编程语言中的 6 种内存模型(2016)
转载 https://arthurchiao.art/blog/memory-models-underlie-programming-languages-zh/
编程语言中的 6 种内存模型(2016)
译者序
本文翻译自一篇英文博客 The memory models that underlie programming languages,截至本文翻译时,原文最 后一次更新是在 2016 年。
作者似乎是计算机和编程领域的老兵,除了高屋建瓴地分析这 6 种横跨半个多 世纪的内存模型之外,还举重若轻地点评了如下几十种语言、库或系统(大部 分都是编程语言):Forth、morden Lisps、Haskell、ML、Python、Ruby、PHP5、Lua、 JavaScript、Erlang、Smalltalk、Java、C#、Assembly、Awk、Perl4、Tcl、Octave、 Matlab、APL、J、K、PV-WAVE IDL、Lush、S、S-Plus、R、Numpy、Pandas、OpenGL、Linda 、C++、D、MUMPS、Wheat、Prolog、miniKANREN 等等。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
目录
- 引言
- 序曲:只有原子变量的程序
- COBOL 内存模型:嵌套结构 —— 内存就像一张税单
- LISP 内存模型:对象图 —— 内存是一张带标签的有向图
- FORTRAN 内存模型:并行数组 —— 内存是一系列数组
- 茶歇:为什么没有 Lua、Erlang 和 Forth 内存模型?
- 磁带内存模型:管道 —— 写入、等待数据、继续写入
- MULTICS 内存模型:目录 —— 内存是一棵树
- SQL 内存模型:关系 —— 内存是一个可变、多值有限函数集
- 注释
编程语言发展至今,大约产生了 6 种主要的内存概念化(conceptualizations of memory )模型,我将其称为 “内存模型”(memory models)[2]。从历史渊源上看,这 6 种 模型中有 3 种来自于 20 世纪 50 年代(1950s)最重要的 3 种编程语言:
- COBOL
- LISP
- FORTRAN
另外 3 种来自于在历史上有重要地位的数据存储系统:
- 磁带(magnetic tap)
- Unix-style 层级文件系统(Unix-style hierarchical filesystems)
- 关系数据库(relational databases)
相比于语法(syntax)乃至类型系统(type systems),内存模型在更深层次 上决定了一门编程语言能够做什么或不能做什么。但奇怪的是,我还从未看到过介绍这 些模型的好文章,因此我决定自己来写一篇。在本文中,我会介绍一些主流模型之外的其他 选项(possible alternatives to the mainstream options),以及为什么它们很有趣。
1. 引言
每种现代编程环境都会在一定程度上处理所有这六种内存模型,这也是为什么我们的系 统如此复杂和难以理解的原因之一。
下面的内容中,我将分析这些内存模型如何:
- 表示实体的属性(represent attributes of entities)
- 与数据序列化交互(interact with data serialization)
- 执行(perform)程序的解耦
- 支持(support)程序的解耦
解耦的实现方式是对程序按功能分块,限制每块功能的可访问范围(局部化或私有化)。
2. 序曲:只有原子变量的程序
我们先从一门简单的编程语言开始,这种语言没有结构化数据(structure data)的能力, 因为它没有闭包(closure)和数据类型(data types),只有固定精度的数值类型( number)和布尔类型变量。
2.1 定义示例语言(example language)
下面是这种语言的 BNF 定义,其语义(semantics) 和常规语言差不多,并且有必要的运算符优先级,而不是由语法(grammar)隐式提供:
program ::= def*
def ::= "def" name "(" args ")" block
args ::= "" | name "," args
block ::= "{" statement* "}"
statement ::= "return" exp ";" | name ":=" exp ";" | exp ";" | nest
nest ::= "if" exp block | "if" exp block "else" block | "while" exp block
exp ::= name | num | exp op exp | exp "(" exps ")" | "(" exp ")" | unop exp
exps ::= "" | exp "," exps
unop ::= "!" | "-" | "~"
op ::= logical | comparison | "+" | "*" | "-" | "/" | "%"
logical ::= "||" | "&&" | "&" | "|" | "^" | "<<" | ">>"
comparison ::= "==" | "<" | ">" | "<=" | ">=" | "!="
这门语言能够实现下面的程序:
def f2c(f) { return (f - 32) * 5 / 9; }
def main() { say(f2c(-40)); say(f2c(32)); say(f2c(98.6)); say(f2c(212)); }
2.2 规定进一步限制
这里我们规定:
- 递归是非法的
- 这门编程语言是及早求值的(eager/greedy evaluation, 与惰性求值 lazy evaluation 相反)
- 函数调用是按值传递(call-by-value),这和大部分编程语言是一样的
- 调用子过程(subroutine)时,所有变量默认(implicitly)都是局部变量,并且会被 零值初始化(zero-initialized),因此子函数不会产生任何副作用
2.3 抽象能力和使用场景
在这些限制条件下,这种编程语言只能用来实现有限状态机(FSM)。你可以将其制 作成一个电路(compile it into a circuit)。(不是一个理论上的电路,在计算 机科学中,理论上的电路只是一个布尔表达式有向无环图;而我们这里所说的是一个真正 的物理电路,可以集成寄存器。)
- 程序中出现的每个变量可以分配一个寄存器
