Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020)
转载 https://arthurchiao.art/blog/intro-to-io-uring-zh/
Linux 异步 I/O 框架 io_uring:基本原理、程序示例与性能压测(2020)
译者序
本文组合翻译了以下两篇文章的干货部分,作为 io_uring 相关的入门参考:
- How io_uring and eBPF Will Revolutionize Programming in Linux, ScyllaDB, 2020
- An Introduction to the io_uring Asynchronous I/O Framework, Oracle, 2020
io_uring 是 2019 年 Linux 5.1 内核首次引入的高性能 异步 I/O 框架,能显著加速 I/O 密集型应用的性能。 但如果你的应用已经在使用 传统 Linux AIO 了,并且使用方式恰当, 那 io_uring 并不会带来太大的性能提升 —— 根据原文测试(以及我们 自己的复现),即便打开高级特性,也只有 5%。除非你真的需要这 5% 的额外性能,否则 切换成 io_uring 代价可能也挺大,因为要 重写应用来适配 io_uring(或者让依赖的平台或框架去适配,总之需要改代码)。
既然性能跟传统 AIO 差不多,那为什么还称 io_uring 为革命性技术呢?
-
它首先和最大的贡献在于:统一了 Linux 异步 I/O 框架,
- Linux AIO 只支持 direct I/O 模式的存储文件 (storage file),而且主要用在数据库这一细分领域;
io_uring支持存储文件和网络文件(network sockets),也支持更多的异步系统调用 (accept/openat/stat/...),而非仅限于read/write系统调用。
-
在设计上是真正的异步 I/O,作为对比,Linux AIO 虽然也 是异步的,但仍然可能会阻塞,某些情况下的行为也无法预测;
似乎之前 Windows 在这块反而是领先的,更多参考:
- 浅析开源项目之 io_uring,“分步试存储”专栏,知乎
- Is there really no asynchronous block I/O on Linux?,stackoverflow
-
灵活性和可扩展性非常好,甚至能基于
io_uring重写所有系统调用,而 Linux AIO 设计时就没考虑扩展性。
eBPF 也算是异步框架(事件驱动),但与 io_uring 没有本质联系,二者属于不同子系统, 并且在模型上有一个本质区别:
- eBPF 对用户是透明的,只需升级内核(到合适的版本),应用程序无需任何改造;
io_uring提供了新的系统调用和用户空间 API,因此需要应用程序做改造。
eBPF 作为动态跟踪工具,能够更方便地排查和观测 io_uring 等模块在执行层面的具体问题。
本文介绍 Linux 异步 I/O 的发展历史,io_uring 的原理和功能, 并给出了一些程序示例和性能压测结果(我们在 5.10 内核做了类似测试,结论与原文差不多)。
Ceph 代码上已经支持了
io_uring,但发行版在编译时没有打开这个配置,判断是否支持 io_uring 直接返回的false, 因此想测试得自己重新编译。测试时的参考配置:$ cat /etc/ceph/ceph.conf [osd] bluestore_ioring = true ...确认配置生效(这是只是随便挑一个 OSD):
