

贝叶斯个性化排序(Bayesian Personalized Ranking, 以下简称BPR)
原文链接:https://www.jianshu.com/p/ba1936ee0b69
https://www.cnblogs.com/pinard/p/9128682.html
------------------------------------------------------------------------------------------------------------------------------------------------------------
排序推荐算法大体上可以分为三类,第一类排序算法类别是点对方法(Pointwise Approach),这类算法将排序问题被转化为分类、回归之类的问题,并使用现有分类、回归等方法进行实现。第二类排序算法是成对方法(Pairwise Approach),在序列方法中,排序被转化为对序列分类或对序列回归。所谓的pair就是成对的排序,比如(a,b)一组表明a比b排的靠前。第三类排序算法是列表方法(Listwise Approach),它采用更加直接的方法对排序问题进行了处理。它在学习和预测过程中都将排序列表作为一个样本。排序的组结构被保持。
之前我们介绍的算法大都是Pointwise的方法,今天我们来介绍一种Pairwise的方法:贝叶斯个性化排序(Bayesian Personalized Ranking, 以下简称BPR)
1.BPR算法简介
1.1基本思路
在BPR算法中,我们将任意用户u对应的物品进行标记,如果用户u在同时有物品i和j的时候点击了i,那么我们就得到了一个三元组<u,i,j>,它表示对用户u来说,i的排序要比j靠前。如果对于用户u来说我们有m组这样的反馈,那么我们就可以得到m组用户u对应的训练样本。
这里,我们做出两个假设:
- 每个用户之间的偏好行为相互独立,即用户u在商品i和j之间的偏好和其他用户无关。
- 同一用户对不同物品的偏序相互独立,也就是用户u在商品i和j之间的偏好和其他的商品无关。
为了便于表述,我们用>u符号表示用户u的偏好,上面的<u,i,j>可以表示为:i >u j。
在BPR中,我们也用到了类似矩阵分解的思想,对于用户集U和物品集I对应的U*I的预测排序矩阵,我们期望得到两个分解后的用户矩阵W(|U|×k)和物品矩阵H(|I|×k),满足:
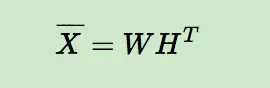
那么对于任意一个用户u,对应的任意一个物品i,我们预测得出的用户对该物品的偏好计算如下:
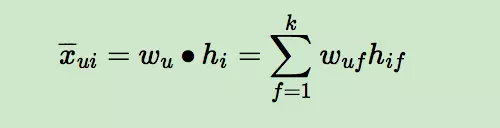
而模型的最终目标是寻找合适的矩阵W和H,让X-(公式打不出来,这里代表的是X上面有一个横线,即W和H矩阵相乘后的结果)和X(实际的评分矩阵)最相似。看到这里,也许你会说,BPR和矩阵分解没有什区别呀?是的,到目前为止的基本思想是一致的,但是具体的算法运算思路,确实千差万别的,我们慢慢道来。
1.2 算法运算思路
BPR基于最大后验估计P(W,H|>u)来求解模型参数W,H,这里我们用θ来表示参数W和H, >u代表用户u对应的所有商品的全序关系,则优化目标是P(θ|>u)。根据贝叶斯公式,我们有:
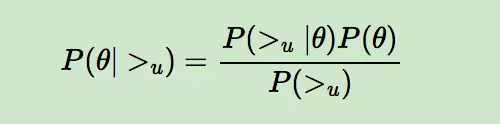
由于我们求解假设了用户的排序和其他用户无关,那么对于任意一个用户u来说,P(>u)对所有的物品一样,所以有
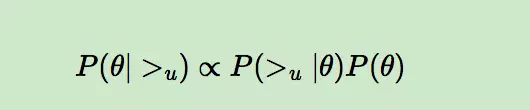
这个优化目标转化为两部分。第一部分和样本数据集D有关,第二部分和样本数据集D无关。
第一部分:
对于第一部分,由于我们假设每个用户之间的偏好行为相互独立,同一用户对不同物品的偏序相互独立,所以有:
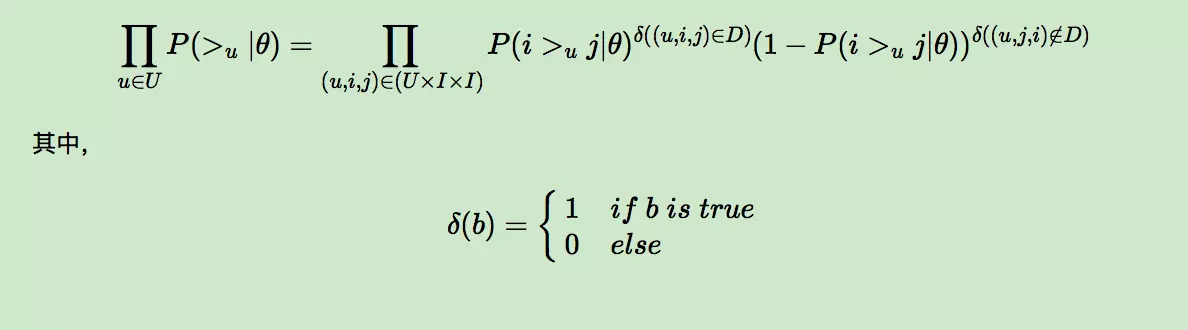
上面的式子类似于极大似然估计,若用户u相比于j来说更偏向i,那么我们就希望P(i >u j|θ)出现的概率越大越好。
上面的式子可以进一步改写成:
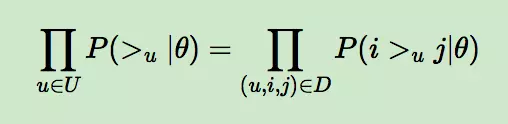
而对于P(i >u j|θ)这个概率,我们可以使用下面这个式子来代替:
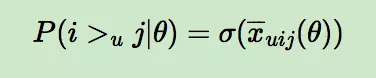
其中,σ(x)是sigmoid函数,σ里面的项我们可以理解为用户u对i和j偏好程度的差异,我们当然希望i和j的差异越大越好,这种差异如何体现,最简单的就是差值:
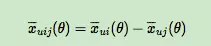
省略θ我们可以将式子简略的写为:
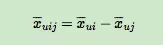
因此优化目标的第一项可以写作:
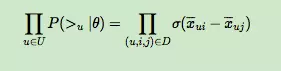
哇,是不是很简单的思想,对于训练数据中的<u,i,j>,用户更偏好于i,那么我们当然希望在X-矩阵中ui对应的值比uj对应的值大,而且差距越大越好
第二部分:
当θ的先验分布是正态分布时,其实就是给损失函数加入了正则项,因此我们可以假定θ的先验分布是正态分布:

