Scrapy使用详细记录
这几天,又用到了scrapy框架写爬虫,感觉忘得差不多了,虽然保存了书签,但有些东西,还是多写写才好啊
首先,官方而经典的的开发手册那是需要的:
https://doc.scrapy.org/en/latest/intro/tutorial.html
一、创建项目
命令行cd到合适的目录:
scrapy startproject tutorial
就新建了一个tutorial的项目,项目的结构如下:
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
这里还会提示需不需要帮你创建一个新的爬虫文件,随意了
初步使用官方教程 我就不详细说了
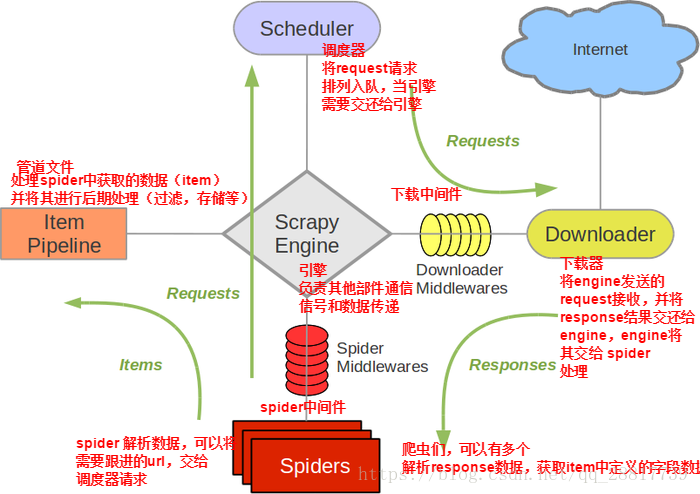
二、各种组件介绍
scrapy.sfg
以我现在理解是,部署项目发布相关的东西,比如在使用scrapyd发布时需要用到,其余时候不用动它
items.py
这里是用来计划你需要哪些数据的,比如爬虫需要保存4个值:


import scrapy class Product(scrapy.Item): name = scrapy.Field() price = scrapy.Field() stock = scrapy.Field() last_updated = scrapy.Field(serializer=str)
middlerwares.py
爬虫中间件是使用非常多的,比如需要为每个请求设置随机User-Agent
代码如下,需要在settings.py中准备好ua数据,或者其他方式读取进来也行
USER_AGENTS = [ "Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5", "Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7", "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1", "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7", "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10", "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-GB; rv:1.9.0.11) Gecko/2009060215 Firefox/3.0.11 (.NET CLR 3.5.30729)", "Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6 GTB5", "Mozilla/5.0 (Windows; U; Windows NT 5.1; tr; rv:1.9.2.8) Gecko/20100722 Firefox/3.6.8 ( .NET CLR 3.5.30729; .NET4.0E)", "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:2.0.1) Gecko/20100101 Firefox/4.0.1", "Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0a2) Gecko/20110622 Firefox/6.0a2", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:7.0.1) Gecko/20100101 Firefox/7.0.1", "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:2.0b4pre) Gecko/20100815 Minefield/4.0b4pre", "Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0 )", "Mozilla/4.0 (compatible; MSIE 5.5; Windows 98; Win 9x 4.90)", "Mozilla/5.0 (Windows; U; Windows XP) Gecko MultiZilla/1.6.1.0a", "Mozilla/2.02E (Win95; U)", "Mozilla/3.01Gold (Win95; I)", "Mozilla/4.8 [en] (Windows NT 5.1; U)", "Mozilla/5.0 (Windows; U; Win98; en-US; rv:1.4) Gecko Netscape/7.1 (ax)", "HTC_Dream Mozilla/5.0 (Linux; U; Android 1.5; en-ca; Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", "Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.2; U; de-DE) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/234.40.1 Safari/534.6 TouchPad/1.0", "Mozilla/5.0 (Linux; U; Android 1.5; en-us; sdk Build/CUPCAKE) AppleWebkit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", "Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 2.2; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Linux; U; Android 1.5; en-us; htc_bahamas Build/CRB17) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", "Mozilla/5.0 (Linux; U; Android 2.1-update1; de-de; HTC Desire 1.19.161.5 Build/ERE27) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Linux; U; Android 1.5; de-ch; HTC Hero Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", "Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Linux; U; Android 2.1; en-us; HTC Legend Build/cupcake) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 1.5; de-de; HTC Magic Build/PLAT-RC33) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1 FirePHP/0.3", "Mozilla/5.0 (Linux; U; Android 1.6; en-us; HTC_TATTOO_A3288 Build/DRC79) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", "Mozilla/5.0 (Linux; U; Android 1.0; en-us; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2", "Mozilla/5.0 (Linux; U; Android 1.5; en-us; T-Mobile G1 Build/CRB43) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari 525.20.1", "Mozilla/5.0 (Linux; U; Android 