
排查服务的TIME_WAIT问题
排查服务的TIME_WAIT问题
学好排除问题的方法,有助于提高生产力。

1. 排查问题原因
说一个前几天的事,早上刚刚上班,系统运维的同事说,我们负责的一个区域的机器有一个tomcat的TIME_WAIT很多,其他的则都不较少,相差相近20倍的量级。让我帮忙排查下,是什么方面的问题导致的。
# 查看TCP连接状态
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
# 查找较多time_wait连接
$ netstat -n | grep TIME_WAIT | awk '{print $5}' | sort | uniq -c | sort -rn | head -n 20
登录到两台主机(一台正常、一台异常)上,首先我需要确认的是两台机器的上游负载是否有问题,主要考虑反向代理服务器的调度算法。发现上游的Nginx代理使用的RR算法且再没有其他参数,所以排除了反代导致的后端服务器分配不一致导致的问题。
其实,心里还是有点不放心,随即查看了两台后端服务器的访问日志,对比发现两者访问数目相差不大,确认不是负载导致的。
打开Google或者Bing搜索发现对应的解决方案中,排在最前面或者被很多人到处转载的解决方案,如下所示。
[escape@localhost ~]$ vim sysctl.conf
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_timestamps = 1
你也会被告知,开启tw_recylce和tw_reuse一定需要timestamps的支持,而且这些配置一般不建议开启,但是对解决TIME_WAIT很多的问题,有很好的用处。
随即,对比两个服务器的sysctl.conf内核配置,发现TIME_WAIT多的那一台没有配置该参数,而正常的那一台则在几个月之前有人给配置了。到这个时候,终于发现了问题的原因。
2. 基础知识准备
对应图示
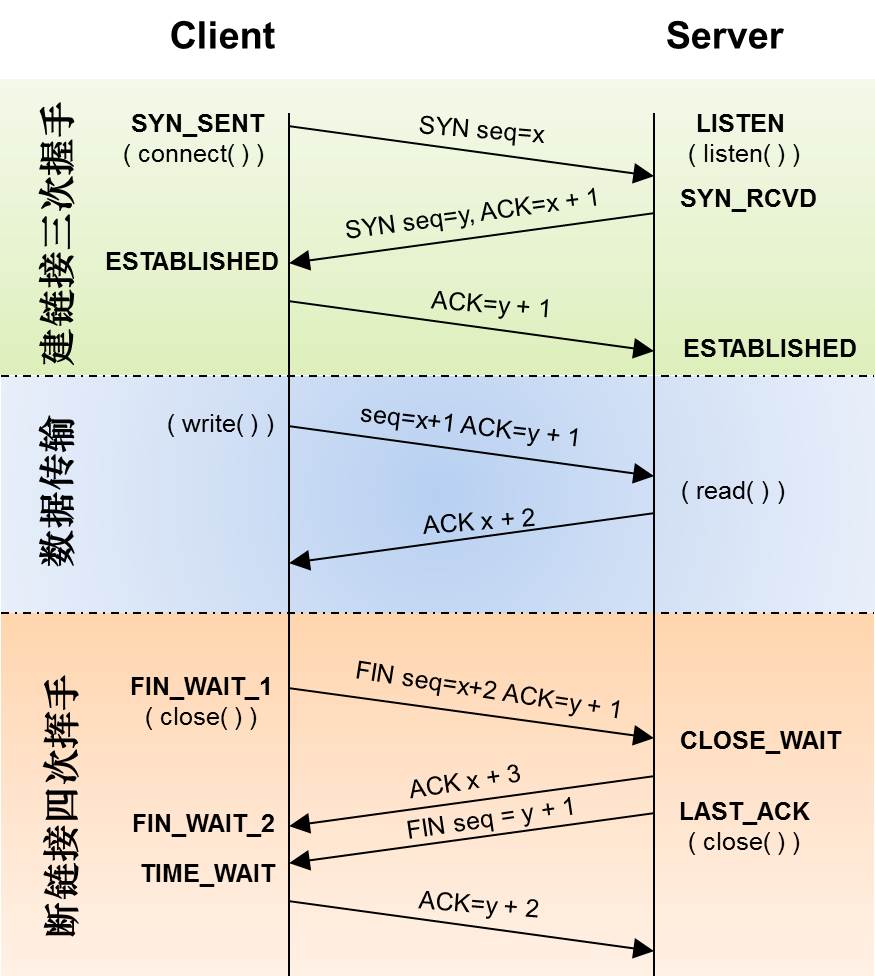
三次握手
- 客户端发送第一次握手
- 客户端发送连接请求(
SYNC包)到服务器 - 之后客户端由
Closed状态转为Sync-Send状态
- 客户端发送连接请求(
- 服务器收到客户端第一次握手
- 服务器收到客户端的请求(
SYNC包),然后发送第二次握手(SYNC+ACK包、即对客户端SYNC包的确认)给客户端 - 之后服务器由
Listen状态转为Sync-Recv状态
- 服务器收到客户端的请求(
