珂朵莉树/ODT/颜色段均摊
珂朵莉树/ODT/颜色段均摊
诞生于 CF896C (镜像站),最开始叫做老司机树(因为发现此数据结构的用户名叫 \(\texttt{Old Driver}\)),后来因为题目名字 \(\texttt{Willem, Chtholly and Seniorious}\) ,所以又名珂朵莉树(珂朵莉是世界上最幸福的女孩)。
珂朵莉树一般适用于数据随机,且带有区间推平这类操作的问题,可以在快于线段树的时间内跑出正确答案(如果数据不随机的话也可以 T 到飞起)。
珂朵莉树的主要思想是将连续一段值相等的区间用一个三元组 \([l,r,v]\) 表示( \(l\) 表示区间左端点, \(r\) 表示区间右端点, \(v\) 表示区间值 )。那么在区间推平操作时就可以将许多区间直接合并成为一个区间,这样使区间数量减少。
建树
珂朵莉树的建立很简单,只需要用一个结构体 Node 存储三元组 \([l,r,v]\) ,然后将这些三元组放在一个set 中,以左端点为关键字定义 \(<\) 号。
具体代码也很简单:
struct NODE{
int l,r;//左右端点
mutable int v;//区间值,具体根据题目而定
NODE (int l,int r=0,int v=0) : l(l),r(r),v(v) {}
bool operator< (const NODE &a) const {return l<a.l;}//重载<号
};
set <NODE> ctlt;//建树
这里使用了 mutable 这一关键字,使得 \(v\) 在任意情况下都是可以更改的,即使在 const 函数中也强制可以更改。这样就可以方便珂朵莉树的一些操作。
珂朵莉树最基础的操作有两个: split和assign 。
Split 操作
即分裂操作,将原有区间 \([l,r]\) 以 \(pos\) 为中间端点,分裂成为 \([l,pos-1]\) 和 \([pos,r]\) 两个区间,并返回后一个区间的迭代器。
首先需要在珂朵莉树中二分找到第一个左端点大于等于 \(pos\) 的区间,这一点用 set 自带的 lower_bound 函数即可解决。
找到这个区间后,如果 \(pos\) 刚好就是该区间的左端点,那么根据定义,就没必要分裂了,直接返回当前区间的迭代器。
如果 \(pos\) 不是这个区间的左端点,那么将迭代器向前移动一个区间就得到了 \(pos\) 所在的区间的迭代器。但是可能出现向前移后 \(pos\) 大于右端点的情况,这时直接返回 ctlt.end() 即可。分裂时,直接将原区间从珂朵莉树中删除,添加 \([l,pos-1,v]\) 和 \([pos,r,v]\) 两个区间就行了。
有一个小技巧, set 中的 insert 操作会返回一个二元组 pair ,这个 pair 的第一项就是插入的这个区间的迭代器,直接用 first 调用即可。
另外,感谢 C++14,现在我们可以用auto来代替set<NODE>::iterator 定义迭代器了。
auto split(int pos)
{
auto it=ctlt.lower_bound(NODE(pos));//找到区间的迭代器
if (it!=ctlt.end() && it->l==pos) return it;//如果pos是区间左端点直接返回当前区间迭代器
--it;//迭代器前移
if (it->r<pos) return ctlt.end();//不符合条件直接返回end()
int l=it->l,r=it->r,v=it->v;
ctlt.erase(it);//删除原区间
ctlt.insert(NODE(l,pos-1,v));//插入左区间
return ctlt.insert(NODE(pos,r,v)).first;//插入右区间并返回迭代器
}
Assign 操作
这一操作是降低珂朵莉树时间复杂度的最重要部分,在数据随机的情况下会出现大量 assign 操作,从而使得区间数量大概大概维持在 \(\log n\) 级别(我也不会证明)。
Assign 操作的意思是将一个区间的值直接推平。那么可以得知,如果需要推平的区间 \([l,r]\) 的左右端点不是已有区间的左右端点,就需要进行 split 操作,所以在 assign 开始时直接 split(l) 和 split(r+1) 。需要注意的是,必须先 split(r+1) 在 split(l) ,否则可能导致 split 操作返回的迭代器在 split(r+1) 失效,导致 \(\texttt{RE}\) 。
实现起来也很简单, set 中提供的 erase 函数支持传入两个迭代器 itl 和 itr ,表示删除迭代器 itl 和 itr 之间的所有元素。所以在 split 操作时获取到 itl 和 itr ,然后直接 ctlt.erase(itl,itr) 即可。此时 \([l,r]\) 这一区间在珂朵莉树中已经被清理出位置了,直接插入三元组 \([l,r,x]\) 即可。
