

requests , bs4 和 lxml库 巩固
请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.58'
}
request_params = '''
requests 方法 请求参数
• url 请求的URL地址
• params GET请求参数
• data POST请求参数
• json 同样是POST请求参数,要求服务端接收json格式的数据
• headers 请求头字典
• cookies cookies信息(字典或CookieJar)
• files 上传文件
• auth HTTP鉴权信息
• timeout 等待响应时间,单位秒
• allow_redirects 是否允许重定向
• proxies 代理信息
• verify 是否校验证书
• stream 如果为False,则响应内容将直接全部下载
• cert 客户端证书地址
'''
Response = '''
字段
• cookies 返回CookieJar对象
• encoding 报文的编码
• headers 响应头
• history 重定向的历史记录
• status_code 响应状态码,如200
• elaspsed 发送请求到接收响应耗时
• text 解码后的报文主体
• content 字节码,可能在raw的基础上解压
方法
• json() 解析json格式的响应
• iter_content() 需配置stream=True,指定chunk_size大小
• iter_lines() 需配置stream=True,每次返回一行
• raise_for_status() 400-500之间将抛出异常
• close()
'''

soup
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>



.next_sibling 属性获取了该节点的下一个兄弟节点,
.previous_sibling 属性获取了该节点的上一个兄弟节点,
如果节点不存在,则返回 None
注:
因为空白或者换行也可以被视作一个节点,
所以得到的结果可能是空白或者换行。



lxml_roles = '''
标签名 选取此节点的所有子节点
/ 从当前节点选取直接子节点
// 从当前节点选取子孙节点
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
* 通配符,选择所有元素节点与元素名
@* 选取所有属性
[@attrib] 选取具有给定属性的所有元素
[@attrib='value'] 选取给定属性具有给定值的所有元素
[tag] 选取所有具有指定元素的直接子节点
[tag='text'] 选取所有具有指定元素并且文本内容是 text 节点
'''
lxml_operators = '''
or 或
and 与
mod 取余
| 取两个节点的集合
+ 加 , - 减 , * 乘 , div 除
= 等于 , != 不等于 , < 小于
<= 小于或等于 , > 大于 , >= 大于或等于
'''

由于 jupyter 复制过来文字会乱,以上为 jupyter 文件转 html 截图
下面为 以上三种库的文本形式
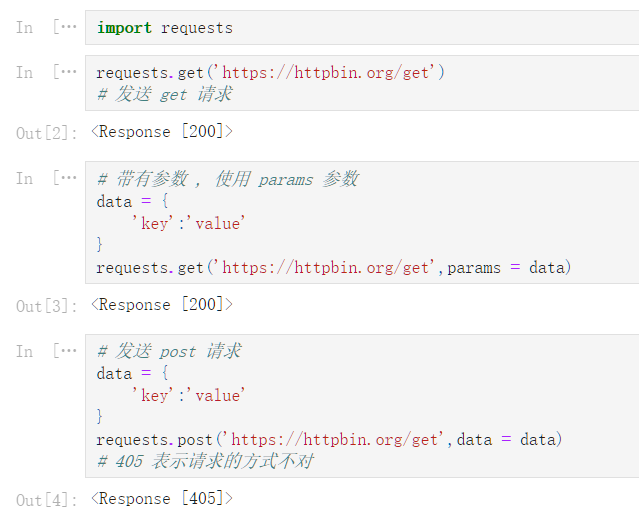
requests 库
import requests
requests.get('https://httpbin.org/get')
# 发送 get 请求
<Response [200]>
# 带有参数 , 使用 params 参数
data = {
'key':'value'
}
requests.get('https://httpbin.org/get',params = data)
<Response [200]>
# 发送 post 请求
data = {
'key':'value'
}
requests.post('https://httpbin.org/get',data = data)
# 405 表示请求的方式不对
<Response [405]>
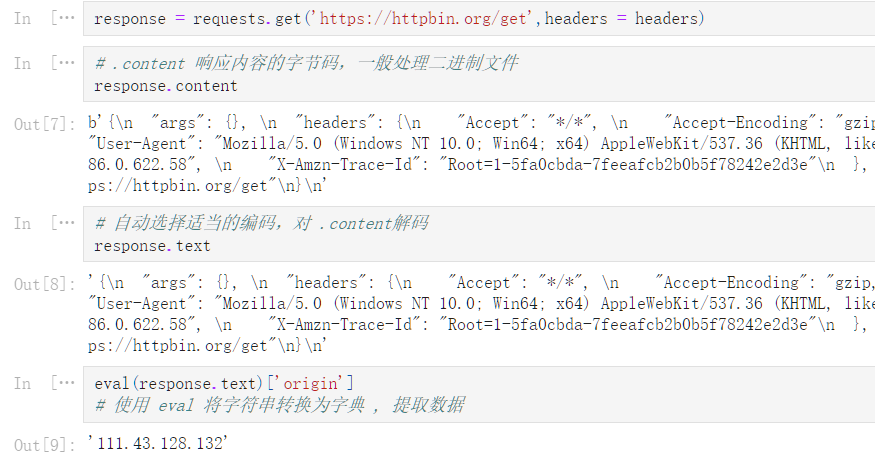
# 定义请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.58'
}
response = requests.get('https://httpbin.org/get',headers = headers)
# .content 响应内容的字节码,一般处理二进制文件
response.content
b'{\n "args": {}, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Host": "httpbin.org", \n "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.58", \n "X-Amzn-Trace-Id": "Root=1-5fa0cbda-7feeafcb2b0b5f78242e2d3e"\n }, \n "origin": "111.43.128.132", \n "url": "https://httpbin.org/get"\n}\n'
# 自动选择适当的编码,对 .content解码
response.text
