解读1-YOLO v7
转载:https://zhuanlan.zhihu.com/p/549069736
《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》
paper:https://arxiv.org/pdf/2207.02696.pdf
code:https://github.com/WongKinYiu/yolov7
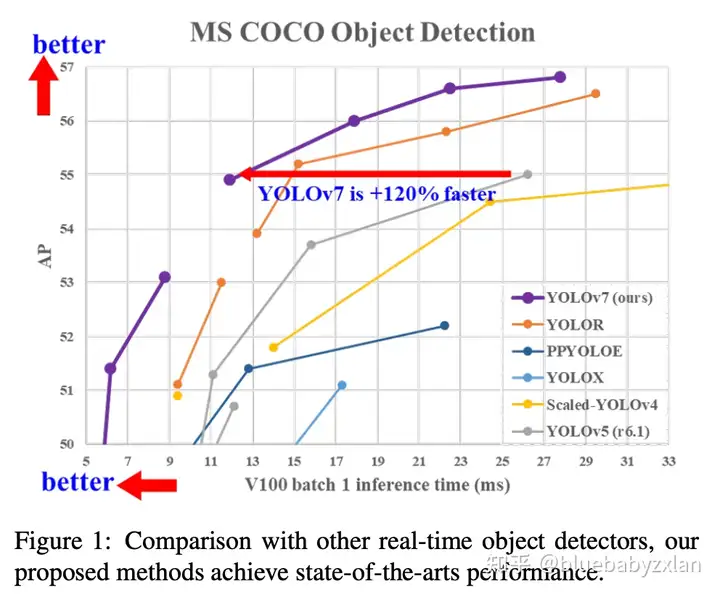
YOLO v7,一个出场即喊了一句“在座的各位都是腊鸡”的detector,其在COCO数据集上的表现如下图,不论是mAP还是latency,都比同级别的detector好. 正如文章标题所描述的,YOLO v7实现高精度检测的方式更多的是依靠训练策略的优化. BTW,YOLO v7的整体架构和YOLO v5仍然非常相似,皆为backbone+FPN+PAN+三个不同尺度的head,但其中内嵌的模块有了较大改变.
highlight
- 特征提取单元优化. 使用ELAN作为特征提取单元.
- 下采样优化. 同时使用了最大池化和步长为2的卷积进行下采样.
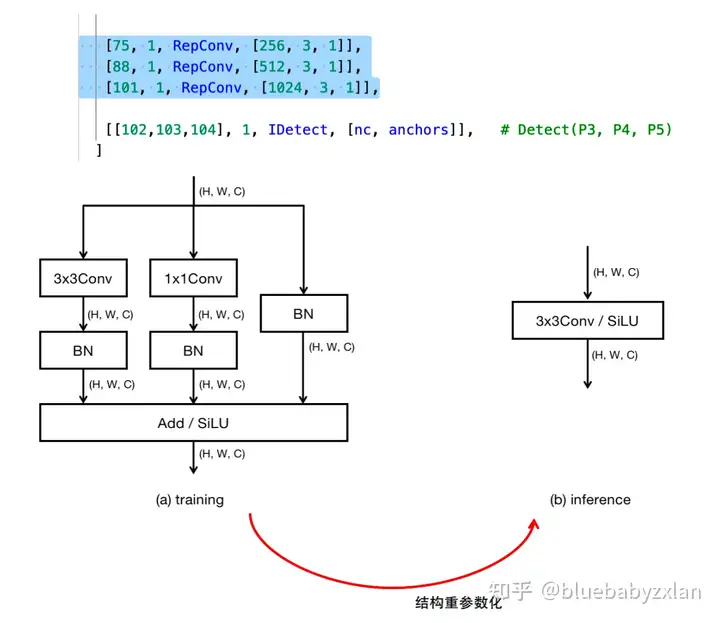
- 结构重参数化. 在三个不同尺度的检测头前增加了RepConv,并在测试时转换成普通的3x3Conv.
- 检测头改进. 使用了YOLOR的检测头.
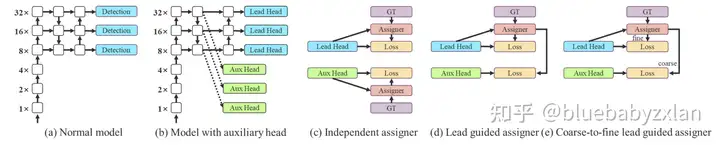
- 辅助训练. 在训练时增加辅助head,并在测试时丢弃.
