
Dreambooth, Textual Inversion, LoRA, Hypernetworks ,示意图解释

How does Stable Diffusion Work?
Stable diffusion has two core parts, the Diffusion Process and the Reverse Diffusion Process. The diffusion process adds noise to images and generates slightly noisy images with every step. The reverse diffusion process then reverses this process by predicting the amount of noise required to subtract from the noisy image to get the original image. This process is then repeated several times until a coherent image is obtained.
Let’s dive deeper into both of the concepts:
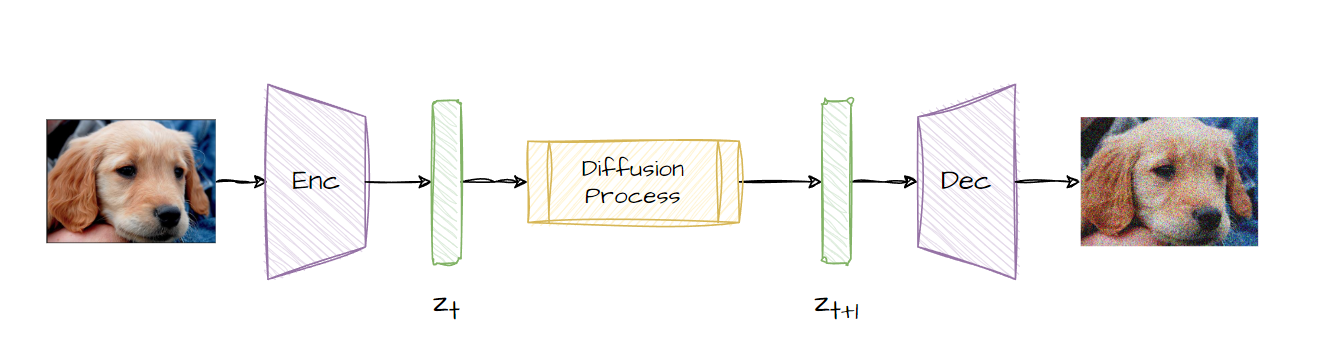
Forward Diffusion
As mentioned above, forward diffusion is the process of adding noise to an image. This happens in steps, so a number of steps are predetermined, and then a distribution of strength of noise is calculated for those steps. The higher the step, the more noise is added. This is an iterative process, but the authors of the LDM paper show this can be done in one go. Given a step and the image, you can skip the previous iterations of adding noise.