- 每个子过程调用可以分配一个寄存器存放其返回值
- 另外还需要一个额外的寄存器存放程序计数器(PC)
在一台有几 GB 内存的机器上运行这种语言写的代码并不会带来多大好处,因为它只能用 到程序中声明的那些变量,其他的变量是无法用到的(never be able to use any more variables than the ones it started with)。
但这并不是说这种语言就毫无用处 —— 很多有用的计算都可以在有限空间(finite space)内完成。但话说回来,这种编程语言的抽象能力还是非常弱的,即使是面向有限空 间计算的场景。
2.4 访问内存方式
可以使用该语言提供的 peek() 和 poke() 函数来访问内存 —— 读/写给定数值地址 (numerical address) 的单个字节。例如,基于这两个函数实现字符串拷贝:
def strcpy(d, s, n) {
while n > 0 { poke(d + n, peek(s + n)); n := n - 1; }
}
这或多或少就是机器码(machine code)和 Forth 能提供的基础设施。 但是,大部分编程语言不会止步于此,事实上很多语言并不会提供 peek() 和 poke() 函数。相反,它们会在朴素的、单一维度的字节数组(austere uniform array of bytes) 之上提供某种形式的结构。
例如,即使只能对有限状态机进行编程,但只要有了嵌套记录(nested-record)、数组 (array)和 union 等数据结构,就能使语言的能力得到很大加强。
3. COBOL 内存模型:嵌套结构 —— 内存就像一张税单
3.1 历史起源
在 COBOL 中,一个数据对象要么是不可分割的(indivisible)—— 例如字符串或数值 这种特定大小的基础对象 —— 要么是一个聚合类型(aggregate),例如:
- 记录(record):将不同类型的数据对象相邻存放到一起
- 联合(union):同一位置能够存放不同类型的数据对象,但对于任意一个给定的 union 对象,其中存储的只能是唯一一种特定类型的对象
- 数组(array):同一类型的数据对象连续地存储在一起
为了在 60 多年后的今天以“事后诸葛亮”的方式来更简单地解释 COBOL 提供的概念,下 面的内容中我会在较大程度上偏离 COBOL 专业术语和分类。)
这或多或少代表了计算机商业数据处理(business data processing on computers)的 穿孔卡片(punched-card)和纸张表格(paper-form)的起源,而这些是继承了 Hollerith 在 1890 年美国人口普查(1890 US census)中使用的自动化系统。
3.2 嵌套记录内存模型
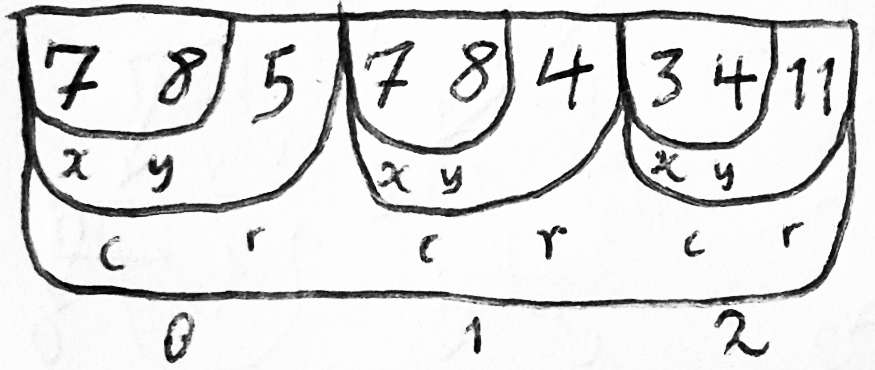
COBOL 程序的任何部分都可以在任意时间读或修改这个表格的字段层级中的任何 部分(any part of this hierarchy of form fields)。
我不确定你是否真的能修改输入文件中的数据(想象一下,这里的输入文件都是人口 普查记录表,你在对记录表做处理/统计的时候,真的能在表格之上随意做修改吗?再推 广到编程范式,应该允许对传入的数据做修改吗?译者注)。但我对此处不是太关心,因 此不再展开。
在这种嵌套记录(nested-record)内存模型中,如果有同一类型的多个实体(several entities of the same type),那每个实体都会对应一个这种类型的记录(record),其 中有与存储这些信息相关的子字段(subfields)和字节大小(size);因此,一个给 定实体的所有信息在内存中都是连续的。
可以很容易地从存储媒介(例如磁盘、磁带或穿孔卡片)加载这些连续的数据块(“反序 列化”),或向存储媒介存放数据块(“序列化”)。如果同时在内存中有多个实体, 它们可能会以数组的形式存放。
一个实体的类型中的某个属性 —— 例如,银行账户中的“账户类型”(account type)属 性 —— 是用一个地址偏移对(a pair of byte offsets)表示的:
- 第一个 offset 表示这个属性在实体中的起始地址
- 第二个 offset 表示这个属性在实体中的结束地址
例如,一个 account 对象可能有一个 account-holder 字段,对应对象中的 10-35 字节, account-holder 可能又包括一个 middle-name 子字段,占据的是 18-26 字节。
3.3 设计特点
这种模型中有一些很有趣的东西,其中一些设计甚至要比我们现在在用的方式还要好。
首先,这种内存模型中没有指针。这意味着:
- 无法做动态内存分配
- 不会解引用一个空指针
- 不会出现野指针覆写(overwrite)某些内存区域的情况(如果两个变量通过
REDEFINES语句共享存储,那其中一个可以覆写另一个;但 tagged unions 可以避免这种问题) - 不会出现内存耗尽
- 不会有别名(aliasing)
- 不会为指针消耗内存(no memory spent on pointers)
但另一方面,这也意味着:
- 定义每个数据结构占用多少内存是不受限制的(arbitrary limit)
- 复用内存的风险与让两个程序同时使用这段内存是一样的(没有动态内存分配和回收,译者注)。
嵌套记录在内存使用上很经济,只需要将当前要用的实体加载到内存中。这意味着完全 可以在只有 KB 级内存的机器上处理 MB 级别的数据 —— 实际上人们在 20 世纪 50 年代( 1950s)就是用 COBOL 这么做的。
3.4 内存布局
内存布局:
- 整个程序除了最外层(top level)之外,程序中的每段数据(字段、子字段、数据项或 者其他任何数据片段)都有一个唯一的父字段或父记录
- 每段数据都包含在其父字段或父记录的数据之中
- 最外层表示整个程序的内存
在这种内存模型中,如果程序的某个部分有一段私有/局部内存(例如栈指针或私有静 态变量),那程序就能够将某些实体作为私有实体/局部实体,只需要将这些实体存储 在这段私有/局部内存就行了。这对创建局部临时变量来说非常有用,这些变量不会影 响到程序其他部分的执行。
但是,嵌套记录内存模型并没有提供一种将程序某个部分中的某个属性(attribute)声明 为私有的方式的。
3.5 对其他编程语言的影响
ALGOL(可能是 ALGOL-58,也可能是 ALGOL-60)采用了 COBOL 的这种“记录”( record)模型作为它的主要数据结构机制(data structuring mechanism),而不是采用 数组(array)。