'{\n "args": {}, \n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "Host": "httpbin.org", \n "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.58", \n "X-Amzn-Trace-Id": "Root=1-5fa0cbda-7feeafcb2b0b5f78242e2d3e"\n }, \n "origin": "111.43.128.132", \n "url": "https://httpbin.org/get"\n}\n'
eval(response.text)['origin']
# 使用 eval 将字符串转换为字典 , 提取数据
'111.43.128.132'
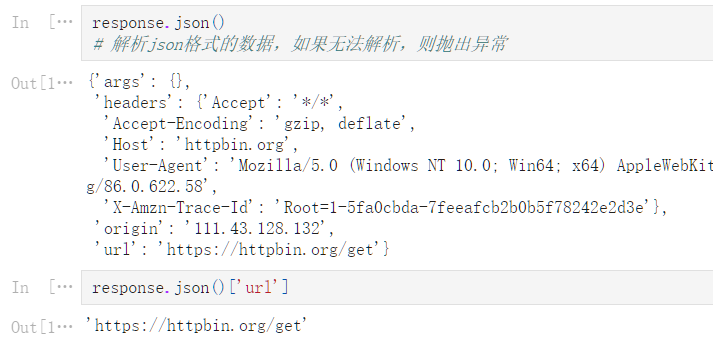
response.json()
# 解析json格式的数据,如果无法解析,则抛出异常
{'args': {},
'headers': {'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Host': 'httpbin.org',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36 Edg/86.0.622.58',
'X-Amzn-Trace-Id': 'Root=1-5fa0cbda-7feeafcb2b0b5f78242e2d3e'},
'origin': '111.43.128.132',
'url': 'https://httpbin.org/get'}
response.json()['url']
'https://httpbin.org/get'
request_params = '''
requests 方法 请求参数
• url 请求的URL地址
• params GET请求参数
• data POST请求参数
• json 同样是POST请求参数,要求服务端接收json格式的数据
• headers 请求头字典
• cookies cookies信息(字典或CookieJar)
• files 上传文件
• auth HTTP鉴权信息
• timeout 等待响应时间,单位秒
• allow_redirects 是否允许重定向
• proxies 代理信息
• verify 是否校验证书
• stream 如果为False,则响应内容将直接全部下载
• cert 客户端证书地址
'''
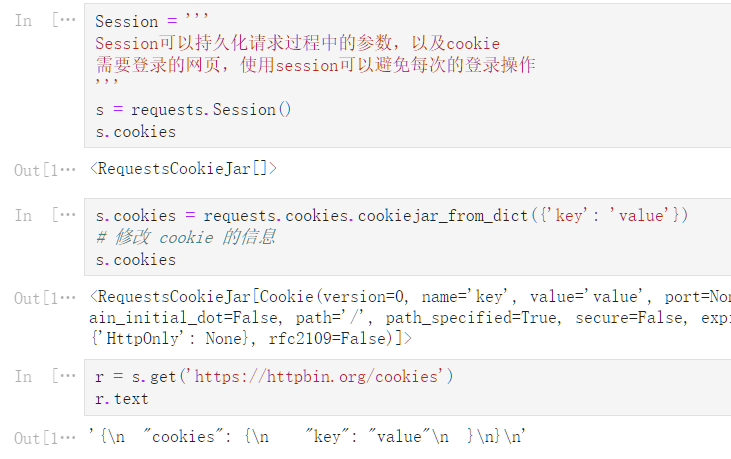
Session = '''
Session可以持久化请求过程中的参数,以及cookie
需要登录的网页,使用session可以避免每次的登录操作
'''
s = requests.Session()
s.cookies
<RequestsCookieJar[]>
s.cookies = requests.cookies.cookiejar_from_dict({'key': 'value'})
# 修改 cookie 的信息
s.cookies
<RequestsCookieJar[Cookie(version=0, name='key', value='value', port=None, port_specified=False, domain='', domain_specified=False, domain_initial_dot=False, path='/', path_specified=True, secure=False, expires=None, discard=True, comment=None, comment_url=None, rest={'HttpOnly': None}, rfc2109=False)]>
r = s.get('https://httpbin.org/cookies')
r.text
'{\n "cookies": {\n "key": "value"\n }\n}\n'
'''
Session 提供默认值
'''
s = requests.Session()
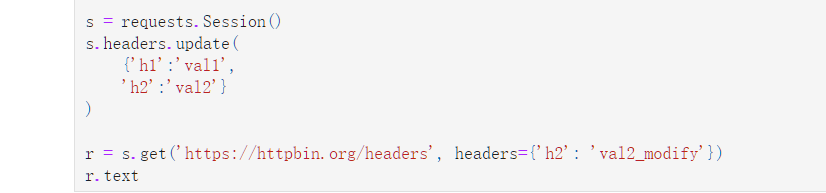
s.headers.update(
{'h1':'val1',
'h2':'val2'}
)
r = s.get('https://httpbin.org/headers', headers={'h2': 'val2_modify'})
r.text
'{\n "headers": {\n "Accept": "*/*", \n "Accept-Encoding": "gzip, deflate", \n "H1": "val1", \n "H2": "val2_modify", \n "Host": "httpbin.org", \n "User-Agent": "python-requests/2.24.0", \n "X-Amzn-Trace-Id": "Root=1-5fa0cbde-38199df23237b30c6c65df0c"\n }\n}\n'
Response = '''
字段
• cookies 返回CookieJar对象
• encoding 报文的编码
• headers 响应头
• history 重定向的历史记录
• status_code 响应状态码,如200
• elaspsed 发送请求到接收响应耗时
• text 解码后的报文主体
• content 字节码,可能在raw的基础上解压
方法
• json() 解析json格式的响应
