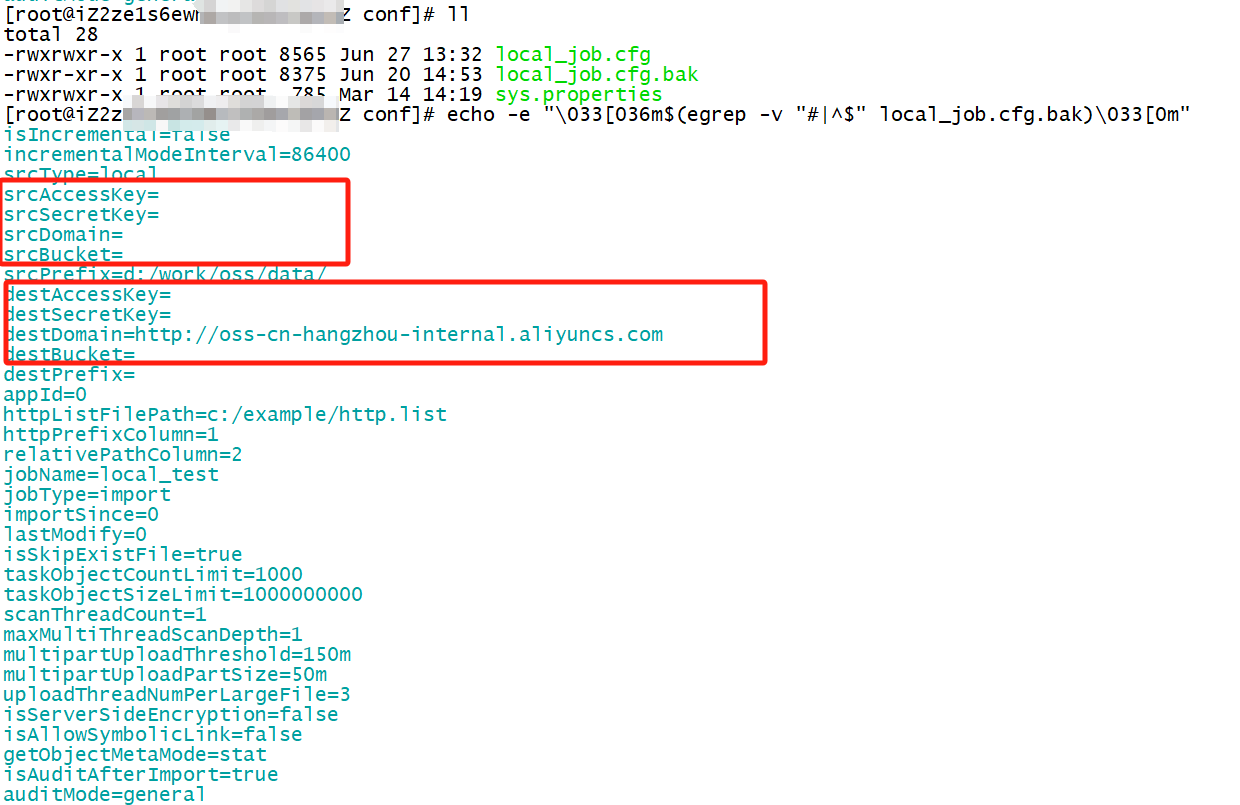
要修改的字段:
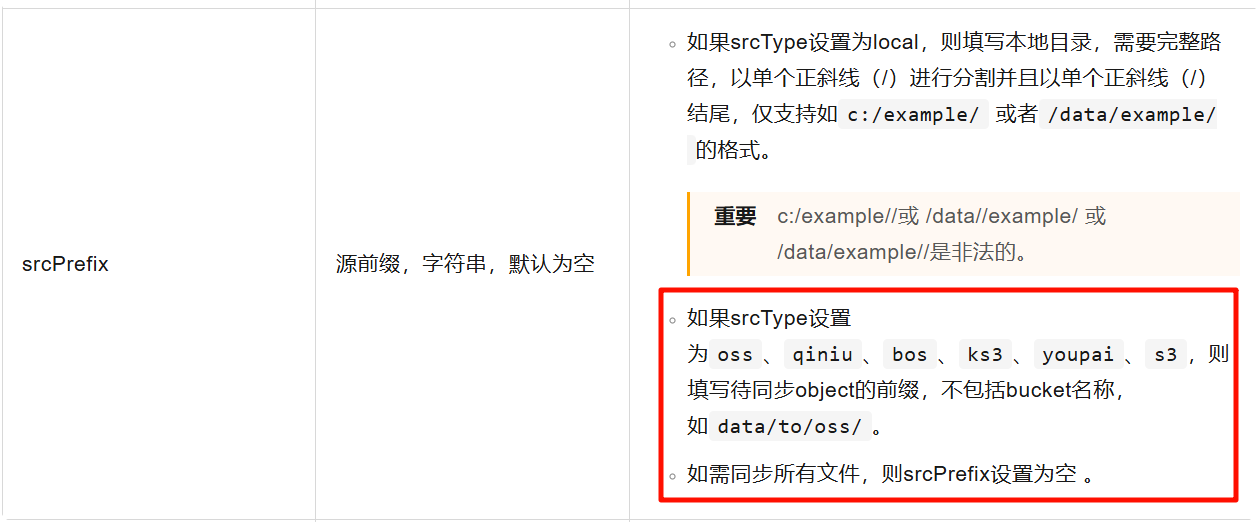
srcPrefix=留空
注意不要修改以下内容:
-
conf/sys.properties中的配置项workingDir、workerUserName、workerPassword、privateKeyFile。
-
conf/local_job.cfg的名称、位置、配置项jobName。
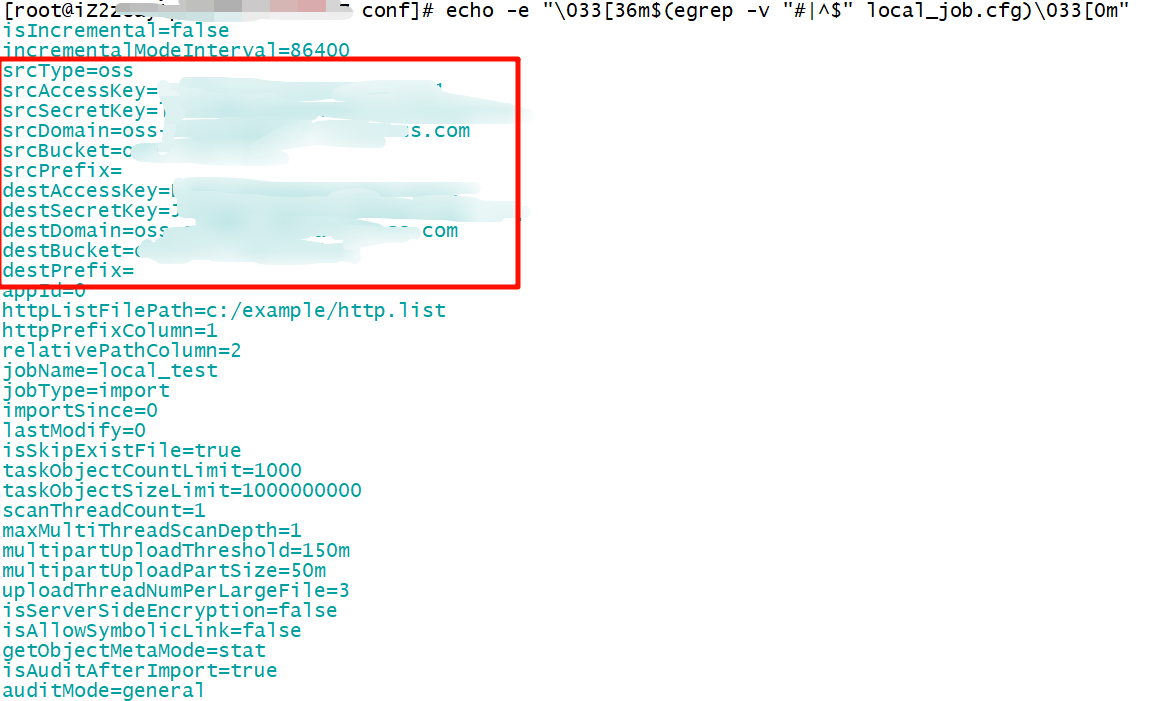
配置示例请参见配置文件示例。
3.配置完成后运行任务。
-
Window系统下在双击运行import.bat。
-
Linux终端中执行bash import.sh命令。
[root@localhost ossimport-2.3.7]# bash import.sh
运行方式
单机模式下,数据迁移任务有以下两种执行方式:
- 一键导入
- 分步执行
这里选择一键导入方式:
-
一键导入:是对所有步骤的封装,按照脚本提示执行即可完成数据迁移。快速使用步骤使用的是这种执行方式,对于初级用户建议使用一键导入 。
-
执行一键导入。
-
Window系统下在双击运行import.bat。
-
Linux终端中执行bash import.sh命令。
如果之前执行过程序,会提示是否从上次的断点处继续执行,或者重新执行同步任务。对新的数据迁移任务,或者修改了同步的源端/目的端,请选择重新执行。
-
-
Windows下任务开始后,会打开一个新的cmd窗口执行同步任务并显示日志,旧窗口会每隔10秒打印一次任务状态,数据迁移期间不要关闭两个窗口;Linux下服务在后台执行。
-
当Job完成后,如果发现有任务失败了,会提示是否重试。输入y重试,输入n则跳过退出。
-
如果上传失败,请查看master/jobs/local_test/failed_tasks/<taskid>/audit.log文件,确定失败原因。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号