Requests库入门实例
了解了Requests库的基本用法,附上一篇理论链接https://www.cnblogs.com/hao11/p/12593419.html
我们就可以做一些小实例了
1.亚马逊商品的爬取
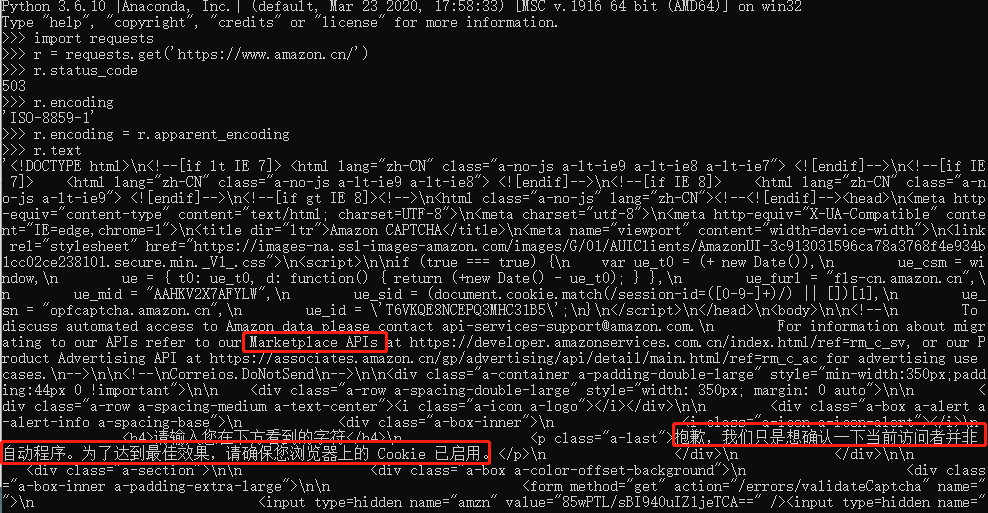
首先用get方法对亚马逊网站发送请求,然后看返回的状态码,此处503不是200,表明没有成功,
然后要看text内容,首先检查编码格式,header中不存在,用备用的替代,然后看到text中 For information about migrating to our APIs refer to our Marketplace APIs 还有确认我们是不是爬虫,说明这个网站对爬虫做了限制。
于是如下处理
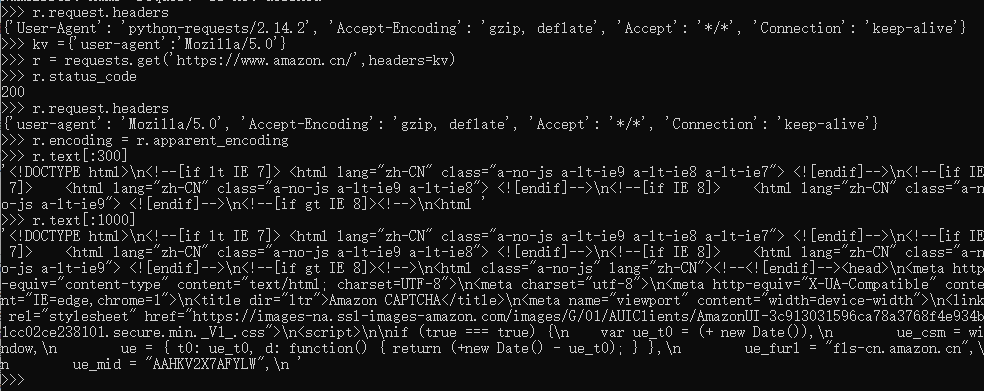
首先查看请求头,可以看到是原生的python请求,这样会被一些网站认为爬虫被拒绝访问
我们将请求头的代理字段替换, ‘Mozilla/5.0’ 伪装成火狐浏览器进行访问即可
最后写的健壮点
#RequestAmazon.py import requests url = 'https://www.amazon.cn/' try: kv = {'user-agent':'Mozilla/5.0'} r = requests.get(url, headers=kv) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[1000:2000]) except: print("爬取失败")
2.百度/谷歌搜索关键词提交
首先打开百度,输入python并回车,观察网址变化


百度的wd字段就是我们搜索的关键词
于是我们可以尝试:
http://www.baidu.com/s?wd=python
也是一样的
同理查看google可知其接口为
https://www.google.com/search?q=keyword
于是可以用爬虫实现查找功能
#Requestbaidu.py import requests keyword = 'python' url = 'https://www.baidu.com/s' #google把网站换了 s换成search try: kv = {'wd':keyword} #google把wd换成q r = requests.get(url, params=kv) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[1000:2000]) except: print("爬取失败")
3.图片爬取和存储
百度搜索一张图片,点击右键,在新分页中开启图片,然后复制网址过来即可。
#Pcis.py import requests import os url = 'https://pic4.zhimg.com/80/f2ded3c7f2873e5e7d48c139e1203e5f_720w.jpg' root = 'D://pics//' path = root +url.split('/')[-1] #文件名用本来的名字 try: if not os.path.exists(root): #不存在路径则创建 os.mkdir(root) if not os.path.exists(path): r = requests.get(url, timeout=30) with open(path,'wb') as f: #将文件以二进制打开 f.write(r.content) #content是二进制数据 f.close() print('文件保存成功') else: print('文件已存在') except: print("爬取失败")
跑一下,成功后去对应的路径就能看到
4.ip归属地查询
这个实例和实例二是类似,但有区别,这个实例直接字符串连接。
首先登录m.ip138.com 查询ip地址
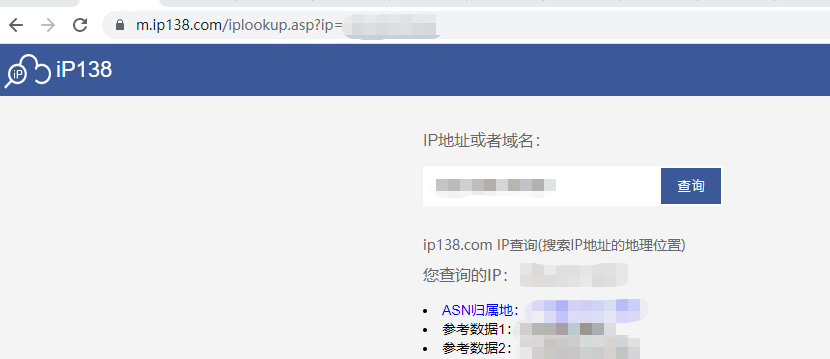
于是其接口是:http://m.ip138.com/ip.asp?ip=ipaddress
#IpQuerry.py import requests url = 'http://m.ip138.com/iplookup.asp?ip=' ip = '111.111.11.11' try: r = requests.get(url+ip, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding print(r.status_code) print(r.text[-300:]) except: print("爬取失败")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号