在 ALGOL 之后,几乎所有其他编程语言都继承了这个系统,虽然具体形式上可能有些 差别。例如,C 语言几乎完全包含了这个数据结构操作符集合(set of data-structuring operators):
- 原生类型,例如
char、int - 结构体(
structs) unions- 数组(arrays)
但是,C 还有子函数,这些函数不仅可以带参数,而且还可以递归,这对栈分配等等来说是 不可或缺的;另外,C 还有指针。这些对 COBOL 模型的扩展或多或少来自 LISP。
4. LISP 内存模型:对象图 —— 内存是一张带标签的有向图
4.1 特点(LISP vs COBOL)
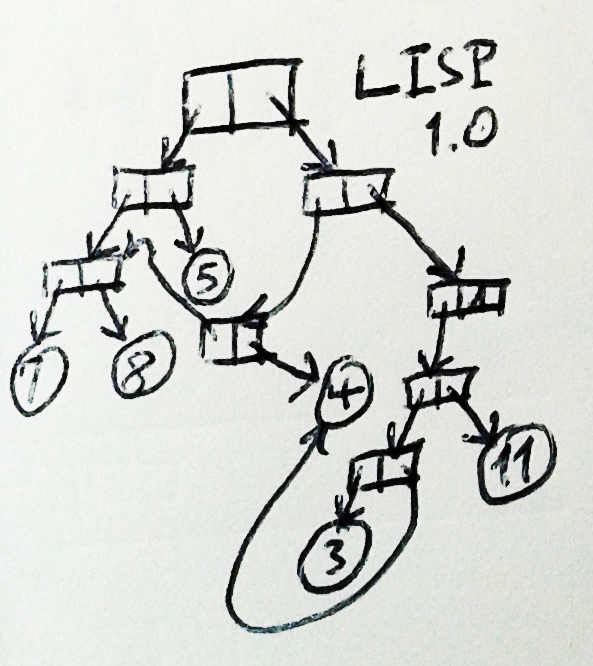
LISP(虽然现在叫 Lisp,但 1959 年的时候还叫 LISP)和 COBOL 的差异不能更大 了:
- LISP 不仅有指针,而且几乎只有指针
- LISP 唯一的数据结构是一个叫
cons的东西:一个cons包含两个指针,一个称 为car,另一个称为cdr - 每个变量的值都是一个指针:可能是一个指向
cons的指针,一个指向符号( symbol)的指针,一个指向数值(number)的指针(某些 Lisps 使用 pointer-tagging 小把戏来避免在内存中真正地创建一个数值对象),甚至是指向一个子过程(subroutine )的指针,但不管是那种情况,它都是一个指针 - LISP 还支持带参数的子过程。事实上,这个特性加上它的尾调用优化特性,你 能够编写在完全不改变变量的情况下做任何事情的程序。(这大部分归功于 Martin 和 Newell 的 IPL,但 LISP 是公认的 IPL 精神的继承者。)
- 由于可以向任何对象添加任意数量的指针别名(pointer alias),而通过任何一个 别名就可以修改这个对象,因此在 LISP 中没有唯一的父结构
4.2 优缺点
这种模型极度灵活,使得编写下列方面的程序非常简单:
- 自然语言解析
- 程序解释和编译
- 穷举搜索(exhaustive search of possibilities)
- 符号数学(symbolic mathematics)
另外,这种模型还使得只需要编写一个数据结构(例如,红黑树),就可以将其应用到不 同类型的数据对象上(Lisp 是动态类型,编写程序时不需要指明数据类型,译者注)。 作为对比,从 COBOL 衍生的语言(例如 C)在这种泛型(generalization)上就有非常大的 困难,导致程序员不得不为新数据类型实现那些著名的数据结构和算法,而其中其实包含了 大量的重复代码(某种程度上,C++ 的模板可以做类似的事情,译者注)。
LISP 内存模型的缺点包括:
- 内存管理很差,程序很容易占用大量内存
- 容易产生 bug(bug-prone)
- 编写高效的代码需要很高的天赋
- 指针管理成本高:由于每个对象都是通过指针来识别的,因此每个对象都可以有别名( every object can be aliased)。每个变量都可能是空指针(null pointer)
- 大量类型错误:由于一个指针可以指向任何东西,因此到处存在类型错误(指向一个某 种类型的对象的指针存储在另一个变量中,后者很可能是另一种类型)
- 执行效率低:传统的对象-图(object-graph)语言使用运行时类型检测来避免调试时间 的膨胀,这进一步降低了程序的执行速度
4.3 查找对象和修改对象
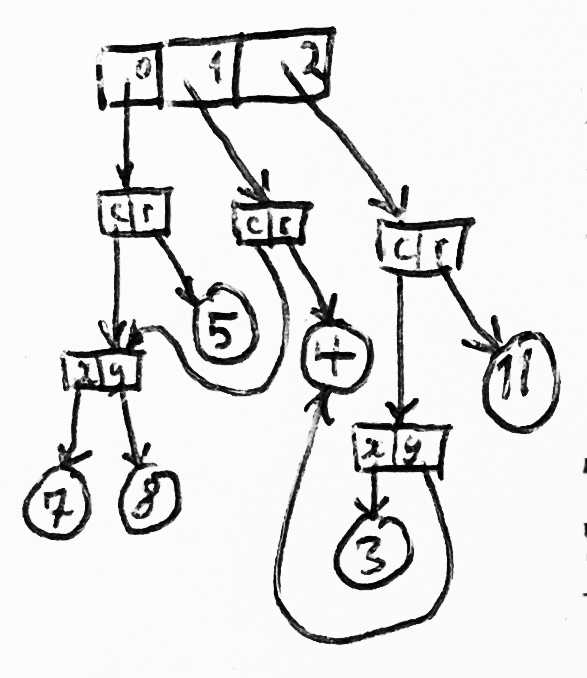
在这种对象-图(object-graph)内存模型中,如果有同一类型的多个实体,那每个实体会 通过一个指针识别;要访问一个实体中的某个具体属性(attribute),需要沿着对象图 中这个指针的开始位置往后寻找。
例如,如果有一个 account 对象,我们用 alist 表示。要查找这个 account 对 象中的 account-holder 对象(可能和其他 account 对象共享,因为一个持有人可 以有多个账户),需要
- 沿着
alist往后走,直到找到一个cons,这个cons的car是ACCOUNT-HOLDER - 取这个
car的cdr
要进一步查找 account-holder 中的 middle-name 对象,你可能会在一个包含了 account-holder 各种属性的向量内进行查找(index into a vector of account-holder attributes)对应的 middle-name 的指针,这个指针指向的( middle-name 对象)可能是一个字符串,也可能是一个符号(symbol),因为在早期 Lisps 中没有字符串。
更新 middle-name 可能涉及到:
- 修改原有字符串
- 更新属性向量,让
middle-name指向新的字符串 - 构造一个指向新
account-holder对象的新alist
具体取决于 account-holder 是否在多个 account 对象之间共享,以及是否希望其 他 account 的 account-holder 也被更新。
4.4 垃圾回收
垃圾回收(GC)在这类语言中是必不可少的。
从 McCarthy 在 1959 年发明 LISP,到 1980 年 Lieberman 和 Hewitt 提出新一代的垃圾 回收算法,在这中间的二十多年,所有使用标记有向图(labeled-directed-graph)的 内存模型通常都将 1/3 到 1/2 的时间用在垃圾回收上。在此期间,某些特意设计为多核的 计算机会将专门的核用于垃圾回收。
对象-图(Object-graph)语言重度依赖垃圾回收器,这不仅是因为它们相比于修改现有对 象更倾向于分配新对象,还因为它们一般都会有大量的指针。
从 COBOL 衍生的语言 ,例如 C 和 Golang,相比之下对垃圾回收期的依赖没有那么强烈,因为它们:
- 分配的次数更少,分配的也都是大对象
- 倾向于在原有的对象上做修改,而不是新分配一个修改过的版本
- 只要有可能,程序员都倾向于嵌套记录(nest records),而不是用指针将这些字段连 起来,因此只有在多态(polymorphism)、nullability(可以认为是多态的一种特殊情 况)或者别名(aliasing)的时候才会用到指针
4.5 序列化
对对象图(object graph)做序列化有点棘手,因为:
- 其中可能包含循环引用(circular references)
- 想序列化的部分可能包含对我们不想序列化的部分的引用
这两种情况都需要做特殊处理。