1.5; en-gb; T-Mobile_G2_Touch Build/CUPCAKE) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", "Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 2.2; en-us; Droid Build/FRG22D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Linux; U; Android 2.0; en-us; Milestone Build/ SHOLS_U2_01.03.1) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 2.0.1; de-de; Milestone Build/SHOLS_U2_01.14.0) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2", "Mozilla/5.0 (Linux; U; Android 0.5; en-us) AppleWebKit/522 (KHTML, like Gecko) Safari/419.3", "Mozilla/5.0 (Linux; U; Android 1.1; en-gb; dream) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2", "Mozilla/5.0 (Linux; U; Android 2.0; en-us; Droid Build/ESD20) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 2.1; en-us; Nexus One Build/ERD62) AppleWebKit/530.17 (KHTML, like Gecko) Version/4.0 Mobile Safari/530.17", "Mozilla/5.0 (Linux; U; Android 2.2; en-us; Sprint APA9292KT Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Linux; U; Android 2.2; en-us; ADR6300 Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Linux; U; Android 2.2; en-ca; GT-P1000M Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1", "Mozilla/5.0 (Linux; U; Android 3.0.1; fr-fr; A500 Build/HRI66) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13", "Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/525.10 (KHTML, like Gecko) Version/3.0.4 Mobile Safari/523.12.2", "Mozilla/5.0 (Linux; U; Android 1.6; es-es; SonyEricssonX10i Build/R1FA016) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", "Mozilla/5.0 (Linux; U; Android 1.6; en-us; SonyEricssonX10i Build/R1AA056) AppleWebKit/528.5 (KHTML, like Gecko) Version/3.1.2 Mobile Safari/525.20.1", ]
# 随机User-Agent class RandomUserAgentMiddleware(object): def __init__(self, agents): """接收从from_crawler传的List-agents""" self.agents = agents @classmethod def from_crawler(cls, crawler): """从settings读取USER_AGENTS,传参到构造函数""" return cls(crawler.settings.getlist('USER_AGENTS')) def process_request(self, request, spider): """修改每一个request的header""" request.headers.setdefault('User-Agent', random.choice(self.agents))
最后一定要在settings.py中配置,才会生效
DOWNLOADER_MIDDLEWARES = { 'tutorial.middlewares.RandomUserAgentMiddleware': 1 }
设置动态代理,同样在这,只需要在meta中指定即可,scrapy会帮你调度,这里以设置固定代理为例
# 代理服务器 class ProxyMiddleware(object): def process_request(self, request, spider): """设置代理""" request.meta['proxy'] = 'http://115.226.140.24:44978'
同上,需要在settings.py中配置,才会生效
DOWNLOADER_MIDDLEWARES = { 'tutorial.middlewares.RandomUserAgentMiddleware': 1, 'tutorial.middlewares.ProxyMiddleware': 556 }
设置cookie,同样也可以在这配置,和设置请求头其实是一样的
# Cookies更新 class CookiesMiddleware(object): def get_cookies(self): # 1.从redis中获取 # 2.http接口 pass def process_request(self, request, spider): request.cookies = self.get_cookies()
同样,需要在settings.py中配置
pipelines.py
这里是写关于item类的处理方式的
比如,需要将item存放至mysql中,就可以在这里写,这里我写用文件追加形式保存数据
class WenshuPipeline(object): def process_item(self, item, spider): date = item['date'] # 一个日期一个文件 with open(date + '.txt', 'a', encoding='utf-8') as f: f.write(item['json_data'] + "\n")
同样,需要在settings.py中配置
ITEM_PIPELINES = { 'tutorial.pipelines.WenshuPipeline': 300, }
settings.py
这里配置了许多,非常重要的配置,记几个常用的,以后补充
名字:
一般自动生成,略
遵守爬虫协议:
# Obey robots.txt rules ROBOTSTXT_OBEY = False # 默认true
失败重试:
# 请求失败重试 RETRY_ENABLED = True # 默认true RETRY_TIMES = 3 # 默认2 # RETRY_HTTP_CODECS #遇到什么http code时需要重试,默认是500,502,503,504,408,其他的,网络连接超时等问题也会自动retry的
下载超时时间:
DOWNLOAD_TIMEOUT = 15 # 默认180秒 # 但是减小下载超时可能会引发错误: # TimeoutError: User timeout caused connection failure: Getting http://xxx.com. took longer than 15.0 seconds.
