

hbase hadoop
hadoop: wget http://archive.apache.org/dist/hadoop/common/hadoop-3.1.0/hadoop-3.1.0.tar.gz --no-check-certificate hbase: wget http://archive.apache.org/dist/hbase/2.0.3/hbase-2.0.3-bin.tar.gz zookeeper: wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz --no-check-certificate ambari: wget http://archive.apache.org/dist/ambari/ambari-2.7.5/apache-ambari-2.7.5-src.tar.gz
jdk8 : http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
http://archive.apache.org/dist/hadoop/common/hadoop-3.1.0/ http://archive.apache.org/dist/hbase/2.0.3/ http://archive.apache.org/dist/ambari/
一、环境准备
三台机配置
目录准备
lvm 做3个盘 data_1 data_2 data_3 [root@slave1 ~]# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert lv_sdb data_1 -wi-ao---- <20.00g lv_sdc data_2 -wi-ao---- <20.00g lv_sdd data_3 -wi-ao---- <20.00g [root@slave1 ~]# pvs PV VG Fmt Attr PSize PFree /dev/sdb data_1 lvm2 a-- <20.00g 0 /dev/sdc data_2 lvm2 a-- <20.00g 0 /dev/sdd data_3 lvm2 a-- <20.00g 0 [root@slave1 ~]# vgs VG #PV #LV #SN Attr VSize VFree data_1 1 1 0 wz--n- <20.00g 0 data_2 1 1 0 wz--n- <20.00g 0 data_3 1 1 0 wz--n- <20.00g 0 [root@slave1 ~]# df -h|grep data /dev/mapper/data_1-lv_sdb 20G 41M 20G 1% /data_1 /dev/mapper/data_2-lv_sdc 20G 35M 20G 1% /data_2 /dev/mapper/data_3-lv_sdd 20G 35M 20G 1% /data_3
mkdir -pv /data_1/namenode /data_2/namenode /data_3/namenode /data_1/datanode /data_2/datanode /data_3/datanode
hostname (3台)
hostnamectl set-hostname master hostnamectl set-hostname slave1 hostnamectl set-hostname slave2
hosts (3台,0.0.0.0分别配置各自的hostname)
[root@master ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.67.130 master
192.168.67.131 slave1
192.168.67.132 slave2
0.0.0.0 master
[root@slave1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.67.130 master
192.168.67.131 slave1
192.168.67.132 slave2
0.0.0.0 slave1
免密登陆(3台)
ssh-keygen -t rsa -- 三台分别执行ssh-keygen -t rsa 不用输入密码,一路回车就行
#slave1
cp ~/.ssh/id_rsa.pub ~/.ssh/slave1_id_rsa.pub
scp ~/.ssh/slave1_id_rsa.pub master:~/.ssh/
#slave2
cp ~/.ssh/id_rsa.pub ~/.ssh/slave2_id_rsa.pub
scp ~/.ssh/slave2_id_rsa.pub master:~/.ssh/
#master
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/slave1_id_rsa.pub >> ~/.ssh/authorized_keys
cat ~/.ssh/slave2_id_rsa.pub >> ~/.ssh/authorized_kyes
scp ~/.ssh/authorized_keys slave1:~/.ssh
scp ~/.ssh/authorized_keys slave2:~/.ssh
-- 关闭防火墙 systemctl stop firewalld.service systemctl disable firewalld.service -- 关闭SELINUX sed -i s#'SELINUX=enforcing'#'SELINUX=disabled'#g /etc/selinux/config
jdk配置
tar xvf jdk-8u131-linux-x64.tar.gz -C /usr
##~/.bash_profile 添加如下 export JAVA_HOME=/usr/jdk1.8.0_131 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH
解压 拷贝 安装包
[root@master usr]# ls -lrt /usr|egrep 'had|zoo|jdk|amb|grep hba' drwxr-xr-x 8 10 143 255 Mar 15 2017 jdk1.8.0_131 drwxrwxr-x 19 zzx zzx 4096 Dec 13 2019 ambari-2.7.5 drwxr-xr-x 8 root root 157 Mar 13 21:12 zookeeper-3.8.0 drwxr-xr-x 12 zzx zzx 183 Mar 13 22:58 hadoop-3.1.0 #稍后分别拷到slave1 和slave2 (等env文件配置都配置好了再scp) scp -r zookeeper-3.8.0/ slave1:/usr/
环境变量配置
vi /etc/profile export HADOOP_HOME=/usr/hadoop-3.1.0 export PATH=$PATH:$HADOOP_HOME export ZOO_HOME=/usr/zookeeper-3.8.0 export PATH=$ZOO_HOME/bin:$PATH export HBASE_HOME=/usr/hbase-2.0.3 export PATH=$HBASE_HOME/bin:$PATH source /etc/profile
scp /etc/profile slave1:/etc/
scp /etc/profile slave2:/etc/
二、配置zookeep
cd zookeeper-3.8.0/
mkdir data
echo "1" > data/myid (scp目录zookeep后修改slave1和2的myid分别为3和4)
cp zoo_sample.cfg zoo.cfg vi zoo.cfg 添加如下 dataDir=/usr/zookeeper-3.8.0/data server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888
zookeep配置完毕 可以scp了,scp完记得修改 data/myid 内容
scp -r zookeeper-3.8.0/ slave1:/usr/ scp -r zookeeper-3.8.0/ slave2:/usr/
三、配置hadoop