例如,在某些系统中,一个类实例(class instance)会包含一个对这个类的引用( reference to its class),而类不仅包含对所有类方法的当前版本的引用,还包含对它 的超类(superclass)的引用,而你可能不想每个序列化的对象中都对这个类的整个字节 码(the entire bytecode for the class)做序列化。
另外,当反序列化两个共享同一引用(前面提到的两个账户共享同一个账户持有人)的对象 时,你可能想保持这种共享性质。
因此,解决这些问题的方式可能会随着做序列化的目的的不同而不同。
4.6 私有属性
与嵌套记录(nested-record)模型类似,对象图(object-graph)模型允许将一个特定 实体的所有属性定义为局部(local)的 —— 这些局部属性只会对程序的某一部分可见, 不会泄露给程序的其他部分 —— 但无法将所有实体的某个特定属性定义为私有的( private)。
但是,和嵌套记录不同,对象图模型减少了节点的内存占用(memory size), 这给面向对象的继承(object-oriented inheritance)打开了大门,后者能够提供某些 私有属性(private attributes),虽然它自身也有其他严重的问题。
4.7 对其他编程语言的影响
最近流行的一些编程语言都使用这种模型。这不仅包括各种现代 Lisp,还包括 Haskell、ML、Python、Ruby、PHP5、Lua、JavaScript、Erlang 以及 Smalltalk。
- 这些语言无一例外地都对内存中的对象类型(set of object types)进行了扩展, 不再仅仅是原来简单的
(cdr, car)对。 - 通常情况下,它们还至少包含了指针数组(arrays of pointers)和哈希表,后 者将字符串或指针映射到其他指针。哈希表尤其重要,如果一段运行中的代码使用了某实 体,在大部分情况下,哈希表都能提供一种在不影响代码正常运行的前提下,向这些实 体添加新属性(new properties)的能力。
- 其中一些语言还包括带标签的 union(tagged union)和不可变记录(immutable records)。
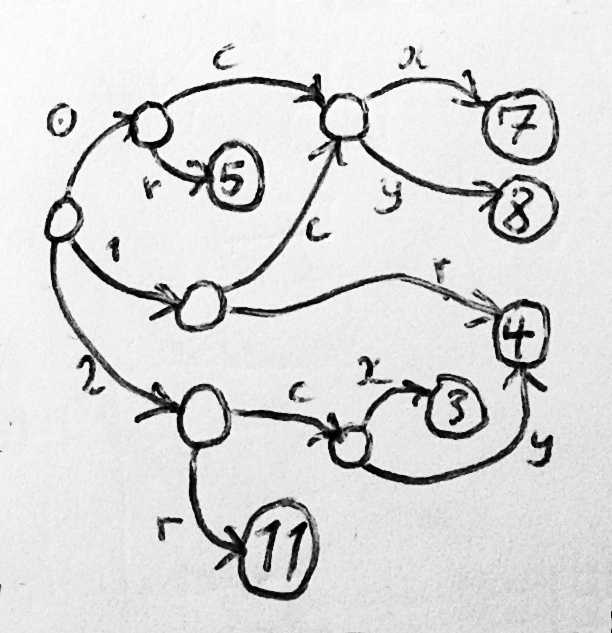
总的来说,在这些语言中,只能沿着图的边缘(graph edges)的指向行走,而且边缘标 签(edge labels)从源节点看是唯一的(一个 cons 只有一个 car,不会有两个或十个) ,但从目的节点看不是唯一的。
如果要求在源节点和目的节点看都是唯一的,那 Ted Nelson 的 ZigZag 数据结构是一个例子。UnQL,在某种程度上,是一次完全消除唯一性限 制的尝试(n exploration of eliminating the uniqueness constraint entirely)。
Java (和 C#)使用的是这种内存模型的一个细微变种:Java 内存中有 非指针类型的东西,称为 “primitive types”。这意味着无法在常规的容器类型( container types)中存储这些变量,虽然近些年 Java 极力试图掩盖这一缺陷。
5. FORTRAN 内存模型:并行数组 —— 内存是一系列数组
5.1 背景和特点
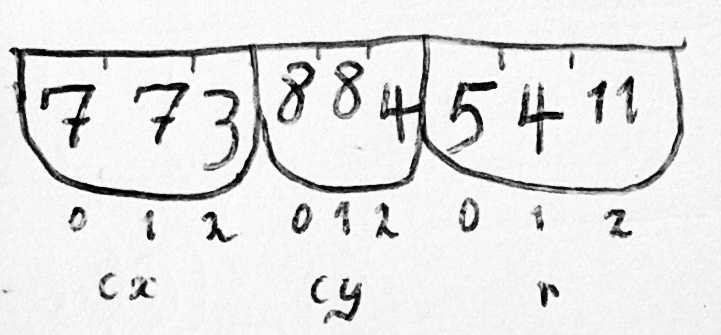
FORTRAN 是为物理现象的数值建模(numerical modeling of physical phenomena)设 计的,这是最早需要使用计算机的场景之一,通常称为“科学计算”(scientific computing)。
在当时,科学计算机(scientific computers)和商业计算机(business computers,使用 COBOL 编程)是有很大区别的,科学计算机的特点包括:
- 使用二进制(binary)而不是十进制(decimal)
- 没有 byte 的概念,只有固定长度 word(fixed-length words)
- 支持浮点数学
- 计算更快,但 I/O 较慢
通常,这些模型涉及到在很大的数值数组(large numerical arrays)之上的大量线性 代数运算(linear algebra),要求计算地越快越好,而这也正是 FORTRAN(后来称为 Fortran)的优化方向:高效地利用多维数组。
FORTRAN 不仅没有递归子过程、指针和记录,它最 初连子过程(subroutines)都没有!后来,我印象中是在 FORTRAN II 里,它才支持了参数 ,参数可以是数组,而这是 ALGOL 直到 ALGOL 60 还一直无法恰当实现的东西。
因为数组是唯一非基元类型(non-primitive type),因此数组元素唯一可能的类型就 是那些 primitive types,例如整数和浮点数。
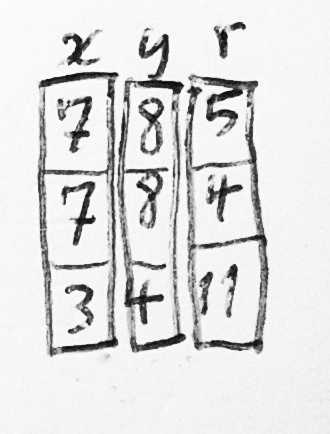
5.2 三种查找 middle-name 算法
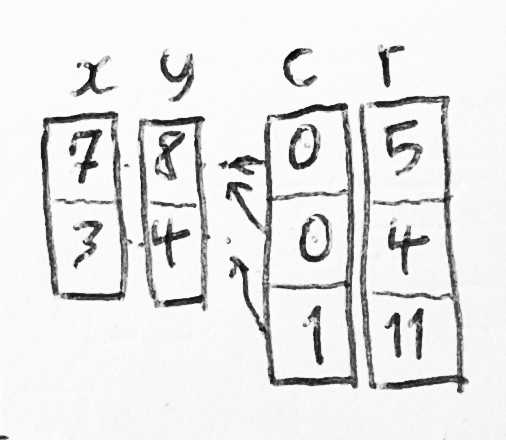
这个在 FORTRAN 世界中演进的并行数组(parallel-array)内存模型中,如果有同一类 型的多个实体,那任意一个实体都可以通过数组的一个整数偏移量(integer offset)来识别, 而访问一个特定实体的某个属性就是先通过一个偏移量在数组中找到该实体,然后在实体中 通过另一个偏移量找到这个属性。
如果时间暂时回退到 20 世纪 50 年代,我们有一个数组,其中存放的元素都是基元字符类 型(primitive character type),并且只使用并行数组这一种数据结构,那前面介绍的寻 找 account-holder 中的 middle name 的例子就能够用以下任意一种方式实现:
-
方式一(针对 account-holder 的各属性分别存储在独立数组中的场景,译者注)
IM = IMDNAM(ICCHLD(IACCTN)) IA = ISTR(IM) IE = ISTR(IM+1) # 基本思想就是先找到存储 middle-name 属性的数组,然后再找到这个账户的 # middle-name 成员在该数组中的起始地址和结束地址,译者注)在完成以上 4 次数组索引的查找操作(array-indexing operations)之后,
CCHARS字符数组的[IA, IE)区间对应的就是 account-holder 的 middle-name 了。 -
方式二(针对 account-holder 的属性没有存储在独立数组中的场景,译者注)
如果 account-holder 的属性没有存储在各自独立的数组中(很有可能),那可以这样 做:
IM = IMDNAM(IACCTN) IA = ISTR(IM) IE = ISTR(IM+1)后面两步和方式一相同。