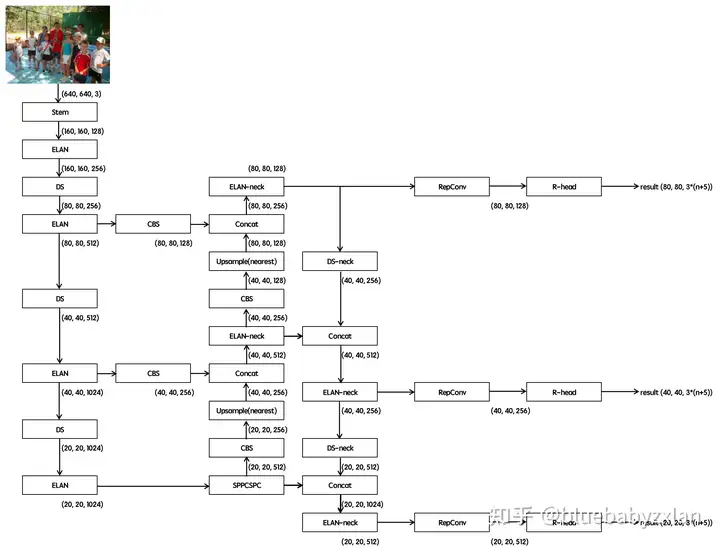
YOLO v7网络结构
YOLO v7网络结构的整体形态和YOLO v5比较类似,均为backbone+FPN+PAN+headx3的形式,但其中具体使用的模块进行了较大更改. YOLO v7的网络结构如下图所示:
backbone
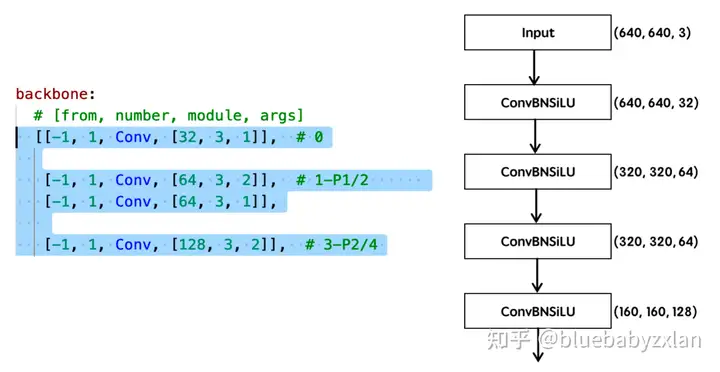
为方便描述,将下采样块记为DS. 则backbone部分由stem、ELAN和DS三种模块组合而成,以下是YOLO v7的backbone具体配置:
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
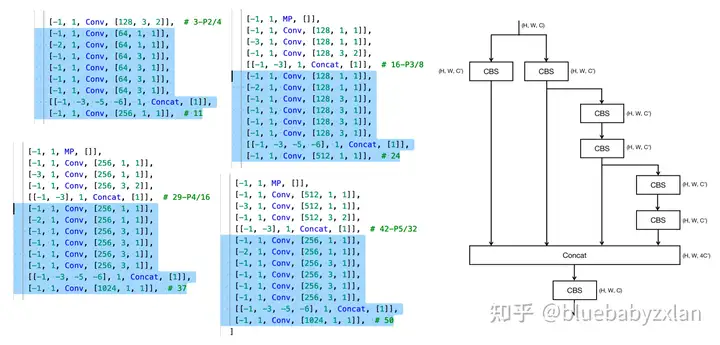
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]其中,stem结构为:
累计用到了4次ELAN结构. 具体地,其位置和结构如下图所示(记CBS为Conv+BN+SiLU),前三处c'=c/2,第四处c'=c/4.
累计用到了3次DS结构,具体地,其位置和结构如下图所示(记CBS为Conv+BN+SiLU):
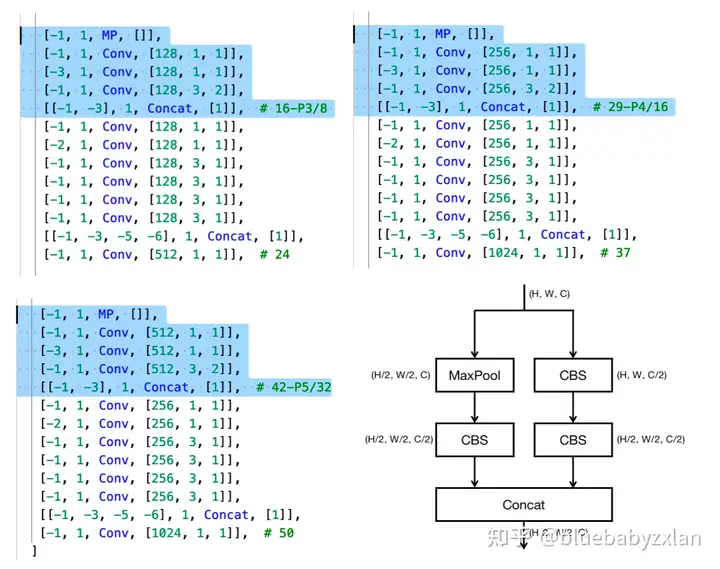
综上,backbone部分结构由stem、ELAN和DS三部分构成,ELAN主要用于特征提取和通道数控制,DS主要用于下采样(输入前后通道数一致). 整体结构可简单描述为:Input->stem->ELAN->(DS->ELAN)^3->Output.