• iter_content() 需配置stream=True,指定chunk_size大小
• iter_lines() 需配置stream=True,每次返回一行
• raise_for_status() 400-500之间将抛出异常
• close()
'''
bs4 库
from bs4 import BeautifulSoup,element
# 导入 BeautifulSoup
import lxml
import requests
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
soup = BeautifulSoup(html_doc,'lxml') #创建 beautifulsoup 对象
soup1 = BeautifulSoup(open('index.html'))
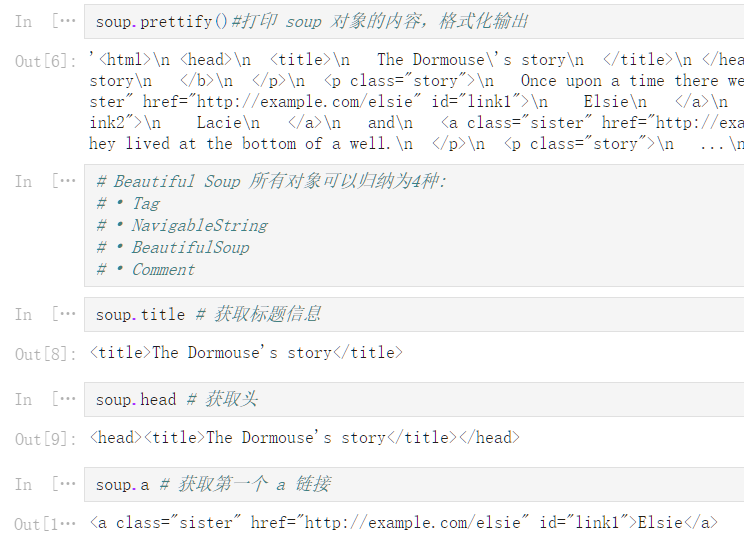
soup.prettify()#打印 soup 对象的内容,格式化输出
'<html>\n <head>\n <title>\n The Dormouse\'s story\n </title>\n </head>\n <body>\n <p class="title">\n <b>\n The Dormouse\'s story\n </b>\n </p>\n <p class="story">\n Once upon a time there were three little sisters; and their names were\n <a class="sister" href="http://example.com/elsie" id="link1">\n Elsie\n </a>\n ,\n <a class="sister" href="http://example.com/lacie" id="link2">\n Lacie\n </a>\n and\n <a class="sister" href="http://example.com/tillie" id="link3">\n Tillie\n </a>\n ;\nand they lived at the bottom of a well.\n </p>\n <p class="story">\n ...\n </p>\n </body>\n</html>'
# Beautiful Soup 所有对象可以归纳为4种:
# • Tag
# • NavigableString
# • BeautifulSoup
# • Comment
soup.title # 获取标题信息
<title>The Dormouse's story</title>
soup.head # 获取头
<head><title>The Dormouse's story</title></head>
soup.a # 获取第一个 a 链接
<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
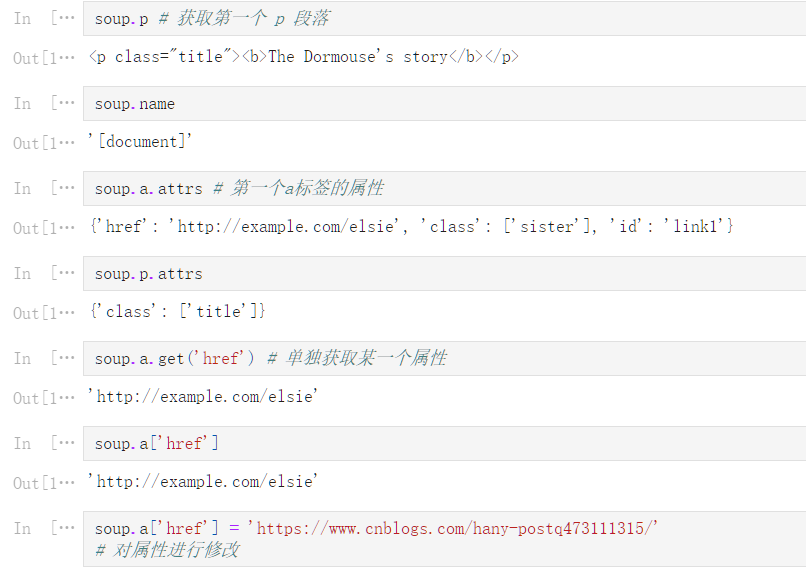
soup.p # 获取第一个 p 段落
<p class="title"><b>The Dormouse's story</b></p>
soup.name
'[document]'
soup.a.attrs # 第一个a标签的属性
{'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
soup.p.attrs
{'class': ['title']}
soup.a.get('href') # 单独获取某一个属性
'http://example.com/elsie'
soup.a['href']
'http://example.com/elsie'
soup.a['href'] = 'https://www.cnblogs.com/hany-postq473111315/'
# 对属性进行修改
del soup.a['href'] # 删除属性
soup.p.string # 使用 string 获取内容
"The Dormouse's story"
soup.a.string # 输出 a 的内容
'Elsie'
'''
.string 输出的内容,已经把注释符号去掉了,可能会带来麻烦
'''
print(type(soup.a.string))
if type(soup.a.string)==element.Comment:
print(soup.a.string)
<class 'bs4.element.NavigableString'>
soup
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
soup.head.contents # 将tag的子节点以列表的方式输出
[<title>The Dormouse's story</title>]
soup.head.contents[0] # 列表方式取值
<title>The Dormouse's story</title>
soup.head.children # list 生成器对象
<list_iterator at 0x292935d4fc8>
for item in soup.head.children:
print(item)
# 通过循环输出
<title>The Dormouse's story</title>
'''