-
方式三
使用
CMDNAM而不是IMDNAM,前者是一个Nx12的字符数组,每个 12-character 的列用于每个账户的 middle-name(with one 12-character column for the middle name of each account holder)。
5.3 并行数组内存模型
在这种内存模型中,对于作为参数传给子过程(subroutine)的数组或者共享数组,子过 程能够访问这些数组的任意位置(any index)的,能够随机地对其进行读或写操作,并 且没有次数限制。
这就是“可以用任何语言进行 FORTRAN 式编程”(programming FORTRAN in any language )表达的意思:几乎每种编程语言中都有数组(arrays of primitive types)。
- 即使是在汇编语言或 Forth 中,数组都不是很难构造。
- Awk、Perl4 和 Tcl 还额外提供了字典(dictionaries),虽然这些并不是一等对象( first-class objects),因为这些语言并不是对象图(object-graph)语言,但在对实 体的属性进行排序方面,这些字典完全可以取代数组,允许用字符串而不是数组(by strings instead of integers)来识别实体。
一个有趣的细节是,在简单的情况下,并行数组在机器层面产生的代码和嵌套记录模型( nested-record model)中通过指针引用的结构体成员产生的代码几乎是一模一样的。例 如,下面是 b->foo 产生的代码,其中 b 是一个指向结构体变量的指针,foo 是一 个 32 位的成员变量:
40050c: 8b 47 08 mov 0x8(%rdi),%eax
而下面是 foos[b] 产生代码,其中 b 是 32 位数组 foos 的一个索引(index):
400513: 8b 04 bd e0 d8 60 00 mov 0x60d8e0(,%rdi,4),%eax
以上两种情况下,这个代表某个属性的立即常量(immediate constant)都被加到一个存放 在寄存器中的变量上,最终的结果就是我们在寻找的的那个实体。机器码层面的唯一区别是 ,在第二种情况下,我们将索引乘以了元素大小(item size),因此这个常量会更大一些 。
另外需要注意,两者的指令格式是不同的,而且不是所有 CPU 架构都支持如此大的常 量偏移;在某些机器上,必须将数组的起始地址,或者某个足够大的结构体某字段偏移, 加载到一个寄存器中。
Adam N. Rosenberg 提倡永远用并行数组风格来编程 ,并且用一本书的厚度来解释为什 么应该这样做。我并不认为这一个好主义,但他是我见过的这种思想的最佳现代捍卫者。
5.4 优缺点
优点
简单来说,
- 并行数组是缓存友好的
- 支持不同属性有不同的可见度
- 支持设置 watchpoints
- 提供的序列是有意义的(provide a sequence that can be meaningful)
- 支持多维索引(属性可以是 entity tuple,而并不仅仅是单个 entity)
另外,并行数组还支持编写子过程来在属性之上进行抽象,因为它们在运行时才对每 个属性进行具体化:你可以写一个能够应用到任何属性的 sum 或 covariance 函数 — — 这一点尤其有趣:虽然并行数组不支持让某个特定实体对某段特定程序可见(private) ,但它支持让实体(变量)的某个 属性(attribute)是私有的(private)。
缺点
我不喜欢并行数组,因为它们非常容易导致错误。
- 编译器无法分辨数组的某个给定的索引是否合法,调试器和垃圾回收器也不能。
- 并行数组本质上容易导致类型错误(type error)—— 将某种类型的实体的某个标识 符存储在一个另一种类型的数组中 —— 相比于编译时错误消息或运行时错误消息,这种方 式会更容易导致错误(尤其是在没有打开数组范围检查的情况下)。
- 另外,由于并行数组在运行时具体化的是属性(attributes)而不是实体(entities), 因此创建和删除实体很容易出错,子过程倾向于有很多的参数(增加了抽象的 成本,导致子过程的实现变长)
- 与嵌套记录模型中类似的 arbitrary limits 问题(即对内存中数组的大小没有施加限制 ,可以为任意大小,见上文。译者注)。
并行数组的序列化非常容易和高效,尤其是如果你不考虑 CPU 架构间的可移植性;但是它 们一般是以属性为维度的,需要同时对涉及到的所有实体的某个属性进行序列化或反序 列化。
5.5 对其他编程语言的影响
Fortran 并不是唯一一种推荐用并行数组组织内存的语言。
- Octave、Matlab、APL、J、K、PV-WAVE IDL、Lush、S、S-Plus 和 R 很大程度上都是面 向并行数组(parallel-array-oriented)的编程语言
- Numpy、Pandas、和 OpenGL 是面向并行数组的库(parallel-array-oriented libraries)
- 我前面还提到,Perl4、awk、和 Tcl 在一定程度上也是面向并行数组的
以上提到的某些语言为了减少并行数组不一致(getting out of sync)的风险,将数 组设计为一旦创建就不可变的(immutable once populated),或者至少鼓励创建新数 组;Pandas、K 和 那些并行字典衍生语言(parallel-dictionary variant)减少类型错误 风险的方式是鼓励用非数值方式访问数组(index your arrays by things that aren’ t integers)。
在并行数组模型中,我们可以很方便地将对某个实体集合进行循环的操作封装到一个叶子函 数(leaf functions,即不会再调用其他自定义函数的函数),这可以降低解释开销( interpretation overhead),因此即使是在 1960s 年代的某个解释器上 APL 都可以做高 性能数值计算任务(high-performance numerical work)。
现代硬件的某些特性限制了并行数组取得更高的性能的可能性:CPU 和内存速度之间越来越 大的 gap、GPU 的 SIMT 架构、CPU(为了增加 ALU 硅片面积相比于控制硅片面积的比例而 增加的)SIMD 指令。最终,游戏程序员开始以“面向数据的设计”(data-oriented design)和(某种程度的)“实体系统”(entity systems)的名义回归到并行数组。 数值(科学)计算从未抛弃过并行数组。
6. 茶歇:为什么没有 Lua、Erlang 和 Forth 内存模型?
