姿态估计-openpifpaf
转载:https://blog.csdn.net/Murdock_C/article/details/93748001 openpifpaf源码解析
转载:https://zhuanlan.zhihu.com/p/93896207 深度解析pifpaf
这是CVPR2019上面的一篇基于Bottom-Up方法的姿态估计文章,标题是:PifPaf: Composite Fields for Human Pose Estimation。Paper链接为:
开源代码在:
摘要
我们提出了一种新的自下而上的多人2D人体姿势估计方法,该方法特别适合于城市机动性,例如无人驾驶汽车和送货机器人。 新方法PifPaf使用“部件强度场”(Part Intensity Field,PIF)来定位身体部位,并使用“部件关联场”(Part Association Field,PAF)将身体部位彼此关联以形成完整的人体姿势。 由于(i)我们新的复合场PAF编码细粒度信息,以及(ii)选择拉普拉斯损失进行回归,并结合了不确定性,因此我们的方法在低分辨率和拥挤,混乱和遮挡的场景中优于以前的方法。 我们的体系结构基于全卷积,单发,box-free设计。 我们的方法在标准COCO关键点任务上与现有的state-of-the-art 自下而上方法效果相同,并在运输领域的改进的COCO关键点任务上产生了state-of-the-art结果。
1、介绍
在流行的数据收集运动的推动下,在“野外”估计人的姿势方面已经取得了巨大进展[1,27]。 但是,当涉及到诸如自动驾驶汽车或社交机器人等“运输领域”时,我们仍然远远不能达到可接受的准确性水平。 虽然姿势估计不是最终目标,但它是有效的低维度且可解释的人类表示形式,可以尽早地为自主导航系统检测关键动作(例如,检测打算过马路的行人)。 因此,可以检测到人体姿势越远,自动驾驶系统越安全。 这直接与提高感知人体姿势所需的最低分辨率的限制有关。
在这项工作中,我们解决了给定单个输入图像的多人2D人体姿势估计问题。 我们专门解决了如图1所示的自主导航设置中出现的挑战:(i)对人的分辨率有限的宽视角,即30-90像素的高度,以及(ii)行人彼此遮挡的高密度人群 。 当然,我们的目标是提高召回率和准确性。

【图1、我们要估算在拥挤场景中运行自主导航系统的交通领域中的人类2D姿势。 人体占据图像的一小部分,并且可能部分相互遮挡。 我们用彩色线段显示PifPaf方法的输出。】
尽管在深度学习时代之前就已经对姿势估计进行了研究,但重要的基石是OpenPose [3]的工作,其次是Mask R-CNN [18]。 前者是一种自下而上的方法(在没有人检测器的情况下检测关节),后者是一种自上而下的方法(首先使用人检测器并在检测到的边界框中输出关节)。 尽管这些方法在足够高分辨率的图像上表现出惊人的效果,但它们在有限的分辨率范围内以及人与人之间相互遮挡的人群中表现不佳。
在本文中,我们建议将姿势估计中的场概念[3]从标量场和矢量场扩展到复合场。我们介绍了一种具有两个头部网络的新神经网络架构。对于每个身体部位或关节,一个头部网络可预测该关节的置信度分数,精确位置和大小,我们称其为“部件强度场”(PIF),与[34]中的融合部分置信度图相似。另一个头部网络预测零件之间的关联,称为部件关联场(PAF),它是一种新的复合结构。我们的编码方案具有在低分辨率激活图上存储细粒度信息的能力。精确地回归关节位置至关重要,我们使用基于拉普拉斯的L1损失[23]而不是vanilla L1损失[18]。我们的实验表明,我们在低分辨率图像上的性能优于自下而上和已建立的自上而下的方法,而在高分辨率下却表现出色。该软件是开源的,可以在网络上获取。
2、相关工作