The authors also note that instead of adding noise directly to the image, we can encode the image and do the same operation in a latent space instead and then decode the image later on. This HUGELY reduces the computational power required to train and use diffusion models.
This process is used to generate training samples for the reverse diffusion process.
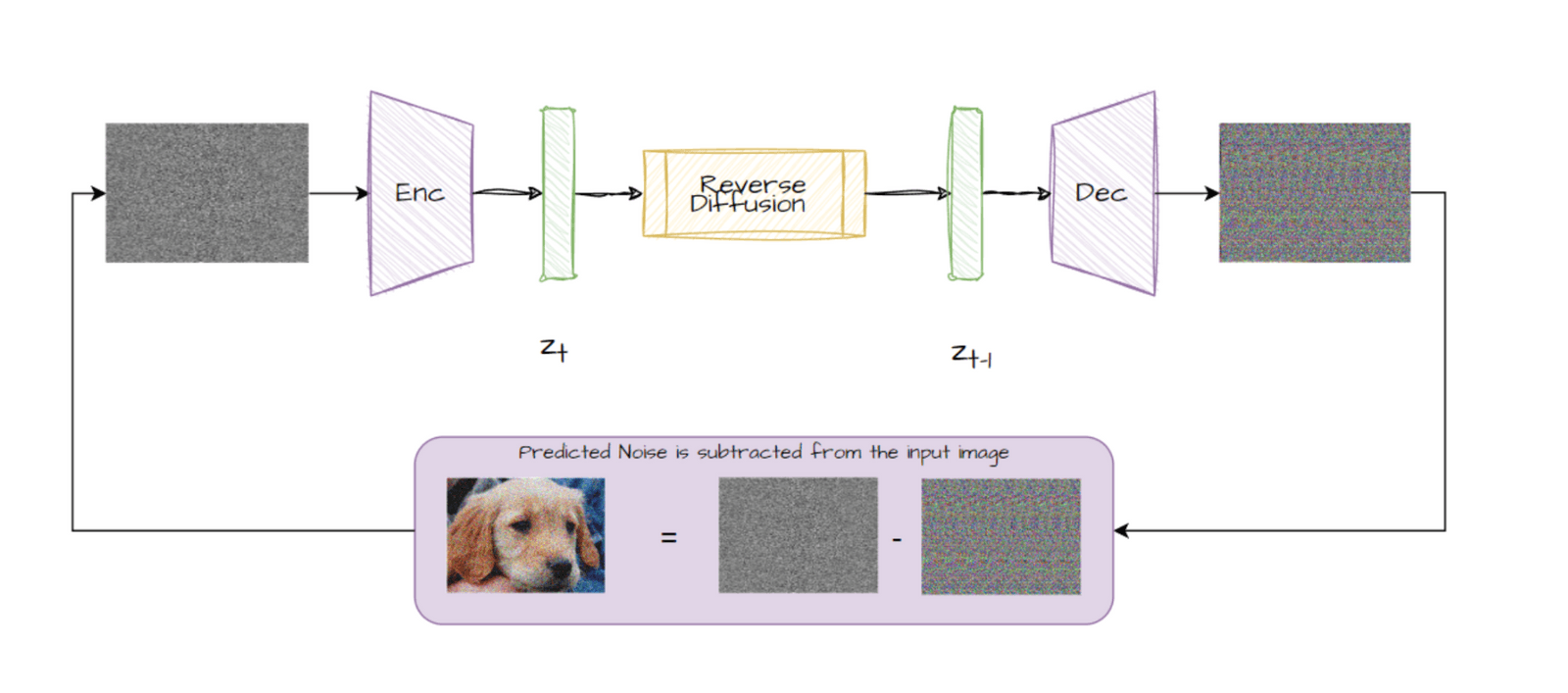
Reverse Diffusion
Once we have the training samples from the forward diffusion process. We can start training the generative model to generate images. The generative model generates images by removing noise from a completely noisy image. This happens in an iterative fashion. The generative model predicts the noise that has to be subtracted from the noisy image to get an actual image. Then a fraction of this noise is subtracted from the noisy image. The resultant image is then again fed to the network. This process is repeated for a set amount of steps.
Alternatives to Stable Diffusion
DALL-E