$ ceph config show osd.16 | grep ioring bluestore_ioring true file还要去看下日志,是否因为检测 io_uring 失败而 fallback 回了 libaio。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
很多人可能还没意识到,Linux 内核在过去几年已经发生了一场革命。这场革命源于 两个激动人心的新接口的引入:eBPF 和 io_uring。 我们认为,二者将会完全改变应用与内核交互的方式,以及 应用开发者思考和看待内核的方式。
本文介绍 io_uring(我们在 ScyllaDB 中有 io_uring 的深入使用经验),并略微提及一下 eBPF。
1 Linux I/O 系统调用演进
1.1 基于 fd 的阻塞式 I/O:read()/write()
作为大家最熟悉的读写方式,Linux 内核提供了基于文件描述符的系统调用, 这些描述符指向的可能是存储文件(storage file),也可能是 network sockets:
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
二者称为阻塞式系统调用(blocking system calls),因为程序调用 这些函数时会进入 sleep 状态,然后被调度出去(让出处理器),直到 I/O 操作完成:
- 如果数据在文件中,并且文件内容已经缓存在 page cache 中,调用会立即返回;
- 如果数据在另一台机器上,就需要通过网络(例如 TCP)获取,会阻塞一段时间;
- 如果数据在硬盘上,也会阻塞一段时间。
但很容易想到,随着存储设备越来越快,程序越来越复杂, 阻塞式(blocking)已经这种最简单的方式已经不适用了。
1.2 非阻塞式 I/O:select()/poll()/epoll()
阻塞式之后,出现了一些新的、非阻塞的系统调用,例如 select()、poll() 以及更新的 epoll()。 应用程序在调用这些函数读写时不会阻塞,而是立即返回,返回的是一个 已经 ready 的文件描述符列表。
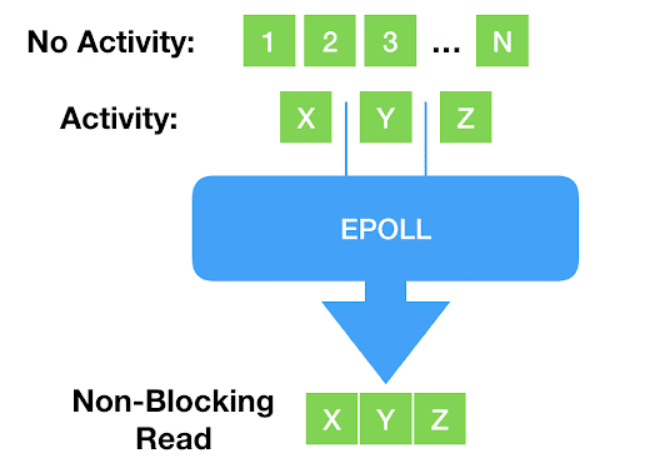
但这种方式存在一个致命缺点:只支持 network sockets 和 pipes —— epoll() 甚至连 storage files 都不支持。
1.3 线程池方式
对于 storage I/O,经典的解决思路是 thread pool: 主线程将 I/O 分发给 worker 线程,后者代替主线程进行阻塞式读写,主线程不会阻塞。
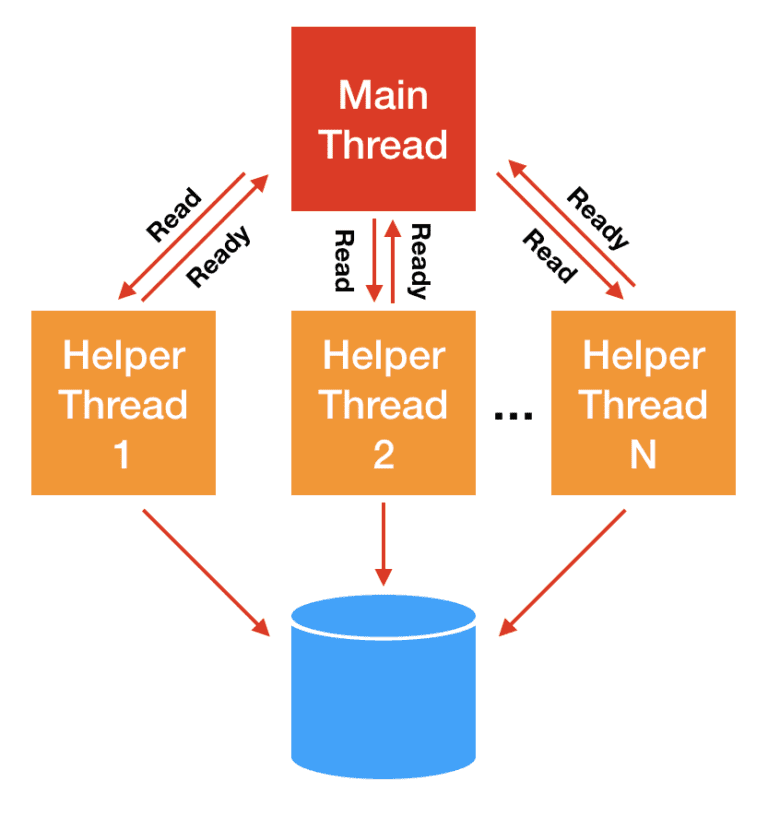
这种方式的问题是线程上下文切换开销可能非常大,后面性能压测会看到。
1.4 Direct I/O(数据库软件):绕过 page cache
随后出现了更加灵活和强大的方式:数据库软件(database software) 有时 并不想使用操作系统的 page cache, 而是希望打开一个文件后,直接从设备读写这个文件(direct access to the device)。 这种方式称为直接访问(direct access)或直接 I/O(direct I/O),
- 需要指定
O_DIRECTflag; - 需要应用自己管理自己的缓存 —— 这正是数据库软件所希望的;
- 是 zero-copy I/O,因为应用的缓冲数据直接发送到设备,或者直接从设备读取。
1.5 异步 IO(AIO)