在过去的几年中,state-of-the-art姿势估计方法基于卷积神经网络[18,3,31,34]。 它们优于基于图形结构[12、8、9]和可变形零件模型[11]的传统方法。 深度学习海啸始于DeepPose [39],DeepPose使用级联的卷积网络进行全身姿势估计。 然后,某些工作代替预测绝对的人体关节位置,而是通过预测每次迭代的错误反馈(即校正)来精炼姿态估计[4、17],或使用人体姿态修正网络来利用输入和输出空间之间的依赖性[13]。 。现在正在争相提出替代性神经网络架构:从卷积姿势机[42],堆叠式沙漏网络[32、28]到递归网络[2]和投票方案,例如[26]。
所有这些用于人体姿势估计的方法都可以分为自下而上和自上而下的方法。前者首先估计每个人体关节,然后将它们分组以形成唯一的姿势。后者首先运行人体检测器,并在检测到的边界框中估计人体关节。
Top-down 方法 自上而下方法的示例是PoseNet [35],RMPE [10],CFN [20],Mask R-CNN [18、15],以及最近的CPN [6]和MSRA [44]。 这些方法得益于人体检测器的进步以及为人们提供的大量标记边界框。 利用这些数据的能力将人体检测器的需求变成了优势。
值得注意的是,Mask R-CNN将关键点检测视为实例细分任务。 在训练期间,对于每个独立关键点,目标都将转换为包含单个前景像素的二进制蒙版。 通常,自上而下的方法是有效的,但是当人的边界框重叠时会遇到困难。
Bottom-up 方法 自下而上的方法包括Pishchulin的DeepCut [37]以及Insafutdinov的DeeperCut [21]的开创性工作。 他们使用整数线性程序解决部件关联问题,这会导致单个图像处理时间的增加。 后来的工作加快了预测时间[5],并扩大了跟踪动物行为的应用[30]。 通过将贪婪解码器与其他工具如Part Affinity Fields[3], Associative Embedding [31]和PersonLab [34]结合使用, 其他方法可以大大减少预测时间。 最近,MultiPoseNet [24]开发了一种多任务学习架构,该架构结合了对人的检测,分割和姿势估计。
在图像平面的2D姿势估计之上还建立了其他中间表示,包括3D姿势估计[29],视频中的人体姿势估计[36]和密集姿势估计[16],这些都可以从改进的2D姿势估计中获利。
3、方法
我们方法的目标是估计拥挤图像中的人体姿势。 我们解决与低分辨率和部分被遮挡的行人相关的挑战。 当行人被边界框碰撞的其他行人遮挡时,自顶向下方法特别困难。 以前的自下而上的方法没有边界框,但仍包含用于本地化的粗略特征图。 我们的方法不受关节空间定位的任何基于网格的约束,并且能够估计多个相互遮挡的姿势。
图2展示了我们的整体模型。 它是一个具有两个头部网络的共享ResNet[19]基础网络:一个头部网络可预测置信度,精确位置和关节大小,我们将其称为部件强度场(PIF),另一个头部网络可预测部件之间的关联 ,称为部件关联场(PAF)。 我们将我们的方法称为PifPaf。
在详细描述每个头网络之前,我们先定义我们的场符号。
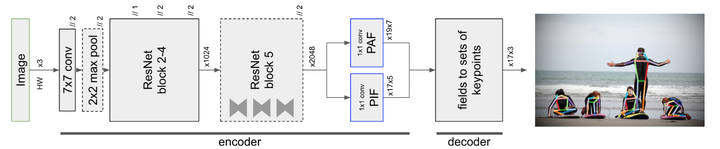
图2、模型结构
【输入是具有三个颜色通道的大小为(H,W)的图像,用“ x3”表示。 基于神经网络的编码器产生具有17×5和19×7通道的PIF和PAF场。 用“ // 2”表示步幅为2的操作。 解码器是一个程序,可将PIF和PAF场转换为姿势估计,每个姿势包含17个关节。 每个关节均由x和y坐标以及置信度分数表示。】
3.1、场符号
场是用于推断图像顶部结构的有用工具。 复合场的概念直接激励了我们提出的部件关联场。
我们将使用i, j在空间上枚举神经网络的输出位置,并使用x, y表示实值坐标。 场在域 上用
表示,并且可以具有标量,向量或复合数作为共域(场的值)。 例如,标量场
和向量场
的复合可以表示为{s,
,
},等效于用向量场“覆盖”置信度图。
3.2、Part Intensity Fields