是否启用cookie:
# Disable cookies (enabled by default) COOKIES_ENABLED = True
是否启用httpcahe:
# Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
异步请求数(控制速度十分重要的设置):
# Configure maximum concurrent requests performed by Scrapy (default: 16) CONCURRENT_REQUESTS = 16 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16
中间件,前面提到过
日志:
# 设置日志 # 日志文件 LOG_FILE = BOT_NAME + '_' + time.strftime("%Y-%m-%d", time.localtime()) + '.log' # 日志等级 LOG_LEVEL = 'INFO' # 是否启用日志(创建日志后,不需开启,进行配置) LOG_ENABLED = True # (默认为True,启用日志) # 日志编码 LOG_ENCODING = 'utf-8' # 如果是True ,进程当中,所有标准输出(包括错误)将会被重定向到log中;例如:在爬虫代码中的 print() LOG_STDOUT = False # 默认为False
spiders
这里写爬虫,爬虫的起始url,怎么解析,和怎么处理,都是在这里完成
三、三个重要的类详解
scrapy.Request
scrapy框架提供的请求类,源码在scrapy.http.request.__init__文件中,这个类一般用来提交get请求,在spider中通过yield交给引擎
class Request(object_ref): def __init__(self, url, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None, encoding='utf-8', priority=0, dont_filter=False, errback=None, flags=None): self._encoding = encoding # this one has to be set first self.method = str(method).upper() self._set_url(url) self._set_body(body) assert isinstance(priority, int), "Request priority not an integer: %r" % priority self.priority = priority if callback is not None and not callable(callback): raise TypeError('callback must be a callable, got %s' % type(callback).__name__) if errback is not None and not callable(errback): raise TypeError('errback must be a callable, got %s' % type(errback).__name__) assert callback or not errback, "Cannot use errback without a callback" self.callback = callback self.errback = errback self.cookies = cookies or {} self.headers = Headers(headers or {}, encoding=encoding) self.dont_filter = dont_filter self._meta = dict(meta) if meta else None self.flags = [] if flags is None else list(flags) @property def meta(self): if self._meta is None: self._meta = {} return self._meta def _get_url(self): return self._url def _set_url(self, url): if not isinstance(url, six.string_types): raise TypeError('Request url must be str or unicode, got %s:' % type(url).__name__) s = safe_url_string(url, self.encoding) self._url = escape_ajax(s) if ':' not in self._url: raise ValueError('Missing scheme in request url: %s' % self._url) url = property(_get_url, obsolete_setter(_set_url, 'url')) def _get_body(self): return self._body def _set_body(self, body): if body is None: self._body = b'' else: self._body = to_bytes(body, self.encoding) body = property(_get_body, obsolete_setter(_set_body, 'body')) @property def encoding(self): return self._encoding def __str__(self): return "<%s %s>" % (self.method, self.url) __repr__ = __str__ def copy(self): """Return a copy of this Request""" return self.replace() def replace(self, *args, **kwargs): """Create a new Request with the same attributes except for those given new values. """ for x in ['url', 'method', 'headers', 'body', 'cookies', 'meta', 'encoding', 'priority', 'dont_filter', 'callback', 'errback']: kwargs.setdefault(x, getattr(self, x)) cls = kwargs.pop('cls', self.__class__) return cls(*args, **kwargs)
可以看到,它有我们了解的一般request所需要的内容,我们设置url,headers,cookies,callback等,都可以在构造函数中来设置
当然,还有两个重要的方法,是比较鼓励外部调用的,copy()和replace(),replace()将所有构造函数的属性浅拷贝,但你可以设置给定新值,
注意是浅拷贝,所以meta的拷贝只是引用改变。copy()就是浅拷贝request
当然还需要有post请求,也就是form表单提交,源文件在scrapy.http.request.form.FormRequest,这个类继承自scrapy.Request,确实有很多可以复用的