前面提到,随着存储设备越来越快,主线程和 worker 线性之间的上下文切换开销占比越来越高。 现在市场上的一些设备,例如 Intel Optane ,延迟已经低到和上下文切换一个量级(微秒 us)。换个方式描述, 更能让我们感受到这种开销: 上下文每切换一次,我们就少一次 dispatch I/O 的机会。
因此,Linux 2.6 内核引入了异步 I/O(asynchronous I/O)接口, 方便起见,本文简写为 linux-aio。AIO 原理是很简单的:
- 用户通过
io_submit()提交 I/O 请求, - 过一会再调用
io_getevents()来检查哪些 events 已经 ready 了。 - 使程序员能编写完全异步的代码。
近期,Linux AIO 甚至支持了 epoll():也就是说 不仅能提交 storage I/O 请求,还能提交网络 I/O 请求。照这样发展下去,linux-aio 似乎能成为一个王者。但由于它糟糕的演进之路,这个愿望几乎不可能实现了。 我们从 Linus 标志性的激烈言辞中就能略窥一斑:
Reply to: to support opening files asynchronously
So I think this is ridiculously ugly.
AIO is a horrible ad-hoc design, with the main excuse being “other, less gifted people, made that design, and we are implementing it for compatibility because database people — who seldom have any shred of taste — actually use it”.
— Linus Torvalds (on lwn.net)
首先,作为数据库从业人员,我们想借此机会为我们的没品(lack of taste)向 Linus 道歉。 但更重要的是,我们要进一步解释一下为什么 Linus 是对的:Linux AIO 确实问题缠身,
- 只支持
O_DIRECT文件,因此对常规的非数据库应用 (normal, non-database applications)几乎是无用的; - 接口在设计时并未考虑扩展性。虽然可以扩展 —— 我们也确实这么做了 —— 但每加一个东西都相当复杂;
- 虽然从技术上说接口是非阻塞的,但实际上有 很多可能的原因都会导致它阻塞,而且引发的方式难以预料。
1.6 小结
以上可以清晰地看出 Linux I/O 的演进:
- 最开始是同步(阻塞式)系统调用;
- 然后随着实际需求和具体场景,不断加入新的异步接口,还要保持与老接口的兼容和协同工作。
另外也看到,在非阻塞式读写的问题上并没有形成统一方案:
- Network socket 领域:添加一个异步接口,然后去轮询(poll)请求是否完成(readiness);
- Storage I/O 领域:只针对某一细分领域(数据库)在某一特定时期的需求,添加了一个定制版的异步接口。
这就是 Linux I/O 的演进历史 —— 只着眼当前,出现一个问题就引入一种设计,而并没有多少前瞻性 —— 直到 io_uring 的出现。
2 io_uring
io_uring 来自资深内核开发者 Jens Axboe 的想法,他在 Linux I/O stack 领域颇有研究。 从最早的 patch aio: support for IO polling 可以看出,这项工作始于一个很简单的观察:随着设备越来越快, 中断驱动(interrupt-driven)模式效率已经低于轮询模式 (polling for completions) —— 这也是高性能领域最常见的主题之一。