neck / head
由于实际head部分占比很小,neck部分和head部分的配置通常是写在一起的,因此对neck和head部分做统一描述,以下是YOLO v7的head配置,其主要由ELAN-neck、DS-neck和RepConv构成(由于这里的ELAN和DS形式和backbone中有细微区别,故计作ELAN-neck和DS-neck).
# yolov7 head
head:
[[-1, 1, SPPCSPC, [512]], # 51
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[37, 1, Conv, [256, 1, 1]], # route backbone P4
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 63
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[24, 1, Conv, [128, 1, 1]], # route backbone P3
[[-1, -2], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [128, 1, 1]], # 75
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3, 63], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 88
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3, 51], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-2, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 101
[75, 1, RepConv, [256, 3, 1]],
[88, 1, RepConv, [512, 3, 1]],
[101, 1, RepConv, [1024, 3, 1]],
[[102,103,104], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)
]其中,SPPCSPC对应于原YOLO v5的SPPF. SPPCSPC的结构如下图所示(记CBS为Conv+BN+SiLU):
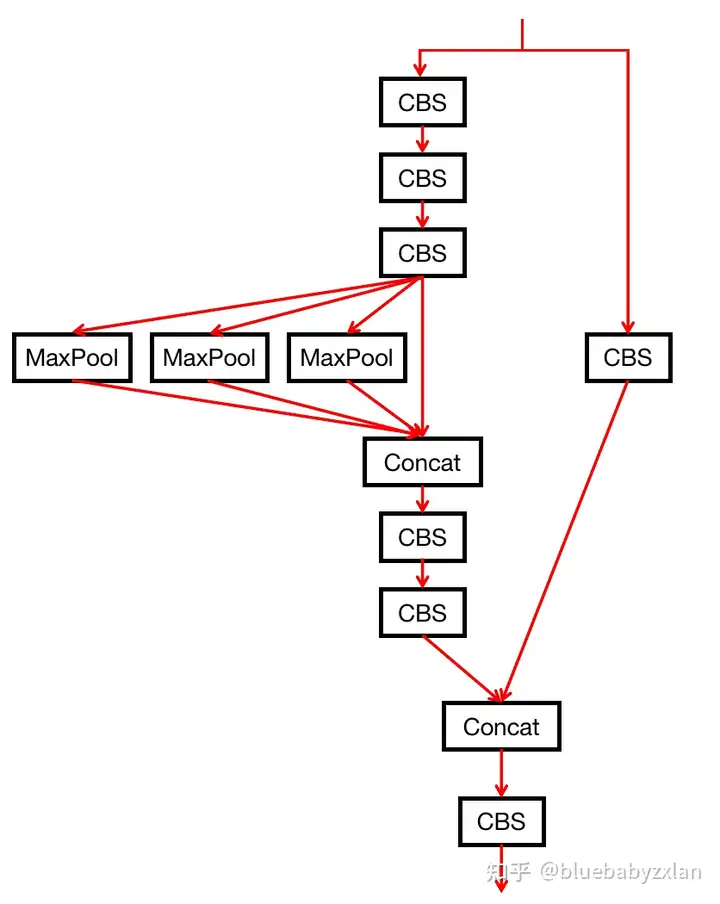
上图三个MaxPool的核大小各不相同,默认情况下分别为5、9和13. SPPCSPC的代码如下:
class SPPCSPC(nn.Module):
# CSP https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5, k=(5, 9, 13)):
super(SPPCSPC, self).__init__()
c_ = int(2 * c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(c_, c_, 3, 1)
self.cv4 = Conv(c_, c_, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
self.cv5 = Conv(4 * c_, c_, 1, 1)
self.cv6 = Conv(c_, c_, 3, 1)
self.cv7 = Conv(2 * c_, c2, 1, 1)
def forward(self, x):
x1 = self.cv4(self.cv3(self.cv1(x)))