代码很短:
void assign(int l,int r,int x)
{
auto itr=split(r+1),itl=split(l);//分裂区间,创造出区间[l,r]
ctlt.erase(itl,itr);//删除[l,r]之间的所有区间
ctlt.insert(NODE(l,r,x));//插入新的区间
}
这些就是珂朵莉树的基本操作,具体查询之类的根据题目来写。
下面结合珂朵莉树的最初题目来理解珂朵莉树的使用。
Willem, Chtholly and Seniorious
题面翻译
【题面】
请你写一种奇怪的数据结构,支持:
- \(1\) \(l\) \(r\) \(x\) :将\([l,r]\) 区间所有数加上\(x\)
- \(2\) \(l\) \(r\) \(x\) :将\([l,r]\) 区间所有数改成\(x\)
- \(3\) \(l\) \(r\) \(x\) :输出将\([l,r]\) 区间从小到大排序后的第\(x\) 个数是的多少(即区间第\(x\) 小,数字大小相同算多次,保证 \(1\leq\) \(x\) \(\leq\) \(r-l+1\) )
- \(4\) \(l\) \(r\) \(x\) \(y\) :输出\([l,r]\) 区间每个数字的\(x\) 次方的和模\(y\) 的值(即(\(\sum^r_{i=l}a_i^x\) ) \(\mod y\) )
【输入格式】
这道题目的输入格式比较特殊,需要选手通过\(seed\) 自己生成输入数据。
输入一行四个整数\(n,m,seed,v_{max}\) ($1\leq $ \(n,m\leq 10^{5}\) ,\(0\leq seed \leq 10^{9}+7\) $,1\leq vmax \leq 10^{9} $ )
其中\(n\) 表示数列长度,\(m\) 表示操作次数,后面两个用于生成输入数据。
数据生成的伪代码如下

其中上面的op指题面中提到的四个操作。
【输出格式】
对于每个操作3和4,输出一行仅一个数。
题目描述
— Willem...
— What's the matter?
— It seems that there's something wrong with Seniorious...
— I'll have a look...

Seniorious is made by linking special talismans in particular order.
After over 500 years, the carillon is now in bad condition, so Willem decides to examine it thoroughly.
Seniorious has \(n\) pieces of talisman. Willem puts them in a line, the \(i\) -th of which is an integer \(a_{i}\) .
In order to maintain it, Willem needs to perform $ m $ operations.
There are four types of operations:
- \(1\ l\ r\ x\) : For each \(i\) such that \(l<=i<=r\) , assign \(a_{i}+x\) to \(a_{i}\) .
- \(2\ l\ r\ x\) : For each \(i\) such that \(l<=i<=r\) , assign \(x\) to \(a_{i}\) .
- \(3\ l\ r\ x\) : Print the \(x\) -th smallest number in the index range \([l,r]\) , i.e. the element at the \(x\) -th position if all the elements \(a_{i}\) such that \(l<=i<=r\) are taken and sorted into an array of non-decreasing integers. It's guaranteed that \(1<=x<=r-l+1\) .
- \(4\ l\ r\ x\ y\) : Print the sum of the \(x\) -th power of \(a_{i}\) such that \(l<=i<=r\) , modulo \(y\) , i.e.
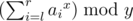 .
.
输入格式
The only line contains four integers \(n,m,seed,v_{max}\) ( \(1<=n,m<=10^{5},0<=seed<10^{9}+7,1<=vmax<=10^{9}\) ).
