
资深小白带你走进OS Memory

图片来源:http://www.tomshardware.com/
序言:
Memory(内存)是一台计算机组成的重要部分,也是最基础的一部分。其它基础组件有主板、CPU、磁盘、显卡(可独立可集成)等。写这篇文章源自后面的一个案例,出于想搞明白,以及分享以前关于内存方面的一些记录的知识点。
本文概要主要讲了内存的介绍;如何正确查看系统内存使用率;对Swap分区进行介绍;如何将内存当作硬盘来加速数据读写,以及分享关于内存异常的案例分析;介绍了oom-killer的机制。
一、内存的介绍
1.何为内存
内存 是一种利用半导体技术制成的存储数据的电子设备。其电子电路中的数据以二进制方式存储,内存的每一个存储单元称做记忆元。内存根据存储能力及电源关系又可分为易失性内存(断电后丢失),非易失性内存(断电后持久)。
- 易失性内存:是指当电源供应中断后,内存所存储的数据将会丢失。有两类:动态随机访问内存(DRAM),静态随机访问内存(SRAM)。后者速度更快。
- 非易失性内存:是指当电源供应中断后,内存说存储的数据并不会小时。供电恢复后,数据可用正常读取(有很小的几率会出现数据损坏的情况)。有三类,只读内存、闪存、磁盘(磁盘就是我们最常见的非易失性内存的内存)
- 后文所出现‘内存’字样,均指易失性内存。
2.内存、CPU、磁盘三者的关系
- 内存与cpu的关系:cpu(中央处理器)就像人类的大脑一样,负责解释计算机指令以及处理计算机软件中的数据。由于cpu需要处理数据,如果直接从硬盘中读取写入数据,以现在的机械寻址的硬盘和固态SSD硬盘的速度来比较,两者差距太大。所以内存作为CPU和硬盘 两者的桥梁存在,另外CPU与内存之间为了缩小读写差距,CPU技术加入了高速缓存概念(L1、L2、L3,三种级别的Cache),一般在CPU产品型号技术参数列表中都会具体的介绍。
- 内存与硬盘的关系:程序是在内存上运行的,为了加快读速度,内存会将读取过的数据在自身中进行缓存。直到cache已满,会释放最先缓存的数据,将其写入磁盘,并腾出一定空间来满足当前正在读取的新数据。硬盘是为了持久化存储程序运行的数据,保证数据在机器断电后不被丢失。
二、如何正确查看内存的使用率
1.free 命令查看内存使用
[root@docker ~]# free total used free shared buff/cache available Mem: 1883740 440288 896080 31024 547372 1256984 Swap: 0 0 0
注:本机已关闭swap分区。
- 物理总内存total:1883740KB / 1024 =1.8G(这里不包括内核在启动时为其自身保留的一小部分,所以这里是1.8G,而其实是2G内存)
- 使用内存:1883740KB - 896080KB -547372KB = 440288KB(计算公式:total - free - buffers - cache = used)
- free 空闲内存:1883740KB - 440288KB -547372KB = 440288KB(同used计算公式)
- shared共享内存:被tmpfs使用的(大部分)内存
- buffers缓冲区:内核缓冲区使用的内存(写数据时的缓冲)
- cache缓存:页面缓存和slab 使用的内存 (注:slab内存分配机制 参考页面点此)(读数据时的缓存,设置drop_cache=3,使用time分别计算 读文件打开时间,动态watch cache的大小)
- available有效内存:估计有多少内存可用于启动新的应用程序,没有交换。 与缓存或free字段提供的数据不同,此字段考虑到页面缓存,并且由于项目正在使用,并不是所有可回收内存板都将被回收。(由系统动态的估算,此值相当于6.x系统里 free+cache+buffers的可用内存)
2.top 查看进程使用的内存
可指定进程查看,不加参数显示所有的进程,以及概览。
[root@docker ~]# top -p `pgrep nginx|head -n 1` ...省略 PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 26826 root 20 0 45816 1000 0 S 0.0 0.1 0:00.00 nginx
注释:
第一行,显示了默认的字段,另top状态下,可输入 f 键,进行选择其它字段,如DATA、SWAP等
第二行,显示字段的值。这里说下进程RES (驻留内存空间)和%MEM的关系,%MEM 是该进程占用系统物理total内存的百分比。RES计算方式:total*%MEM=RES;VIRT包括所需要的代码、数据和共享库。
3.vmstat 查看虚拟内存使用以及swap分区 和系统、cpu的io 报告
[root@docker ~]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 4 0 0 858708 15756 571772 0 0 6 49 16 0 8 0 92 0 0
三、Swap——与内存紧密相关的交换空间
1.Swap 用途介绍