部件强度场(PIF)可检测并精确定位人体部位。 在[35]中引入了置信度图与回归点融合以进行关键点检测。 在这里,我们用复合场的语言来概括该技术,并添加一个标度σ作为新的成分来形成我们的PIF场。
PIF具有复合结构。 它们由一个用于表示置信度的标量分量,一个指向特定类型的最接近人体部位的矢量分量和另一个用于关节大小的标量分量组成。 更正式地说,在每个输出位置(i,j),PIF都会预测置信度c,具有spread b(详见3.4节)和比例σ的一个向量(x,y),可以写成 。
PIF的置信度图非常粗糙。图3a显示了示例图像的左肩置信度图。为了改善此置信度图的定位,我们将其与图3b中所示的PIF的矢量部分融合为高分辨率的置信度图。我们创建了一个高分辨率的零件置信度图f(x, y),该图由未标准化的高斯核N的卷积组成,宽度为pσ,其宽度由零件强度场中经其置信度pc加权的回归目标得出:
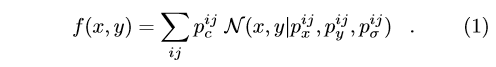
该方程式强调了定位的无网格性质。 关节的空间范围σ被视为该场的一部分。 图3c中显示了一个示例。 生成的高度局部化的关节图用于为姿势生成提供种子,并对新提出的关节的位置进行评分。
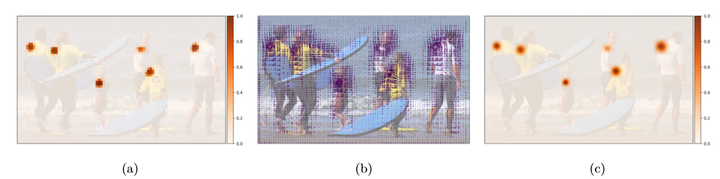
图3、可视化左肩的PIF组件
【这是17个复合PIF之一。置信度图如(a)所示,矢量域如(b)所示。(c)中显示了融合的置信度,向量和比例分量。】
3.3、Part Association Fields
在人群相互遮挡的拥挤场景中,将关节组合成多个姿势是具有挑战性的。在这种情况下,尤其是两步过程(自上而下的方法)难以解决:首先,他们检测到人的边界框,然后尝试为每个边界框找到一种关节类型。自下而上的方法没有边界框,因此不会遇到冲突的边界框问题。
我们提出了自下而上的零件关联字段(PAF),以将关节位置连接到姿势中。 PAF方案的图示如图4所示。在每个输出位置,PAF都会预测一个置信度,该关联所连接的两个部分的两个向量和两个宽度b(详细信息请参见第3.4节)用于回归的空间精度。 PAF用
表示。 左肩和左臀部之间的关联的可视化效果如图5所示。
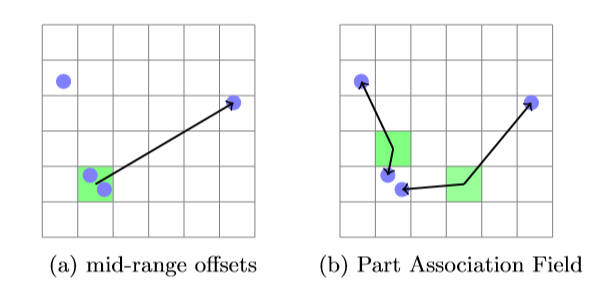
图4、feature map网格上PersonLab的mid-range offsets(a)与PAF(b)之间差异的说明。
【蓝色圆圈表示关节,置信度以绿色标记。 Mid-range offsets(a)的起点在feature map单元格的中心。 部件关联场(b)具有其原点的浮点精度。】
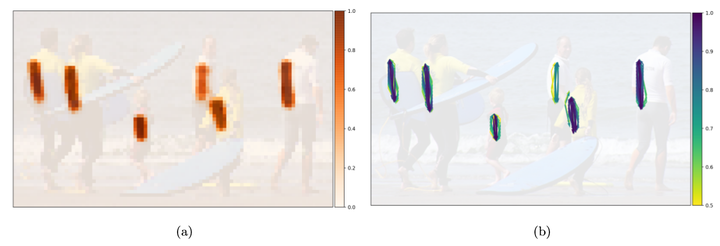
图5、PAF组件的可视化,该组件将左肩与左臀部关节关联
【这是19个PAF之一。 特征图的每个位置都是两个向量的起点,它们指向要关联的肩膀和臀部。 在(a)中显示了关联ac的置信度,在(b)中显示了ac> 0.5的向量分量。】
这两个端点都使用回归进行局部化,因为回归不会出现在基于网格的方法中,因此不会受到离散化的影响。 这有助于精确地解决附近人的关节位置,并将其解析为不同的标签。
COCO数据集中有19个针对人体姿态的连接,每个连接都连接两种类型的关节。 例如,从右膝到右脚踝有关联。 在特定特征图位置构造PAF组件的算法包括两个步骤。 首先,找到确定矢量分量之一的两种类型中最接近的一种。 第二,GT姿势决定了另一个表示关联的向量分量。 第二关节不一定是最接近的关节,并且可以很远。
在训练期间,该场的组成部分必须指向应关联的部分。 与矢量域的x分量始终必须与y分量指向相同的目标类似,PAF场的分量必须指向相同的部件关联。
3.4、自适应回归损失
人体姿势估计算法倾向于与人体姿势在图像中可能具有的比例尺的多样性作斗争。 虽然大尺度的人体的关节的定位错误可能很小,但对于小尺度的人体来说,相同的绝对错误可能是主要错误。 我们使用L1型损失来训练回归输出。 我们通过使用SmoothL1 [14]或Laplace损失[23]向回归损失中注入比例依赖来提高网络的定位能力。
