

pandas 笔记
reset_index()用法总结
axis=0与axis=1 np中1是横轴 从左到右计算 按列名删除用1 按行删除用0 drop中 axis 默认为0,指删除行,因此删除columns时要指定axis=1
cut 函数 cut和qcut value_counts()
df.sort_values(by='列名',acsending="True")
import pandas as pd
#读csv xls
df=pd.read_csv('D:\\Anaconda3\\A\\1.csv',encoding='gbk')
df1=pd.read_excel('D:\\Anaconda3\\A\\1.xls',encoding='gbk')
print(df,df1)
#list转pd数据框
my_list=[('xiaoming','11'),('wang','22')]
df=pd.DataFrame(my_list,columns=['name','age'])
#插入mysql数据库 test是库名 xxx是表名 root:123mysql是账号密码
# pip install pymysql
# pip install mysql-connector-python
from sqlalchemy import create_engine
from sqlalchemy.types import *
df=pd.DataFrame({"班级":["一年级","二年级"],
"男生人数":[11,14],
"女生人数":[10,15]})
engin=create_engine('mysql+mysqlconnector://root:123mysql@127.0.0.1:3306/test')
df.to_sql("xxx",engin)

#打印数据框行列 df.shape

#打印数据框列名 df.columns
![]()
#打印索引

#打印数据类型

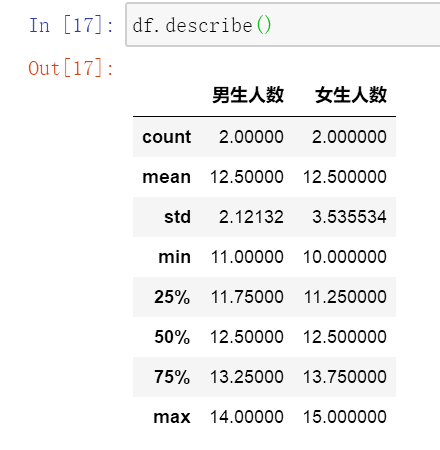
#打印数据摘要
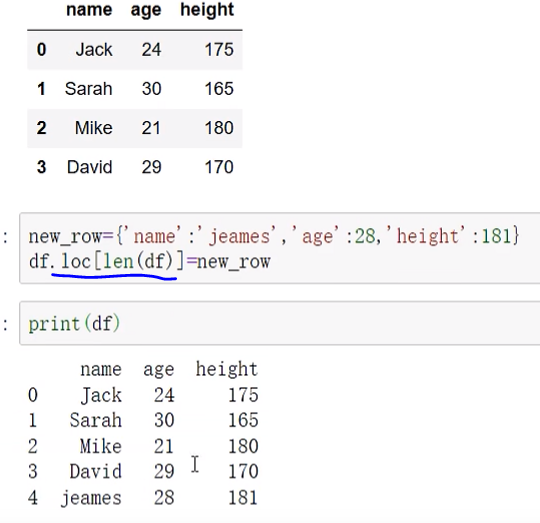
添加一行
添加一列

drop
labels 就是要删除的行列的名字,用列表给定
axis 默认为0,指删除行,因此删除columns时要指定axis=1;
index 直接指定要删除的行
columns 直接指定要删除的列
inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe;
inplace=True,则会直接在原数据上进行删除操作,删除后无法返回。
df.drop("index0-9")
或
df.drop(index=0-9,axis=0)#删除某行
df.drop(columns=["列名"],axis=1)或者df.drop(labels="ZZ",axis=1)#删除某列
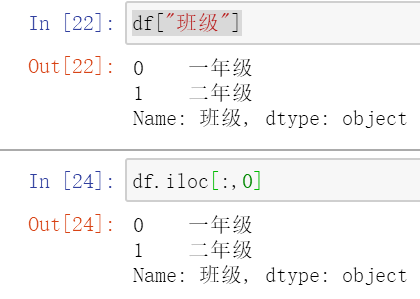
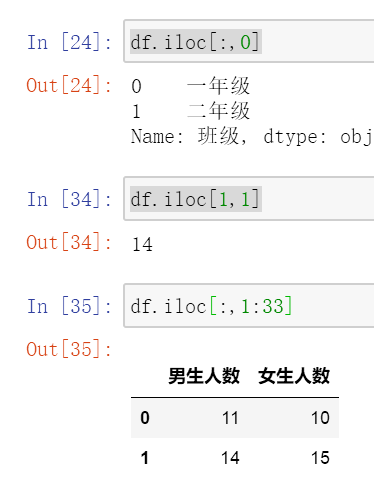
#打印行 loc[[0-9,"xxx"]] iloc[x:y-1,x:y-1]