当物理内存(RAM)的数量已满时,会使用Linux中的swap交换空间。如果系统需要更多内存资源并且RAM已满,则内存中的非活动页面将移动到交换空间中。虽然交换空间可以帮助机器使用少量的RAM,但不应该被认为是更多RAM的替代品。因为交换空间位于硬盘驱动器上,访问时间比物理内存慢的很多。发生的交换越多,系统越慢。
Linux有两种形式的交换空间:交换分区和交换文件。交换分区是仅用于交换的硬盘的独立部分,没有其他文件可以存放在那里。交换文件是位于系统和数据文件之间在文件系统中的一个特殊文件。另外,swap 空间一般设置物理内存的2倍。
2.启用或禁止交换空间
- 启用:如果觉得服务器应用对内存的读写不是特别在意,但服务器内存又很小的话,可设置开启swap 交换空间。
- 禁止:一种情况是当主机内存够大时,如果开启swap空间,当发生物理内存使用到达内核设定的一个临界值时(稍后会讲),内存中的数据会移动到swap交换空间内,而这时,物理内存还是有很多的。由于swap分区是走磁盘IO,所以我们有必要修改这个临界值或者禁止使用swap分区。还有一种情况就是我们的客户机操作系统是虚拟机(如kvm虚拟化上的),这个时候是要一定禁止swap分区的。
3.如何启用或禁用交换空间
查看当前swap空间状态
root@docker ~]# swapon -s 文件名 类型 大小 已用 权限 /mnt/os_swap file 4194300 0 -1
禁用swap空间
[root@docker ~]# swapoff -a
启用swap空间(这里使用的文件形式作为swap分区)
[root@docker ~]# swapon /mnt/os_swap
4.创建swap分区大小
- 用文件形式来创建swap
在当前的文件系统里,用dd或者fallocate(更快更简单)创建一个用于swap分区的文件:
[root@docker ~]# dd if=/dev/zero of=/mnt/os_swap bs=1M count=4096
或
[root@docker ~]# fallocate -l 4G /mnt/os_swap
修改该文件权限为600
[root@docker ~]# chmod 600 /mnt/os_swap
使用mkswap命令将文件建成一个交换空间(也可在最后用 -p size 指定划分给swap空间的大小,默认使用整个file 大小)
[root@docker ~]# mkswap /mnt/os_swap mkswap: /mnt/os_swap: warning: wiping old swap signature. 正在设置交换空间版本 1,大小 = 4194300 KiB 无标签,UUID=fc870bd5-c823-4e70-9d14-966543a52db2
使用swap分区,并检查swap空间大小
[root@docker ~]# swapon /mnt/os_swap [root@docker ~]# swapon -s 文件名 类型 大小 已用 权限 /mnt/os_swap file 4194300 0 -1
- 用磁盘分区的方式创建swap
首先找到一个大小合适的磁盘分区,分区类型选择82-Linux Swap。然后之后和上述类似,用mkswap命令创建启用swap分区。并用swapon /dev/vdb1(vdb1为分区设备)命令启用swap分区。
5.swappiness-系统什么时候开始使用交换空间
当我们设置启用swap分区后,系统会在什么情况下使用交换空间?这要从物理RAM内存使用情况来看,系统内核参数定义了这个界限:vm.swappiness,该参数取值范围在0-100之间,它定义了当系统剩余内存是总内存的多少百分比后,即开始使用交换空间。(暂时对这句话保持质疑,经过多方内存使用的测试,系统在由RAM转向Swap空间时并没有一个固定的剩余内存值!如你有相关计算方式,还望不吝赐教,谢谢!)
vm.swappiness 默认值是60。swappiness参数的值越高,表示内核将会更积极地从内存到交换空间中移动数据。经测试
当值为0时,系统可用内存在使用完后再使用swap进行交换。
当值为1时,和0的区别不大。
推荐在数据库读写数据密集的应用中禁用swap交换空间或者设置更低的vm.swappiness值,避免更多的硬盘IO操作,以此作为提高读写速度的一个方式。
四、如何将内存当作磁盘使用来加速数据读写
1.内存文件系统介绍
图片来源:www.thomas-krenn.com
如上图所示,利用内存作为特殊文件系统,目前知道的方式有3种,RAMdisk、ramfs、tmpfs。
ramdisk:RAM disk是使用主系统内存作为块设备的一种方式。它也可用于临时文件系统的加密工作,因为内容在重新启动时将被擦除。由于这个块设备大小是固定的,因此安装存放在其上面的文件系统是固定的大小。
ramfs:Ramfs是一个非常简单的文件系统,用于导出Linux的磁盘缓存 机制(页面缓存和dentry缓存)基于RAM的文件系统,可以动态的根据需要调整大小(前提不超过总RAM的情况)。通常,文件都被Linux缓存在内存中,数据页从后备存储(通常是安装文件系统的块设备)中读取并被保存 防止它再次需要,但标记为干净(可自由使用的),以防万一 虚拟内存系统需要其他内存。但ramfs 是没有后备存储的,像往常一样,写入ramfs的文件分配 dentry和页面缓存,但是没有地方可写。这意味着页面从未被标记为干净,因此当VM正在寻找回收内存时,它们不能被释放 。除非关机断电。