io_uring的基本逻辑与 linux-aio 是类似的:提供两个接口,一个将 I/O 请求提交到内核,一个从内核接收完成事件。- 但随着开发深入,它逐渐变成了一个完全不同的接口:设计者开始从源头思考 如何支持完全异步的操作。
2.1 与 Linux AIO 的不同
io_uring 与 linux-aio 有着本质的不同:
-
在设计上是真正异步的(truly asynchronous)。只要 设置了合适的 flag,它在系统调用上下文中就只是将请求放入队列, 不会做其他任何额外的事情,保证了应用永远不会阻塞。
-
支持任何类型的 I/O:cached files、direct-access files 甚至 blocking sockets。
由于设计上就是异步的(async-by-design nature),因此无需 poll+read/write 来处理 sockets。 只需提交一个阻塞式读(blocking read),请求完成之后,就会出现在 completion ring。
-
灵活、可扩展:基于
io_uring甚至能重写(re-implement)Linux 的每个系统调用。
2.2 原理及核心数据结构:SQ/CQ/SQE/CQE
每个 io_uring 实例都有两个环形队列(ring),在内核和应用程序之间共享:
- 提交队列:submission queue (SQ)
- 完成队列:completion queue (CQ)
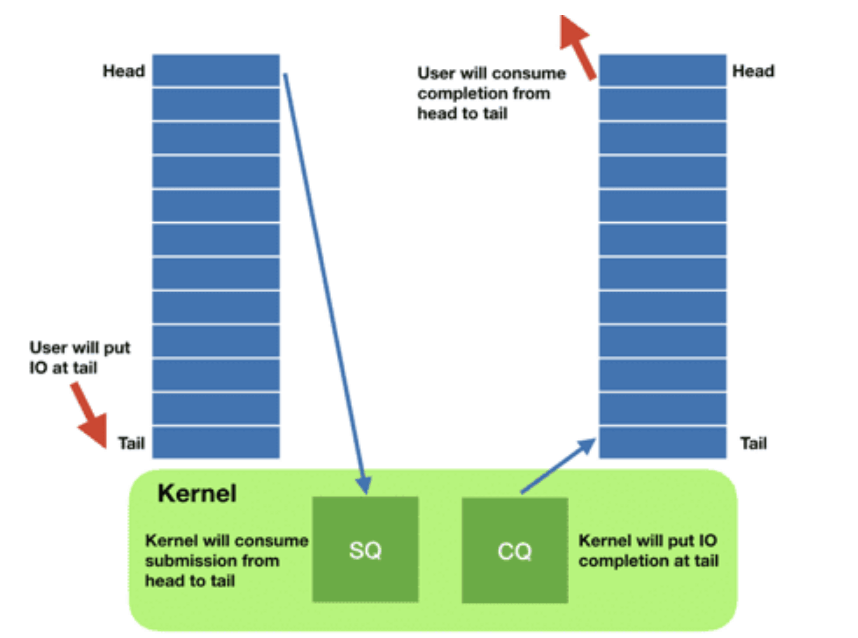
这两个队列:
- 都是单生产者、单消费者,size 是 2 的幂次;
- 提供无锁接口(lock-less access interface),内部使用 内存屏障做同步(coordinated with memory barriers)。
使用方式:
-
请求
- 应用创建 SQ entries (SQE),更新 SQ tail;
- 内核消费 SQE,更新 SQ head。
-
完成
- 内核为完成的一个或多个请求创建 CQ entries (CQE),更新 CQ tail;
- 应用消费 CQE,更新 CQ head。
- 完成事件(completion events)可能以任意顺序到达,到总是与特定的 SQE 相关联的。
- 消费 CQE 过程无需切换到内核态。
2.3 带来的好处
io_uring 这种请求方式还有一个好处是:原来需要多次系统调用(读或写),现在变成批处理一次提交。
还记得 Meltdown 漏洞吗?当时我还写了一篇文章 解释为什么我们的 Scylla NoSQL 数据库受影响很小:aio 已经将我们的 I/O 系统调用批处理化了。
io_uring 将这种批处理能力带给了 storage I/O 系统调用之外的 其他一些系统调用,包括:
readwritesendrecvacceptopenatstat- 专用的一些系统调用,例如
fallocate
此外,io_uring 使异步 I/O 的使用场景也不再仅限于数据库应用,普通的 非数据库应用也能用。这一点值得重复一遍:
虽然
io_uring与aio有一些相似之处,但它的扩展性和架构是革命性的: 它将异步操作的强大能力带给了所有应用(及其开发者),而 不再仅限于是数据库应用这一细分领域。
我们的 CTO Avi Kivity 在 the Core C++ 2019 event 上 有一次关于 async 的分享。 核心点包括:从延迟上来说,