#iloc打印列
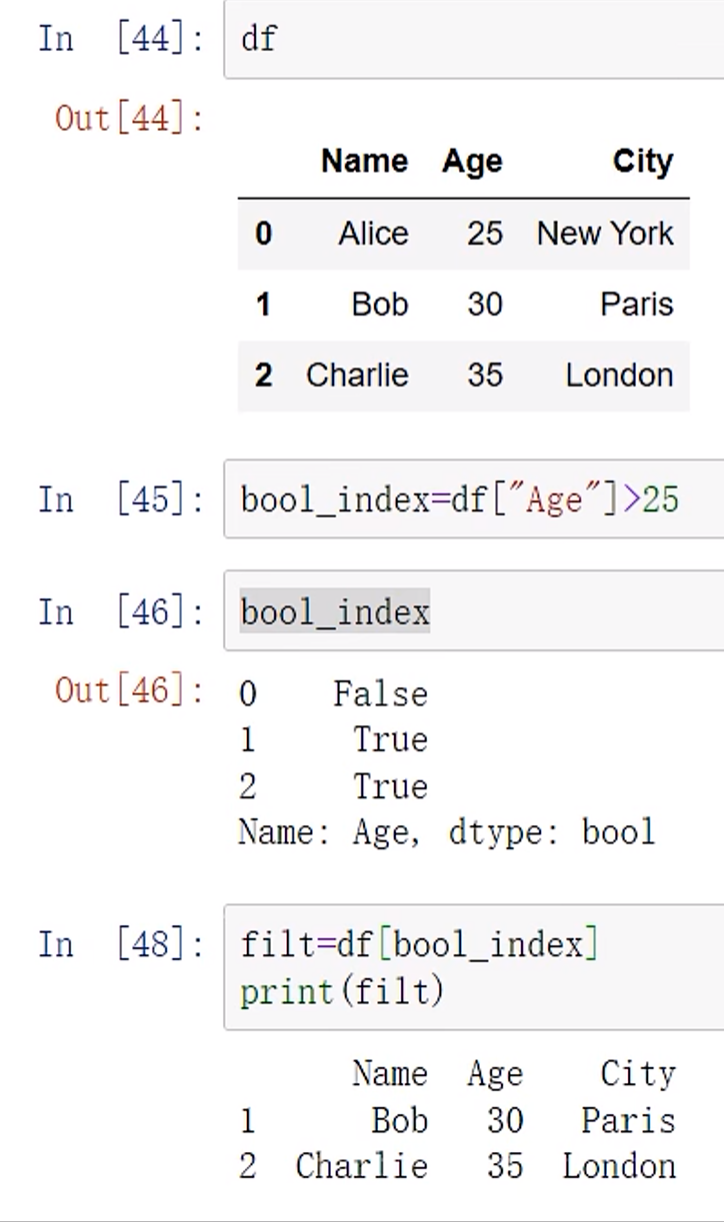
#bool_index
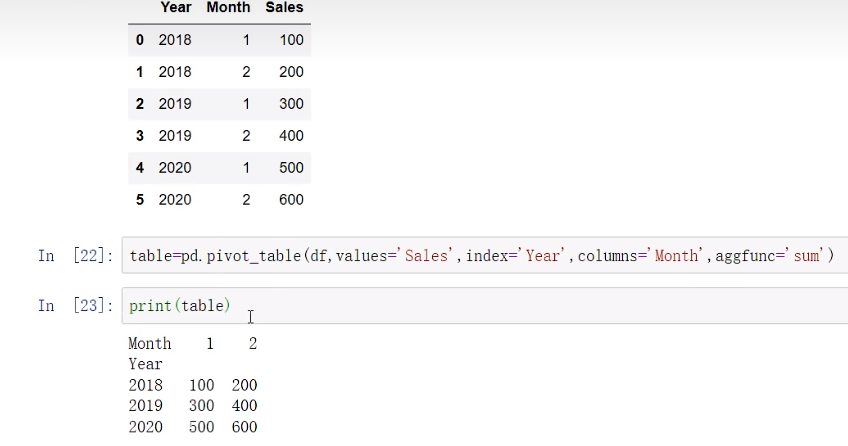
透视表 pivot_table aggfunc
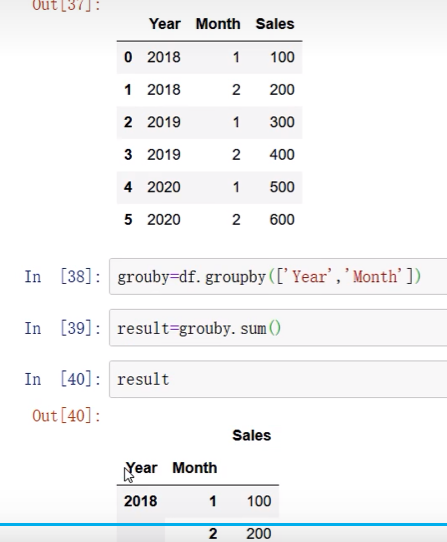
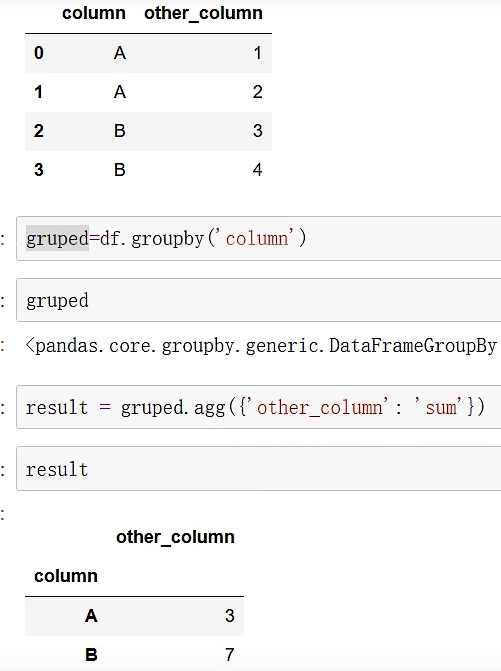
groupby
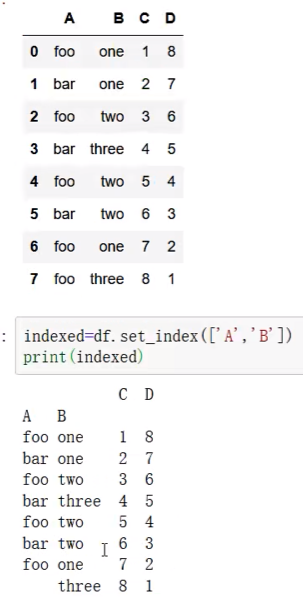
set_index 设置索引
reseted 重置索引