cd /usr/hadoop-3.1.0 mkdir pid tmp
编辑workers文件,2.x是slaves文件
[root@master hadoop]# cat /usr/hadoop-3.1.0/etc/hadoop/workers
slave1
slave2
/usr/hadoop-3.1.0/etc/hadoop/hadoop-env.sh
[root@master usr]# cat hadoop-3.1.0/etc/hadoop/hadoop-env.sh |grep -v ^#|grep -v ^$ export JAVA_HOME=/usr/jdk1.8.0_131 export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)} case ${HADOOP_OS_TYPE} in Darwin*) export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.realm= " export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.kdc= " export HADOOP_OPTS="${HADOOP_OPTS} -Djava.security.krb5.conf= " ;; esac export HADOOP_PID_DIR=/usr/hadoop-3.1.0/pid/
/usr/hadoop-3.1.0/etc/hadoop/core-site.xml
cd /usr/hadoop-3.1.0/etc/hadoop vi core-site.xml 添加如下 <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-cluster</value> <description>集群名称</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop-3.1.0/tmp</value> <description>节点上本地的hadoop临时文件夹</description> </property> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> <description>zookeeper集群</description> </property> </configuration>
hdfs-site.xml


<configuration>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster</value>
<description>集群名称</description>
</property>
<property>
<name>dfs.ha.namenodes.hadoop-cluster</name>
<value>nn01,nn02</value>
<description>namenode名称,随便,可以是nn1,nn2,注意和下面保持一致</description>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster.nn01</name>
<value>master:9000</value>
<description>nn01的RPC通信地址,注意务必是9000,不要用8020之类的,否则ui会有点问题</description>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster.nn02</name>
<value>slave1:9000</value>
<description>同上</description>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster.nn01</name>
<value>master:9870</value>
<description>ui地址及端口(原先是50070),随便</description>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster.nn02</name>
<value>slave1:9870</value>
<description>同上</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;slave1:8485;slave2:8485/hadoop-cluster</value>
<description>指定NameNode的edits元数据的共享存储位置。也就是JournalNode列表该url的配置格式:qjournal://host1:port1;host2:port2;host3:port3/journalId;journalId推荐使用nameservice,默认端口号是:8485</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoop-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>高可用失败自动切换代理服务</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>禁用权限</description>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
<description>允许数据追加</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本数量</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data_1/namenode,/data_2/namenode,/data_3/namenode</value>
<description>namenode数据存放目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data_1/datanode,/data_2/datanode,/data_3/datanode</value>
<description>datanode数据存放目录</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data_1/journalnode,/data_2/journalnode,/data_3/journalnode</value>
<description>journalnode数据存放目录</description>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>开启NameNode失败自动切换</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>启用webhdfs</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
<description>配置sshfence隔离机制超时时间</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>使用sshfence隔离机制时需要ssh免登陆</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
<description>配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行</description>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>指定mr框架为yarn方式</description>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>开启RM高可用</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
<description>指定RM的cluster id</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>指定RM的名字</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master</value>
