
大数据数据库应用技术测试----词云图
基于中文新闻分词绘制词云图
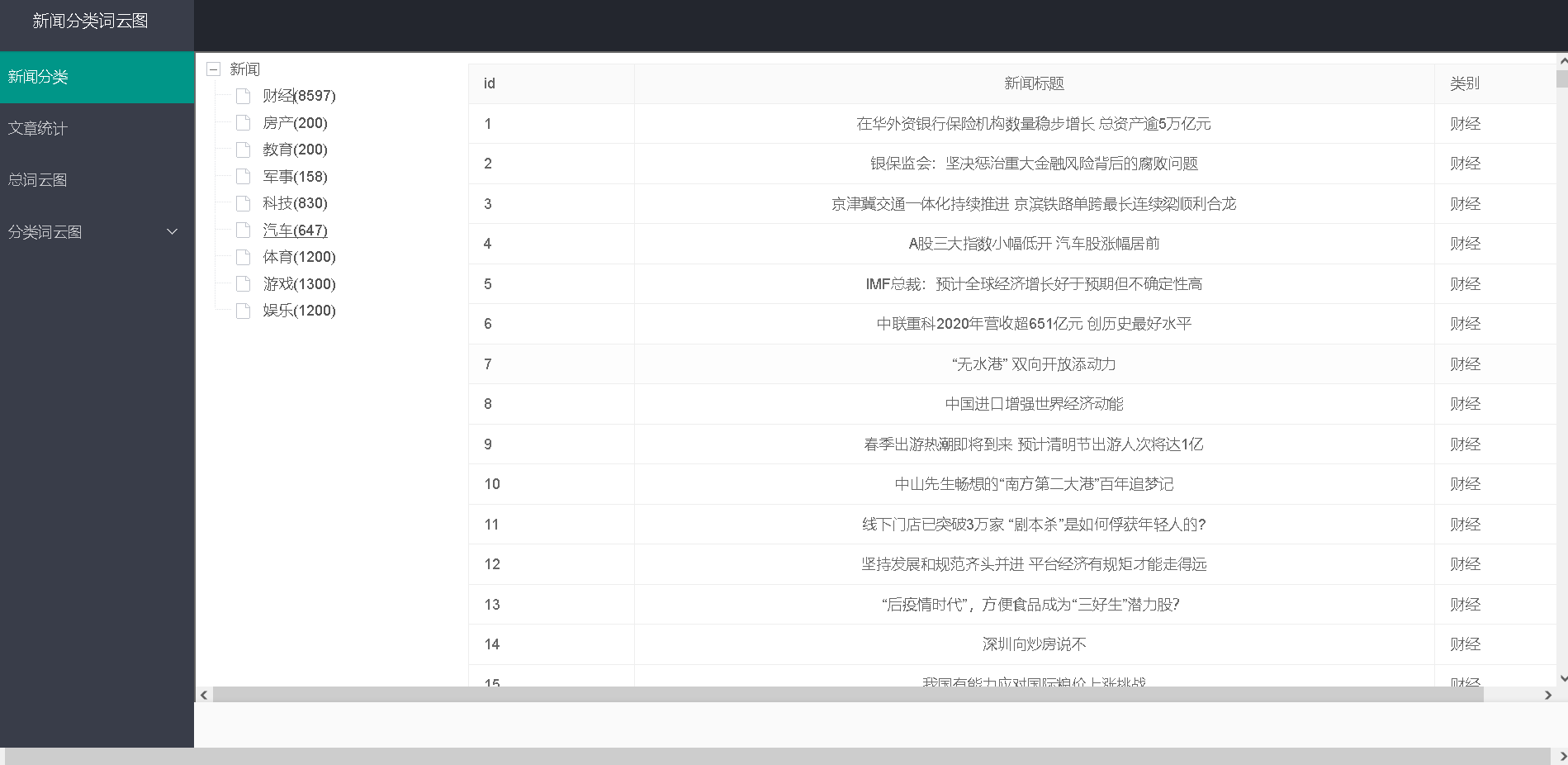
1、数据导入展示:
将所有类别的新闻导入数据库中。以树形目录形式展示新闻类别,每个树形节点代表
新闻分类,括号中代表该类新闻的数量,选择每个新闻,以列表形式显示新闻标题,点击新
闻标题,可以查看详细信息。
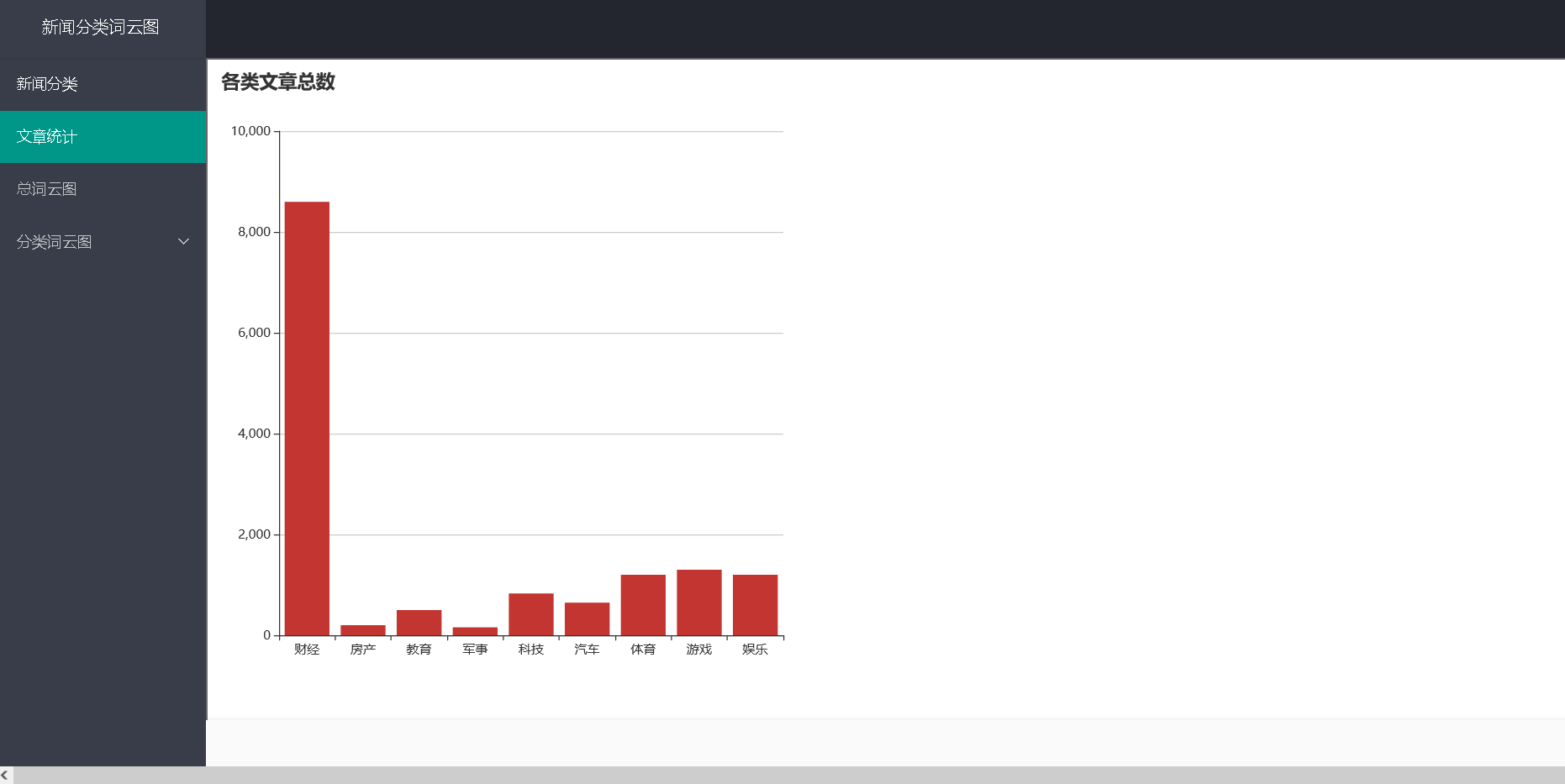
2、文章统计:
统计各个类别的文章总数,以柱状图表示。
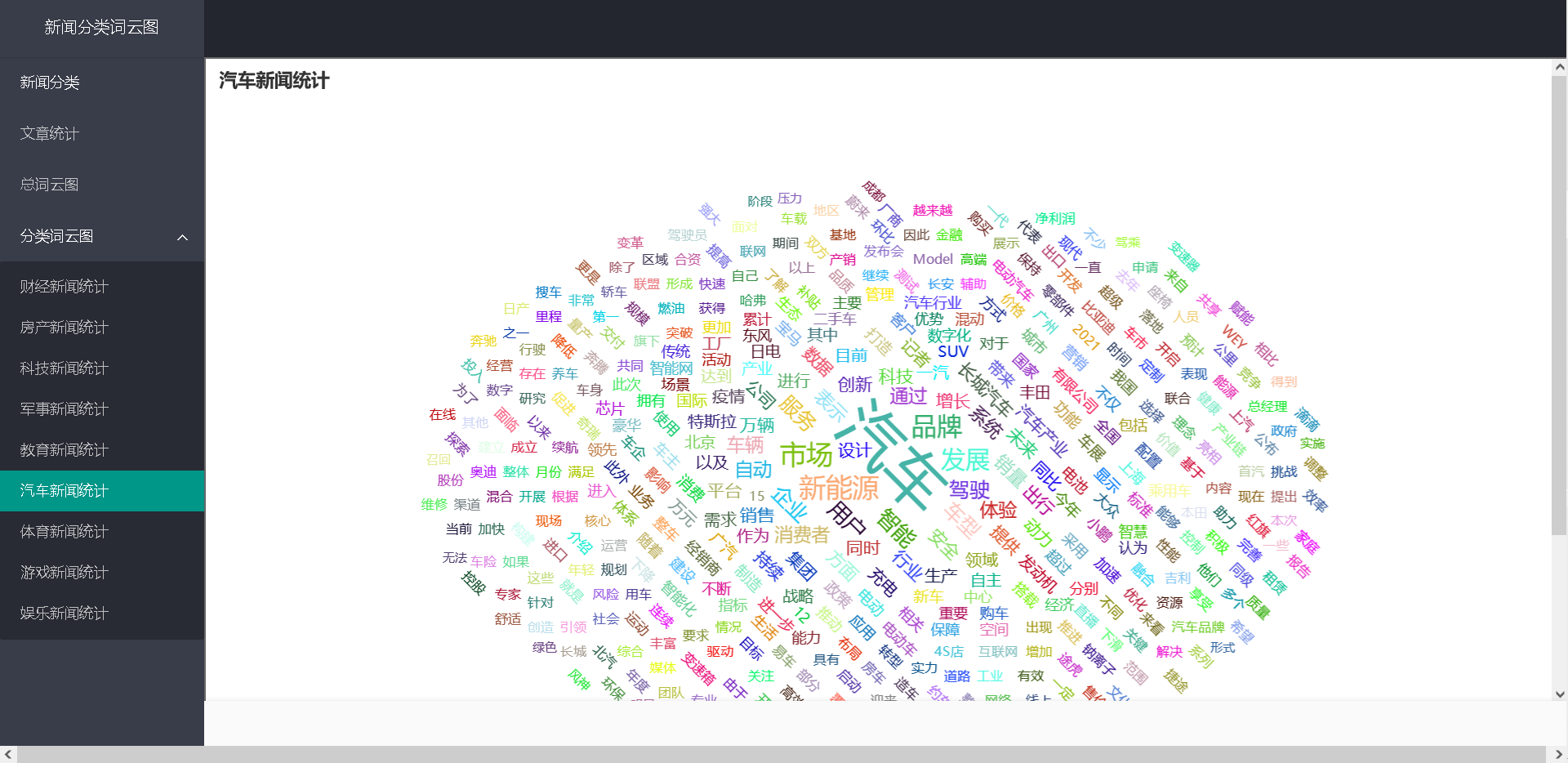
3、文章分词:
使用中文分词算法解析所有新闻正文,并统计每个词语出现的数量,并以词云图的方
式展示,点击词云图中该词语,显示其数量。
4、选择某一类文章,绘制该类型新闻文章词云图,例如汽车类新闻词云图。
测试结果:
1.
2.
3.

4.
先分享使用python进行分词的代码:
import jieba
import pandas as pd
import re
from collections import Counter
import pymysql
import xlwt
import csv
if __name__ == '__main__':