SmoothL1损耗允许围绕原点调整半径 ,在原点处产生较柔和的渐变。对于一个人体实例,边界框面积
和
的关键点大小 ,
可以被设置成与
比例,我们在表3中进行了研究。
拉普拉斯损失是另一种L1损失,它通过预测的spread b衰减:
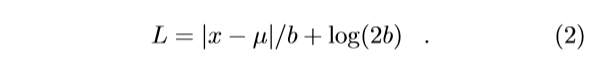
它独立于 和
的任何估计,我们将其用于所有矢量分量。
3.5、Greedy Decoding
解码是将神经网络的输出特征图转换为17组坐标的过程,这些坐标可进行人体姿态估计。我们的过程类似于[34]中使用的快速贪婪解码。
在等式1中定义的高分辨率置信度映射 中,具有最高值的PIF向量为新的姿势播种。从种子开始,借助PAF字段添加与其他关节的连接。 该算法既快速又贪心。 一旦建立了新关节的连接,该决定即为最终决定。
多个PAF关联可以在当前关节和下一个关节之间形成连接。给定起始关节的位置 ,可以用以下公式计算PAF关联a的分数s
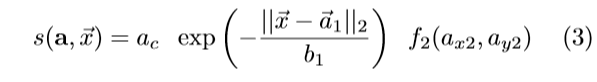
其中考虑到了此连接ac的置信度,到第一向量位置的距离(使用两尾Laplace分布概率校准)和第二个向量的目标位置f2的高分辨率部分置信度。为了确认新关节的建议位置,我们进行反向匹配。重复该过程,直到获得完整姿势为止。我们在关键点级别上应用了非最大抑制,如[34]。抑制半径是动态的,并且基于PIF字段的预测比例分量。无论是在训练还是测试期间,我们都不对任何场进行refine。
代码解析过程:
openpifpaf 的decode过程:
- 网络的输出:
pif, 原始的输出共有4个, 分别为:
joint_intensity_fields, shape 为 [17, output_h, output_w]. 其实就是输出的每个位置上的confidence map, 17表示channel数, 在pose检测里面表示总共有多少个关键点需要检测.
joint_offset_fields, shape 为[17, 2, output_h, output_w]. 为对应位置上的离其最近的关节点位置的偏移量. 这个是学习得到的, 2表示是两个方向(x, y)的偏移量. 所以关节点的真正位置需要把该位置的(x, y)和其两个方向的(x_offset, y_offset)相加起来得到.
joint_b, shape为[17, output_h, output_w]. 论文里提到的spread b,是自适应并且经过网络学习得到的, 用来参与loss计算, 在decode的时候并没有用到.
joint_scale_fields. shape为[17, output_h, output_w]. 自适应的scale值, 用来表明该关键点的scale大小.不确定是否有用在loss计算里. decode的时候则是作为类似gaussian的sigma值参与decode过程.
paf, 原始的输出共有5个, 按照顺序为: (首先说明下, 论文提出的paf和之前OpenPose及PersonLab提出的连接方式都不一样. 该论文提出的paf连接为, 每个位置预测出哪两个点需要连接在一起, 因此不是单纯的两个关节点之间的直接连接, 而是经过了另外一个位置进行第三方连接)
joint_intensity_fields, shape为[19, output_h, output_w]. 19表明共有多少个连接需要学习, 对应的是每个输出位置上的paf的confidence值
joint1_fields, shape为[19, 2, output_h, output_w]. 这个位置表明的两个可以连接在一起的点中的第一个点的信息, 其实就是偏移值, (x_offset, y_offset).