DALL-E is a text-to-image model by OpenAI. It has two model versions, DALL-E and DALL-E 2. DALL-E 2 is an encoder-decoder architecture. The text encoder takes text as input and generates text embeddings. They are passed to a prior model which is a diffusion model. It generates the corresponding CLIP image embeddings. The embeddings are passed to an image decoder which then generates actual images from the embeddings.
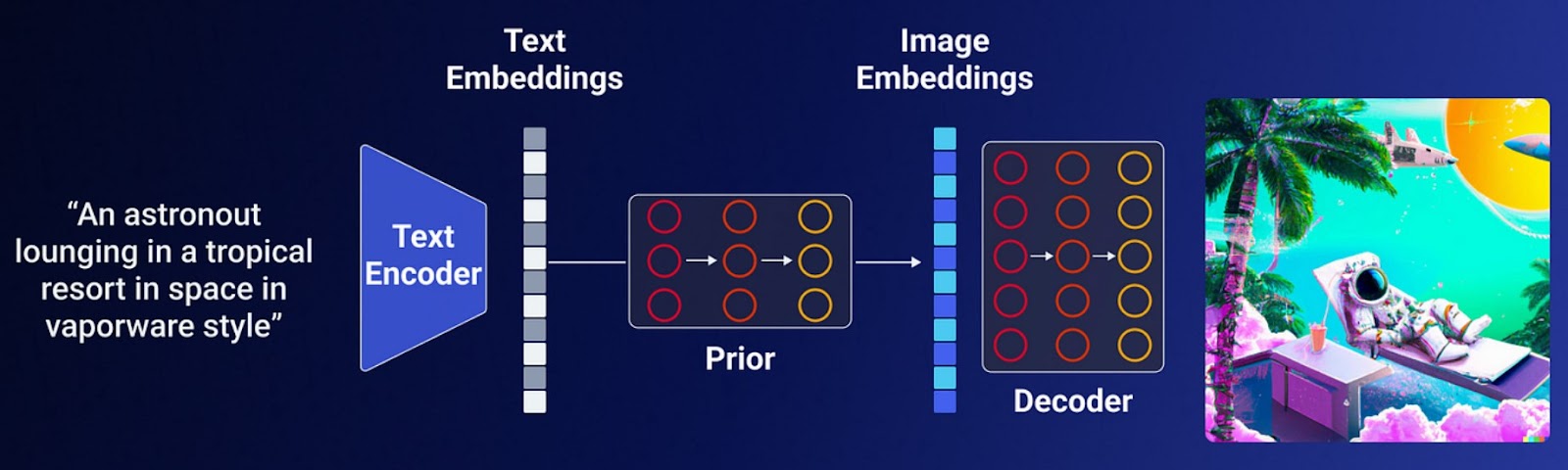
Figure From Medium
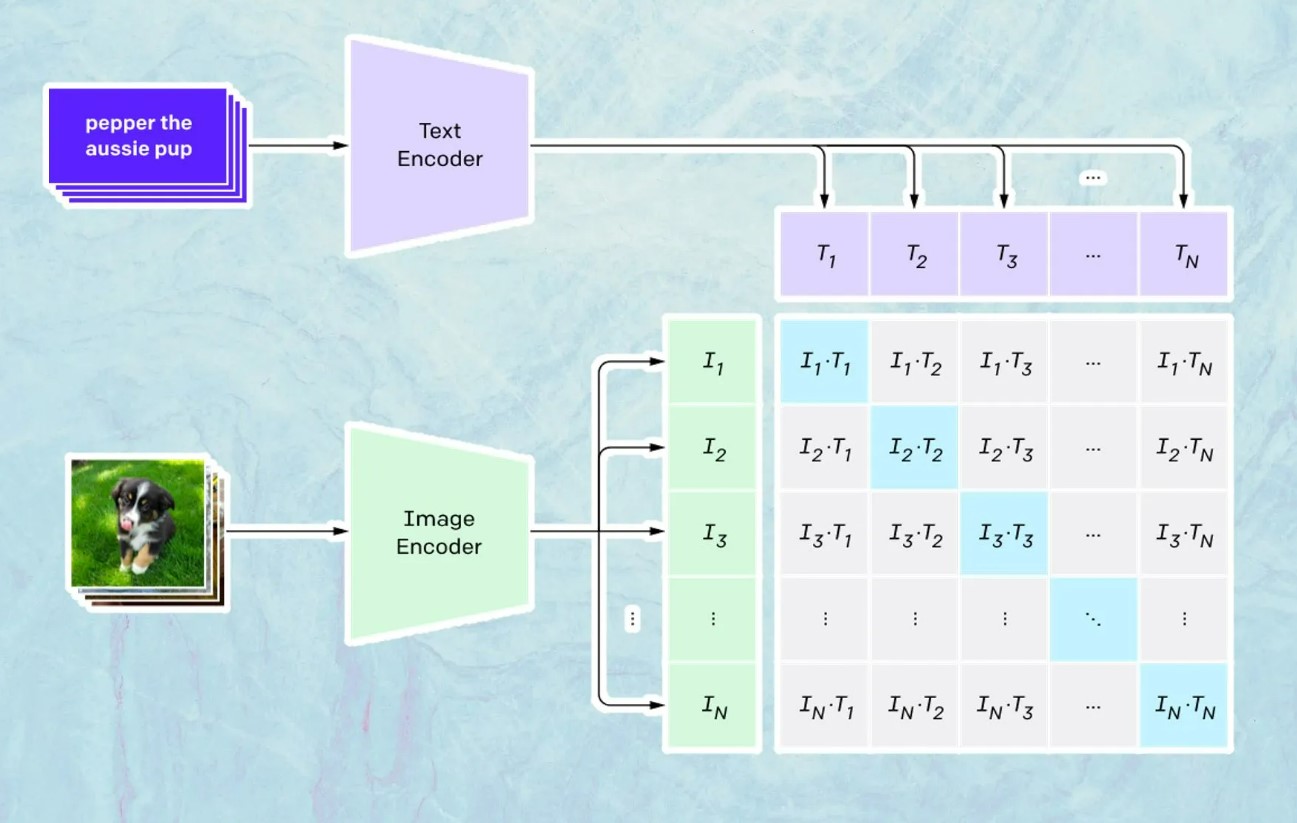
The embeddings come from CLIP (Contrastive Language-Image Pretraining). CLIP is trained on millions of images and their captions, to understand the relation between text and images. The model is designed to test how well a given caption matches an image, rather than predicting captions based on images. CLIP generates text and image encodings of each image-caption pair. It then calculates the cosine similarity of each of these embeddings. It minimizes the similarity between incorrect pairs and maximizes that of correct pairs. It then freezes and DALL-E 2 moves to the next task. CLIP guides the prior that takes text embeddings and turns them into image embeddings.