- 现代多核、多 CPU 设备,其内部本身就是一个基础网络;
- CPU 之间是另一个网络;
- CPU 和磁盘 I/O 之间又是一个网络。
因此网络编程采用异步是明智的,而现在开发自己的应用也应该考虑异步。 这从根本上改变了 Linux 应用的设计方式:
- 之前都是一段顺序代码流,需要系统调用时才执行系统调用,
- 现在需要思考一个文件是否 ready,因而自然地引入 event-loop,不断通过共享 buffer 提交请求和接收结果。
2.4 三种工作模式
io_uring 实例可工作在三种模式:
-
中断驱动模式(interrupt driven)
默认模式。可通过 io_uring_enter() 提交 I/O 请求,然后直接检查 CQ 状态判断是否完成。
-
轮询模式(polled)
Busy-waiting for an I/O completion,而不是通过异步 IRQ(Interrupt Request)接收通知。
这种模式需要文件系统(如果有)和块设备(block device)支持轮询功能。 相比中断驱动方式,这种方式延迟更低(连系统调用都省了), 但可能会消耗更多 CPU 资源。
目前,只有指定了 O_DIRECT flag 打开的文件描述符,才能使用这种模式。当一个读 或写请求提交给轮询上下文(polled context)之后,应用(application)必须调用
io_uring_enter()来轮询 CQ 队列,判断请求是否已经完成。对一个 io_uring 实例来说,不支持混合使用轮询和非轮询模式。
-
内核轮询模式(kernel polled)
这种模式中,会 创建一个内核线程(kernel thread)来执行 SQ 的轮询工作。
使用这种模式的 io_uring 实例, 应用无需切到到内核态 就能触发(issue)I/O 操作。 通过 SQ 来提交 SQE,以及监控 CQ 的完成状态,应用无需任何系统调用,就能提交和收割 I/O(submit and reap I/Os)。
如果内核线程的空闲时间超过了用户的配置值,它会通知应用,然后进入 idle 状态。 这种情况下,应用必须调用
io_uring_enter()来唤醒内核线程。如果 I/O 一直很繁忙,内核线性是不会 sleep 的。
2.5 io_uring 系统调用 API
有三个:
io_uring_setup(2)io_uring_register(2)io_uring_enter(2)
下面展开介绍。完整文档见 manpage。
2.5.1 io_uring_setup()
执行异步 I/O 需要先设置上下文:
int io_uring_setup(u32 entries, struct io_uring_params *p);
这个系统调用
- 创建一个 SQ 和一个 CQ,
- queue size 至少
entries个元素, - 返回一个文件描述符,随后用于在这个 io_uring 实例上执行操作。
SQ 和 CQ 在应用和内核之间共享,避免了在初始化和完成 I/O 时(initiating and completing I/O)拷贝数据。
参数 p:
- 应用用来配置 io_uring,
- 内核返回的 SQ/CQ 配置信息也通过它带回来。
io_uring_setup() 成功时返回一个文件描述符(fd)。应用随后可以将这个 fd 传给 mmap(2) 系统调用,来 map the submission and completion queues 或者传给 to the io_uring_register() or io_uring_enter() system calls.