以上就是对应以下三种基本数据结构的三种内存模型:
- 记录(record)
- 链表(linked list)
- 数组(array)
但是,有几种其他的数据类型也是适用范围非常广泛的:
- Lua 以有限映射表(finite maps)的方式组织内存;也叫字典(dictionaries),Lua 中称为 “tables”
- Erlang 基于主动无共享进行模型(active shared-nothing processes),将每个进 程的消息放到各自的消息队列,这其实是 Hewitt 和 Agha 的 actor 模型的一个变种
- Forth 基于栈(stack)组织
那么,为什么没有 Lua、Erlang 和 Forth 内存模型?我其实也不知道为什么。
- Lua 和 Erlang 本质上是面向对象图(object-graph oriented)的语言
- Forth 程序经常只使用并行数组,虽然 Forth dictionary 是链表(linked list) 的一 个变种
- 也许你可以构建一个系统,其中程序的内存视角是一个哈希表,或者某种类型的 actor 变种(而不是对象图),或者两个或更多个栈。Linda 是这样的一次探索,它在 actor 之间通过一个 tuple space 进行非图结构的通信(non-graph-structured communication ),也许这可以进一步扩展成一门完整的语言
但本文不会就此深入展开,而是再来看其他几种已有的重要内存模型。
7. 磁带内存模型:管道 —— 写入、等待数据、继续写入
7.1 管道
Unix 管道(pipe)在所有内存模型中是最简单的(而且这些管道都是模拟相应的硬件 )。管道支持的唯一几个操作是:
- 写一个字节(或者,某些管道允许写多个字节,算是一种优化)
- 读一个字节
除此之外可能还包括关闭操作(从任何一端)。(真实的磁带读写都是以块为单位,但我们 这里不考虑这种情况)。通常情况下,不会在同一个程序中同时读和写同一个管道。
事实证明,这种只能追加(append-only)的存储对某些算法来说完全足够了; MapReduce 的工作方式不会比这种方式复杂多少,其他的,比如典型的令牌化问题( tokenization with lex)使用的就是这样一个最简接口作为它的输入。
Python 的迭代器(iterators )和生成器(generators)、C++ STL 的前向迭代器( forward iterators)、D 语言的 forward ranges,以及 Golang 的 channel 都是这种管道或 channel 的例子,它们都是纯顺序化的数据访问。
7.2 例子:示例语言 + 管道实现合并排序
如果一种编程语言的内存模型完全基于管道,那将会是什么样子?需要有从管道中读取 数据元素(可能都只能是 primitive 类型的数据)和将数据元素写入管道的操作。考虑我 们在文章开头定义的示例编程语言。给定管道和 empty、get 和 put 子过程,我们就 可以写一个 merge 函数,用于合并排序(merge sorting),虽然这样的实现并没有 Python 或其他语言更方便。
def merge(in1, in2, out) {
have1 := 0;
have2 := 0;
while !empty(in1) || !empty(in2) {
if 0 == have1 && !empty(in1) {
val1 := get(in1);
have1 := 1;
}
if 0 == have2 && !empty(in2) {
val2 := get(in2);
have2 := 1;
}
if 0 == have1 {
put(out, val2);
have2 := 0;
} else {
if 0 == have2 || val1 < val2 {
put(out, val1);
have1 := 0;
} else {
put(out, val2);
have2 := 0;
}
}
}
}
注意上面的函数,以及会用到这个函数的 mergesort 函数(我太懒当前还不想写),这 里唯一的几条假设是:
- 有至少四个管道
- 每个管道有足够的空间用于存储数据
- 函数能区分这些管道
该函数不需要创建、删除管道或通过管道传递管道(pass pipes through pipes);in1 、out 等等参数,不必是某种类型的一等管道对象(first-class pipe object),它们 可以只是数值类型。(事实上这就是 Unix 程序如何处理 Unix 管道的:使用文件描述符 索引。)或者,它们也可以是可以作为参数传递的一等管道对象,但不能通过管道传递管 道。
设想一个多线程的控制流系统:在其中可以 fork 出不同的线程,线程读取空的流( empty stream)时会阻塞,直到有数据到来。在这个系统里,你必须得使用管道而不是数组 或记录,而且可能必须得为每个属性使用一个流。运行时会调度不同的管道处理线程( pipe-processing threads),可能会将它们分散到不同机器上执行。
7.3 π-calculus:是使用管道的内存模型
在某种程度上,π-calculus 是一种只使用管道的语言;它是一种面向 channel 的并发 语言(concurrent channel-oriented alternative),与 λ-calculus 类似。
按照 Jeannette Wing 的解释,用 P 和 Q 表示两个进程。那么:
P | Q表示一个由 P 和 Q 组成的进程,其中 P 和 Q 并行运行(running in parallel)a(x).P表示一个等待从 channela中读取一个值x的进程;读取到x之 后,该进程接下来的行为与进程 P 一样(behaves like P)ā〈x〉.P表示一个等待在 channela中发送一个值x的进程;在x被对 方接收之后,该进程接下来的行为与进程 P 一样(behaves like P)(νa)P保证a是 P 中的一个新 channel(希腊单词 nu 表示 new)!P表示 P 的无限次拷贝,这些拷贝都在并行运行P + Q表示一个行为与 P 或 Q 一样的进程(behaves like either P or Q)0表示什么都不做的进程(inert process that does nothing)