tmpfs:将所有文件保存在虚拟内存中的文件系统。tmpfs中的所有内容都是临时的,因为在你的硬盘上不会有文件被创建。如果卸载tmpfs实例, 存储在其中的一切都丢失。如果你umount tmpfs文件系统,存储在里面的内容将丢失。tmpfs可以将所有内容放入内核内部缓存并增长收缩以容纳它包含的文件,并能够交换不需要的页面到swap交换空间。由于tmpfs 完全位于页面缓存和交换中,所有tmpfs页面将在/proc/meminfo 和‘shared’ 中显示为 ”Shmem“
2.它们三的简单比较
ramfs与ramdisk比较:使用ram disk还需要不必要地将伪造块设备中的内存复制到页面缓存(并复制更改),以及创建和销毁dentries。此外,它还需要一个文件系统驱动程序(如ext2)来格式化和解释这些数据。与ramfs相比,这浪费了内存(和内存总线带宽),为CPU创造了不必要的工作,并污染了CPU高速缓存。更重要的一点,ramfs的所有的工作都发生在_anyway_,因为所有文件访问都通过页面和dentry缓存。 RAM disk是不必要的; ramfs在内部更简单,使用起来更灵活,大小可随着需要的空間而动态增加或減少。
本文原文出自飞走不可,如有转载,还请注明出处,如 飞走不可:http://www.cnblogs.com/hanyifeng/p/6915399.html
ramfs与tmpfs比较:ramfs的一个缺点是你可以持续的往里面写入数据,直到填满所有的内存,并且VM无法释放它,因为VM认为文件应该写入后备存储(而不是交换空间),但是ramfs 它没有任何后备存储。因此,只有root(或受信任的用户)才允许对ramfs mount进行写访问。创建一个名为tmpfs的ramfs派生物,以增加大小限制和能力,将数据写入swap交换空间。普通用户也可以允许写入权限 tmpfs挂载。
3.如何设置ramfs
创建一个目录,用于挂载ramfs
[root@docker ~]# mkdir /ramfs_test
挂载ramfs到上一步创建的目录中
[root@docker ~]# mount -t ramfs ramfs /ramfs_test/ 检查 [root@docker ~]# mount |grep ramfs_test ramfs on /ramfs_test type ramfs (rw,relatime)
测试一下ramfs与磁盘io读写的比较,一目了然。
[root@docker ~]# dd if=/dev/zero of=/ramfs_test/testfile.ramfs bs=1M count=1000 记录了1000+0 的读入 记录了1000+0 的写出 1048576000字节(1.0 GB)已复制,0.60369 秒,1.7 GB/秒 [root@docker ~]# dd if=/dev/zero of=/tmp/testfile.ramfs bs=1M count=1000 记录了1000+0 的读入 记录了1000+0 的写出 1048576000字节(1.0 GB)已复制,13.3286 秒,78.7 MB/秒
另外一个需要说明,网上大部分文章说挂载ramfs时,可以指定maxsize,即使用的最大的内存,经过测试,size(maxsize)参数没有生效,我使用以下命令进行挂载:
[root@docker ~]# mount -t ramfs ramfs /ramfs_test -o size=1024M && mount | grep ramfs ramfs on /ramfs_test type ramfs (rw,relatime,size=1024M)
然后放入一个大于1G的文件,并检查大小
[root@docker ~]# dd if=/dev/zero of=/ramfs_test/testramfs.file bs=1M count=1200 记录了1200+0 的读入 记录了1200+0 的写出 1258291200字节(1.3 GB)已复制,0.78763 秒,1.6 GB/秒 [root@docker ~]# ll -h /ramfs_test/testramfs.file -rw-r--r-- 1 root root 1.2G 6月 2 09:04 /ramfs_test/testramfs.file
从上面可以看出,使用ramfs作文件系统,并没有受到限制,所以它有可能占用系统全部的RAM,并导致系统死锁,无法进行操作,系统内核将崩溃。所以这里在使用ramfs时,要慎重考虑使用场景,避免程序故障或内存溢出导致系统崩溃,必须重启才能解决!另外查看了mount的man 手册,挂载ramfs内容时只有以下内容:
Mount options for ramfs Ramfs is a memory based filesystem. Mount it and you have it. Unmount it and it is gone. Present since Linux 2.3.99pre4. There are no mount options.
而,size参数只适用于tmpfs!