y1 = self.cv6(self.cv5(torch.cat([x1] + [m(x1) for m in self.m], 1)))
y2 = self.cv2(x)
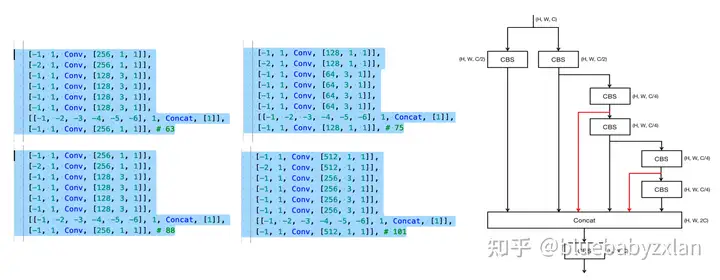
return self.cv7(torch.cat((y1, y2), dim=1))累计用到4处ELAN-neck,具体位置和结构如下图所示(红线为ELAN基础上的新增路径):
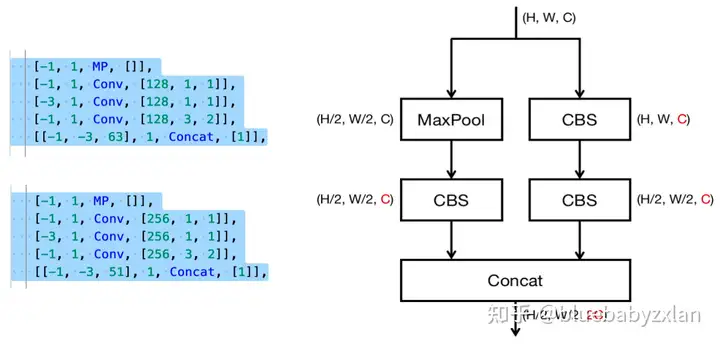
累计用到2处DS-neck,DS-neck和backbone中的DS模块区别在于通道数的控制(DS-neck输出通道数变为输入的2倍,DS则保持输入/输出通道数不变),Ds-neck的具体位置和结构如下图所示(对63和51的concat不属于MP-neck模块内容,是融合路径下来自FPN的特征复用):
累计使用2次上采样,上采用使用最近邻插值,具体位置如下:

累计使用3次RepConv,分别位于三个不同尺度的head分支前,具体如下:
关于结构重参数化,可参照bluebabyzxlan:解读ACNet;bluebabyzxlan:解读DBB-Net(ACNet V2);bluebabyzxlan:解读RepVGG.
head部分则使用了YOLOR的head(简记为R-head),具体如下图所示,其中ImplicitA和ImplicitM均有长度为C的向量(C大小根据通道数变化决定,与输入通道数保持一致),该向量的值是可学习的(也被称为隐形知识),不同的是ImplicitA使用可学习向量和输入做加法,ImplicitM使用可学习向量和输入做乘法(相当于对通道值进行一个shift和scale,有点类似于SENet,但SENet只有scale).

E-ELAN
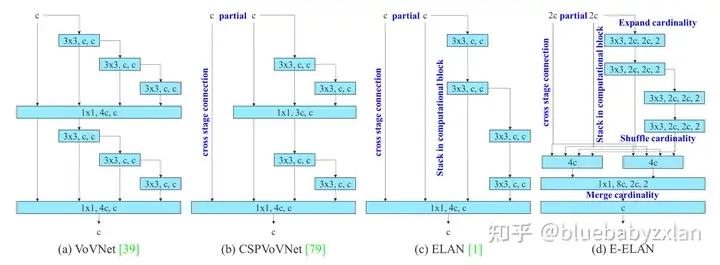
YOLO v7基于ELAN提出了E-ELAN,其结构如下图(d)所示,但在其开源代码中所提供的模型配置文件中(cfg/training/yolov7.yaml),并未使用该模块. E-ELAN的关键在于expand、shuffle和merge cardinality,expand就是使用了更大的通道数(是ELAN的两倍),shuffle则是指深浅层特征间的通道shuffle(四个分支的第一、第二个分支为浅层特征,第三、第四个分支为深层特征,对二者进行shuffle),merge cardinality则是将深浅层特征做进一步融合.
个人理解:由于expand扩大了两倍通道数,猜测是为了降低参数量和计算量,所以后续使用分组卷积,而为了增强组之间的信息交互,所以进行了shuffle,而merge操作则是CSPNet的精髓——跨阶段特征融合,对于E-ELAN的示例结构,在merge时采用group=2的分组卷积,因此两个4c特征独立得到两个c特征,这也是为什么在merge前需要进行shuffle的原因,最终再融合为一个c特征.
深度监督
The detailed coarse-to-fine implementation method and constraint design details will be elaborated in Apendix.
如下图(d)和(e)所示,YOLO v7提出使用aux head来帮助训练并且lead head和aux head使用不同的标签分配策略,其具体细节在附录中,但其目前发表的文章中并没有附录,这里先放一个坑,待YOLO v7的paper有了进一步更新后再填上.
附onnx导出的结构图工解析;

posted on 2022-12-07 20:28 Sanny.Liu-CV&&ML 阅读(1923) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号