她给出的示例 π-calculus 代码是:
!incr(a, x).ā〈x+1〉 | (νa)( i̅n̅c̅r̅〈a, 17〉 | a(y) )
!incr(a, x).ā〈x+1〉 解释如下:
!P创建了一个有无数个进程的服务程序(server),这里P就是incr(a, x).ā〈x+1〉- 每个进程监听在 channel
incr上,等待接收一条消息;收到消息后会将其分别赋给a和x两个变量 - 在 channel
a上将x+1发送出去,然后进程终止
同时,还有两个与此并行运行的进程(i̅n̅c̅r̅〈a, 17〉 和 a(y)):
- 这两个进程共享一个名字为
a的新 channel - 其中一个进程在 channel
incr上发送 channela和数值 17 - 另一个进程在 channel
a上等待接收数据,收到后将其绑定到变量 y
π-calculus 可能不会成为一门实用的编程系统,其他与此类似的进程代数(process calculi)也不会。但是,它至少说明了只使用管道作为内存模型是有可能的。但也 要注意,以上版本其实用到了元组(tuple)和进程间的关系图(labeled graphs of processes)!如果不用这两个特性,我不确定这门语言的通用性还能剩多少。
7.4 其他基于管道的尝试
基于流的编程(Flow-based programming),例如 NSA 项目 Apache NiFi,是另一种 对 Unix 管道和过滤器(pipes-and-filters)进行通用化的尝试方式。
8. MULTICS 内存模型:目录 —— 内存是一棵树
Directories, the Multics memory model: memory is a string-labeled tree with blob leaves。
8.1 模型特点(目录树模型 vs 对象图模型)
Unix(或 Windows、MacOS、Multics)层级文件系统是另一种内存组织方式。
这种方式通常是是由 spinning rust(TODO?)组成的持久内存,shell 脚本尤其大量使用 这种内存模型。
从基本形式上说,这种内存模式是在对象图模型(object-graph model)的基础上加了一 些限制得到的:
- 其中的每个节点都有一个唯一的父节点
- 每个节点要么是一个目录(directory),要么是一个常规文件(regular file)
- 目录是一个用字符串作为 key 索引的字典,其中存放了指向子节点的链接
- 常规文件是一个可变对象(mutable blob),其中存储了字节序列
一个重要的不同是添加了第三种节点类型:符号链接(symbolic link),这是一个可 跟踪的路径(a path to follow),可以从 root 或其父目录开始跟踪,来找到期望的节 点 —— 如果这个节点存在。
8.2 序列化和反序列化
典型情况下,在一个层级文件系统中要表示一个实体的属性,需要将这些属性(连同 其他一些实体)序列化(serialize)到一个常规文件中。但这样做的大部分原因是:系 统调用的接口太慢太笨重了;另外就是每个节点的开销比较大,通常情况下在几百字节这样 的级别。与此相比,你完全可以为每个实体使用一个目录,将它的每个属性都存储到这个目 录中的一个单独文件中,例如属性 x 存储到名为 x 的文件中。Unix 就是用这种方式存 储某些信息的,例如用户信息(information about users),或者软件包的版本信息, 或者如何编译不同的软件包的信息。
这种有唯一父节点的特性使得序列化和反序列化变得相对比较直接。
8.3 局部变量
对于局部变量,层级文件系统的做法比较折中(occupies a middle ground)。
典型情况下 ,任何节点都可以通过遍历这个树访问到,但我们相当确定,当前在文件系统的某部分运行 的软件不会注意到文件系统的另一个部分中新加入的文件;而且,在大部分情况下,可以在 不破坏已经在运行中的软件的情况下,向目录里添加新文件,虽然这一点是没有保证的。
8.4 对其他编程语言或系统的影响
有很多的编程系统或多或少就是以这种方式工作的。
- MUMPS,一个仍然运行在美国退伍军人管理局(US Veteran’s Administration)的系统, 或多或少就是这样工作的(虽然典型的“文件”会限制在 4096 字节以内,并且一个节点可 以同时是目录和常规文件)。
- IBM 的 IMS database 也是一个仍然在广泛使用的系统,其数据模型也与此非常相似; 其中的节点称为 “segments”,每个数据库上会有一个 schema。
- 另外,几年之前,Mark Lentczner 开始基于这种内存模型开发一个名为 Wheat 的现代面向对象编程环境,作为 PHP 之外的 web app 编程环境;我个人对此是有点喜欢的。
In Wheat, each function’s activation record is a “directory”, with its variables as (dynamically typed, rather than blob) “files” in it. Some subtrees of the “filesystem” are persistent, but not others; access to remotely hosted data is transparent. Essentially, Wheat sought to eliminate the impedance mismatch between the persistent, hierarchically-named, globally-accessible resources of the Web, and the program’s own conception of memory.