2.5.2 io_uring_register()
注册用于异步 I/O 的文件或用户缓冲区(files or user buffers):
int io_uring_register(unsigned int fd, unsigned int opcode, void *arg, unsigned int nr_args);
注册文件或用户缓冲区,使内核能长时间持有对该文件在内核内部的数据结构引用(internal kernel data structures associated with the files), 或创建应用内存的长期映射(long term mappings of application memory associated with the buffers), 这个操作只会在注册时执行一次,而不是每个 I/O 请求都会处理,因此减少了 per-I/O overhead。
注册的缓冲区(buffer)性质
- Registered buffers 将会被锁定在内存中(be locked in memory),并计入用户的 RLIMIT_MEMLOCK 资源限制。
- 此外,每个 buffer 有 1GB 的大小限制。
- 当前,buffers 必须是匿名、非文件后端的内存(anonymous, non-file-backed memory),例如 malloc(3) or mmap(2) with the MAP_ANONYMOUS flag set 返回的内存。
- Huge pages 也是支持的。整个 huge page 都会被 pin 到内核,即使只用到了其中一部分。
- 已经注册的 buffer 无法调整大小,想调整只能先 unregister,再重新 register 一个新的。
通过 eventfd() 订阅 completion 事件
可以用 eventfd(2) 订阅 io_uring 实例的 completion events。 将 eventfd 描述符通过这个系统调用注册就行了。
The credentials of the running application can be registered with io_uring which returns an id associated with those credentials. Applications wishing to share a ring between separate users/processes can pass in this credential id in the SQE personality field. If set, that particular SQE will be issued with these credentials.
2.5.3 io_uring_enter()
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t *sig);
这个系统调用用于初始化和完成(initiate and complete)I/O,使用共享的 SQ 和 CQ。 单次调用同时执行:
- 提交新的 I/O 请求
- 等待 I/O 完成
参数:
fd是io_uring_setup()返回的文件描述符;to_submit指定了 SQ 中提交的 I/O 数量;-
依据不同模式:
- 默认模式,如果指定了
min_complete,会等待这个数量的 I/O 事件完成再返回; -
如果 io_uring 是 polling 模式,这个参数表示:
- 0:要求内核返回当前以及完成的所有 events,无阻塞;
- 非零:如果有事件完成,内核仍然立即返回;如果没有完成事件,内核会 poll,等待指定的次数完成,或者这个进程的时间片用完。
- 默认模式,如果指定了
注意:对于 interrupt driven I/O,应用无需进入内核就能检查 CQ 的 event completions。
io_uring_enter() 支持很多操作,包括:
- Open, close, and stat files
- Read and write into multiple buffers or pre-mapped buffers
- Socket I/O operations
- Synchronize file state
- Asynchronously monitor a set of file descriptors
- Create a timeout linked to a specific operation in the ring
- Attempt to cancel an operation that is currently in flight
- Create I/O chains
- Ordered execution within a chain
- Parallel execution of multiple chains
当这个系统调用返回时,表示一定数量的 SEQ 已经被消费和提交了,此时可以安全的重用队列中的 SEQ。 此时 IO 提交有可能还停留在异步上下文中,即实际上 SQE 可能还没有被提交 —— 不过 用户不用关心这些细节 —— 当随后内核需要使用某个特定的 SQE 时,它已经复制了一份。
2.6 高级特性
io_uring 提供了一些用于特殊场景的高级特性:
- File registration(文件注册):每次发起一个指定文件描述的操 作,内核都需要花费一些时钟周期(cycles)将文件描述符映射到内部表示。 对于那些针对同一文件进行重复操作的场景,
io_uring支持提前注册这些文件,后面直接查找就行了。 - Buffer registration(缓冲区注册):与 file registration 类 似,direct I/O 场景中,内核需要 map/unmap memory areas。