Lastly, a decoder generates an image. It uses a modified diffusion model called GLIDE (Guided Language to Image Diffusion for Generate and Editing). Glide improves diffusion models by adding text inputs. It creates images based on both text and diffusion methods. This model is adapted to decode the CLIP image embeddings into coherent images, maintaining the essence of the original prompts. A diffusion model, employed by GLIDE, ensures the creation of photorealistic images.
DALL-E still faces some limitations. For example, it might struggle to create images where text and visuals align coherently. It also faces challenges in linking attributes to objects or generating complex scenes. Additionally, it may inherit biases from the data it is trained on. However, it is still a powerful generative AI model that can create realistic and creative images from text descriptions.
Midjourney
Midjourney is a self-funded and independent generative AI program. It can generate high-quality images from text descriptions. It is hosted by an independent research lab, Midjourney, Inc., and operates entirely on Discord or third-party servers. To use Midjourney, you need to have a Discord account. You do not need any specialized hardware or software, and you do not need to download any files. Currently, the lab is working to make it accessible through a web interface.
Midjourney is a closed-source program. No proper knowledge of its underlying working is available. However, it can be said that it uses large language and diffusion models. The former is used by Midjourney to understand the meaning of a text prompt. The language model then converts the prompt into a vector, which is used to guide a diffusion process. The diffusion process gradually generates an image that is consistent with the meaning of the prompt. To generate images, users input prompts using the /imagine command. Advanced techniques, such as using Upscale, Vary, and Redo buttons, empower users to enhance results. Midjourney's unique artistic style is evident in its outcomes, similar to paintings rather than photographs.
Techniques to generate product images using Stable Diffusion
Textual Inversion
Textual Inversion is a method used in machine learning, specifically in text-to-image generation. It's a way to introduce new concepts to a model using a few example images. The model learns these new concepts by creating new 'words' in the embedding space of the text encoder. These words can then be used in text prompts to generate images with a high degree of control. The technique was first introduced in this research paper and has since been applied to various models, including the Stable Diffusion models.
The assumption here is that the embedding space of the text encoder is vast enough to encode the aspects of the new images that one would want to introduce and generate using the image decoder.

To generate product images using this process, one can upload a few images of the product, preferably in different positions and lighting. Once we have that we can start training the model on our new images, but the embeddings for the new token will be the only trainable params. This means all the loss of the model will be focused on learning the embeddings that are required to generate the given images. This will find the best vectors responsible in the text encoder latent space which can best represent the given images or concepts in the image.
The advantage of this process is that we are not expanding the space of the model. We are learning the new embedding required specifically for our product. This means we can use the same model for multiple products, just assigning a new word to every specific product.
DreamBooth
Dreambooth is another method to add new concepts to image generative models. This one came out of Google in 2022. Similar to Textual Inversion, DreamBooth also lets you introduce new objects/concepts in the model and assign unique identifiers to them. Once the model has learned the new concept, you can use the associated unique identifier to generate images of the object in different settings and scenarios.

Although similar in concept and goal, DreamBooth differs completely in approach from Textual Inversion. Instead of just finetuning the text embedding space and learning the embedding for the new object. We finetune the whole network, in a few-shot fashion. And that’s The core problem here is to finetune the network in a few-shot fashion. Authors show that you can use this method with as little as 3 images, although the more the better. But finetuning with such a small amount of data can lead to major issues in the network. The authors introduce a few ways to make this possible.