所以:

因此,最终的最大对数后验估计函数可以写作:

剩下的我们就可以通过梯度上升法(因为是要让上式最大化)来求解了。
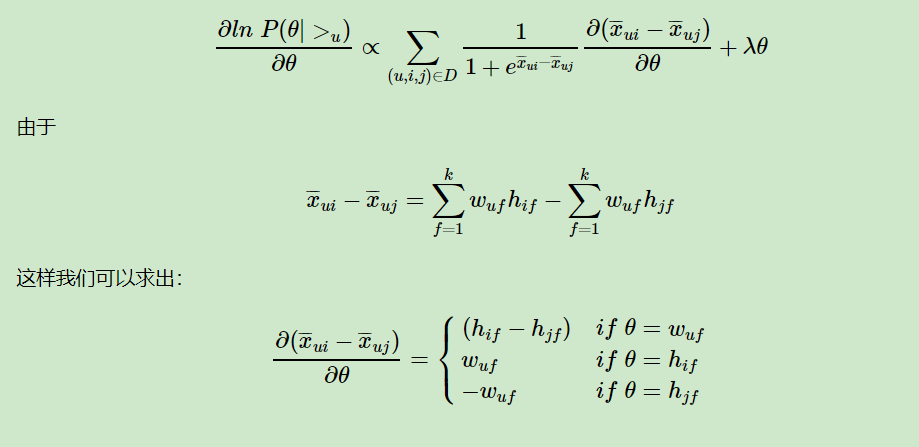
1.3 BPR算法流程
下面简要总结下BPR的算法训练流程:
输入:训练集D三元组,梯度步长αα, 正则化参数λλ,分解矩阵维度k。
输出:模型参数,矩阵W,HW,H
1. 随机初始化矩阵W,HW,H
2. 迭代更新模型参数:
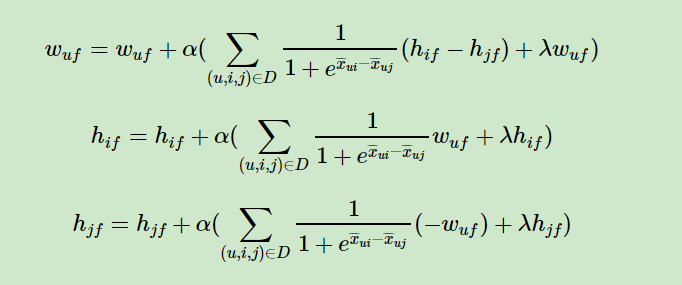
3. 如果W,HW,H收敛,则算法结束,输出W,H,否则回到步骤2.
当我们拿到W,HW,H后,就可以计算出每一个用户u对应的任意一个商品的排序分: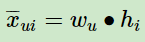 最终选择排序分最高的若干商品输出。
最终选择排序分最高的若干商品输出。