class FormRequest(Request): def __init__(self, *args, **kwargs): formdata = kwargs.pop('formdata', None) if formdata and kwargs.get('method') is None: kwargs['method'] = 'POST' super(FormRequest, self).__init__(*args, **kwargs) if formdata: items = formdata.items() if isinstance(formdata, dict) else formdata querystr = _urlencode(items, self.encoding) if self.method == 'POST': self.headers.setdefault(b'Content-Type', b'application/x-www-form-urlencoded') self._set_body(querystr) else: self._set_url(self.url + ('&' if '?' in self.url else '?') + querystr) @classmethod def from_response(cls, response, formname=None, formid=None, formnumber=0, formdata=None, clickdata=None, dont_click=False, formxpath=None, formcss=None, **kwargs): kwargs.setdefault('encoding', response.encoding) if formcss is not None: from parsel.csstranslator import HTMLTranslator formxpath = HTMLTranslator().css_to_xpath(formcss) form = _get_form(response, formname, formid, formnumber, formxpath) formdata = _get_inputs(form, formdata, dont_click, clickdata, response) url = _get_form_url(form, kwargs.pop('url', None)) method = kwargs.pop('method', form.method) return cls(url=url, method=method, formdata=formdata, **kwargs) def _get_form_url(form, url): if url is None: action = form.get('action') if action is None: return form.base_url return urljoin(form.base_url, strip_html5_whitespace(action)) return urljoin(form.base_url, url) def _urlencode(seq, enc): values = [(to_bytes(k, enc), to_bytes(v, enc)) for k, vs in seq for v in (vs if is_listlike(vs) else [vs])] return urlencode(values, doseq=1) def _get_form(response, formname, formid, formnumber, formxpath): """Find the form element """ root = create_root_node(response.text, lxml.html.HTMLParser, base_url=get_base_url(response)) forms = root.xpath('//form') if not forms: raise ValueError("No <form> element found in %s" % response) if formname is not None: f = root.xpath('//form[@name="%s"]' % formname) if f: return f[0] if formid is not None: f = root.xpath('//form[@id="%s"]' % formid) if f: return f[0] # Get form element from xpath, if not found, go up if formxpath is not None: nodes = root.xpath(formxpath) if nodes: el = nodes[0] while True: if el.tag == 'form': return el el = el.getparent() if el is None: break encoded = formxpath if six.PY3 else formxpath.encode('unicode_escape') raise ValueError('No <form> element found with %s' % encoded) # If we get here, it means that either formname was None # or invalid if formnumber is not None: try: form = forms[formnumber] except IndexError: raise IndexError("Form number %d not found in %s" % (formnumber, response)) else: return form def _get_inputs(form, formdata, dont_click, clickdata, response): try: formdata = dict(formdata or ()) except (ValueError, TypeError): raise ValueError('formdata should be a dict or iterable of tuples') inputs = form.xpath('descendant::textarea' '|descendant::select' '|descendant::input[not(@type) or @type[' ' not(re:test(., "^(?:submit|image|reset)$", "i"))' ' and (../@checked or' ' not(re:test(., "^(?:checkbox|radio)$", "i")))]]', namespaces={ "re": "http://exslt.org/regular-expressions"}) values = [(k, u'' if v is None else v) for k, v in (_value(e) for e in inputs) if k and k not in formdata] if not dont_click: clickable = _get_clickable(clickdata, form) if clickable and clickable[0] not in formdata and not clickable[0] is None: values.append(clickable) values.extend((k, v) for k, v in formdata.items() if v is not None) return values def _value(ele): n = ele.name v = ele.value if ele.tag == 'select': return _select_value(ele, n, v) return n, v def _select_value(ele, n, v): multiple = ele.multiple if v is None and not multiple: # Match browser behaviour on simple select tag without options selected # And for select tags wihout options o = ele.value_options return (n, o[0]) if o else (None, None) elif v is not None and multiple: # This is a workround to bug in lxml fixed 2.3.1 # fix https://github.com/lxml/lxml/commit/57f49eed82068a20da3db8f1b18ae00c1bab8b12#L1L1139 selected_options = ele.xpath('.