.contents 和 .children 属性仅包含tag的直接子节点,
.descendants 属性可以对所有tag的子孙节点进行递归循环
'''
for item in soup.descendants:
print(item)
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
<head><title>The Dormouse's story</title></head>
<title>The Dormouse's story</title>
The Dormouse's story
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
<p class="title"><b>The Dormouse's story</b></p>
<b>The Dormouse's story</b>
The Dormouse's story
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>
Elsie
,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
Lacie
and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
Tillie
;
and they lived at the bottom of a well.
<p class="story">...</p>
...
soup.head.string # 查看内容
"The Dormouse's story"
soup.title.string
"The Dormouse's story"
soup.strings
<generator object Tag._all_strings at 0x00000292931AD548>
for string in soup.strings:
# soup.strings 为 soup 内的所有内容
print(string)
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.
...
# 使用 .stripped_strings 可以去除多余空白内容
for string in soup.stripped_strings:
print(string)
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
,
Lacie
and
Tillie
;
and they lived at the bottom of a well.
...
soup
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
soup.p.parent.name # 父标签的名称
'body'
soup.head.title.string.parent.name
'title'
'''
通过元素的 .parents 属性可以递归得到元素的所有父辈节点
'''
for parent in soup.head.title.string.parents:
# print(parent)
print(parent.name)
title
head
html
[document]
'''
.next_sibling 属性获取了该节点的下一个兄弟节点,
.previous_sibling 属性获取了该节点的上一个兄弟节点,
如果节点不存在,则返回 None
注:
因为空白或者换行也可以被视作一个节点,
所以得到的结果可能是空白或者换行。
'''
soup.p.next_sibling
'\n'
soup.p.previous_sibling
'\n'
soup.p.next_sibling.next_sibling
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
'''
.next_siblings 和 .previous_siblings
可以对当前节点的兄弟节点迭代
'''
for sibling in soup.a.next_siblings:
print(sibling)
,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
;
and they lived at the bottom of a well.
soup.head.next_element # 后一个节点
<title>The Dormouse's story</title>
soup.head.previous_element # 前一个节点
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>
'''
通过 .next_elements 和 .previous_elements 的迭代器
可以向前或向后访问文档的解析内容
'''
for element in soup.a.next_elements:
print(element)
Elsie
,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
Lacie
and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
Tillie
;
and they lived at the bottom of a well.
<p class="story">...</p>
...