Mount options for tmpfs size=nbytes Override default maximum size of the filesystem. The size is given in bytes, and rounded up to entire pages. The default is half of the memory. The size parameter also accepts a suffix % to limit this tmpfs instance to that percentage of your physical RAM: the default, when neither size nor nr_blocks is specified, is size=50%
4.如何设置tmpfs
和ramfs有点类似,先创建一个目录,用于挂载tmpfs
[root@docker ~]# mkdir /tmpfs_test
使用mount命令挂载到tmpfs_test目录中,并检查挂载情况
[root@docker ~]# mount -t tmpfs -o size=1G tmpfs /tmpfs_test && mount |grep tmpfs_test tmpfs on /tmpfs_test type tmpfs (rw,relatime,size=1048576k)
现在我们使用dd来测试一下速度,并检查下size 限制空间的效果
[root@docker ~]# dd if=/dev/zero of=/tmpfs_test/testtmpfs.file bs=1M count=1100 dd: error writing ‘/tmpfs_test/testtmpfs.file’: No space left on device 1025+0 records in 1024+0 records out 1073741824 bytes (1.1 GB) copied, 0.497443 s, 2.2 GB/s
从上面的提示可以看出,空间已经不够,现在看下实际存入的文件大小
[root@docker ~]# ls -l --block-size=K /tmpfs_test/testtmpfs.file -rw-r--r-- 1 root root 1048576K Jun 2 12:16 /tmpfs_test/testtmpfs.file
从ls的输出可以看到,实际存入的文件大小,刚好是size限制的大小。很明显,size起到了避免系统RAM/SWAP内存被tmpfs 全部填满的情况。也体现了tmpfs 比ramfs的优势所在。所以推荐使用tmpfs。
下面是之前tmpfs介绍中所说的tmpfs在/proc/meminfo 以及shared 显示。
[root@docker ~]# free -m && echo '-------------------------/proc/meminfo' && cat /proc/meminfo |grep Shmem total used free shared buff/cache available Mem: 1839 268 174 1024 1397 393 Swap: 0 0 0 -------------------------/proc/meminfo Shmem: 1048964 kB
五、常见内存不足或内存溢出导致的故障分析
1.一次内存异常导致应用被kill的案例
某台应用无法提供服务,主机sshd无法访问,通信异常。使用vnc连接到本地终端后,发现终端界面上报以下错误日志,也无法进行操作: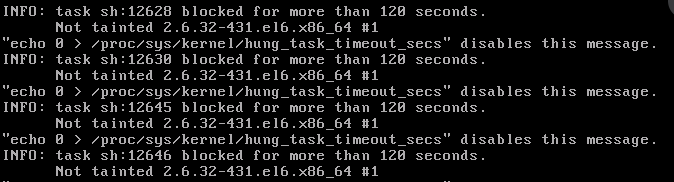
INFO: task sh:12628 blocked for more than 120 seconds.Not tainted 2.6.32-431.el6.x86 #1 "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
上述错误,只是警告提示,跟系统内核参数vm.dirty_ratio有关系,后面会专门的介绍。 由于该主机无法响应任何操作,系统也登陆不进去,只有断电重启了(这里也可看出系统日志收集到某个中心节点的好处Y(^_^)Y)。重启后观察系统messages日志,下面是日志的一部分,这里有完整的日志,有兴趣的可以下载看下:


May 19 00:31:07 robot-web kernel: VFS: file-max limit 65535 reached May 19 00:31:30 robot-web kernel: VFS: file-max limit 65535 reached May 19 00:32:24 robot-web kernel: sh invoked oom-killer: gfp_mask=0x84d0, order=0, oom_adj=0, oom_score_adj=0 May 19 00:32:24 robot-web kernel: sh cpuset=/ mems_allowed=0 May 19 00:32:24 robot-web kernel: Pid: 20387, comm: sh Not tainted 2.6.32-431.el6.x86_64 #1 May 19 00:32:24 robot-web kernel: Call Trace: May 19 00:32:24 robot-web kernel: [<ffffffff810d05b1>] ? cpuset_print_task_mems_allowed+0x91/0xb0 May 19 00:32:24 robot-web kernel: [<ffffffff81122960>] ? dump_header+0x90/0x1b0 May 19 00:32:24 robot-web kernel: [<ffffffff8122798c>] ? security_real_capable_noaudit+0x3c/0x70 May 19 00:32:24 robot-web kernel: [<ffffffff81122de2>] ? oom_kill_process+0x82/0x2a0 May 19 00:32:24 robot-web kernel: [<ffffffff81122d21>] ? select_bad_process+0xe1/0x120 May 19 00:32:24 robot-web kernel: [<ffffffff81123220>] ? out_of_memory+0x220/0x3c0 May 19 00:32:24 robot-web kernel: [<ffffffff8112fb3c>] ? __alloc_pages_nodemask+0x8ac/0x8d0 May 19 00:32:24 robot-web kernel: [<ffffffff81167a9a>] ? alloc_pages_current+0xaa/0x110 May 19 00:32:24 robot-web kernel: [<ffffffff8104ee9b>] ? pte_alloc_one+0x1b/0x50 May 19 00:32:24 robot-web kernel: [<ffffffff81146412>] ? __pte_alloc+0x32/0x160 May 19 00:32:24 robot-web kernel: [<ffffffff8114b220>] ? handle_mm_fault+0x1c0/0x300 May 19 00:32:24 robot-web kernel: [<ffffffff8104a8d8>] ? __do_page_fault+0x138/0x480 May 19 00:32:24 robot-web kernel: [<ffffffff8152d45e>] ? do_page_fault+0x3e/0xa0 May 19 00:32:24 robot-web kernel: [<ffffffff8152a815>] ? page_fault+0x25/0x30 May 19 00:32:24 robot-web kernel: [<ffffffff8152d45e>] ? do_page_fault+0x3e/0xa0 May 19 00:32:24 robot-web kernel: [<ffffffff8152a815>] ? page_fault+0x25/0x30 May 19 00:32:24 robot-web kernel: Mem-Info: May 19 00:32:24 robot-web kernel: Node 0 DMA per-cpu: May 19 00:32:24 robot-web kernel: CPU 0: hi: 0, btch: 1 usd: 0 May 19 00:32:24 robot-web kernel: CPU 1: hi: 0, btch: 1 usd: 0 May 19 00:32:24 robot-web kernel: CPU 2: hi: 0, btch: 1 usd: 0 May 19 00:32:24 robot-web kernel: CPU 3: hi: 0, btch: 1 usd: 0 May 19 00:32:24 robot-web kernel: Node 0 DMA32 per-cpu: May 19 00:32:24 robot-web kernel: CPU 0: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: CPU 1: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: CPU 2: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: CPU 3: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: Node 0 Normal per-cpu: May 19 00:32:24 robot-web kernel: CPU 0: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: CPU 1: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: CPU 2: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: CPU 3: hi: 186, btch: 31 usd: 0 May 19 00:32:24 robot-web kernel: active_anon:1459499 inactive_anon:284686 isolated_anon:0 May 19 00:32:24 robot-web kernel: active_file:54 inactive_file:45 isolated_file:0 May 19 00:32:24 robot-web kernel: unevictable:0 dirty:0 writeback:0 unstable:0 May 19 00:32:24 robot-web kernel: free:26212 slab_reclaimable:6599 slab_unreclaimable:53001 May 19 00:32:24 robot-web kernel: mapped:697 shmem:793 pagetables:131666 bounce:0 May 19 00:32:24 robot-web kernel: Node 0 DMA free:15728kB min:124kB low:152kB high:184kB active_anon:0kB inactive_anon:0kB active_file:0kB inactive_file:0kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:15340kB mlocked:0kB dirty:0kB writeback:0kB mapped:0kB shmem:0kB slab_reclaimable:0kB slab_unreclaimable:0kB kernel_stack:0kB pagetables:0kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:0 all_unreclaimable? yes May 19 00:32:24 robot-web kernel: lowmem_reserve[]: 0 3000 8050 8050 May 19 00:32:24 robot-web kernel: Node 0 DMA32 free:45816kB min:25140kB low:31424kB high:37708kB active_anon:1983180kB inactive_anon:496216kB active_file:28kB inactive_file:72kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:3072092kB mlocked:0kB dirty:0kB writeback:0kB mapped:2000kB shmem:1912kB slab_reclaimable:3200kB slab_unreclaimable:82768kB kernel_stack:10296kB pagetables:147684kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:1 all_unreclaimable? no May 19 00:32:24 robot-web kernel: lowmem_reserve[]: 0 0 5050 5050 May 19 00:32:24 robot-web kernel: Node 0 Normal free:43304kB min:42316kB low:52892kB high:63472kB active_anon:3854816kB inactive_anon:642528kB active_file:188kB inactive_file:108kB unevictable:0kB isolated(anon):0kB isolated(file):0kB present:5171200kB mlocked:0kB dirty:0kB writeback:0kB mapped:788kB shmem:1260kB slab_reclaimable:23196kB slab_unreclaimable:129236kB kernel_stack:26800kB pagetables:378980kB unstable:0kB bounce:0kB writeback_tmp:0kB pages_scanned:59 all_unreclaimable? no May 19 00:32:24 robot-web kernel: lowmem_reserve[]: 0 0 0 0 May 19 00:32:24 robot-web kernel: Node 0 DMA: 2*4kB 1*8kB 2*16kB 2*32kB 2*64kB 1*128kB 0*256kB 0*512kB 1*1024kB 1*2048kB 3*4096kB = 15728kB May 19 00:32:24 robot-web kernel: Node 0 DMA32: 340*4kB 76*8kB 461*16kB 264*32kB 132*64kB 62*128kB 12*256kB 5*512kB 0*1024kB 1*2048kB 1*4096kB = 45952kB May 19 00:32:24 robot-web kernel: Node 0 Normal: 9334*4kB 326*8kB 2*16kB 8*32kB 4*64kB 2*128kB 2*256kB 0*512kB 0*1024kB 1*2048kB 0*4096kB = 43304kB May 19 00:32:24 robot-web kernel: 30346 total pagecache pages May 19 00:32:24 robot-web kernel: 29453 pages in swap cache May 19 00:32:24 robot-web kernel: Swap cache stats: add 691531, delete 662078, find 1720814/1738009 May 19 00:32:24 robot-web kernel: Free swap = 0kB May 19 00:32:24 robot-web kernel: Total swap = 2064376kB May 19 00:32:24 robot-web kernel: 0 8384 26517 56 1 0 0 sh May 19 00:32:24 robot-web kernel: [ 8385] 0 8385 64694 2309 2 0 0 php May 19 00:32:24 robot-web kernel: [ 8386] 0 8386 26517 56 2 0 0 sh May 19 00:32:24 robot-web kernel: [ 8387] 0 8387 26517 57 0 0 0 sh May 19 00:32:24 robot-web kernel: [ 8388] 0 8388 26517 55 1 0 0 sh May 19 00:32:24 robot-web kernel: [ 8402] 0 8402 26517 56 0 0 0 sh May 19 00:32:24 robot-web kernel: [ 8887] 93 8887 23967 272 1 0 0 sendmail May 19 00:32:24 robot-web kernel: [15917] 0 15917 64760 2347 3 0 0 php May 19 00:32:24 robot-web kernel: [15921] 0 15921 64760 2351 3 0 0 php May 19 00:32:24 robot-web kernel: [15923] 0 15923 64760 2349 2 0 0 php May 19 00:32:24 robot-web kernel: [15925] 0 15925 64696 2343 3 0 0 php May 19 00:32:24 robot-web kernel: [15950] 0 15950 64760 2346 3 0 0 php