joint2_fields, shape为[19, 2, output_h, output_w]. 同上, 表示的是一条线段上的第二个点的偏移值.
joint1_fields_logb, shape为[19, output_h, output_w]. 论文里提到的spread b,是joint1的, 用来参与loss计算和decode. 根据decode的过程来看, 网络输出的这个值是经过log计算后的, 所以叫做logb,在decode的时候需要先exp还原.
joint2_fields_logb, shape为[19, output_h, output_w]. 同上, 只不过变成是第二个点的b了.
- decode过程:
normalize_pif. 就是把网络的pif 4个输出整合在一起, 首先是对joint_intensity_fields和joint_scale_fields进行扩维, 把shape从[17, output_h, output_w]变成[17, 1, output_h, output_w]. 接着是根据joint_offset_fields对[output_h, output_w]这么大的矩阵上, 对应的位置(x, y) + offset. 举例来说, 原来的joint_offset_fields, 其中[1, :, 4, 5] 这个位置表示的offset值为(1, 2), 那么意思就是在(4, 5)这个位置坐标(4, 5)上, 需要加上偏移(1, 2)才是真正的这个位置所表示的关键点坐标值, 也即是(5, 7), 因此最后[1, :, 4, 5] == [5, 7]. 最后把更新后的这三个矩阵concatenate一起, 变成[17, 4, output_h, output_w]的pif信息, 4表示每个位置上都有四个值, 分别是[confidence, x, y, scale]. 这个时候的[x, y]就是真正的这个点表示的关键点的坐标值.
normalize_paf. 同pif一样, 也是把网络的paf 5个输出整合在一起. 除了对joint1_fields和joint2_fields进行同样的offset相加外(和pif的操作一样), 还对两个logb进行了exp操作, 然后对joint_intensity_fields和两个b进行扩维成[19, 1, output_h, output_w]. 最后对更新后的joint_intensity_fields, joint1_fields, joint1_logb进行concatenate一起, 得到[19, 4, output_h, output_w]大小的矩阵, 这个存储的全是有关joint1的, 同理, 对joint2做同样的操作, 同样得到[19, 4, output_h, output_w]大小的矩阵. 4表示[confidence, x, y, b]. 需要注意的是joint1和joint2共享同样的confidence值. 最后, 对这两个矩阵进行stack一起,得到最终的[19, 2, 4, output_h, output_w]输出.
_target_intensities: 根据上面得到的新的pif信息, 利用文章提出的公式1, 得到在高维空间(也就是网络的输入分辨率下)的pif_hr, pifhr_scales信息. hr表示的就是high resolution的意思. 方法就是首先找到pif里所有confidence > v_th的值, 先把(x, y, s) 都乘上网络的scale值, 然后针对这些位置, 以这些位置为中心, 位置对应的scale值为gaussian的sigma, 范围为当前位置对应的confidence/16(不是很理解为什么是这个值), 接着对这个范围内的值做高斯变换, 和pif里原来的位置信息相加, 使得本来confidence就很高的位置值更高, confidence值低的位置值更低. (具体图示可以参考文章图3). 源码里的scalar_square_add_gaussian函数就是这个作用, 这样就得到了pif_hr. cumulative_average函数的作用好像是对这个区域的scale求个平均? 没有很理解这个函数的作用, 但结果是得到对应的scale值.