- 客户端收到服务器第二次握手
- 客户端收到服务器(
SYNC+ACK包),然后发送第三次握手(ACK包、即对服务器(SYNC+ACK包)的确认)给给服务器 - 之后客户端就转为
ESTABLISHED状态
- 客户端收到服务器(
- 服务器收到客户端第三次握手
- 服务器收到第三次握手的客户端(
ACK包) - 之后服务器也进入了
ESTABLISHED状态
- 服务器收到第三次握手的客户端(
四次挥手
- 客户端发送第一次挥手
- 客户端发送连接请求(
FIN+ACK包)到服务器 - 之后由
ESTABLISHED状态转为FIN_WAIT1状态
- 客户端发送连接请求(
- 服务器收到客户端的第一次挥手
- 服务器收到客户端的第一次挥手(
FIN+ACK包),然后发送第二次挥手(ACK包 ,即对客户端FIN+ACK包的确定)给服务器 - 之后,服务器进入
CLOSE_WAIT状态,等待服务器自身的socket关闭等处理(等待IO,业务处理,资源回收等等)
- 服务器收到客户端的第一次挥手(
- 客户端收到服务器的第二次挥手
- 客户端收到服务器的第二次挥手
ACK包 - 之后,客户端进入
FIN_WAIT2状态,等待服务器关闭(服务器调用close函数发送服务器的FIN包)
- 客户端收到服务器的第二次挥手
- 服务器发送第三次挥手
- 服务器在处理完自己的事情,调用
close函数发送服务器的FIN包给客户端 - 之后,服务器进入
LAST_ACK状态
- 服务器在处理完自己的事情,调用
- 客户端收到服务器第三次挥手
- 客户端收到服务器第三次挥手的
FIN包,然后发送第四次挥手(第二个FIN+ACK包,即对服务器 FIN 包的确定) - 之后,客户端进入
TIME_WAIT状态
- 客户端收到服务器第三次挥手的
- 服务器收到客户端第四次挥手
- 服务器收到客户端第二个
FIN+ACK包 - 之后,服务器进入
CLOSED状态
客户端等待2MSL时间,进入CLOSED状态
- 服务器收到客户端第二个
3. 产生问题原因
通过修改对应的几个参数,reload一下,没几分钟,TIME_WAIT的数量真的降低了。做到这一步,只是完成了50%的工作,知其然就要知其所以然。
所以要解决问题就要先理解产生问题原因,而不是随便修改两行内核参数,发现没有问题了,就万事大吉。没有发现正在的bug所在,只会让问题隐藏的更深,导致更大的问题。
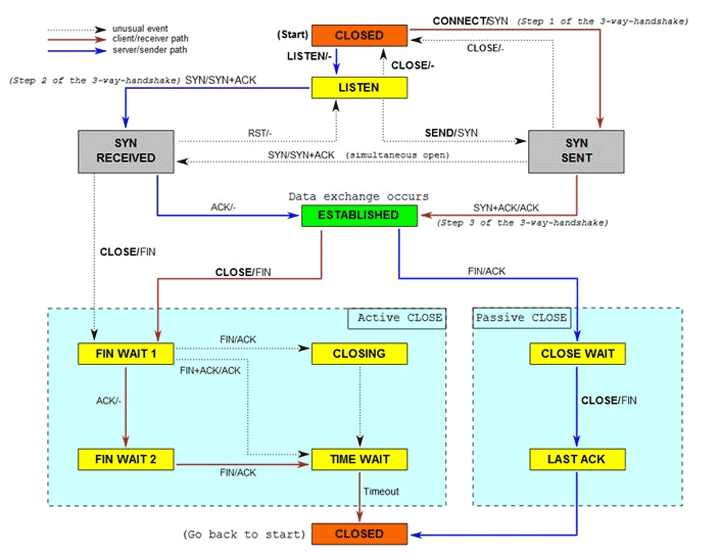
- 什么是 TIME-WAIT 和 CLOSE-WAIT?