//option[@selected]') v = [(o.get('value') or o.text or u'').strip() for o in selected_options] return n, v def _get_clickable(clickdata, form): """ Returns the clickable element specified in clickdata, if the latter is given. If not, it returns the first clickable element found """ clickables = [ el for el in form.xpath( 'descendant::*[(self::input or self::button)' ' and re:test(@type, "^submit$", "i")]' '|descendant::button[not(@type)]', namespaces={"re": "http://exslt.org/regular-expressions"}) ] if not clickables: return # If we don't have clickdata, we just use the first clickable element if clickdata is None: el = clickables[0] return (el.get('name'), el.get('value') or '') # If clickdata is given, we compare it to the clickable elements to find a # match. We first look to see if the number is specified in clickdata, # because that uniquely identifies the element nr = clickdata.get('nr', None) if nr is not None: try: el = list(form.inputs)[nr] except IndexError: pass else: return (el.get('name'), el.get('value') or '') # We didn't find it, so now we build an XPath expression out of the other # arguments, because they can be used as such xpath = u'.//*' + \ u''.join(u'[@%s="%s"]' % c for c in six.iteritems(clickdata)) el = form.xpath(xpath) if len(el) == 1: return (el[0].get('name'), el[0].get('value') or '') elif len(el) > 1: raise ValueError("Multiple elements found (%r) matching the criteria " "in clickdata: %r" % (el, clickdata)) else: raise ValueError('No clickable element matching clickdata: %r' % (clickdata,))
不过很显然几乎都是_私有方法,不建议调用,而且很多数据都是需要urlencode的
为什么要讲这些呢,因为在我使用过程中,需要使用中间件动态改变headers,cookies,formdata,让我查了很久才知道怎么改
因为比如cookie,也许spider中yield之后,经过很长时间才能抵达下载器,为了维护成最新的cookie,可以在中间件中进行修改
scrapy.Response
这是scrapy提供的响应类,源文件scrapy.http.response.Response
""" This module implements the Response class which is used to represent HTTP responses in Scrapy. See documentation in docs/topics/request-response.rst """ from six.moves.urllib.parse import urljoin from scrapy.http.request import Request from scrapy.http.headers import Headers from scrapy.link import Link from scrapy.utils.trackref import object_ref from scrapy.http.common import obsolete_setter from scrapy.exceptions import NotSupported class Response(object_ref): def __init__(self, url, status=200, headers=None, body=b'', flags=None, request=None): self.headers = Headers(headers or {}) self.status = int(status) self._set_body(body) self._set_url(url) self.request = request self.flags = [] if flags is None else list(flags) @property def meta(self): try: return self.request.meta except AttributeError: raise AttributeError( "Response.meta not available, this response " "is not tied to any request" ) def _get_url(self): return self._url def _set_url(self, url): if isinstance(url, str): self._url = url else: raise TypeError('%s url must be str, got %s:' % (type(self).__name__, type(url).__name__)) url = property(_get_url, obsolete_setter(_set_url, 'url')) def _get_body(self): return self._body def _set_body(self, body): if body is None: self._body = b'' elif not isinstance(body, bytes): raise TypeError( "Response body must be bytes. " "If you want to pass unicode body use TextResponse " "or HtmlResponse.") else: self._body = body body = property(_get_body, obsolete_setter(_set_body, 'body')) def __str__(self): return "<%d %s>" % (self.status, self.url) __repr__ = __str__ def copy(self): """Return a copy of this Response""" return self.replace() def replace(self, *args, **kwargs): """Create a new Response with the same attributes except for those given new values. """ for x in ['url', 'status', 'headers', 'body', 'request', 'flags']: kwargs.setdefault(x, getattr(self, x)) cls = kwargs.pop('cls', self.