我筛选了几条,主要内容有以下部分:
1 May 19 00:31:30 robot-web kernel: VFS: file-max limit 65535 reached 2 ... 3 4 May 19 00:32:24 robot-web kernel: Free swap = 0kB 5 May 19 00:32:24 robot-web kernel: Total swap = 2064376kB 6 ... 7 8 May 19 00:32:24 robot-web kernel: [20477] 0 20477 26518 55 3 0 0 sh 9 May 19 00:32:24 robot-web kernel: Out of memory: Kill process 1572 (mysqld) score 3 or sacrifice child 10 May 19 00:32:24 robot-web kernel: Killed process 1572, UID 500, (mysqld) total-vm:452564kB, anon-rss:5400kB, file-rss:40kB 11 May 19 00:32:24 robot-web kernel: sh invoked oom-killer: gfp_mask=0x201da, order=0, oom_adj=0, oom_score_adj=0
从日志中可以看到两个问题,1是系统打开文件句柄数到达设置上限;2是内存不足,swap交换空间都用完了,触发了内存Oom-Killer,由oom-killer根据算法选择了mysqld,将其杀死(稍后将会说下oom-killer是怎么选择的)。按理应该系统这时就可以恢复的,但是当时系统内的crontabd 里有每10秒执行的sh任务,且这些命令运行完没有正常释放,导致进程连接数太多,占用的内存超过了系统的可用内存。所以猜测这是系统无法响应任何操作的根本原因,只能重启。
重启系统恢复正常后,根据以上出现的问题,对系统进行了调优工作。主要包括以下几个部分:
- 按照提示修改 /proc/sys/kernel/hung_task_timeout_secs 值为 0
临时: echo 0 > /proc/sys/kernel/hung_task_timeout_secs 或 sysctl -w hung_task_timeout_secs=0 永久 echo “kernel.hung_task_timeout_secs = 0” >>/etc/sysctl.conf sysctl -p
增加系统物理内存到16G,并修改用户open files限制数为1048576 计算是每4M内存打开256个文件数,即:(16G*1024)M/4M *256。临时: ulimit -n 1048576 或 echo "ulimit -n 1048576" >> /etc/profile 永久:编写/etc/security/limits.conf,根据提示在末行添加
- 增加file-max值为1048576
临时: echo 1048576 > /proc/sys/fs/file-max 或 sysctl -w fs.file-max=1048576 永久 echo “fs.file-max=1048576” >> /etc/sysctl.conf sysctl -p
- 优化修改系统对脏数据的刷新策略
临时: sysctl -w vm.dirty_background_ratio=5 sysctl -w vm.dirty_ratio=10 永久: echo "vm.dirty_background_ratio=5" >> /etc/sysctl.conf echo "vm.dirty_ratio=10" >> /etc/sysctl.conf
sysctl -p - 优化crontab里的任务计划,检查,确保执行后释放
- 由于该系统是虚拟机,关闭swap分区。(虚拟机里使用磁盘做swap分区,IO性能会更低)
做了以上修改优化后,系统到目前为止,没有出现过异常。
2.对以上参数修改进行分析
"echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message
先说下这个吧。关于内核为什么提示我们要“修改这个时间为0,来禁用这条消息”的提示。先看下hung_task_timeout_secs的介绍,参考内核文档:
hung_task_timeout_secs: Check interval. When a task in D state did not get scheduled for more than this value report a warning. This file shows up if CONFIG_DETECT_HUNG_TASK is enabled. 0: means infinite timeout - no checking done. Possible values to set are in range {0..LONG_MAX/HZ}.
内核定时检测系统中处于D状态的进程,如果其处于D状态的时间超过了指定时间(默认120s,可以配置),则打印相关堆栈信息,也可以通过proc参数配置使其直接panic。
默认情况下,Linux使用高达40%的可用内存将进行文件系统缓存。达到此标记后,文件系统将所有未完成的数据刷新到磁盘,导致所有的IO进行同步。要将此数据刷新到磁盘,默认情况下有120秒的时间限制。在这种情况下,IO子系统速度不够快,可以有120秒的时间刷新数据。由于IO子系统响应缓慢,并且用户进程又提出了更多的请求,系统内存将被填满,从而导致上述截图中的错误提示。
将其值修改为 0,意味着表示可以无限超时--不检查完成情况。但此并不能真正的解决问题根源。
与hung_task其相关的几个参数
[root@docker ~]# sysctl -a|grep vm.dirty vm.dirty_background_bytes = 0 vm.dirty_background_ratio = 10 vm.dirty_bytes = 0 vm.dirty_expire_centisecs = 3000 vm.dirty_ratio = 30 vm.dirty_writeback_centisecs = 500
这里只说下其中两个相关的参数:vm.dirty_ratio 、vm.dirty_background_ratio,以下内容出自Linux内核文档介绍:
dirty_background_ratio Contains, as a percentage of total available memory that contains free pages and reclaimable pages, the number of pages at which the background kernel flusher threads will start writing out dirty data. The total available memory is not equal to total system memory. ============================================================== dirty_ratio Contains, as a percentage of total available memory that contains free pages and reclaimable pages, the number of pages at which a process which is generating disk writes will itself start writing out dirty data. The total available memory is not equal to total system memory.