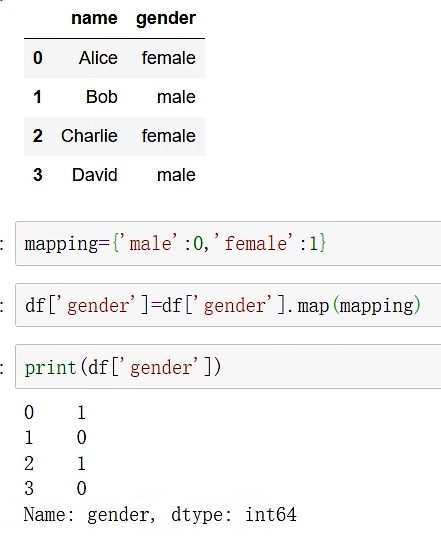
map
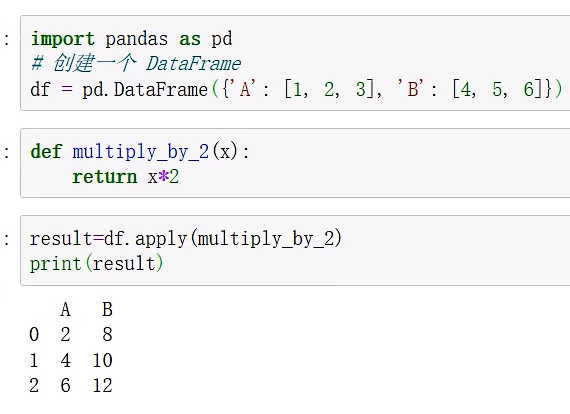
apply 自定义函数
agg
pd.agg({'A':['mean','max'],'B': 'var'})
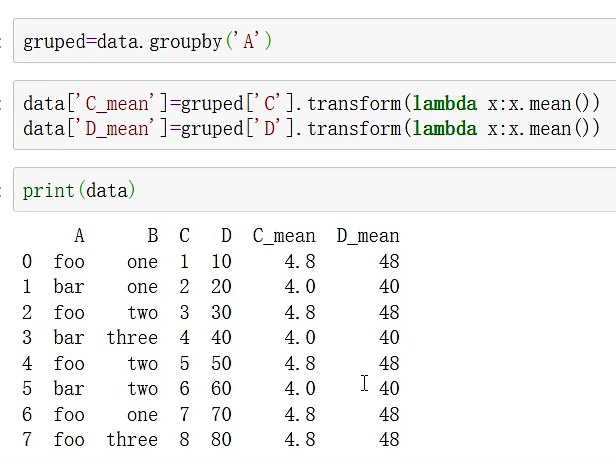
transform 24/5=4.8