__class__) return cls(*args, **kwargs) def urljoin(self, url): """Join this Response's url with a possible relative url to form an absolute interpretation of the latter.""" return urljoin(self.url, url) @property def text(self): """For subclasses of TextResponse, this will return the body as text (unicode object in Python 2 and str in Python 3) """ raise AttributeError("Response content isn't text") def css(self, *a, **kw): """Shortcut method implemented only by responses whose content is text (subclasses of TextResponse). """ raise NotSupported("Response content isn't text") def xpath(self, *a, **kw): """Shortcut method implemented only by responses whose content is text (subclasses of TextResponse). """ raise NotSupported("Response content isn't text") def follow(self, url, callback=None, method='GET', headers=None, body=None, cookies=None, meta=None, encoding='utf-8', priority=0, dont_filter=False, errback=None): # type: (...) -> Request """ Return a :class:`~.Request` instance to follow a link ``url``. It accepts the same arguments as ``Request.__init__`` method, but ``url`` can be a relative URL or a ``scrapy.link.Link`` object, not only an absolute URL. :class:`~.TextResponse` provides a :meth:`~.TextResponse.follow` method which supports selectors in addition to absolute/relative URLs and Link objects. """ if isinstance(url, Link): url = url.url url = self.urljoin(url) return Request(url, callback, method=method, headers=headers, body=body, cookies=cookies, meta=meta, encoding=encoding, priority=priority, dont_filter=dont_filter, errback=errback)
显然,这里提供一些方法调用,从这里可以看出,response包含了request,并且共用一个meta字典,所以才能用于传参
还有就是各种常用的选择器使用,但是可以看出,这并不是我们一般使用的Resonse,我们使用的也是它的子类scrapy.http.response.text.TextResponse
子类才真正实现了那些选择器和text
Middlerware
这个并不是指一个类,泛指中间件,一般写在Middlerware.py文件中,主要讲一讲自定义的功能,定义格式:
class tutorialDownloaderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)
@classmethod
def from_crawler(cls, crawler):
这个方法主要用于给中间件构造函数传参,返回的就是实例
def process_request(self, request, spider):
这个方法会处理从引擎发往下载器的request
def process_response(self, request, response, spider):
这个方法会处理从下载器发往引擎的response
def process_exception(self, request, exception, spider):
这个方法会处理其他中间件抛出的异常和下载时候的异常
def spider_opened(self, spider):
这个没用过,哈哈,不过看得出是可以在爬虫打开时被调用
好了,上面笼统介绍了用处,其实是为了说我写中间件时候遇到的问题,因为scrapy有自带的很多中间件,所以方法的编写,优先级的设置,没搞好出bug都不知道哪出的,还千奇百怪
默认的中间件:DOWNLOADER_MIDDLEWARES_BASE 几乎都有重要的功能,了解这些,如果再深入一点源码,对理解http请求都很有辅助的帮助
所以记录一下最近用到的Middlerware和优先级,亲测是可行的
def process_request(self, request, spider): """修改headers,优先级 1""" request.headers.setdefault('User-Agent', random.choice(self.agents)) def process_request(self, request, spider): """修改cookies,优先级 50""" request.cookies = self.get_cookies() def process_request(self, request, spider): """设置代理,优先级60""" request.meta['proxy'] = 'http://' + self.proxys[self.num % PROXY_POOL_NUM] def process_response(self, request, response, spider): """检查response合法性, 优先级 560""" html = response.body.decode() if response.status != 200 or html is None: print('内容为空') return request.replace(dont_filter=True) elif 'VisitRemind' in html: print('出现验证码') return request.replace(dont_filter=True) else: return response def process_exception(self, request, exception, spider): """处理异常,优先级 560""" print(exception) meta = request.meta if 'req_error_times' in meta.keys(): meta['req_error_times'] = meta['req_error_times'] + 1 else: meta['req_error_times'] = 1 print(meta['req_error_times']) if meta['req_error_times'] > MAX_ERROR_TIMES: raise IgnoreRequest return request.replace(dont_filter=True)
四、调试scrapy
这是非常重要的部分,我刚开始学的时候就完全摸不着头脑怎么去调试,有些错误由于框架封装的缘故,报得很奇怪,有时候不能定位具体的错误代码在哪,提示错误在scrapy源码中,总不可能去改源码吧。。。下面讲讲怎么调试
有许多命令行可以调试的命令,但是总感觉很简陋
如果你在使用IDE,可以在项目根目录,也就是scrapy.sfg同级目录下新建一个run.py文件
# !usr/bin/env python # -*- coding:utf-8 _*- """ @author:happy_code @email: happy_code@foxmail.com @file: run.py @time: 2019/01/24 @desc: """ from scrapy import cmdline if __name__ == '__main__': cmdline.execute('scrapy crawl tutorial'.split())
这样,右键运行项目可以很方便。打断点后,右键debug也和普通项目一样debug,很方便
五、运行和部署
运行,命令行cd到项目根目录
scrapy crawl tutorial
最近在使用scrapyd和scrapy-client部署,还在学习,感觉挺方便的,有时间更
六、心得
现在还有中间件的配置中,优先级的控制上有些疑惑,
还有在于源码,比如引擎,下载器,这方面有疑惑
还有关于异步也是不太明白原理
继续奋斗吧!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号