dirty_background_ratio:是系统总内存的占用百分比,其中包括空闲页面和可回收页面。后台内核刷新线程的页面开始写入脏数据。即dirty data如果达到了dirty_background_ratio,则内核将在后台执行回写磁盘,但是应用程序仍然可以在不阻塞的情况下写入页面缓存。
dirty_ratio:包含可用页面和可回收页面的占 总可用内存的百分比,产生磁盘写入的进程将自动开始写入脏数据。这时应用程序将阻塞并将脏页面写入磁盘。直到系统内的dirty page低于该值。
即先达到dirty_background_ratio,这是程序不会阻塞,等到达dirty_ratio时,程序将阻塞请求,直到将数据写入磁盘中。这些参数的值取决于系统的运行的什么程序,如果运行大型数据库,建议将这些值保持小数值 background_ratio < dirty_ratio,以避免I/O瓶颈以及增加系统负载。这也是作为系统VM优化的一个点。
说下file-max
sysctl -w fs.file-max=1048576
file-max中的值表示Linux内核将要分配的文件句柄的最大数量。 每当应用程序请求文件句柄时,内核会动态分配文件句柄,但内核在应用程序关闭时并不会释放销毁这些文件句柄。内核会循环使用这些文件句柄。也意味着随着时间的推移,分配的文件句柄的总数将增加,即使当前使用的文件句柄的数量可能较低。所以当您收到大量关于运行文件句柄的错误消息时,可能需要增加file-max值的大小。
3.什么是oom-killer ?
介绍
OOM(Out Of Memory) Management:它有一个简单的任务->检查系统是否有足够的可用内存来满足应用程序,验证系统是否真的是内存不足,如果是这样,请‘选择’一个进程来杀死它。
当检查可用内存时,所需页面的数量作为参数传递给vm_enough_memory()。除非系统管理员指定系统应该过度使用内存,否则将检查可用内存的安装。为了确定有多少页是潜在可用的,Linux总结了以下几个关注数据:
Total page cache 因为页面缓存容易回收
Total free pages 因为它们已经是有效可利用的
Total free swap pages 作为用户空间的页面可能会被分页换出
Total pages managed by swapper_space 尽管这重复计算了空闲的交换页面。这是平衡的,因为事实上,插槽有时是保留的,但没有在使用。
Total pages used by the dentry cache 易于回收的
Total pages used by the inode cache 易于回收的
如果以上添加的总页数足以满足请求,vm_enough_memory()函数将返回true给调用者。如果返回false,调用者就知道内存不可用,通常决定将-ENOMEM返回给用户空间。这时机器内存不足时,旧的页帧将被回收,但是尽管回收页面可能会发现还是无法释放足够的页面来满足请求,如果它无法释放页面帧,则调用out_of_memory() 函数来查看系统是否内存不足,并且还需要kill某进程。

不巧的是,有可能系统在没有空闲内存可用时,只需要等待IO完成 或页面交换到后备存储器中(如硬盘)。所以为了防止误杀情况,在决定杀死一个进程之前,它将通过以下清单检查:
- 是否有足够的交换空间 (nr_swap_pages > 0) ? 如果是,不执行OOM
- 自上次失败以来是否超过5秒? 如果是, 不执行OOM
- 我们在最后一刻失败了吗? 如果否,不执行OOM
- 如果至少在过去5秒内没有发生10次故障, 我们不执行OOM
- 一个进程在最近5秒内被杀死了么? 如果是, 不执行OOM
只有上述测试通过了,才能调用oom_kill()来选择一个进程kill。
以上是2.6内核以前的几个关注数据,2.6内核以后的,将以下信息片段添加在一起以确定可用内存:
Total page cache 因为页面缓存容易回收
Total free pages 因为它们已经是有效可利用的
Total free swap pages 作为用户空间的页面可能会被分页换出
Slab pages with SLAB_RECLAIM_ACCOUNT set 他们是容易回收的
这些页面减去根进程的3%预留内存,就是可用于请求的总内存量。如果内存可用,则进行检查以确保已提交内存的总量不超过允许的阈值。
允许的阈值为TotalRam *(OverCommitRatio / 100)+ TotalSwapPage,其中OverCommitRatio 由系统管理员设置。
以上内容参考Mel Gorman的书籍<<Understanding the Linux Virtual Memory Manager>>
注:
对swapper_space作个解释备注,当释放不用的物理页面时,内核并不会立即将其放入空闲队列(free_area),而是将其插入非活动队列lru,便于再次时能够快速的得到。swapper_space则用于记录换入/换出到磁盘交换文件中的物理页面。swapper_space是3个全局的LRU队列其中之一,可参考作者zszmhd的内存管理的文章
对dentry(翻译:目录项)的解释:它们用来实现名称和 inode 之间的映射,有一个目录缓存用来保存最近使用的 dentry。dentry 还维护目录和文件之间的关系,从而支持在文件系统中移动
4.为什么oom_killer选择了mysqld进程?