<description>指定RM的地址</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>slave1</value>
<description>指定RM的地址</description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master:2181,slave1:2181,slave2:2181</value>
<description>zookeeper集群</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description></description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description></description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>启用自动恢复</description>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>制定resourcemanager的状态信息存储在zookeeper集群上</description>
</property>
</configuration>
start-dfs.sh stop-dfs.sh
[root@master sbin]# cat /usr/hadoop-3.1.0/sbin/start-dfs.sh :添加如下 HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_ZKFC_USER=root HDFS_JOURNALNODE_USER=root HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
start-yarn.sh stop-yarn.sh
[root@master sbin]# cat start-yarn.sh #!/usr/bin/env bash YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
hadoop配置完毕 可以scp了
scp -r hadoop-3.1.0/ slave1:/usr/ scp -r hadoop-3.1.0/ slave2:/usr/
四、配置hbase
cd /usr/hbase-2.0.3/conf [root@master conf]# cat hbase-env.sh |grep -v ^#|grep -v ^$ export JAVA_HOME=/usr/jdk1.8.0_131 export HBASE_CLASSPATH=$HBASE_CLASSPATH:/usr/hadoop-3.1.0/etc/hadoop export HBASE_OPTS="$HBASE_OPTS -XX:+UseConcMarkSweepGC" export HBASE_LOG_DIR=${HBASE_HOME}/logs export HBASE_PID_DIR=/usr/hadoop-3.1.0/pid/ export HBASE_MANAGES_ZK=false
hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-cluster/hbase</value>
<description>hadoop集群名称</description>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2</value>
<description>zookeeper集群</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
<description>是否是完全分布式</description>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
<description>完全分布式式必须为false</description>
</property>
</configuration>
配置 regionservers
[root@master conf]# cat regionservers slave1 slave2
将hdfs-site.xml映射到conf下hdfs-site.xml
ln -s /usr/hadoop-3.1.0/etc/hadoop/hdfs-site.xml ./
[root@master conf]# ls -lrt hdfs-site.xml
lrwxrwxrwx 1 root root 42 Mar 13 20:55 hdfs-site.xml -> /usr/hadoop-3.1.0/etc/hadoop/hdfs-site.xml
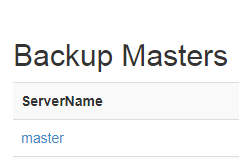
配置hmaster备节点,slave1或者slave2
[root@master conf]# cat backup-masters
slave2
hbase配置完毕,可以scp了
scp -r /usr/hbase-2.0.3/ slave1:/usr/ scp -r /usr/hbase-2.0.3/ slave2:/usr/
五、启动集群
zk (三台分别执行)
zkServer.sh start
[root@master zookeeper-3.8.0]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/zookeeper-3.8.0/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower
[root@slave1 ~]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/zookeeper-3.8.0/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: leader
[root@slave2 logs]# zkServer.sh status ZooKeeper JMX enabled by default Using config: /usr/zookeeper-3.8.0/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower
journalnode(三台分别执行)
hdfs --daemon start journalnode
[root@master zookeeper-3.8.0]# jps|grep -i journalnode 39949 JournalNode
遇到前面 0.0.0.0全部配置成master导致的报错,修改slave1的 0.0.0.0 save1
org.apache.hadoop.hdfs.qjournal.server.JournalNode: Failed to start journalnode.
格式化zkfc和namenode(master)节点,
hdfs zkfc -formatZK
hdfs name -format
启动hadoop,
sh ./sbin/start-all.sh
jps查进程
启动slave1的nn
# 同步fsimage # hdfs namenode -bootstrapStandby # 启动namenode # hdfs --daemon.sh start namenode
这一步好像没做,启动了半天,最后还删除了data下的文件重新格式化
rm -rf /data_1/* /data_2/* /data_3/*
遇到第二个nn无法启动的报错
ERROR org.apache.hadoop.hdfs.server.namenode.NameNode: Failed to start namenode. org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /data_1/namenode is in an inconsistent state: storage directory does not exist or is not accessible.
INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1: org.apache.hadoop.hdfs.server.common.InconsistentFSStateException: Directory /data_1/namenode is in an inconsistent state: storage directory does not exist or is not accessible.
检查
[root@master hadoop-3.1.0]# /usr/hadoop-3.1.0/bin/hdfs haadmin -getServiceState nn01 active [root@master hadoop-3.1.0]# /usr/hadoop-3.1.0/bin/hdfs haadmin -getServiceState nn02 standby
主备切换
[root@master hadoop-3.1.0]# ./sbin/hadoop-daemon.sh stop namenode
WARNING: Use of this script to stop HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon stop" instead.
[root@master hadoop-3.1.0]# hdfs haadmin -getServiceState nn02
active
[root@master hadoop-3.1.0]# hdfs haadmin -getServiceState nn01
2022-03-14 15:32:54,892 INFO ipc.Client: Retrying connect to server: master/192.168.67.130:9000. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From master/192.168.67.130 to master:9000 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
[root@master hadoop-3.1.0]# ./sbin/hadoop-daemon.sh start namenode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
[root@master hadoop-3.1.0]# hdfs haadmin -getServiceState nn01
standby
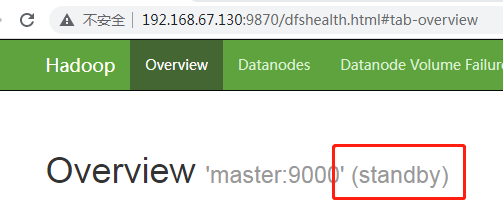
启动hbase
start-hbase.sh
jps
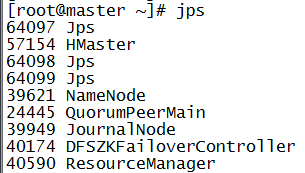
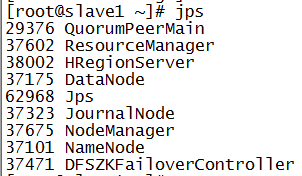
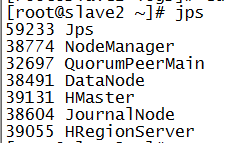
主备切换
slave1的日志
master.ActiveMasterManager: Another master is the active master, master,16000,1647186090722; waiting to become the next active master 停掉主 观察主备切换的日志 master执行:bin/hbase-daemon.sh stop master
slave1的日志 Deleting ZNode for /hbase/backup-masters/slave2,16000,1647186098752 from backup master directory 2022-03-14 09:25:36,802 INFO [Thread-13] master.ActiveMasterManager: Registered as active master=slave2,16000,1647186098752 2022-03-14 09:25:41,151 INFO [Thread-13] fs.HFileSystem: Added intercepting call to namenode#getBlockLocations so can do block reordering using class org.apache.hadoop.hbase.fs.HFileSystem$ReorderWALBlocks 2022-03-14 09:25:41,320 INFO [Thread-13] coordination.SplitLogManagerCoordination: Found 0 orphan tasks and 0 rescan nodes 2022-03-14 09:25:41,905 INFO [Thread-13] zookeeper.ReadOnlyZKClient: Connect 0x10171603 to master:2181,slave1:2181,slave2:2181 with session timeout=90000ms, retries 30, retry interval 1000ms, keepAlive=60000ms
http://192.168.67.130:16010/master-status#alltasks
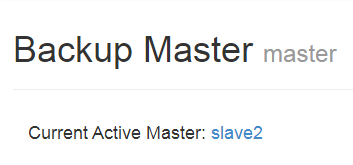
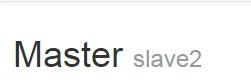
http://192.168.67.132:16010/master-status#alltasks
Ambari
https://archive.cloudera.com/p/ambari/2.x/2.7.4.0/centos7/ambari-2.7.4.0-centos7.tar.gz 只能用迅雷下载,账号密码如下: username 和 password
参考 https://blog.csdn.net/wx2007xing/article/details/88710235
https://gitee.com/tang006/docker-hbase

 浙公网安备 33010602011771号
浙公网安备 33010602011771号