9. SQL 内存模型:关系 —— 内存是一个可变、多值有限函数集
某种程度上说,这是所有内存模型中最抽象的。
9.1 多值函数
“多值函数”(multivalued function)在数学中通常称为“关系”(relation)。,例如 :
cos是一个函数:对于任何θ,cos(θ)都是一个唯一的、定义良好的值cos⁻¹是一个关系:cos⁻¹(0.5)对应多个值 —— 虽然我们通常会将它转换成一 个函数,只取其中的一个值
可以将 cos 认为是一系列有序 pair 的集合,例如 (0, 1), (π/2, 0), (π, -1), (3π/2, 0) 等等,因此逆操作(inversion operation)就是 将 pair 内的两个数字反转的过程:(1, 0), (0, π/2), (-1, π), (0, 3π/2) 等等。
我们这里要考虑的关系(relation)要比二值关系(binary relation)更宽泛:相比于 2-tuple 集合,我们要考虑的是 n-tuples 集合,其中 n 是某个整数。例如考虑 (θ, cos(θ), sin(θ)) 这个 3-tuple,其中 θ 是角度:(0, 1, 0), (π/2, 0, 1), (π, -1, 0)等等。
大部分关系编程系统(systems for relational programming)只对无限关系(infinite relations,例如 cos)进行有限的支持(limited support),因为这种情况下很容易构造 出不可解的问题(undecidable problems)。
9.2 sqlite 例子
举个具体的例子,下面是我的 Firefox 安装之后,permissions.sqlite 表中的一部分内 容:
sqlite> .mode column
sqlite> .width 3 20 10 5 5 15 1 1
sqlite> select * from moz_hosts limit 5;
id host type permi expir expireTime a i
--- -------------------- ---------- ----- ----- --------------- - -
1 addons.mozilla.org install 1 0 0
2 getpersonas.com install 1 0 0
5 github.com sts/use 1 2 1475110629178
9 news.ycombinator.com sts/use 1 2 1475236009514
10 news.ycombinator.com sts/subd 1 2 1475236009514
对于关系模型(relational model),这里的每一列在某种程度上都是主键(primary key)的一个函数,而这里的主键就是 id 这一列;因此,可以说:
host(1)就是addons.mozilla.orghost(2)就是getpersonas.comtype(5)就是sts/use
在这里的实现中,这是一张哈希表。
但是,这里与常规的函数式编程(functional programming)不同的地方在于:可以进 行逆操作 —— 除了可以访问 host(9),还可以访问 host⁻ ¹('news.ycombinator.com'),后者得到的结果就是多个值(multivalued):
sqlite> select id from moz_hosts where host = 'news.ycombinator.com';
id
---
9
10
另外,你还可以将这些多值函数进行更复杂的组合:
sqlite> .width 0
sqlite> select min(expireTime) from moz_hosts where host = 'news.ycombinator.com';
min(expireTime)
---------------
1475236009514
9.3 SQL 模型
通常情况下,要在 SQL 中表示一个实体,需要表中的一行(a row in a table),也就是 关系中的一个元组(a tuple in a relation);要表示它和其他实体的关系,需要用某些 唯一的属性集合来标识出这些实体,这个属性集合称为键(key),例如前面的表 中的 id,然后在其他实体的某个列中包含这个实体的键。
现在回到我们前面的银行账户 middle name 的例子,在这里就可以表示成:
select accountholder.middlename
from accountholder, account
where accountholder.id = account.accountholderid
and account.id = 3201
或者可以将最后一行去掉,这样得到的就不是一个账户的 middle name,而是所有账户的 middle name。
SQL 并不是关系型模型(relational model)的唯一实现,但到目前为止,它是最流行的实 现。另外,SQL 最近无意间变成了图灵完备(Turing-complete)的 ,因此原理上 SQL 是可 以接管整个世界的。
与真正意义上的编程语言,例如 Lisp、FORTRAN 和 C 相比,这种模型看上去并不属于同一个 范畴,这是因为 SQL 作为一个编程语言更多的是出于好奇而不是实用目的。但是,再考虑 一下文章开头给出的示例编程语言。如果对这个示例语言进行扩展,支持 SQL 声明、 将原生类型的结果存储到变量、对结果集合进行迭代,那它就会成为一个可用的编程系统 — — 虽然会是一个不够灵活的系统。(实际上,我描述的这门示例语言或多或少就是 PL/SQL。)
这不是说要改变这门语言中的类型(denoted or expressed types)。即使这门语言仍然只 能将数值当做变量或表达式值处理,只要它能够将这些数值存储到关系中,并且能通过查询 再将它们取出来,那这门语言的处理能力也会得到巨大提升。
9.4 SQL 优缺点
SQL 也有一些限制:
- 表名(table names)在一个全局 namespace 中,行和列都是全局可访问的(你无法创建 私有列或行,虽然在某种意义上说,每次查询得到的结果都是一张私有表,可以作为私有 行和列使用)
- 每列通常情况下只能 hold primitive 数据类型,例如数值和字符串(至少现代数据库已 经不再像 COBOL 一样只支持固定宽度的字符串了)
- 经常运行非常慢(painfully slow)
从某个角度看,SQL 操作,以及它的优缺点,和并行数组非常相似:
for (int i = 0; i < moz_hosts_len; i++) {
if (0 == strcmp(moz_hosts_host[i], "news.ycombinator.com")) {
results[results_len++] = moz_hosts_id[i];
}
}
或者,下面的例子更清晰地展示了 SQL 如何节省了你写算法的 effort,用并行数组实现一 个 sort-merge join 非常难于维护,而用 SQL:
select accountholder.middlename
from accountholder, account
where accountholder.id = account.accountholderid
如果用 C 语言和并行数组来实现同样的功能:
int *fksort = iota(account_len);
sort_by_int_column(account_accountholderid, fksort, account_len);
int *pksort = iota(accountholder_len);
sort_by_int_column(accountholder_id, pksort, accountholder_len);
int i = 0, j = 0, k = 0;
while (i < account_len && j < accountholder_len) {
int fk = account_accountholderid[fksort[i]];
int pk = accountholder_id[pksort[j]];
if (fk == pk) {
result_id[k] = fk;
result_middle_name[k] = accountholder_middlename[pksort[j]];
k++;
i++; // Supposing accountholder_id is unique.
} else if (fk < pk) {
i++;
} else {
j++;
}
}
free(fksort);
free(pksort);
这里 iota 的实现是:
int *iota(int size) {
int *results = calloc(size, sizeof(*results));
if (!results) abort();
for (int i = 0; i < size; i++) results[i] = i;
return results;
}
sort_by_int_column 或多或少可以实现如下:
void sort_by_int_column(int *values, int *indices, int indices_len) {
qsort_r(indices, indices_len, sizeof(*indices),
indirect_int_comparator, values);
}
int indirect_int_comparator(const void *a, const void *b, void *arg) {
int *values = arg;
return values[*(int*)a] - values[*(int*)b];
}
SQL 背后的实现使用了很多技巧,牺牲了简单查询的效率,但提高了复杂查询的效率, 而用户程序看到的抽象是一样的。
9.5 评论:抽象层次
人们经常说 SQL 是一门声明式语言(declarative language):不需要说明应该如何计算 结果(how a result is computed),只需要说明你希望的结果是什么(what result is desired)。 我认为这种观点只是部分正确,而且语言并不是只能分为声明式(declarativeness)或非 声明式两种,这涉及的是描述的抽象层次(level of abstraction of the description) ,而这是一个无限连续体(infinite continuum)问题,如果只是出于性能原因,那些低于 这个抽象层次但很实用的考虑一定会不可避免的侵入进来。
也许更有趣的是,Prolog 和 miniKANREN 实现了关系型模型(虽然二者的实现并不纯粹 ),它们将关系型编程和对象图(object-graph)递归数据结构结合起来,取得了真正令 人惊叹的能力。例如,一个非常简单的 miniKANREN 程序可以在一个合理的计算时间内, 生成无限多个输出自身源代码的程序(quines)。
广义的有约束编程(constraint programming)领域中,只需指定期望的结果的一些特性(结 果必须满足的“约束”),然后系统会承担寻找答案的任务,由于 SAT 和 SMT solvers 近些 年取得的巨大进步,这个领域正在取得长足的发展。
10 注释
- 《Essentials of Programming Languages》 建议分析编程语言时,首先要看它可 以表示什么类型的变量,以及可以对什么类型的表达式求值,这比仅仅分析其语法要有 用的多,但是我认为这很大程度上忽略了更深层次的东西。
- 我将其称为六种 “内存模型”,即使这个术语过去指的是 C 语言中与 8086 寻址模 式相关的一个东西,而与本文所描述的内容关系不大(我倒是很希望为本文描述的东西 找一个更好的术语)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号