函数select_bad_process()负责选择要杀死的进程。badness() 已改oom_badness()通过为其检查每个进程累加的“ponits”并将其返回给select_bad_process()。'points'数值最高的进程,最终会被销毁kill,除非它已经在自己释放内存中。
进程的得分值始于其常驻内存的大小,任何子进程(内核线程除外)的独立内存大小也会添加到该分数中;另外root 进程在计算时将会有3%的优惠,确保超级用户的进程不被杀掉。进程的nice值会乘2计算得分,如果nice大于0即更有可能被选中;长时间运行的进程的分数会降低,运行时间越长,被选中机率越低;直接访问硬件设备的进程分数会降低。 (删除原因,是在Github上看到新的oom_kill.c文件中,已去掉了相关代码)。最后,累积的得分由/proc/pid/oom_score存储,且该文件对用户只读权限。
以下是oom_kill.c文件中关于oom_badness部分的代码:
1 unsigned long oom_badness(struct task_struct *p, struct mem_cgroup *memcg, 2 const nodemask_t *nodemask, unsigned long totalpages) 3 { 4 long points; 5 long adj; 6 7 if (oom_unkillable_task(p, memcg, nodemask)) 8 return 0; 9 10 p = find_lock_task_mm(p); 11 if (!p) 12 return 0; 13 14 /* 15 * Do not even consider tasks which are explicitly marked oom 16 * unkillable or have been already oom reaped or the are in 17 * the middle of vfork 18 */ 19 adj = (long)p->signal->oom_score_adj; 20 if (adj == OOM_SCORE_ADJ_MIN || 21 test_bit(MMF_OOM_SKIP, &p->mm->flags) || 22 in_vfork(p)) { 23 task_unlock(p); 24 return 0; 25 } 26 27 /* 28 * The baseline for the badness score is the proportion of RAM that each 29 * task's rss, pagetable and swap space use. 30 */ 31 points = get_mm_rss(p->mm) + get_mm_counter(p->mm, MM_SWAPENTS) + 32 atomic_long_read(&p->mm->nr_ptes) + mm_nr_pmds(p->mm); 33 task_unlock(p); 34 35 /* 36 * Root processes get 3% bonus, just like the __vm_enough_memory() 37 * implementation used by LSMs. 38 */ 39 if (has_capability_noaudit(p, CAP_SYS_ADMIN)) 40 points -= (points * 3) / 100; 41 42 /* Normalize to oom_score_adj units */ 43 adj *= totalpages / 1000; 44 points += adj; 45 46 /* 47 * Never return 0 for an eligible task regardless of the root bonus and 48 * oom_score_adj (oom_score_adj can't be OOM_SCORE_ADJ_MIN here). 49 */ 50 return points > 0 ? points : 1; 51 }
另外,在oom_kill.h文件中,/proc/pid/oom_adj 有取值范围 -16~15 之间。 -17表示对此进程禁用oom。我们可以修改oom_adj的值,来保护某指定的重要程序。
如何检测系统有无被oom-killer杀死的程序:可查看系统messages日志,以及用dmesg命令。另外还可以用dstat命令来查看当前系统中,被oom机制选中的候选者,如下:
[root@docker ~]# dstat --top-oom --out-of-memory--- kill score mysqld 61 mysqld 61
六、总结
内存管理是Linux系统内核中核心技术,重要性不言而喻,对内存的了解越深,更有利于我们应用程序的开发以及运行。文中的内容部分理论知识来自互联网(链接在文末),另外也加入了自己的分析测试理解,本着深入学习的心理,写下并总结了这篇文章分享给大家。如果文章中有错误的地方,或者可以修改成更好的话来表达,还望大家不吝赐教,留言私信都可以哈。另外感谢虎神给文章起的名字😏 (:对,你没看错,确实是写完之后才想的名字,主要是内存涉及了太多知识,我觉得本文也只是描述了个大概。)
本文原文出自飞走不可,如有转载,还请注明出处,如 飞走不可:http://www.cnblogs.com/hanyifeng/p/6915399.html
参考连接:
https://serverfault.com/questions/85470/meaning-of-the-buffers-cache-line-in-the-output-of-free
https://www.linux.com/news/all-about-linux-swap-space
https://askubuntu.com/questions/103915/how-do-i-configure-swappiness
https://www.kernel.org/doc/Documentation/filesystems/ramfs-rootfs-initramfs.txt
https://www.kernel.org/doc/Documentation/filesystems/tmpfs.txt
https://www.kernel.org/doc/Documentation/blockdev/ramdisk.txt
http://www.vpsee.com/2013/10/how-to-configure-the-linux-oom-killer/
http://www.adminlinux.org/2009/09/tuning-rhel-4xx-5xx-file-max-maximum.html
https://www.kernel.org/doc/Documentation/sysctl/fs.txt
https://www.blackmoreops.com/2014/09/22/linux-kernel-panic-issue-fix-hung_task_timeout_secs-blocked-120-seconds-problem/
https://www.kernel.org/doc/Documentation/sysctl/vm.txt
https://msdn.microsoft.com/en-us/library/bb742613.aspx
http://www.linuxatemyram.com/index.html
http://andylin02.iteye.com/blog/858708
https://lonesysadmin.net/2013/12/22/better-linux-disk-caching-performance-vm-dirty_ratio/
https://linux-mm.org/OOM_Killer
https://www.kernel.org/doc/gorman/html/understand/understand016.html
https://github.com/torvalds/linux/blob/dd23f273d9a765d7f092c1bb0d1cd7aaf668077e/Documentation/filesystems/proc.txt

 浙公网安备 33010602011771号
浙公网安备 33010602011771号