学过TPC/IP协议的童鞋都知道,计算机socket使用的是全双工的工作模式。建立socket需要三次握手来完成,之后才能传输数据,最后断开socket也是需要四次挥手来完成。
经过阅读上面的基础知识,我们很容易明白TIME_WAIT并不可怕,而FIN_WAIT1和CLOSE_WAIT是比较危险的状态,一般服务器网络故障首先要查看这俩个状态是否正常:CLOSE_WAIT在上面说过,如果服务器代码有问题(忘记close等),服务器会一直有需要的CLOSE_WAIT状态的socket,造成服务器不可连接;FIN_WAIT1会在发出来 FIN 而没有手到ACK会重新发送 FIN,重发次数由系统参数配置:tcp_orphan_retries;如果系统负载过重,减少tcp_orphan_retries值可能有作用。
- TIME_WAIT 有什么用?
四次挥手中TIME_WAIT的出现,主要是为了解决网络的丢包和网络不稳定所带来的其他问题,TIME_WAIT会默认等待2MSL时间后,才最终进入CLOSED状态。
第一个用途,防止前一个连接上延迟的数据包或者丢失重传的数据包,被后面复用的连接错误的接收。
第二个用途,确保连接方能在时间范围内,关闭自己的连接。其实,也是因为丢包造成的。
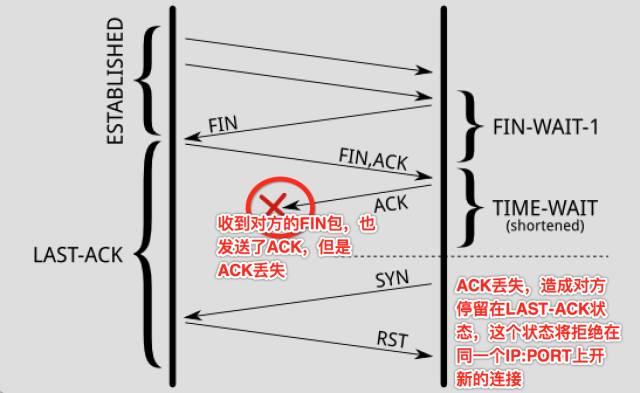
所以,你看到了,TIME_WAIT的存在是很重要的,如果强制忽略TIME_WAIT,还是有很高的机率,造成数据粗乱,或者短暂性的连接失败。
- 相关 TIME_WAIT 调优参数
net.ipv4.tcp_timestamps
RFC 1323在TCP Reliability一节里,引入了timestamp的TCP option,两个4字节的时间戳字段,其中第一个4字节字段用来保存发送该数据包的时间,第二个4字节字段用来保存最近一次接收对方发送到数据的时间。有了这两个时间字段,也就有了后续优化的余地。tcp_tw_reuse 和 tcp_tw_recycle就依赖这些时间字段。
net.ipv4.tcp_tw_reuse
时刻记住一条socket连接,就是那个五元组,出现TIME_WAIT状态的连接,一定出现在主动关闭连接的一方。所以,当主动关闭连接的一方,再次向对方发起连接请求的时候,可以复用TIME_WAIT状态的连接。
例如,客户端关闭连接,客户端再次连接服务端,此时可以复用了;负载均衡服务器,主动关闭后端的连接,当有新的HTTP请求,负载均衡服务器再次连接后端服务器,此时也可以复用。
你看到了,tcp_tw_reuse应用的场景:某一方,需要不断的通过”短连接”连接其他服务器,总是自己先关闭连接(TIME_WAIT在自己这方),关闭后又不断的重新连接对方。
那么,当连接被复用了之后,延迟或者重发的数据包到达,新的连接怎么判断,到达的数据是属于复用后的连接,还是复用前的连接呢?那就需要依赖前面提到的两个时间字段了。复用连接后,这条连接的时间被更新为当前的时间,当延迟的数据达到,延迟数据的时间是小于新连接的时间,所以,内核可以通过时间判断出,延迟的数据可以安全的丢弃掉了。
这个配置,依赖于连接双方,同时对timestamps的支持。同时,这个配置,仅仅影响outbound连接,即做为客户端的角色,连接服务端[connect(dest_ip, dest_port)]时复用TIME_WAIT的socket。
net.ipv4.tcp_tw_recycle
当开启了这个配置后,内核会快速的回收处于TIME_WAIT状态的socket连接。多快?不再是2MSL,而是一个RTO(retransmission timeout,数据包重传的timeout时间)的时间,这个时间根据RTT动态计算出来,但是远小于2MSL。