io_uring支持提前 注册这些缓冲区(buffers)。 - Poll ring(轮询环形缓冲区):对于非常快是设备,处理中断的开 销是比较大的。
io_uring允许用户关闭中断,使用轮询模式。前面“三种工作模式”小节 也介绍到了这一点。 - Linked operations(链接操作):允许用户发送串联的请求。这两 个请求同时提交,但后面的会等前面的处理完才开始执行。
2.7 用户空间库 liburing
liburing 提供了一个简单的高层 API, 可用于一些基本场景,应用程序避免了直接使用更底层的系统调用。 此外,这个 API 还避免了一些重复操作的代码,如设置 io_uring 实例。
举个例子,在 io_uring_setup() 的 manpage 描述中,调用这个系统调用获得一个 ring 文 件描述符之后,应用必须调用 mmap() 来这样的逻辑需要一段略长的代码,而用 liburing 的话,下面的函数已经将上述流程封装好了:
int io_uring_queue_init(unsigned entries, struct io_uring *ring, unsigned flags);
下一节来看两个例子基于 liburing 的例子。
3 基于 liburing 的示例应用
编译:
$ git clone https://github.com/axboe/liburing.git
$ git co -b liburing-2.0 tags/liburing-2.0
$ cd liburing
$ ls examples/
io_uring-cp io_uring-cp.c io_uring-test io_uring-test.c link-cp link-cp.c Makefile ucontext-cp ucontext-cp.c
$ make -j4
$ ./examples/io_uring-test <file>
Submitted=4, completed=4, bytes=16384
$ ./examples/link-cp <in-file> <out-file>
3.1 io_uring-test
这个程序使用 4 个 SQE,从输入文件中读取最多 16KB 数据。
源码及注释
为方便看清主要逻辑,忽略了一些错误处理代码,完整代码见 io_uring-test.c。
/* SPDX-License-Identifier: MIT */
/*
* Simple app that demonstrates how to setup an io_uring interface,
* submit and complete IO against it, and then tear it down.
*
* gcc -Wall -O2 -D_GNU_SOURCE -o io_uring-test io_uring-test.c -luring
*/
#include "liburing.h"
#define QD 4 // io_uring 队列长度
int main(int argc, char *argv[]) {
int i, fd, pending, done;
void *buf;
// 1. 初始化一个 io_uring 实例
struct io_uring ring;
ret = io_uring_queue_init(QD, // 队列长度
&ring, // io_uring 实例
0); // flags,0 表示默认配置,例如使用中断驱动模式
// 2. 打开输入文件,注意这里指定了 O_DIRECT flag,内核轮询模式需要这个 flag,见前面介绍
fd = open(argv[1], O_RDONLY | O_DIRECT);
struct stat sb;
fstat(fd, &sb); // 获取文件信息,例如文件长度,后面会用到
// 3. 初始化 4 个读缓冲区
ssize_t fsize = 0; // 程序的最大读取长度
struct iovec *iovecs = calloc(QD, sizeof(struct iovec));
for (i = 0; i < QD; i++) {
if (posix_memalign(&buf, 4096, 4096))
return 1;
iovecs[i].iov_base = buf; // 起始地址
iovecs[i].iov_len = 4096; // 缓冲区大小
fsize += 4096;
}
// 4. 依次准备 4 个 SQE 读请求,指定将随后读入的数据写入 iovecs
struct io_uring_sqe *sqe;
offset = 0;
i = 0;
do {
sqe = io_uring_get_sqe(&ring); // 获取可用 SQE
io_uring_prep_readv(sqe, // 用这个 SQE 准备一个待提交的 read 操作
fd, // 从 fd 打开的文件中读取数据
&iovecs[i], // iovec 地址,读到的数据写入 iovec 缓冲区
1, // iovec 数量
offset); // 读取操作的起始地址偏移量
offset += iovecs[i].iov_len; // 更新偏移量,下次使用
i++;
if (offset > sb.st_size) // 如果超出了文件大小,停止准备后面的 SQE
break;
} while (1);
// 5. 提交 SQE 读请求
ret = io_uring_submit(&ring); // 4 个 SQE 一次提交,返回提交成功的 SQE 数量
if (ret < 0) {
fprintf(stderr, "io_uring_submit: %s\n