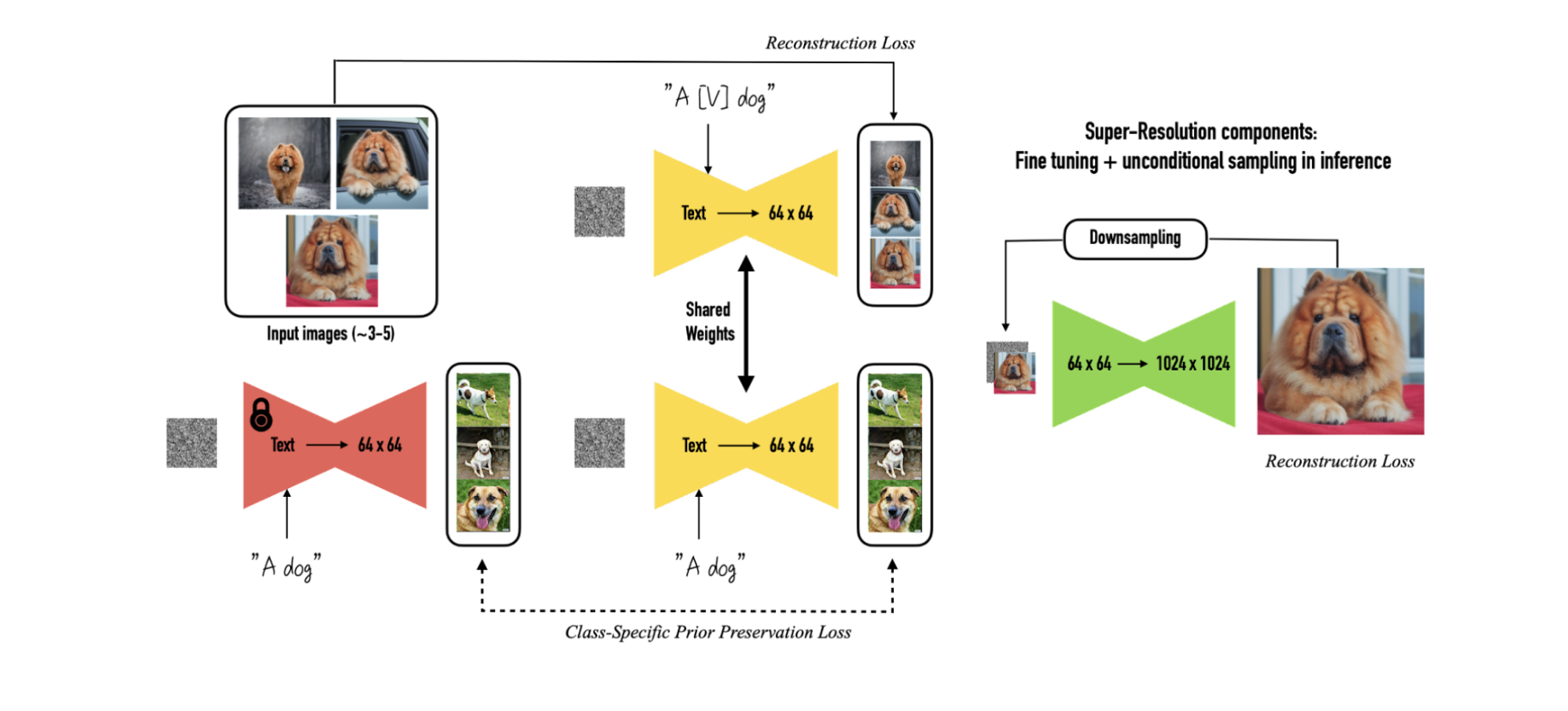
To generate custom product images using this process, you would first need a few images of the product or person that you want to target. Then, along with that, you would need some images of the same class as the product. The class of the product is basically what the product is, bag, shoes, water bottle, etc. As shown in the diagram above, the training is comprised of the new images AND the images from the same class. This is necessary to make sure that the model retains the original information and doesn’t overfit. To ensure the balance between preserving the old concepts and learning the new concepts, the authors introduce a class-preservation loss, which is a loss term with an additional parameter to control the weight of the loss from the old images. One can reduce or increase this parameter according to the needs. This also helps in preventing language drift. This is the phenomenon when a language model trained on a large corpus is finetuned on a smaller more specific corpus, it starts to lose the syntactical and semantic knowledge of the language.
Along with the class preservation loss, the authors also put emphasis on the specific technique to use when building prompts. They suggest using prompts in the specific format of: “A [V] [class noun]” where [V] is the unique identifier, and the [class noun] is the class the object belongs to. Using class nouns helps greatly with learning as it helps the model tie the properties of the new images to something that it has already learned. This is because this way the image and the embeddings are more closely related right off the bat instead of being learned slowly.