有了这个配置,还是需要保障丢失重传或者延迟的数据包,不会被新的连接(注意,这里不再是复用了,而是之前处于TIME_WAIT状态的连接已经被destroy掉了,新的连接,刚好是和某一个被destroy掉的连接使用了相同的五元组而已)所错误的接收。在启用该配置,当一个socket连接进入TIME_WAIT状态后,内核里会记录包括该socket连接对应的五元组中的对方IP等在内的一些统计数据,当然也包括从该对方IP所接收到的最近的一次数据包时间。当有新的数据包到达,只要时间晚于内核记录的这个时间,数据包都会被统统的丢掉。
这个配置,依赖于连接双方对timestamps的支持。同时,这个配置,主要影响到了inbound的连接(对outbound的连接也有影响,但是不是复用),即做为服务端角色,客户端连进来,服务端主动关闭了连接,TIME_WAIT状态的socket处于服务端,服务端快速的回收该状态的连接。
由此,如果客户端处于NAT的网络(多个客户端,同一个IP出口的网络环境),如果配置了tw_recycle,就可能在一个RTO的时间内,只能有一个客户端和自己连接成功(不同的客户端发包的时间不一致,造成服务端直接把数据包丢弃掉)。
4. 相关场景演示
- 场景一:负载均衡服务器首先关闭连接
在这种情况下,因为负载均衡服务器对Web服务器的连接,TIME_WAIT大都出现在负载均衡服务器上。
在负载均衡服务器上的配置:
# 尽量复用连接
net.ipv4.tcp_tw_reuse = 1
# 不能保证客户端不在NAT的网络
net.ipv4.tcp_tw_recycle = 0
在Web服务器上的配置为:
# 这个配置主要影响的是Web服务器到DB服务器的连接复用
net.ipv4.tcp_tw_reuse = 1
# 设置成1和0都没有任何意义。想一想,在负载均衡和它的连接中;
# 它是服务端,但是TIME_WAIT出现在负载均衡服务器上;
# 它和DB的连接,它是客户端,recycle对它并没有什么影响,关键是reuse。
net.ipv4.tcp_tw_recycle = ?
- 场景二:Web 服务器首先关闭来自负载均衡服务器的连接
在这种情况下,Web服务器变成TIME_WAIT的重灾区。负载均衡对Web服务器的连接,由Web服务器首先关闭连接,TIME_WAIT出现在 Web 服务器上;Web服务器对DB服务器的连接,由Web服务器关闭连接,TIME_WAIT也出现在它身上。
此时,负载均衡服务器上的配置:
# 0或者1都行,都没有实际意义
net.ipv4.tcp_tw_reuse = ?
# 一定是关闭recycle
net.ipv4.tcp_tw_recycle=0
在Web服务器上的配置:
# 这个配置主要影响的是Web服务器到DB服务器的连接复用
net.ipv4.tcp_tw_reuse = 1
# 由于在负载均衡和Web服务器之间并没有NAT的网络
# 可以考虑开启recycle,加速由于负载均衡和Web服务器之间的连接造成的大量TIME_WAIT。
net.ipv4.tcp_tw_recycle=1
5. 写在最后总结
知其所以然的这个过程还是很耗费时间了,因为需要牵扯很多知识点。如果对 TPC/IP 完全没有理解,就很难理解对于内核参数控制的范围和用处。但是,一旦你知道了原因,也就是你一点点的成长起来了。
我力求比散布在网上的文章做到准确并尽量整理的清晰一些。但是,也难免会有疏漏或者有错误的地方,高手看到可以随时指正,并和我讨论,大家一起研究!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号