file_ob=open('E:\大三上\软件需求\ceshi02/main.csv',encoding='utf-8').read().split('\n')
file = open("final_hotword2.txt", "w", encoding='utf-8');
filepaixu = open("main.txt", "w", encoding='utf-8');
rs2=[]
dbinserthot = []
for i in range(len(file_ob)):
result=[]
seg_li=jieba.cut(file_ob[i])
for w in seg_li:
result.append(w)
rs2.append(result)
c = Counter()
stopwords = {}.fromkeys([line.rstrip() for line in open(r'final.txt', encoding='UTF-8')])
for seg_list in rs2:
for x in seg_list:
if x not in stopwords:
if len(x) > 1 and x != '\r\n' and x != 'quot':
c[x] += 1
print('\n词频统计结果:')
for (k, v) in c.most_common(1000): # 输出词频最高的前两个词
print("%s:%d" % (k, v))
file.write(k + '\n')
filepaixu.write(k + "," + str(v) + '\n')
value = [k, str(v)]
dbinserthot.append(value)
tuphot = tuple(dbinserthot)
db = pymysql.connect(host="localhost", user="root", password="1229", database="newfc", charset='utf8')
cursor = db.cursor()
sql_hot = "INSERT INTO mainTu values(%s,%s)"
try:
cursor.executemany(sql_hot, tuphot)
db.commit()
except:
print('执行失败,进入回调3')
db.rollback()
db.close()
file=open('G:\Python程序\ceshi\st.txt','w',encoding='utf-8')
file.write(str(rs2));
file.close()
词云图的项目后续后上传到GitHub中