_score_paf_target: 这个函数的作用就是根据上面得到的paf信息, 得出哪些点是连在一起的. 因为paf的shape是[19, 2, 4, output_h, output_w], 因此对于每个连接, 其对应的paf field shape均为[2, 4, output_h, output_w]. 首先, 对于单个线段的信息, 假设为第一条线段的信息, 为fourds, shape = [2, 4, output_h, output_w]. 首先, 找到fourds里每个位置上的confidence值最小的那个(源码是scores = np.min(fourds[:, 0], axis=0), 但我感觉因为对于同一个feature map上的位置而言, joint1 和 joint2的confidence是一致的, 因此其实就是把feature map上对应位置的score值去出来). 然后, 找到满足scores > score_th条件的位置, 把这些位置取出来, 组成个新的fourds. 同理, scores也取出来, 组成个新的scores. 这时fourds的维度就是[2, 4, n], scores的维度是[n, ], n为满足前面score条件的点的个数. 然后, 找到第一条线段对应的pif的channel位置, 例如第一条线段在coco是[15, 13], 那么就把pif_hr[15]当作是这个线段的joint1所在的featuremap, pif_hr[13]就是这个线段的joint2所在的featuremap. 因为此时fourds的shape为[2, 4, n], 那么fourds[0]就是所有满足刚才那个条件的joint1集合, fourds[1]就是joint2集合. 地一个函数scalar_values的意思, 就是找到在pif_hr[15]上, 位置为(fourds[0, 1] * self.stride, fourds[0, 2]*self.sride)的confidence值,(注意这个confidence是指在pif_hr上的confidence, 不知道为啥程序里变量名起做pifhr_b.) 此时得到的pifhr_b就是joint1对应的在pifhr上的confidence值, 接着执行代码scores_b = scores * (pifhr_floor + (1.0 - pifhr_floor) * pifhr_b), 我的理解是这行代码的作用就是根据confidence对scores进行更新, pifhr_floor是0.1, 如果本身的pifhr_b值很大, 那么其对应的在paf的score就还是很大, 如果小, 相应的也缩小了其对应的paf的score值. 更新完后得到scores_b, 再根据这个值进一步过滤找到符合条件的joint1, joint2点, 最后把符合条件的点集合, 得到scored_backward里的一个元素. 因为paf总共有19个channel, 所以scored_backward总共有19个元素, 每个元素都是[7, m]大小的矩阵, 存储的信息分别是[score_b, joint2_x, joint2_y, joint2_b, joint1_x, joint1_y, joint1_b]. m是scores_b中符合条件的点的个数. 因为元素是先joint2元素信息再是joint1信息, 所以叫做scored_backward. 下面还会有在**_pifhr[j2i] (_pifhr[13])**搜索符合条件的joint2的信息, 仿照上面的步骤, 同样得到一个[7, n]的矩阵, 信息为[score_b, joint1_x, joint1_y, joint1_b, joint2_x, joint2_y, joint2_b], 因为这个是先jioint1的信息再是joint2的信息, 因此其组成的列表又叫做scored_forward, 其实就是看是以joint1为出发点还是终止点表示的这个线段信息.
- 总结下先, 3执行完之后, 得到了一个在高分辨率下的pifhr信息和pif_scales信息, shape均为[17, hr_h, hr_w]. 4执行完后, 得到了两个均含有19个元素的列表, 分别叫做scored_forward 和 scored_backward. 列表里的每个元素, 都是满足一系列条件的点的信息, 例如对于scored_forward[0]来说, shape大小为[7, m], m为点的个数, 7表示[score_b, joint1_x, joint1_y, joint1_b, joint2_x, joint2_y, joint2_b], 形象话说, 就是对于7*m的矩阵, 每一列都能找到两个点用来表示线段0. 需要明确的一点, 这里面的两个点, 都还是通过paf信息得到的点的位置, 并不是在pif信息上的点的位置
接着就是根据3和4得到的结果, 用来连线, 判断哪些线段应该连起来组成一个人**.**
_pif_seeds函数: pif_seeds函数用来在self.pif上找到confidence符合阈值的点的信息, , 然后再在pifhr上找到该点对应的confidence值, 接着把(v, field_i, xx, yy, ss)组成一个seed放入seeds中, v是在pifhr上的confidence, field_i是用来表明这个点在第几个channel上, (xx, yy, ss)都是在pif上的位置和scale信息. 最后, 对seeds按照v的值降序排列, 越靠近前面的seed, confidence值更大.(比较奇怪的是为什么confidence是在pifhr找, 但(xx, yy, ss)都是在pif上面找)
首先根据3得到的pifhr_scales生成同样大小的矩阵occupied, 找到了pif_seeds之后, 按照排过序的seeds序号, 先从confidence值最大的seed进行寻找. 首先判断当前seed的(x, y)是否超过了occupied的范围, 如果超过就寻找下一个seed, 没有就返回当前occupied[y, x]的值. (这边同样有个问题, occupied初始化为0, 那寻找第一个seed的时候, 无论是否超出范围, 返回的值都为0, 也就是说按照源码来说, 第一个seed是没有用的?我尝试了把第一个seed当作正常运行放进去, 发现结果没有太大差别, 就是最后的anno score值变大了一些. 不过python格式的程序速度慢了将近一倍.) 然后会执行函数scalar_square_add_single, 这个函数的作用就是让occupied矩阵在(x*stride, y*stride) 为中心, 范围为max(4, s*stride)的范围内加1. 这样就相当于更新了以(x, y)为中心的occupied值. 接着, 根据seed的(x, y, v) 和 当前所处的channel编号f, 构建Annotation类. ann.data是一个[17, 3]的矩阵, 存储的就是一个完整的人体pose应该有的关节点个数. ann.skeleton_m1就是下标从0开始的[19, 3]的skeleton连接编号. 初始化ann的时候, 会根据f的值把传入的(x, y, v) 放进去ann.data[f]上. 接着, 就会以当前ann为已有的skeleton信息, 以前面得到的_paf_forward, _paf_backward连接信息进行_grow操作.