'''
find_all() 方法搜索当前tag的所有tag子节点,
并判断是否符合过滤器的条件
'''
soup.find_all('b')
[<b>The Dormouse's story</b>]
import re
for tag in soup.find_all(re.compile('^b')):
# 通过传入正则表达式,进行查找
print(tag)
print(tag.name)
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
body
<b>The Dormouse's story</b>
b
soup.find_all(['a','b'])
# 传递列表,查找元素
[<b>The Dormouse's story</b>,
<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find_all(['a','b'])[2]['href']
# 查找指定元素
'http://example.com/lacie'
for tag in soup.find_all(True):
# 查找所有的 tag,不会返回字符串节点
print(tag.name)
html
head
title
body
p
b
p
a
a
a
p
# 传递方法
def has_href(tag):
# 如果存在就返回 True
return tag.has_attr('href')
soup.find_all(has_href)
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find_all(id = 'link2')
# 寻找指定的属性值
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
soup.find_all(href = re.compile('tillie'))
[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# 使用多个指定名字的参数可以同时过滤tag的多个属性
soup.find_all(href=re.compile("tillie"), id='link3')
[<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
# class_ 代替 class 进行查找
soup.find_all('a',class_ = 'sister')
[<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
'''
通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag
'''
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')
data_soup.find_all(attrs = {'data-foo':'value'})
# attrs = {'data-foo':'value'} 进行筛选
[<div data-foo="value">foo!</div>]
'''
通过 text 参数可以搜索文档中的字符串内容
text 参数接受 字符串 , 正则表达式 , 列表, True
'''
soup.find_all(text=["Tillie", "Elsie", "Lacie"])
['Elsie', 'Lacie', 'Tillie']
soup.find_all(text="Tillie")
['Tillie']
soup.find_all(text=re.compile("Dormouse"))
["The Dormouse's story", "The Dormouse's story"]
# 使用 limit 参数限制返回结果的数量
soup.find_all('a',limit = 2)
[<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
'''
调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点
如果只想搜索tag的直接子节点,可以使用参数 recursive=False
'''
soup.html.find_all('title',recursive=False)
[]
soup.html.find_all('title',recursive=True)