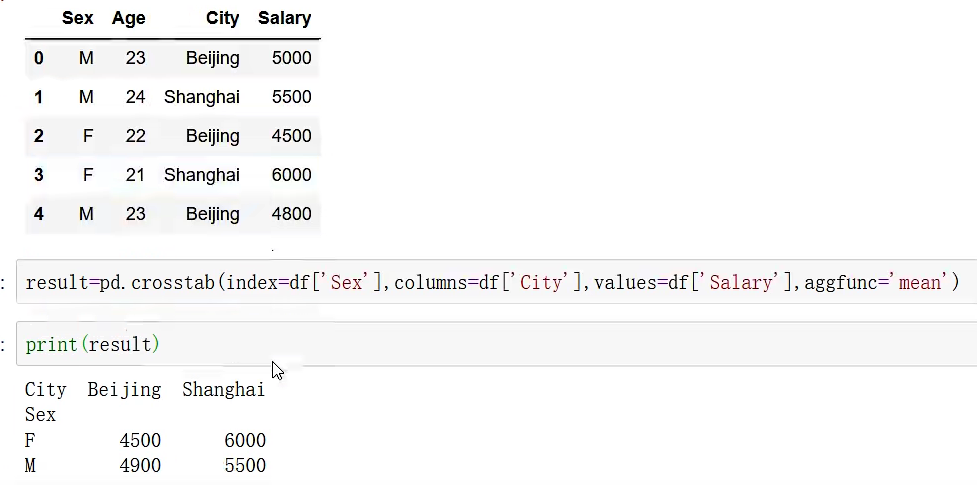
crosstable
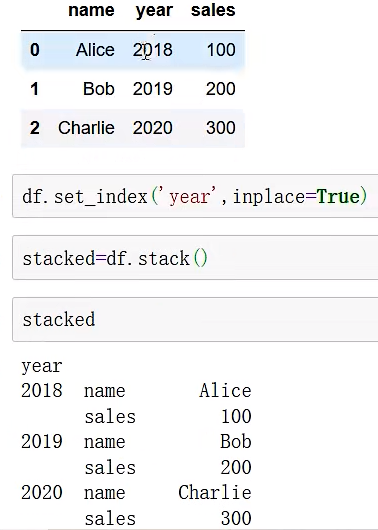
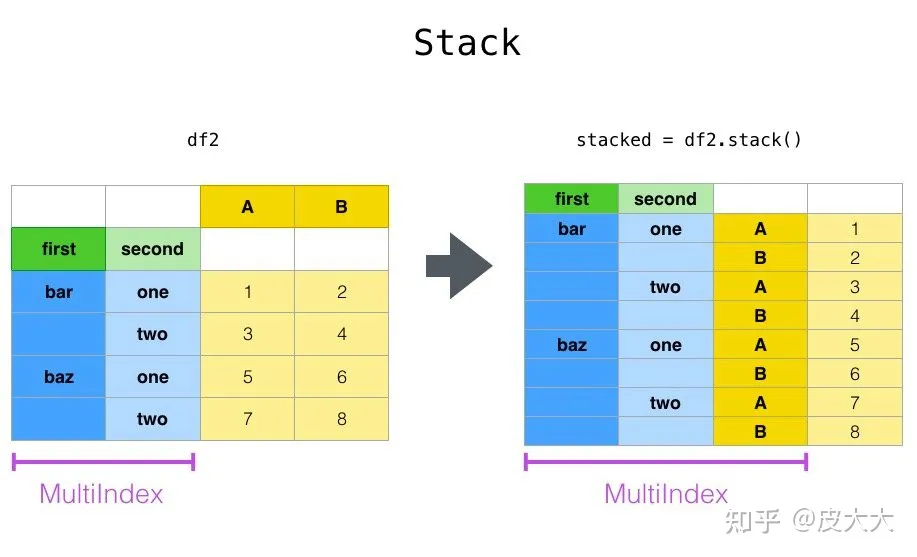
- stack: 将数据的列columns转旋转成行index
- unstack:将数据的行index旋转成列columns
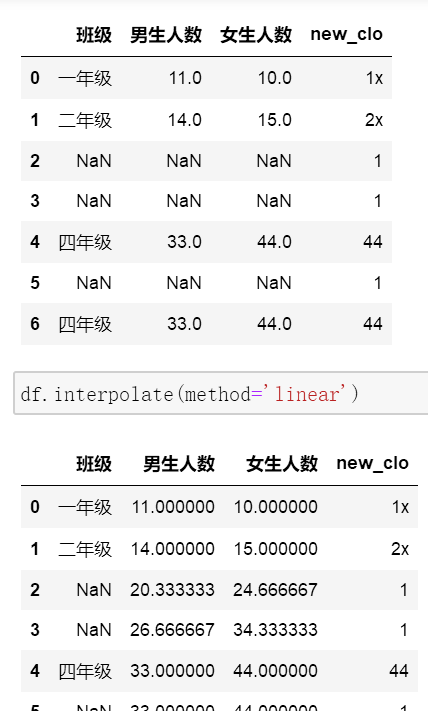
interpolate 数据插值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号