_grow函数: 在进行从_paf_forward, _paf_backward抽取信息前, 会先对当前的ann执行ann.frontier_iter()函数. ann.frontier_iter()函数的意思就是找到当前ann.data里, 应该和ann.data里已有值的点相连的点, 但是却没有在ann.data里面的点. 然后, 根据这个点是在已有点的后面(即已有点是joint1, 未找到点是joint2)还是在前面, 判断该点是处于forward状态还是backward状态. 接着, 对这些所有点进行按照已有值的点的confidence值降序排列. (函数最终会得到一个列表的集合, 每个列表的元素都是[confidence, connection_i, True/False, j1i, j2i], confidence是已有点的confidence, connection_i是这个点应在的线段连接编号, True表明已有点是joint1, 放进去的这个点是joint2, j1i 和 j2i就是这个connection连接的两个点的channel编号). 最后, 从这个列表frontier里取出第一个值, 表明是当前已有的ann.data里, confidence值最高的那个点应该连接的点的信息. 取出的值就是上面所讲的列表的元素值信息, 如果是True(表明为forward), 则xyv = ann.data[j1i], directed_paf_field = paf_forward[i], directed_paf_field_reverse = paf_backward[i], 否则的话, xyv = ann.data[j2i], directed_paf_field = paf_forward[i], directed_paf_field_reverse = paf_backward[i]. xyv是从ann.data里取出的目前confidence值最高且需要额外的一个点和它连接的点(new_xyv), directed_paf_field就是new_xyv所在的paf_field, directed_paf_field_reverse就是刚好xyv所在的paf_field. (刚好一个是paf_forward, 一个是paf_backward). 然后, 根据得到的directed_paf_field, 执行_grow_connection函数.
**_grow_connection**函数. 这个函数比较简单, 首先是在paf_field上, 以(x,y)为中心, 找到在paf_field里的所有点符合条件的点, 拿出来构成新的paf_field, 然后, 在这个新的paf_field里面, 计算这些点和xy这个点的距离, 并根据距离更新里面点的score值, 最后选择score值最大的那个点作为返回值. 为了保证找的这个点是正确的, 会根据找到的这个点进行reverse match, 步骤和前面的一致, 判断通过reverse找到点是否和(x,y)满足距离阈值条件. 如果是, 就把找打的这个点当作新的一个点放进ann.data里面. 这样循环遍历, 就能把ann给尽量的填充满.
当对当前的seed点进行grow_connection之后, 会根据之前得到的pifhr_scales对ann.data的每个点加上对应的scale值, 然后根据目前已有的ann.data值, 再更新一遍每个ann.data里的点对应的occupied矩阵, 就是执行函数scalar_square_add_single函数. 最后选择下一个seed点进行grow, 直到所有的seed点都遍历过一次. 最后再对所有的anns执行complete_annotations操作, 就是寻找对于每个ann上额外的空置的点(应该有点和它连接的实际上没有)是否还有可能有其它点和它连在一起, 就是再执行一边_grow操作.
**soft_nms**函数: 对11得到的annos执行nms操作, 过滤掉一些有可能不符合要求的ann. ann.score值是其中ann.data中每个点的score值的加权平均.
posted on 2021-10-12 00:16 Sanny.Liu-CV&&ML 阅读(1725) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号