[<title>The Dormouse's story</title>]
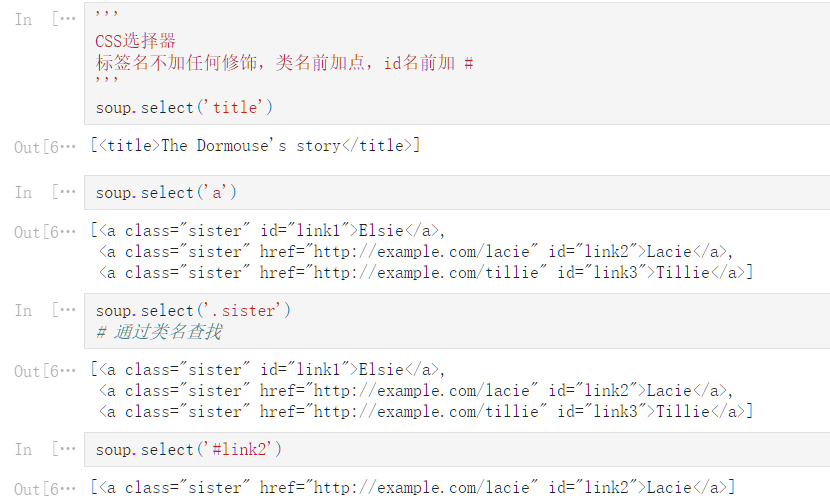
'''
CSS选择器
标签名不加任何修饰,类名前加点,id名前加 #
'''
soup.select('title')
[<title>The Dormouse's story</title>]
soup.select('a')
[<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('.sister')
# 通过类名查找
[<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.select('#link2')
[<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>]
'''
查找 p 标签中,id 等于 link1的内容,二者需要用空格分开
一定注意是 p 标签下的
'''
soup.select("p #link1")
[<a class="sister" id="link1">Elsie</a>]
soup.select('head > title')
[<title>The Dormouse's story</title>]
soup.select('a[class="sister"]')
# 查找时还可以加入属性元素,属性需要用中括号括起来
[<a class="sister" id="link1">Elsie</a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
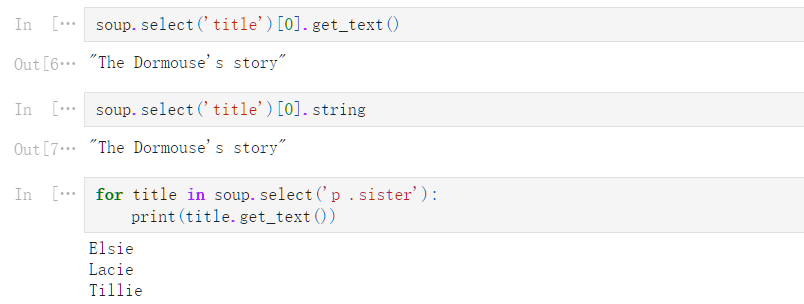
'''
select 选择后,使用 get_text() 方法获取内容
'''
soup.select('title')
[<title>The Dormouse's story</title>]
soup.select('title')[0].get_text()
"The Dormouse's story"
soup.select('title')[0].string
"The Dormouse's story"
for title in soup.select('p .sister'):
print(title.get_text())
Elsie
Lacie
Tillie
'''
lxml 库
import lxml
lxml_roles = '''
标签名 选取此节点的所有子节点
/ 从当前节点选取直接子节点
// 从当前节点选取子孙节点
. 选取当前节点
.. 选取当前节点的父节点
@ 选取属性
* 通配符,选择所有元素节点与元素名
@* 选取所有属性
[@attrib] 选取具有给定属性的所有元素
[@attrib='value'] 选取给定属性具有给定值的所有元素
[tag] 选取所有具有指定元素的直接子节点
[tag='text'] 选取所有具有指定元素并且文本内容是 text 节点
'''
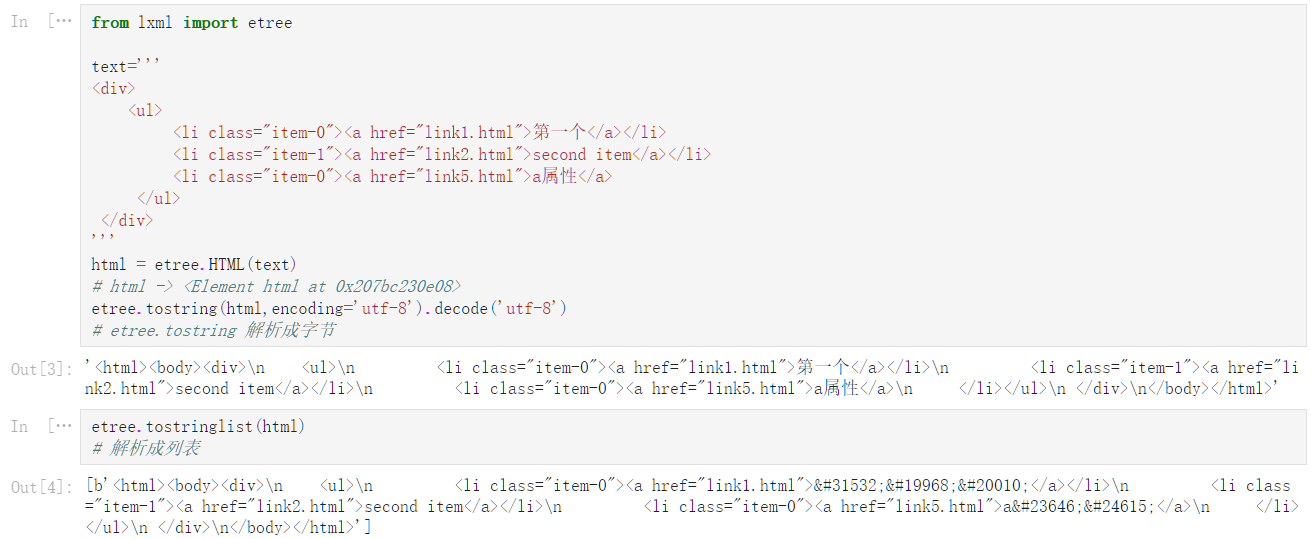
from lxml import etree
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">第一个</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0"><a href="link5.html">a属性</a>
</ul>
</div>
'''
html = etree.HTML(text)
# html -> <Element html at 0x207bc230e08>
etree.tostring(html,encoding='utf-8').decode('utf-8')
# etree.tostring 解析成字节
'<html><body><div>\n <ul>\n <li class="item-0"><a href="link1.html">第一个</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-0"><a href="link5.html">a属性</a>\n </li></ul>\n </div>\n</body></html>'
etree.tostringlist(html)