The initial values and operations are generated using following pseudo code:
def rnd():
ret = seed
seed = (seed * 7 + 13) mod 1000000007
return ret
for i = 1 to n:
a[i] = (rnd() mod vmax) + 1
for i = 1 to m:
op = (rnd() mod 4) + 1
l = (rnd() mod n) + 1
r = (rnd() mod n) + 1
if (l > r):
swap(l, r)
if (op == 3):
x = (rnd() mod (r - l + 1)) + 1
else:
x = (rnd() mod vmax) + 1
if (op == 4):
y = (rnd() mod vmax) + 1
Here \(op\) is the type of the operation mentioned in the legend.
输出格式
For each operation of types \(3\) or \(4\) , output a line containing the answer.
样例 #1
样例输入 #1
10 10 7 9
样例输出 #1
2
1
0
3
样例 #2
样例输入 #2
10 10 9 9
样例输出 #2
1
1
3
3
提示
In the first example, the initial array is \({8,9,7,2,3,1,5,6,4,8}\) .
The operations are:
- \(2\ 6\ 7\ 9\)
- \(1\ 3\ 10\ 8\)
- \(4\ 4\ 6\ 2\ 4\)
- \(1\ 4\ 5\ 8\)
- \(2\ 1\ 7\ 1\)
- \(4\ 7\ 9\ 4\ 4\)
- \(1\ 2\ 7\ 9\)
- \(4\ 5\ 8\ 1\ 1\)
- \(2\ 5\ 7\ 5\)
- \(4\ 3\ 10\ 8\ 5\)
Solution
首先可以得知题目的数据是随机分布的,并且出现了区间推平的操作,所以就可以使用珂朵莉树来解决。
2 操作就是珂朵莉树最基础的操作,就不再讲了。
1 操作与 assign 操作类似,先将 \([l,r]\) 这一区间分裂出来,然后对这一区间的所有 \([l,r,v]\) 的 \(v\) 加上 \(x\) 就行了。代码也很简单,时间复杂度大约为 \(\text O(\log n)\)。
void add(int l,int r,int x)
{
auto itr=split(r+1),itl=split(l);//分裂
for (auto it=itl;it!=itr;it++)//遍历[l,r]的所有区间
it->v+=x;//修改v值
}
然后是 3 操作,要求求出区间第 \(x\) 大,同样可以遍历 \([l,r]\) 的所有元素,将这些区间的值 \(v\) 以及长度记录在一个 vector 中,然后根据区间值 \(v\) 为关键字进行排序,从小到大查看当前的所有区间的长度之和是否达到了 \(x\) ,如果达到了就证明当前区间值就是第 \(x\) 大,否则继续往更大找。因为区间个数大约为 \(\text O(\log n)\) 个,所以此操作的时间复杂度大约为 \(\text O(\log n \log \log n)\)。
struct RANK{//用结构体存储区间值以及区间长度
int num,cnt;
bool operator<(const RANK &a) const{
return num<a.num;
}
};
int RankQuery(int l,int r,int x)
{
auto itr=split(r+1),itl=split(l);
vector<RANK> v;
for (auto it=itl;it!=itr;it++)
v.push_back((RANK){it->v,it->r - it->l +1});//将区间值以及区间长度存入vector
sort(v.begin(),v.end());//对vector排序
for (auto it:v)//遍历vector
{
if (it.cnt<x) x-=it.cnt;//总数量不够x
else return it.num;//够了就返回当前区间值
}
}
最后是 4 操作,要求求出区间 \(x\) 次幂和模 \(y\) 。对于这一操作也可以遍历 \([l,r]\) 所有元素直接计算,因为 \(x\) 可能会很大,所以需要写快速幂。对于区间 \([l,r,v]\) ,那么这个区间的 \(x\) 次幂和为 \(v^x \times(r-l+1)\) 。具体做法可以结合代码理解。
int Fpow(int x,int y,int p)//快速幂模板
{
int res=1,base=x%p;
while (y)
{
if (y&1) res=res*base%p;
base=base*base%p;
y>>=1;
}
return res;
}
int PowerQuery(int l,int r,int x,int y)
{
auto itr=split(r+1),itl=split(l);
int res=0;
for (auto it=itl;it!=itr;it++)
res=(res+Fpow(it->v,x,y)*(it->r - it->l +1)%y)%y;//区间[l,r,v]的区间x次幂和为v的x次幂乘上区间长度
