
每日学习(算法练习和HDFS)
今天学习了HDFS的一些基本理论知识:
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目
录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务
器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭
之后就不需要改变。
HDFS的优缺点:
优点:
高容错性
适合大规模数据
可构建在廉价机器上。
缺点:
不适合低延时数据访问,不能做到像mysql那样的快速。
无法高效的对大量小文件进行存储
不支持并发写入、文件随机修改。
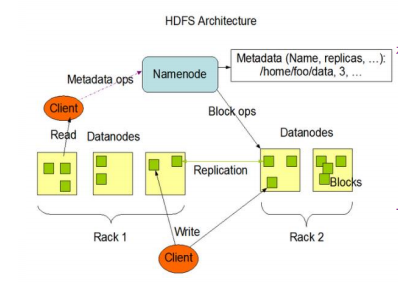
HDFS的组成架构:
NameNode(nn):就是Master,它
是一个主管、管理者。
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端读写请求。
DataNode:就是hadoop2.x叫Slave(3.x叫workers)。NameNode
下达命令,DataNode执行实际的操作。
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
Client:就是客户端。
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如NameNode格式化;
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
Secondary NameNode:并非NameNode的热备(即不能马上就替换上)。当NameNode挂掉的时候,它并不
能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
(2)在紧急情况下,可辅助恢复NameNode。
HDFS的文件块大小:取决于磁盘传输速率,一般是磁盘100mb/s,所以文件块大小默认是128mb
而固态磁盘可以到达200-300mb/s,可以将文件块设置为256mb。
算法练习:
1. 编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
每行中的整数从左到右按升序排列。
每行的第一个整数大于前一行的最后一个整数。
题目来自LeetCode
答:
二维数组是有规则的,每一行都是升序的,所以只需要比较target与每一行的头与尾元素,来确定target可能处于哪一行
matrix.length是行数,matrix[i].length是列数,所以只需要先进行可能所处行的判断,之后在具体行内进行判断
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
boolean p=false;
for(int i=0;i<matrix.length;i++)
{
if(matrix[i][0]<=target&&matrix[i][matrix[i].length-1]>=target)
{
for(int j=0;j<matrix[i].length;j++)
{
if(matrix[i][j]==target)
{
p=true;
break;
}
}
break;
}
}
return p;
}
}
2.
整数数组 nums 按升序排列,数组中的值 互不相同 。
在传递给函数之前,nums 在预先未知的某个下标 k(0 <= k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k+1], ..., nums[n-1], nums[0], nums[1], ..., nums[k-1]](下标 从 0 开始 计数)。例如, [0,1,2,4,5,6,7] 在下标 3 处经旋转后可能变为 [4,5,6,7,0,1,2] 。
给你 旋转后 的数组 nums 和一个整数 target ,如果 nums 中存在这个目标值 target ,则返回它的下标,否则返回 -1 。
题目来自LeetCode
答:
通过研究题目可以知道数组是有规则的,原数组是升序的,且值各不相同,在旋转后可以将数组分为两部分,两部分由某一下标k分割。一部分是以某一下标k开始的,一部分是0- k-1,因此只需要比较target同旋转后数组第一个元素的值,即同原数组下标为k的元素进行比较,大于则顺序进行比较,小于则反向比较,相比直接比较可以更加省时间。
class Solution {
public int search(int[] nums, int target) {
int p=-1;
if(nums[0]>=target)
{
for(int i=0;i<nums.length;i++)
{
if(nums[i]==target)
{
p=i;
break;
}
}
}
else
{
for(int i=nums.length-1;i>0;i--)
{
if(nums[i]==target)
{
p=i;
break;
}
}
}
return p;
}
}
3. 已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums = [0,1,2,4,5,6,7] 在变化后可能得到:
若旋转 4 次,则可以得到 [4,5,6,7,0,1,2]
若旋转 7 次,则可以得到 [0,1,2,4,5,6,7]
注意,数组 [a[0], a[1], a[2], ..., a[n-1]] 旋转一次 的结果为数组 [a[n-1], a[0], a[1], a[2], ..., a[n-2]] 。
给你一个元素值 互不相同 的数组 nums ,它原来是一个升序排列的数组,并按上述情形进行了多次旋转。请你找出并返回数组中的 最小元素 。
题目来自LeetCode
答:
由题可以知道,每一次旋转都是将旋转的元素提取到数组第一位,因此如果数组若进行了旋转且并未旋转至等同于原数组,那么最小的元素必然是小于其前一个元素,因为数组是升序的,且旋转后被提取到数组前面的也是升序的,最小的元素之后也是升序的,所以最小的元素必然会小于其前一个元素,特殊情况:未旋转,或刚好旋转至原数组排序没有变化,这种情况只需要设置初始p为nums[0]。
class Solution {
public int findMin(int[] nums) {
int p=nums[0];
for(int i=0;i<nums.length-1;i++)
{
if(nums[i]>nums[i+1])
{
p=nums[i+1];
}
}
return p;
}
}
明天会继续学习大数据和算法,会继续做信息热词分类分析