# 解析成列表
[b'<html><body><div>\n <ul>\n <li class="item-0"><a href="link1.html">第一个</a></li>\n <li class="item-1"><a href="link2.html">second item</a></li>\n <li class="item-0"><a href="link5.html">a属性</a>\n </li></ul>\n </div>\n</body></html>']
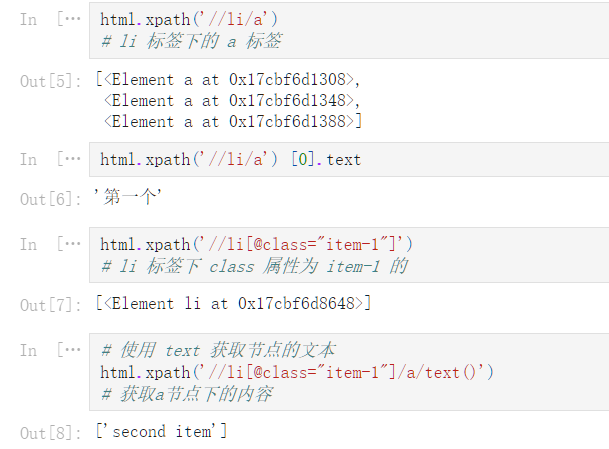
html.xpath('//li/a')
# li 标签下的 a 标签
[<Element a at 0x17cbf6d1308>,
<Element a at 0x17cbf6d1348>,
<Element a at 0x17cbf6d1388>]
html.xpath('//li/a') [0].text
'第一个'
html.xpath('//li[@class="item-1"]')
# li 标签下 class 属性为 item-1 的
[<Element li at 0x17cbf6d8648>]
# 使用 text 获取节点的文本
html.xpath('//li[@class="item-1"]/a/text()')
# 获取a节点下的内容
['second item']
from lxml import etree
from lxml.etree import HTMLParser
text='''
<div>
<ul>
<li class="item-0"><a href="link1.html">第一个</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
</ul>
</div>
'''
html = etree.HTML(text,etree.HTMLParser())
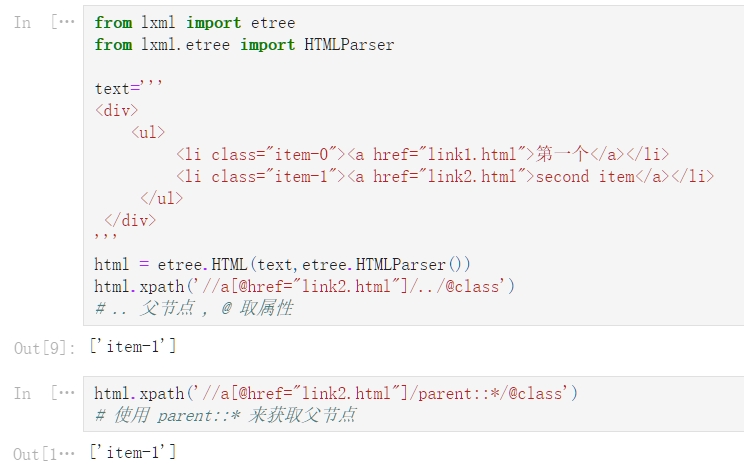
html.xpath('//a[@href="link2.html"]/../@class')
# .. 父节点 , @ 取属性
['item-1']
html.xpath('//a[@href="link2.html"]/parent::*/@class')
# 使用 parent::* 来获取父节点
['item-1']
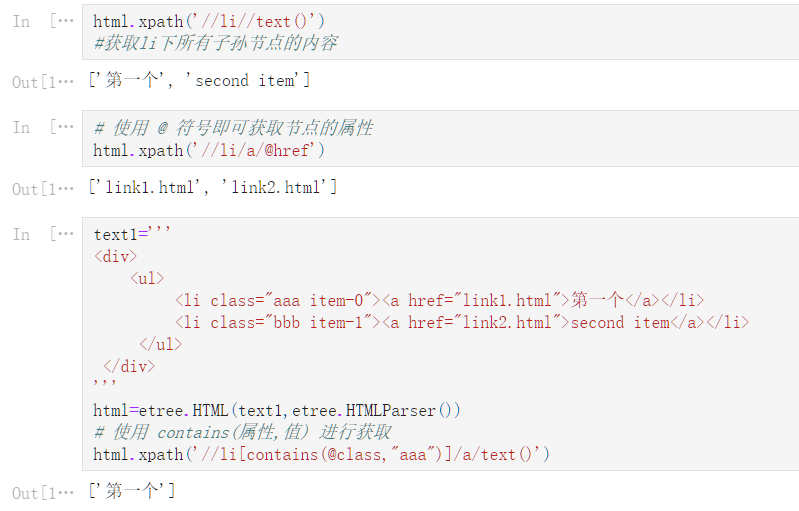
html.xpath('//li//text()')
#获取li下所有子孙节点的内容
['第一个', 'second item']
# 使用 @ 符号即可获取节点的属性
html.xpath('//li/a/@href')
['link1.html', 'link2.html']
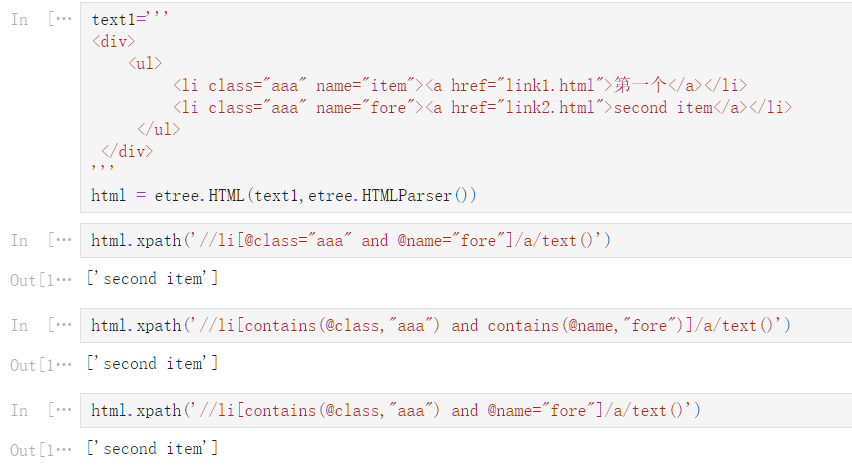
text1='''
<div>
<ul>
<li class="aaa item-0"><a href="link1.html">第一个</a></li>
<li class="bbb item-1"><a href="link2.html">second item</a></li>
</ul>
</div>
'''
html=etree.HTML(text1,etree.HTMLParser())
# 使用 contains(属性,值) 进行获取
html.xpath('//li[contains(@class,"aaa")]/a/text()')
['第一个']
text1='''
<div>
<ul>
<li class="aaa" name="item"><a href="link1.html">第一个</a></li>
<li class="aaa" name="fore"><a href="link2.html">second item</a></li>
</ul>
</div>
'''
html = etree.HTML(text1,etree.HTMLParser())
html.xpath('//li[@class="aaa" and @name="fore"]/a/text()')
['second item']
html.xpath('//li[contains(@class,"aaa") and contains(@name,"fore")]/a/text()')
['second item']
html.xpath('//li[contains(@class,"aaa") and @name="fore"]/a/text()')
['second item']