return res;
}
最后放上总代码:(各部分具体含义前面已经解释清楚了,所以就没写注释了)
#include<bits/stdc++.h>
#define int long long
#define mem(a,b) memset(a,b,sizeof a)
using namespace std;
template<typename T> void read(T &k)
{
k=0;T flag=1;char b=getchar();
while (!isdigit(b)) {flag=(b=='-')?-1:1;b=getchar();}
while (isdigit(b)) {k=k*10+b-48;b=getchar();}
k*=flag;
}
struct NODE{
int l,r;
mutable int v;
NODE (int l,int r=0,int v=0) : l(l),r(r),v(v) {}
bool operator< (const NODE &a) const {return l<a.l;}
};
set <NODE> ctlt;
auto split(int pos)
{
auto it=ctlt.lower_bound(NODE(pos));
if (it!=ctlt.end() && it->l==pos) return it;
--it;
if (it->r<pos) return ctlt.end();
int l=it->l,r=it->r,v=it->v;
ctlt.erase(it);
ctlt.insert(NODE(l,pos-1,v));
return ctlt.insert(NODE(pos,r,v)).first;
}
void assign(int l,int r,int x)
{
auto itr=split(r+1),itl=split(l);
ctlt.erase(itl,itr);
ctlt.insert(NODE(l,r,x));
}
void add(int l,int r,int x)
{
auto itr=split(r+1),itl=split(l);
for (auto it=itl;it!=itr;it++)
it->v+=x;
}
struct RANK{
int num,cnt;
bool operator<(const RANK &a) const{
return num<a.num;
}
};
int RankQuery(int l,int r,int x)
{
auto itr=split(r+1),itl=split(l);
vector<RANK> v;
for (auto it=itl;it!=itr;it++)
v.push_back((RANK){it->v,it->r - it->l +1});
sort(v.begin(),v.end());
for (auto it:v)
{
if (it.cnt<x) x-=it.cnt;
else return it.num;
}
}
int Fpow(int x,int y,int p)
{
int res=1,base=x%p;
while (y)
{
if (y&1) res=res*base%p;
base=base*base%p;
y>>=1;
}
return res;
}
int PowerQuery(int l,int r,int x,int y)
{
auto itr=split(r+1),itl=split(l);
int res=0;
for (auto it=itl;it!=itr;it++)
res=(res+Fpow(it->v,x,y)*(it->r - it->l +1)%y)%y;
return res;
}
int n,m,seed,vmax;
const int MOD=1e9+7;
int rnd()
{
int ret=seed;
seed=(seed*7+13)%MOD;
return ret;
}
signed main()
{
read(n),read(m),read(seed),read(vmax);
for (int i=1;i<=n;i++)
{
int v=rnd()%vmax+1;
ctlt.insert(NODE(i,i,v));
}
for (int i=1;i<=m;i++)
{
int op=rnd()%4+1,l=rnd()%n+1,r=rnd()%n+1,x,y;
if (l>r) swap(l,r);
if (op==3) x=(rnd()%(r-l+1))+1;
else x=(rnd()%vmax)+1;
if (op==4) y=rnd()%vmax+1;
if (op==1) add(l,r,x);
if (op==2) assign(l,r,x);
if (op==3) printf("%lld\n",RankQuery(l,r,x));
if (op==4) printf("%lld\n",PowerQuery(l,r,x,y));
}
return 0;
}
代码的时间复杂度大概在 \(\text O(n\log n)\) 这一级别,但是因为常数小,所以在数据随机的情况下用来代替线段树进行区间推平的操作耗时会大大减小(但现在洛谷基本把珂朵莉树卡完了)。
说实话我没看出来珂朵莉树与树有什么关系,珂朵莉树算是一种优雅的暴力,在特殊情况下用来骗一骗分还是足够用的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号