These two are the core of the finetuning with dreambooth. Once these are in place, one can finetune the smaller resolution model with class preservation loss and class noun prompting technique. And then finetune the larger model with the new images to ensure the fidelity of the generated images.
Dreambooth vs Textual Inversion
Dreambooth when compared to Textual Inversion shows much better results. This is primarily because Dreambooth finetunes the whole network, instead of just the text encoder space. But because of this, finetuning with dreambooth can be notoriously difficult. It is very easy to overfit and can lead to language drift. There are many hyperparameters to control. Many people have been running experiments, you can read this amazing article from hugging face here. Another big issue with Dreambooth is the high number of trainable parameters. This issue can be solved by finetuning with Peft Techniques like LoRA.
This being said, DreamBooth is hugely superior to Textual Inversion. If you want to generate product images using Stable Diffusion, definitely use DreamBooth finetuning with LoRA, but if you only need the model to learn the basic concept, without very high accuracy, Textual Inversion would be better.
Outpainting
Outpainting is a very basic method of extending a passed image. Stable Diffusion is able to perform this operation using the techniques described in another paper, LaMa - Large Mask Inpainting. The authors generate data and evaluate the performance of the stable diffusion model based on the LaMa paper.
This is very important to note that Outpainting is an extension of Inpainting, which is a technique to remove parts from images, not add to them. This works by passing the original image and a mask image to the model, the model will then erase the parts from the original image which are highlighted in the mask. LaMa was a SOTA method at the time, new papers like Feature Refinement have come out since.
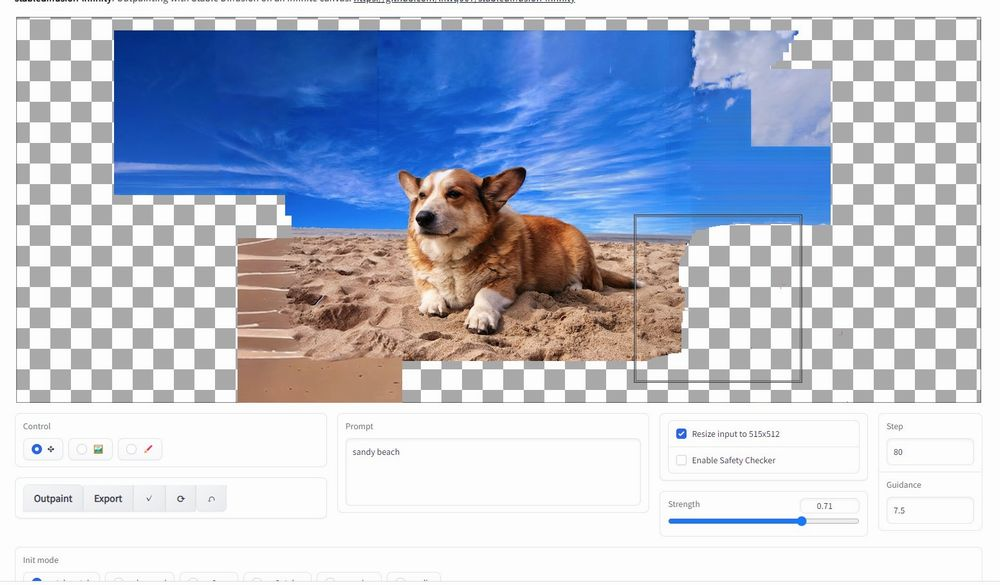
To perform outpainting using this, the mask is made bigger than than original image and is added around the image, not over the original image. This forces the model to add to the image and hence extend the original image.
ControlNet
Control net is not a technique to extend images, but rather a technique to control the output of a generative model. It is a type of generative model that uses a control vector to control the output of the model. This control vector is a set of parameters that are used to control the output of the model. The control vector is used to control the output of the model in terms of the desired features, such as color, texture, shape, etc. This allows for more control over the output of the model and can be used to generate more realistic images.
Control net can be combined with dream booth, textual inversion, and other stable diffusion models to generate finely controlled images of desired products. Here is an example of generating shoe images using nothing but scribble:

posted on 2024-02-01 16:36 Sanny.Liu-CV&&ML 阅读(65) 评论(0) 编辑 收藏 举报