lxml_operators = '''
or 或
and 与
mod 取余
| 取两个节点的集合
+ 加 , - 减 , * 乘 , div 除
= 等于 , != 不等于 , < 小于
<= 小于或等于 , > 大于 , >= 大于或等于
'''
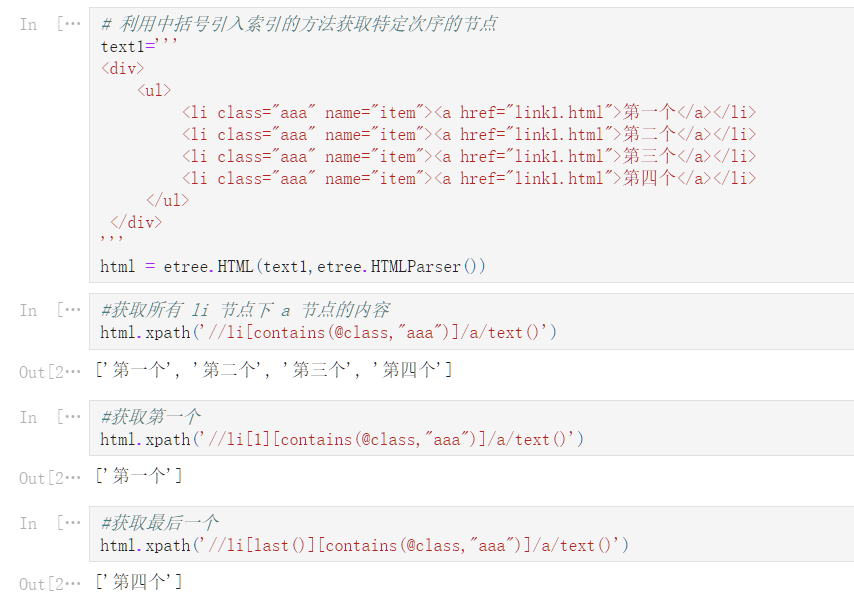
# 利用中括号引入索引的方法获取特定次序的节点
text1='''
<div>
<ul>
<li class="aaa" name="item"><a href="link1.html">第一个</a></li>
<li class="aaa" name="item"><a href="link1.html">第二个</a></li>
<li class="aaa" name="item"><a href="link1.html">第三个</a></li>
<li class="aaa" name="item"><a href="link1.html">第四个</a></li>
</ul>
</div>
'''
html = etree.HTML(text1,etree.HTMLParser())
#获取所有 li 节点下 a 节点的内容
html.xpath('//li[contains(@class,"aaa")]/a/text()')
['第一个', '第二个', '第三个', '第四个']
#获取第一个
html.xpath('//li[1][contains(@class,"aaa")]/a/text()')
['第一个']
#获取最后一个
html.xpath('//li[last()][contains(@class,"aaa")]/a/text()')
['第四个']
#获取第三个
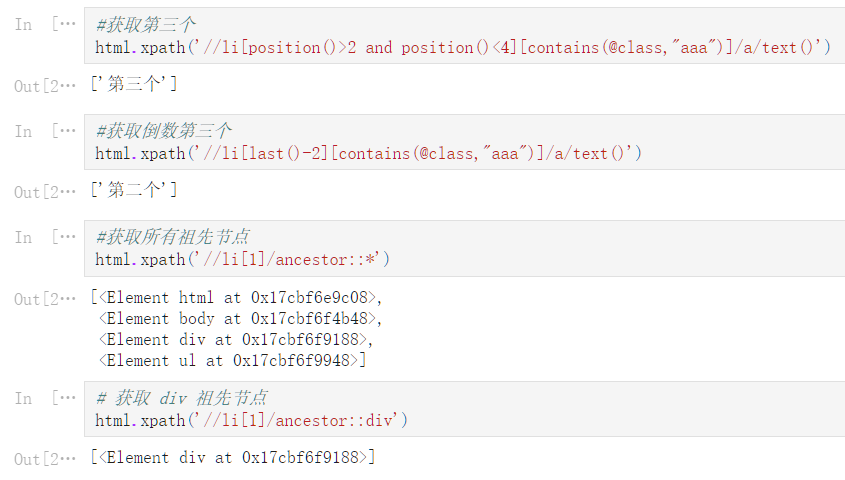
html.xpath('//li[position()>2 and position()<4][contains(@class,"aaa")]/a/text()')
['第三个']
#获取倒数第三个
html.xpath('//li[last()-2][contains(@class,"aaa")]/a/text()')
['第二个']
#获取所有祖先节点
html.xpath('//li[1]/ancestor::*')
[<Element html at 0x17cbf6e9c08>,
<Element body at 0x17cbf6f4b48>,
<Element div at 0x17cbf6f9188>,
<Element ul at 0x17cbf6f9948>]
# 获取 div 祖先节点
html.xpath('//li[1]/ancestor::div')
[<Element div at 0x17cbf6f9188>]
# 获取所有属性值
html.xpath('//li[1]/attribute::*')
['aaa', 'item']
# 获取所有直接子节点
html.xpath('//li[1]/child::*')
[<Element a at 0x17cbf6f07c8>]
# 获取所有子孙节点的 a 节点
html.xpath('//li[1]/descendant::a')
[<Element a at 0x17cbf6f07c8>]
# 获取当前子节点之后的所有节点
html.xpath('//li[1]/following::*')
[<Element li at 0x17cbf6fedc8>,
<Element a at 0x17cbf6f0d48>,
<Element li at 0x17cbf6fee08>,
<Element a at 0x17cbf6f0d88>,
<Element li at 0x17cbf6fee48>,
<Element a at 0x17cbf6f0dc8>]
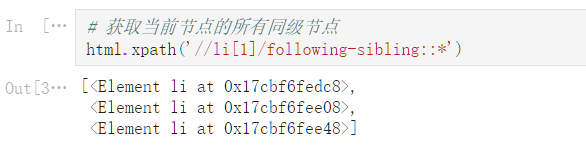
# 获取当前节点的所有同级节点
html.xpath('//li[1]/following-sibling::*')
[<Element li at 0x17cbf6fedc8>,
<Element li at 0x17cbf6fee08>,
<Element li at 0x17cbf6fee48>]
本文来自博客园,作者:Hany47315,转载请注明原文链接:https://www.cnblogs.com/hany-postq473111315/p/14256041.html
