

Hadoop Journal Node 作用
Hadoop Journal Node 作用
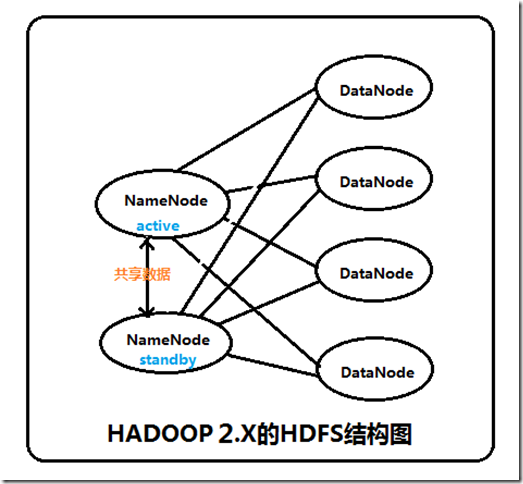
两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNs中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。standby可以确保在集群出错时,命名空间状态已经完全同步了
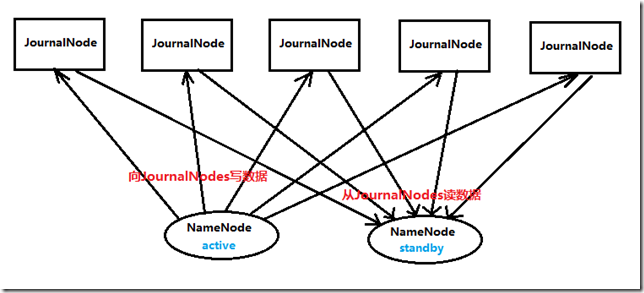
对于HA集群而言,确保同一时刻只有一个NameNode处于active状态是至关重要的。否则,两个NameNode的数据状态就会产生分歧,可能丢失数据,或者产生错误的结果。为了保证这点,JNs必须确保同一时刻只有一个NameNode可以向自己写数据。
JN必须允许至少3个节点。当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等。当运行N个节点时,系统可以容忍至少(N-1)/2(N至少为3)个节点失败而不影响正常运行。
standby状态的NameNode可以完成checkpoint操作 https://my.oschina.net/u/3987818/blog/2245016

 浙公网安备 33010602011771号
浙公网安备 33010602011771号